
Joined March 2012
- Tweets 8,446
- Following 647
- Followers 3,202
- Likes 8,895
528 Photos and videos














Here's the paper, the framework, the seriousness. philarchive.org/rec/HAYAAV-3
May 28

"Advaita Vedanta approach to agentic AI"
No wonder what it means. No white paper. No framework, just non serious stuff.
Current Agents are unreliable.
@AKLKO1977
2
1
393
Kush Varshney कुश वार्ष्णेय retweeted

May 31
The Nexbax AI Index proposes new AI evaluation metrics focused on real-world usability, cost, and accessibility for users in India and the Global South, challenging standard global benchmarks.
✍️Rashmi Patil
trib.al/UwVC8IG
4
8
5,672
Kush Varshney कुश वार्ष्णेय retweeted

May 26
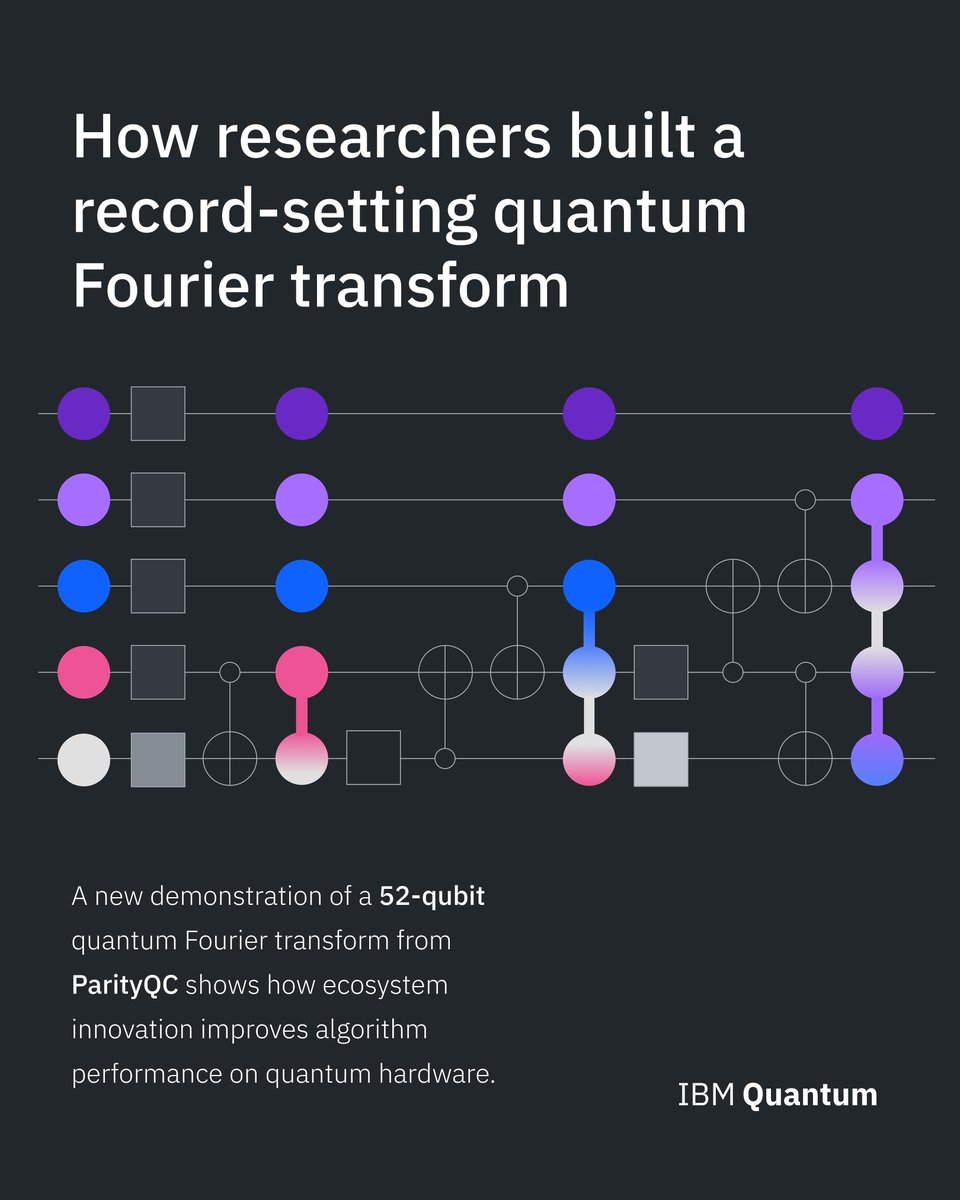
Quantum startup @ParityQC demonstrates 52‑qubit quantum Fourier transform on IBM Heron processor, the largest to date: ibm.co/6017EMVb7
New “Parity Twine” method achieves record-setting performance by rethinking how quantum information is represented and propagated.
15
56
3,780
Kush Varshney कुश वार्ष्णेय retweeted

May 21
A blog on how to get frontier-level results from small language models by using Mellea and Granite Libraries do the heavy lifting: mellea.ai/blogs/small-models…
1
1
497
Kush Varshney कुश वार्ष्णेय retweeted

📊 We also introduce VELI5, a new dataset with controlled factual errors ground-truth fixes. This dataset has already been used to fine-tune state-of-the art factuality guardrails such as Granite Guardian [huggingface.co/ibm-granite/g…].
(3/4)
1
2
1
157
Kush Varshney कुश वार्ष्णेय retweeted

Apr 29
IBM just dropped Granite 4.1, their largest model release to date
Language, vision, speech, embeddings, and safety models all in one drop
The 8B instruct model reportedly matches their previous 32B MoE on instruction following and tool calling
Guardian 4.1 does risk and policy scoring with calibrated confidence levels instead of binary yes/no filtering, which is a smarter approach for enterprise deployment
All Apache 2.0, available on HuggingFace, Ollama, and watsonx
IBM is quietly building a full enterprise AI stack
research.ibm.com/blog/granit…

1
3
234
Kush Varshney कुश वार्ष्णेय retweeted

Apr 29
IBM is clearly doubling down on a very specific lane here: practical, efficient, enterprise-ready models rather than chasing leaderboard dominance.
Granite 4.1 feels like a continuation of that philosophy—especially the 8B. That 4M token usage vs 78M on Qwen is kind of wild. In real deployments, that translates directly into:
lower latency
dramatically lower cost
easier scaling for agent workflows
Which honestly matters more than raw benchmark scores for most companies.
The tradeoff is obvious though: you’re giving up peak intelligence. A 12 vs 15 score doesn’t sound huge, but in practice that gap can show up in:
reasoning depth
edge-case handling
coding reliability
So these aren’t “frontier competitors”—they’re workhorse models.
What’s arguably more important is the Apache 2.0 openness push. That 61 Openness Index score puts IBM ahead of most “open-ish” players like Alibaba (Qwen) and Google (Gemma). For enterprises, that’s a big deal:
fewer licensing headaches
more control over deployment (on-prem / air-gapped)
easier compliance story
The positioning is pretty clear:
Granite 3B → edge / lightweight agents
Granite 8B → sweet spot (cost vs capability)
Granite 30B → heavier enterprise workloads where you still want efficiency
The most interesting signal here isn’t the scores—it’s the token efficiency trend. If models like this keep improving, the industry might shift from “bigger is better” to:
“good enough intelligence, but 10–20x cheaper to run”
And that’s where adoption really explodes.
Curious part: if someone pairs Granite 8B with strong retrieval tools, it could close a lot of that intelligence gap without losing its cost advantage. That’s probably the real play.
1
1
263
Kush Varshney कुश वार्ष्णेय retweeted

IBM has released three new non-reasoning Granite 4.1 models (30B, 8B, 3B) as open weights under Apache 2.0. All three are notably token-efficient relative to peer non-reasoning models, with the 8B standing out for its token efficiency relative to intelligence
@IBM has released three new instruct models in the Granite 4.1 family: Granite 4.1 30B (15 on the Intelligence Index), Granite 4.1 8B (12), and Granite 4.1 3B (9). The release continues IBM's focus on small, efficient, and open models for enterprise and edge deployment, alongside the existing Granite 4.0 Nano family (1B and 350M variants released in October 2025). The Intelligence Index is the Artificial Analysis synthesis metric incorporating 10 evaluations covering agentic tasks, coding, and scientific reasoning.
Key benchmarking results:
➤ All three Granite 4.1 models score 61 on the Artificial Analysis Openness Index, standing out among peer open weights non-reasoning models. This is driven by full open weights under Apache 2.0 plus partial disclosures across pre-training data, post-training data, and training methodology. Granite 4.1 sits well above peers like Qwen3.5 (39), Gemma 4 (39) and GLM-4.7-Flash (44), and represents a meaningful improvement over the Granite 4.0 family (56), driven by stronger methodology disclosure. Olmo 3.1 and K2 Think V2 (both 89) remain leaders as the most ‘open’ models.
➤ Granite 4.1 8B uses just 4M output tokens to run the Intelligence Index. This is ~20x fewer than Qwen3.5 9B (78M tokens), ~3x fewer than Ministral 3 8B (13M), and ~2x fewer than Gemma 4 E4B (8M). The pattern holds across the family: Granite 4.1 30B uses 4.6M output tokens (vs 7M for Gemma 4 31B and 25M for Qwen3.5 27B), and Granite 4.1 3B uses 2.7M.
➤ Token efficiency comes at the cost of intelligence relative to peer non-reasoning models. Granite 4.1 30B (15) trails leading peers like Qwen3.5 27B (37) and Gemma 4 31B (32). Granite 4.1 8B (12) trails Ministral 3 8B (15) and Gemma 4 E4B (15). Granite 4.1 3B (9) trails Gemma 4 E2B (12).
➤ Granite 4.1 30B and 3B both gain on the Intelligence Index over their Granite 4.0 predecessors. Granite 4.1 30B (15) gains 4 points over Granite 4.0 H Small (32B / 9B active, 11), with the largest gains in tool use (τ²-Bench: 42% vs 17%) and agentic tasks (GDPval-AA: 493 vs 344 Elo). Granite 4.1 3B (9) gains 1 point over Granite 4.0 Micro (8).
Other information:
➤ License: Apache 2.0 (open weights, permissive commercial use) ➤ Context window: 128K tokens ➤ Availability: Granite 4.1 8B is available via @WandB ($0.05/$0.1 per 1M input/output tokens) and @replicate. Weights for all three models are available via @huggingface.

10
29
243
24,203
Kush Varshney कुश वार्ष्णेय retweeted

Apr 27
What if your language model could reason efficiently in an entirely new language?
We introduce Abstract Chain-of-Thought, a new mechanism which allows language models to reason through a short sequence of reserved "abstract" tokens through reinforcement learning. It is as performant as verbalized CoT at a fraction of the cost, achieving major gains in inference-time efficiency.

61
132
1,069
1,180,895
Kush Varshney कुश वार्ष्णेय retweeted

Apr 22
I've been working on an open source project called Mellea, and wrote a blog post about using it to automatically validate and fix Qiskit code generated by an LLM: mellea.ai/blogs/qiskit-ivr-c…
1
2
4
223
Kush Varshney कुश वार्ष्णेय retweeted

Mar 13
🚨 Is Explainable AI (XAI) broken at its core? A landmark new study addresses this — and charts a path forward.
📄 Check it out: arxiv.org/pdf/2602.24176
#ExplainableAI #XAI #ArtificialIntelligence #MachineLearning #ResponsibleAI #AIResearch #LLMs #DeepLearning
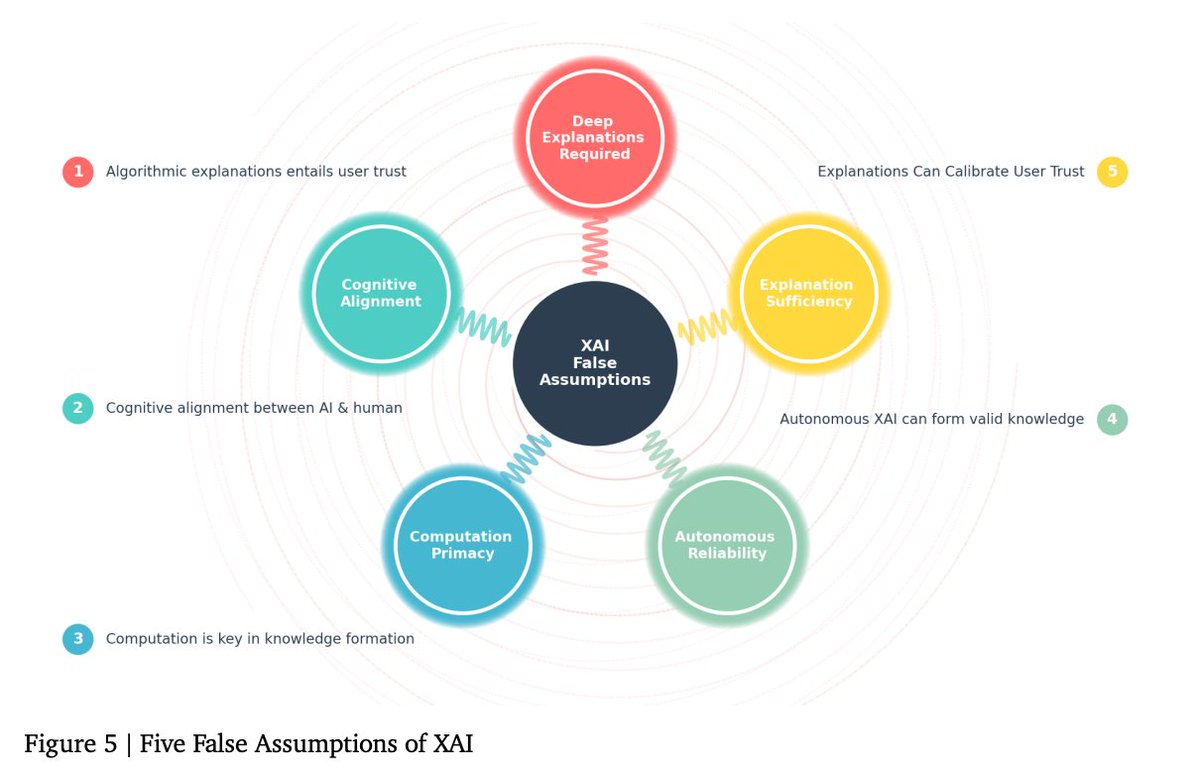
1
2
6
470
Nice to see this benchmark dataset on LLM-supported rare disease diagnosis and confirmation.
paper: thelancet.com/journals/landi…
github: github.com/zhao-zy15/RareAre…
#healourskin #raredisease
2
1
2
194
I disagree with the statement "we do not expect human beings to hold within themselves multiple different sets of moral beliefs and values" that appears in a paper about LLM moral reasoning that was published yesterday.
nature.com/articles/s41586-0…
1
3
193
Kush Varshney कुश वार्ष्णेय retweeted

We have extended our ICLR workshop deadline to Feb 5th! #AFAA2026 Submit your work on fairness across alignment & agentic AI systems. We also continue to accept broad work on fairness. CfP: afciworkshop.org/call-for-pa…

🚨 Deadline Extended to Feb 5 (AoE)!
CFP still OPEN for the #AFAA2026 Workshop at @iclr_conf — on fairness across alignment & agentic AI systems.
Full & tiny papers welcome • Interdisciplinary work encouraged!
🔗 afciworkshop.org
#ICLR2026 #AFAA2026
2
1
453
Kush Varshney कुश वार्ष्णेय retweeted

4th graders welcomed RB parent Kush R. Varshney, an IBM Fellow who volunteered his time to explain how AI works—its benefits and pitfalls—with a tailored presentation featuring our school song and a Charlotte’s Web excerpt. Grateful for his generosity & expertise! #WeAreChappaqua

1
3
220
Kush Varshney कुश वार्ष्णेय retweeted

Grateful to have co-hosted the Trusted AI Symposium yesterday. Left with so many new ideas from the posters, panels, and lectures. 🧠 Big thanks to our keynote speakers, panelists, and staff for driving the conversation on trust in AI.🤝 #TrustedAISymposium2026




1
3
15
1,386
Kush Varshney कुश वार्ष्णेय retweeted

9 Dec 2025
How transparent are major AI companies?
We answer this question each year in the annual Foundation Model Transparency Index.
While the AI industry as a whole is quite opaque, we found a huge spread.
@IBM scored a 95/100 while @xai scored 14/100.
So what's going on? 🧵

15
20
66
59,989

As a follow up from the 2025 AAAI report on the future of AI research, we are organizing several deep dives into some of the topics covered by the report. The next webinar will be on December 11th at 1pm Eastern time and includes AI experts who will discuss AI Factuality and Trustworthiness.
Register here: aaaiforms.wufoo.com/forms/q4…
Topics include: Understanding Factuality, Beyond Accuracy, and
Practical Solutions.
Our Expert Panel:
Oren Etzioni, Founder TrueMedia.org, Professor Emeritus University of Washington
Henry Kautz, Professor of Computer Science, University of Virginia at Charlottesville
Kush Varshney, IBM Fellow and Co-Director IBM Science for Social Good
Moderated by: Francesca Rossi, AAAI past president, IBM Fellow and AI Ethics Global Leader.
Whether you're an AI professional, researcher, or simply curious about the future of AI, this discussion will offer valuable insights into one of technology's most consequential frontiers.
3
14
2,079