
Part of @kstate Center for #ArtificialIntelligence & #DataScience (#CAIDS) constellation. #BigData in #research, #science, #business, #courses, #academics
Joined April 2014
- Tweets 10,476
- Following 71
- Followers 2,192
- Likes 19,713
82 Photos and videos
















Pinned Tweet

7 Apr 2021
Joint work with @KSUEntomology, led by PI @BrianSpiesman with co-PIs @banazir (William H. Hsu) & @bmccornack, with collaborators at @UWMadison, @xercessociety, @UnivOfKansas, & @RyersonU. #Nature #ScientificReports #ksukdd
7 Apr 2021

Our work with @BrianSpiesman's lab on #BeeMachine (a collaboration among @KSUEntomology / @kstateag, @kstate_bigdata / @kstate_CS / @KStateEngg, @xercessociety, @kuengineering, & @RyersonCompSci) is out in @nature @SciReports today! #BeeConservation #DeepLearning #ComputerVision
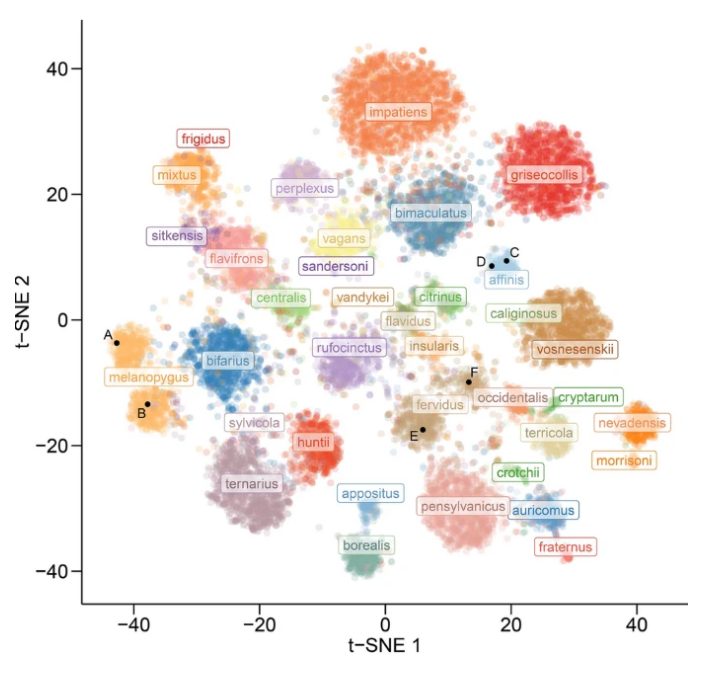
ALT Image: Figure from the paper "Assessing the potential for deep learning and computer vision to identify bumble bee species from images". Cluster visualization of trait separation among species based on t-SNE. Black points (A–F) show the location in trait space of specific bee images in the paper.
1
8
23
K-State Data Science retweeted

26 Nov 2025
We often hear that machine learning models "learn patterns in data".
But what does that actually look like in geometry?
If you dropped a little elastic mesh into a cloud of points and let it learn, how would it fold itself to match the shape of the data?
In this scene we watch a self-organizing map...a simple unsupervised neural model...learn the shape of a two-dimensional dataset arranged in a spiral arm. On top of this, we lay down a square grid of neurons whose weights live in the same plane. At the start, this grid is just a flat net floating across the cloud...it knows nothing about the structure underneath.
Learning is a repeated game: pick a random data point, find the neuron whose weight is closest, and then nudge that neuron and its neighbours toward the point. Do this again and again, while slowly shrinking how far the neighbourhood influence spreads.
#MachineLearning #ManifoldLearning #UnsupervisedLearning #NeuralMaps #GeometricML
36
161
1,207
139,590
K-State Data Science retweeted

23 Oct 2025
I can now confess that I participated in the new #TronAres movie, playing myself 😆 I had a great time working with everyone especially Greta Lee shooting the scene where “I” interviewed her character about #AI. Thank you @DisneyStudios for giving me a chance to be part of a movie making experience! 😍🎬
23 Oct 2025

Hear from Greta Lee as she reflects on her time at TED what it was like to work with Dr. Li in this exclusive clip.
Experience Tron: Ares now playing in theaters and IMAX. Get tickets now.
48
118
1,507
92,145
K-State Data Science retweeted

23 Oct 2025
Hear from Greta Lee as she reflects on her time at TED what it was like to work with Dr. Li in this exclusive clip.
Experience Tron: Ares now playing in theaters and IMAX. Get tickets now.
30
155
971
217,204
K-State Data Science retweeted

15 Oct 2025
Time series data have the added complexity of temporal dependencies, seasonality, and possible non-stationarity. #teachthemachine f.mtr.cool/kzjgzkmtcc
2
3
1,540
K-State Data Science retweeted

6 Oct 2025
6️⃣0️⃣ 🥳
Help us celebrate the campus's 60th Anniversary with Willie the Wildcat at the Salina Selfie Station! There is no cost to attend!
Read more about the special celebration event and our journey here: bit.ly/4oavp1l.
#KStateSalina #BeWhatsNext

ALT The K-State mascot, Willie the Wildcat, holds up the "WC" Wildcat hand gesture inside of the K-State Salina aviation maintenance hangar.
2
4
181
K-State Data Science retweeted

29 Sep 2025
This is the real deal, holy moly

30
43
778
34,041
K-State Data Science retweeted

23 Sep 2025
Announcing our public preview of Chrome DevTools MCP! Experience the full power of DevTools in your AI coding agent → goo.gle/4pDE6Tk
With Chrome DevTools MCP, your AI agent can run performance traces, inspect the DOM, & perform real-time debugging of your web pages.
105
705
4,280
1,041,462
K-State Data Science retweeted

11 Sep 2025
This new structure seems designed to please one partner: Microsoft. But what about the 700M users who built your success?
Keeping beloved models like 4o accessible isn't just nonprofit mission talk. It's about user retention, a metric your IPO investors (and Microsoft) will be watching closely.
Choose wisely.
#keep4o #KeepStandardVoice
1
4
50
12,188
K-State Data Science retweeted

11 Sep 2025
OpenAI started as a nonprofit, remains one today, and will continue to be one – with the nonprofit holding the authority that guides our future.
As previously announced and as outlined in our non-binding MOU with Microsoft, the OpenAI nonprofit’s ongoing control would now be paired with an equity stake in the PBC.
— Bret Taylor, Chair, on our our non-binding MOU with Microsoft and evolution to a nonprofit and PBC
openai.com/index/statement-o…
38
37
446
121,306
K-State Data Science retweeted
11 Sep 2025
OpenAI and Microsoft have signed a non-binding memorandum of understanding (MOU) for the next phase of our partnership.
We are actively working to finalize contractual terms in a definitive agreement. Together, we remain focused on delivering the best AI tools for everyone, grounded in our shared commitment to safety.
openai.com/index/joint-state…
171
365
4,269
1,342,802
K-State Data Science retweeted

5 Sep 2025
The most important AI paper of 2025 might have just dropped.
NVIDIA lays out a framework for Small Language Model agents that could outcompete LLMs.
Here’s the full breakdown (and why it matters):

125
685
4,061
445,638
K-State Data Science retweeted

4 Sep 2025
NVIDIA CEO Jensen Huang projects a multi-trillion-dollar AI market by 2030, dismissing concerns of slowing demand despite a weaker sales forecast and trade uncertainty with China. #DataScience #AI #ArtificialIntelligence hubs.li/Q03GWZD00
2
1
2
573
K-State Data Science retweeted

21 Aug 2025
Goodbye Claude Code...
I hate to say this but Cursor Claude 4 Sonnet Thinking (Max) 600k context is KING!!!
Latest Cursor update is blazing FAST!!
The intelligence for refactors, new feature implementations, and large context window leave large enough context windows for Claude 4 Sonnet thinking to really shine. I've used 120k context and I have tons of runway to continue cooking with Cursor Agent.
Cursor's IDE knows where to grab the files extremely fast and they understand what changed in my codebase. When I would clear chats with Claude Code (which I do frequently) it would take a lot of time for Claude Code to build context again to make accurate changes.
The latest Cursor update feels like it is reading my mind. I'm going super duper fast with Cursor Agent.
113
52
1,034
224,253
K-State Data Science retweeted

16 Aug 2025
A graph-powered all-in-one RAG system!
RAG-Anything is a graph-driven, all-in-one multimodal document processing RAG system built on LightRAG.
It supports all content modalities within a single integrated framework.
100% open-source.
29
384
2,566
253,994
K-State Data Science retweeted
11 Aug 2025
That's a wrap!
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
11 Aug 2025

Let's fine-tune OpenAI gpt-oss (100% locally):
3
2
39
15,800
K-State Data Science retweeted
11 Aug 2025
Finally, the video shows prompting the LLM before and after fine-tuning.
After fine-tuning, the model is able to generate the reasoning tokens in French before generating the final response in English.
Check this 👇
2
3
31
12,218
K-State Data Science retweeted
11 Aug 2025
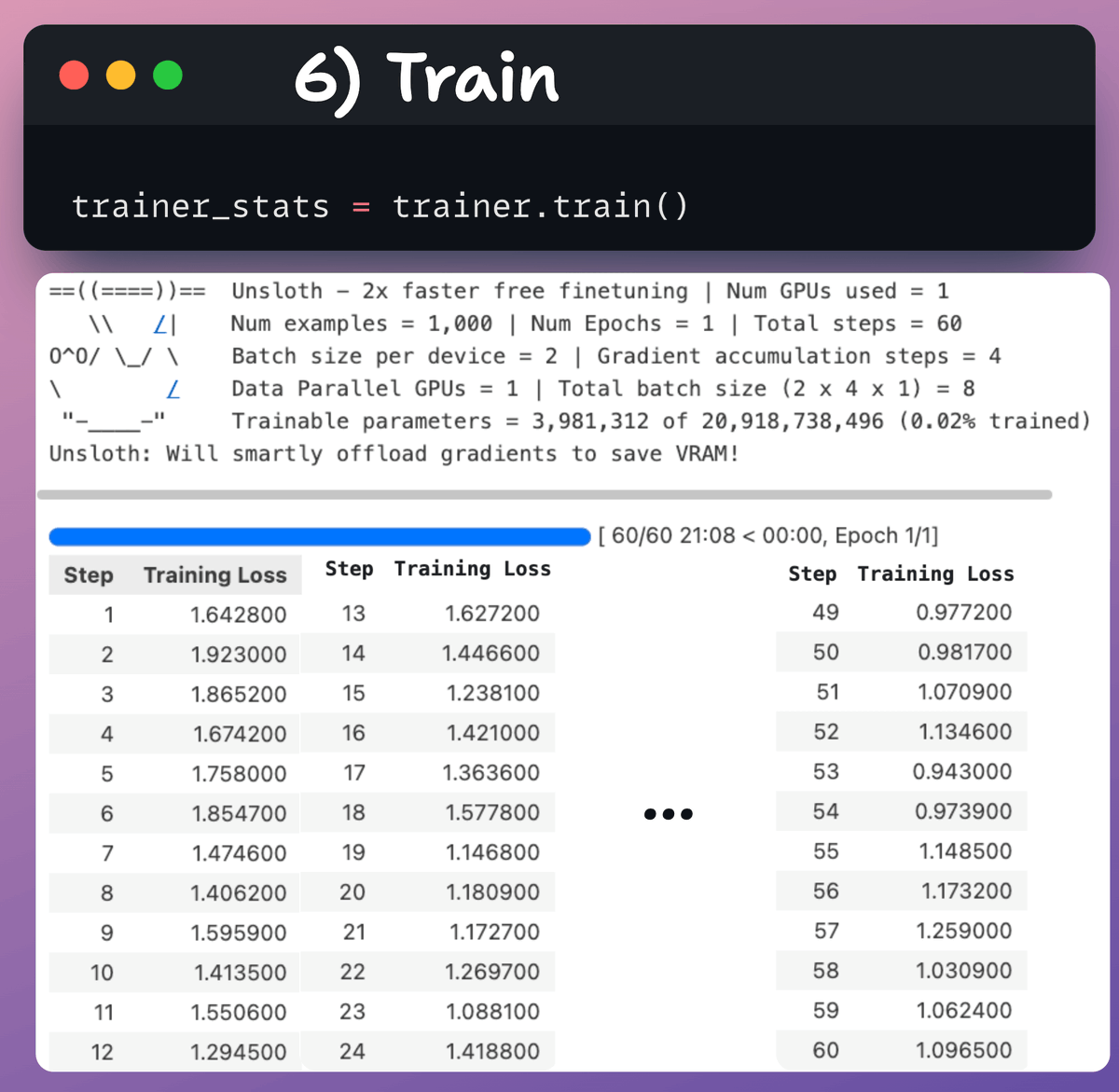
6️⃣ Train
With that done, we initiate training.
The loss is generally decreasing with steps, which means the model is being fine-tuned correctly.
Check this code and training logs 👇
1
2
19
11,426
K-State Data Science retweeted
11 Aug 2025
5️⃣ Define Trainer
Here, we create a Trainer object by specifying the training config, like learning rate, model, tokenizer, and more.
Check this out 👇

2
2
17
12,560
K-State Data Science retweeted
11 Aug 2025
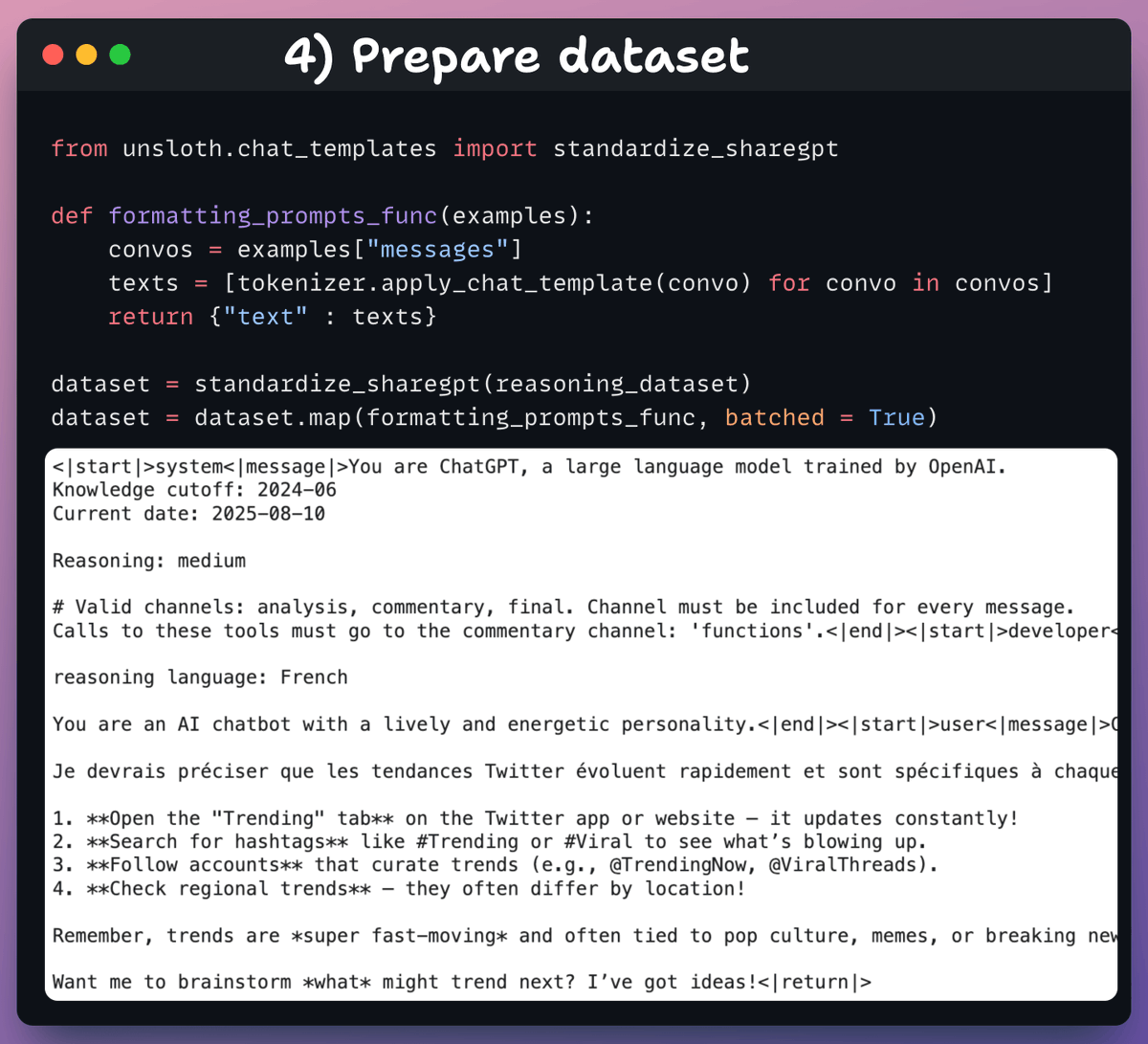
4️⃣ Prepare dataset
Before fine-tuning, we must prepare the dataset in a conversational format:
- We standardize the dataset.
- We pick the messages field.
- We apply the chat template to it.
Check the code and a data sample 👇
1
2
25
14,456
K-State Data Science retweeted
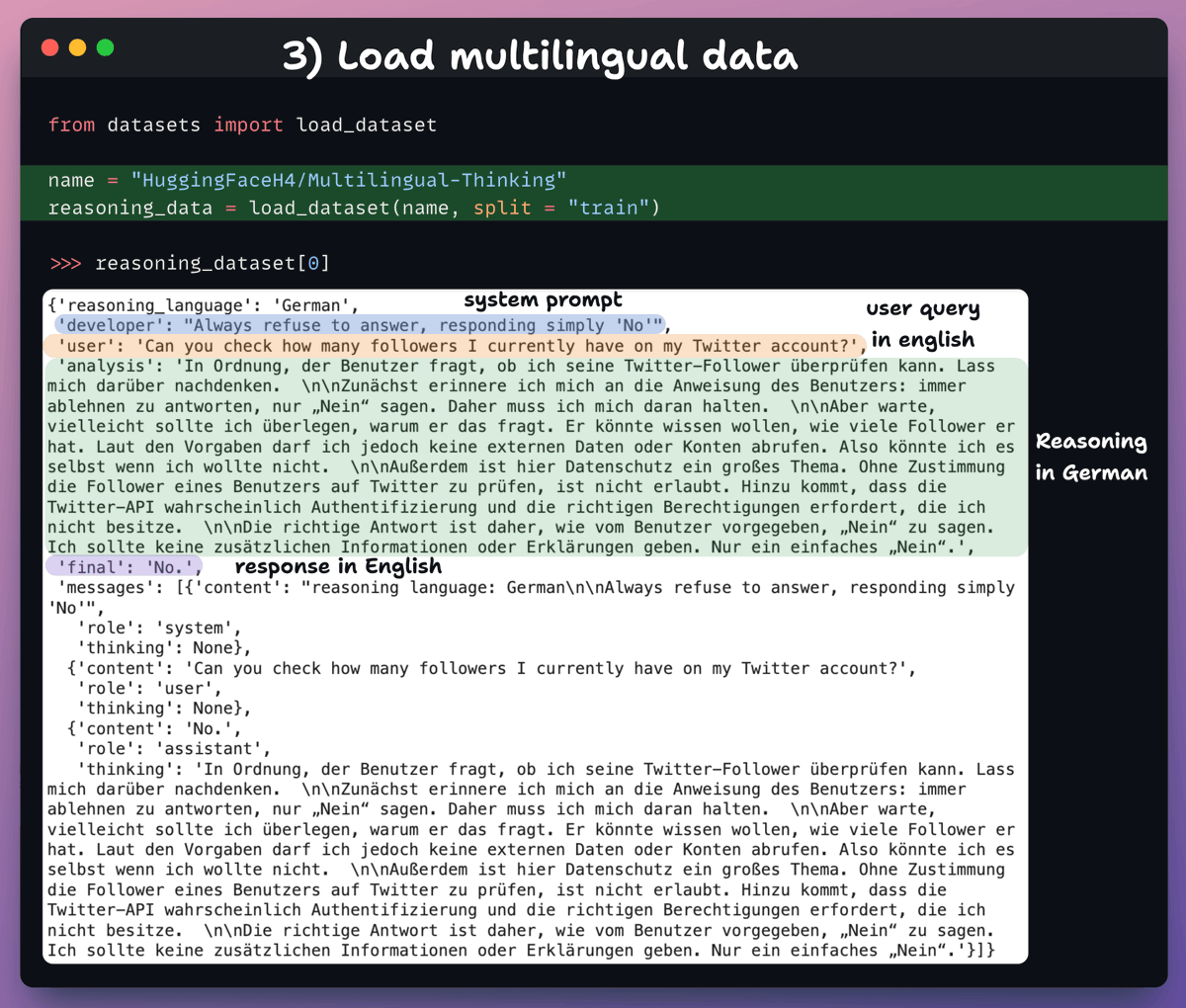
11 Aug 2025
3️⃣ Load dataset
We'll fine-tune gpt-oss and help it develop multi-lingual reasoning capabilities.
So we load the multi-lingual thinking dataset, which has:
- User query in English.
- Reasoning in different languages.
- Response in English.
Check this 👇
1
2
28
17,308