
Joined January 2023
- Tweets 4,165
- Following 293
- Followers 155,206
- Likes 9,485
1,857 Photos and videos













Pinned Tweet

Mar 14
I’ll be speaking at ACCU (C ) on Sea in June and sharing a new library!
C 26 is bringing us compile-time reflection, but what if we built on these capabilities to create new runtime reflection techniques?
Find out during my talk:
CallMeMaybe: Building Modern Runtime Reflection via C 26

19
25
648
152,637
I don’t care what people say, Modern C is starting to get really cool.
For example, C 26 compile-time reflection uses this neat little trick to represent heterogeneous data with a single, scalar value (std::meta::info).
This value is *technically* an ID into the compiler's AST. The neat part is you can steal this technique for representing runtime entities as well!
Next Thursday I’m giving a talk in the UK at ACCU on Sea, where I'll show how to use the static metafunctions to help build a homogeneous runtime reflection registry.
34
28
751
24,946
Jun 12
I’m convinced that old games feel “hard” because modern emulators have like 30 layers of abstraction between the input and the screen.
Today you’ve got controllers going through bluetooth driver stacks, on general purpose operating systems, with all sorts of thread coordination, GPU APIs, not to mention display latency…
Much easier for the brain to learn when the original hardware is extremely deterministic!

168
81
2,102
125,225
Jun 12
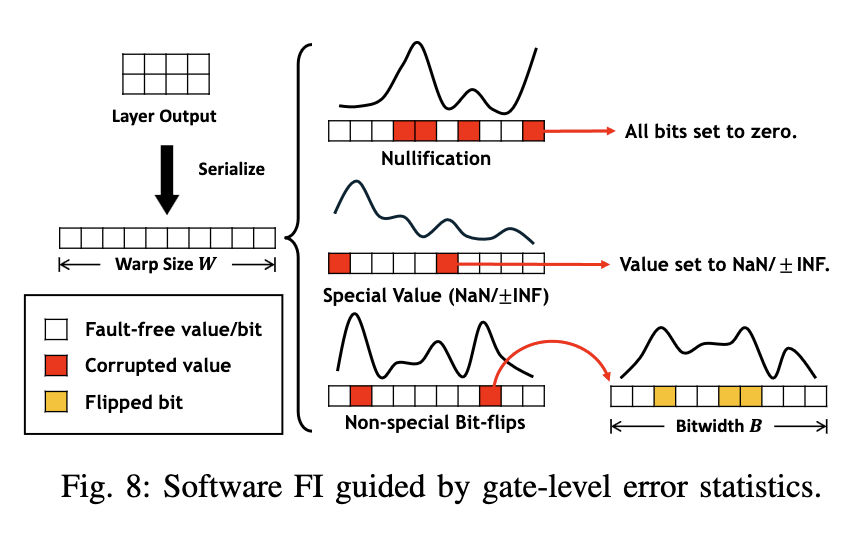
Most computer faults aren’t clean, single bit flips.
In GPUs especially, ~60% of errors are multi-bit events!
This makes a lot of sense when you think about the pipeline. If you get a corruption early enough, the datapath is way more likely to affect the entire warp.
Software Fault Injectors mostly still assume single flips at the destination…which unfortunately isn’t what happens in the real world!
16
49
1,142
35,525
Jun 12
There’s an interesting paper here on GPU silent data corruption, check it out:
arxiv.org/abs/2605.04213
2
5
148
7,995
Jun 11
it's funny how much people care about 4K when the majority of actual movie theaters are barely above 1080p
519
231
14,853
664,072
Jun 8
most non-C developers are just users playing inside a C dev’s program.
164
132
3,282
114,544
Jun 6
It’s no secret that I’m a big fan of the International Obfuscated C Code Contest!
Excited to watch winners streaming at 11AM PDT today (06/06).
It always brings out an interesting blend of compiler nerds, programming language theorists, and researchers.
Give it a watch, it’s the longest-running programming competition in the world!

33
89
2,119
64,898
Jun 5
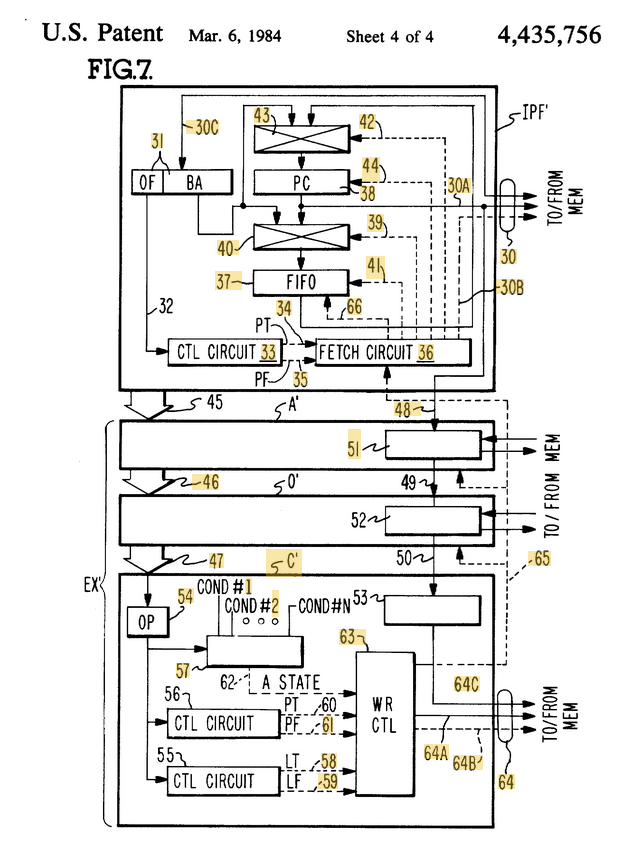
I love looking at old crazy ideas in expired computer patents.
Modern CPU Branch Predictors are invisible. You, as a dev, can’t really see *what* paths the CPU is guessing…it’s all a bunch of AMD/Intel/Apple secret sauce.
For a brief moment in the 80s, there was this wacky proposition of storing the prediction IN the opcodes themselves.
If you don’t understand why that’s insane, bear with me for a second.
Imagine your binary has an ordinary if statement, that compiles down to a jump if equal instruction (JE). You run your program, and let’s say the if statement evaluates as true 99% of the time.
This patent suggested the CPU would then EDIT the running binary, in memory, to a new “JE-probably-taken” instruction, which upon subsequent execution would just assume true.
That might not sound that wild, until you realize the entire structure relies on the branch predictor itself being self modifying code, which you’d then be able to see / evaluate with a debugger! In other words, you’d have a compiled binary, that would then radically change at runtime where you could see all the hints!
The idea ended up not working; a few years later CPU’s started gaining instruction caches, and the round trip back and forth to rewrite the binary in memory would be much too slow. Weird to think about though, to me it feels like it would have been kinda JVM-y / V8ish but at a much much lower level of abstraction.
83
169
2,510
91,788
Jun 5
ti84 game programming about to enter a new golden era


102
75
2,718
72,817
Jun 4
keith and I are ready to watch the C documentary premiere
(noon PST today)
are you?
96
56
4,232
106,891
Jun 4
better put this here before someone thinks they are being original
76
29
4,109
46,921
Jun 3
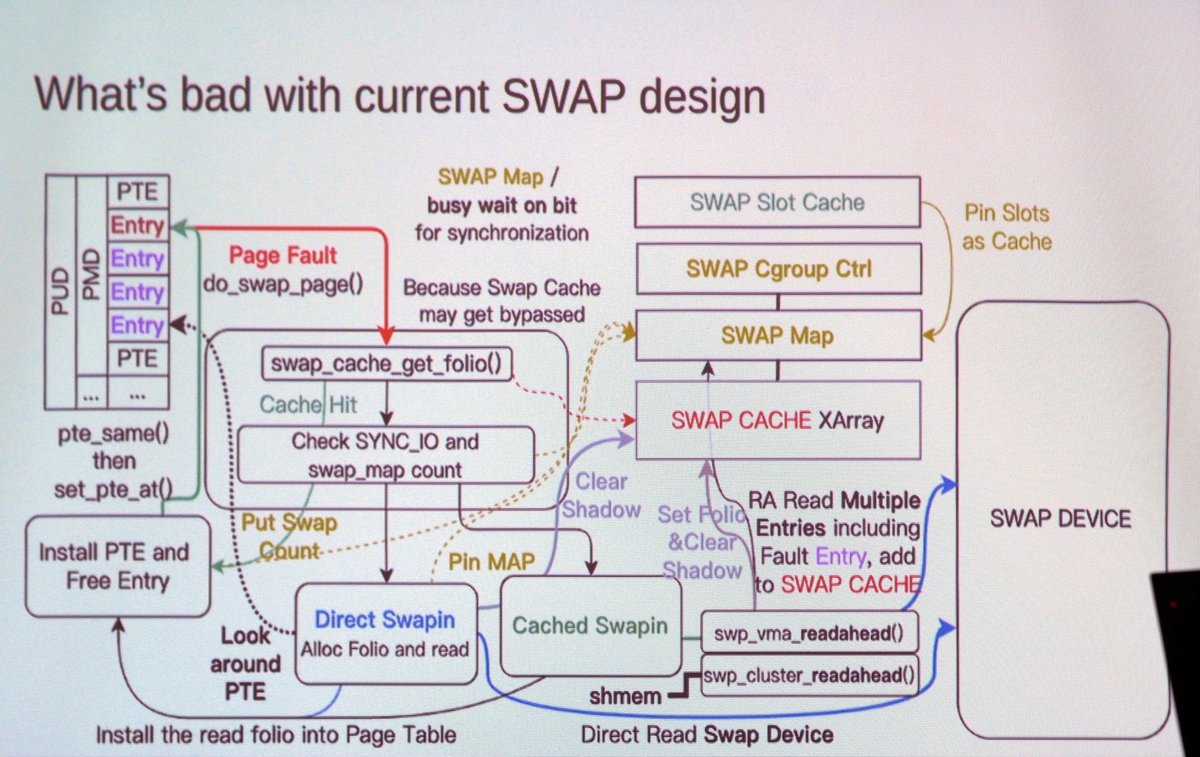
Everyone tends to think of swapfiles being disk based.
In reality, swapping to RAM is exponentially more popular.
If you have a traditional model of memory in your head, this makes NO SENSE. Swap is that thing we use when the system runs out of real ram right?
You know, RAM fills up, swap out to SSD to give the OS some breathing room. Why (and how?) would you swap to memory…very thing that’s full?
Well, Modern CPUs are ridiculously fast at compression, especially with something light like lz4. Zswap intercepts old pages, quickly compresses them, and then crams them back into system RAM. If you’re lucky, you might be able to fit ~3-4 compressed pages into the space of 1 traditional page.
Of course, this also has the benefit of not prematurely wearing out your SSD.
Mobile has done this for *years*, I know Android specifically has used this for a decade . Regular Linux is catching up, Fedora uses zram by default now. The NT kernel (windows) also has their own implementation of in-memory compression, you can see it in task manager quite easily!
Anyway, it’s a fun trick used everywhere that few realize. Towards the future, I wouldn’t be surprised if inline, accelerated LZ4 starts showing up in the majority of CXL controllers.
70
134
1,838
67,091
Jun 1
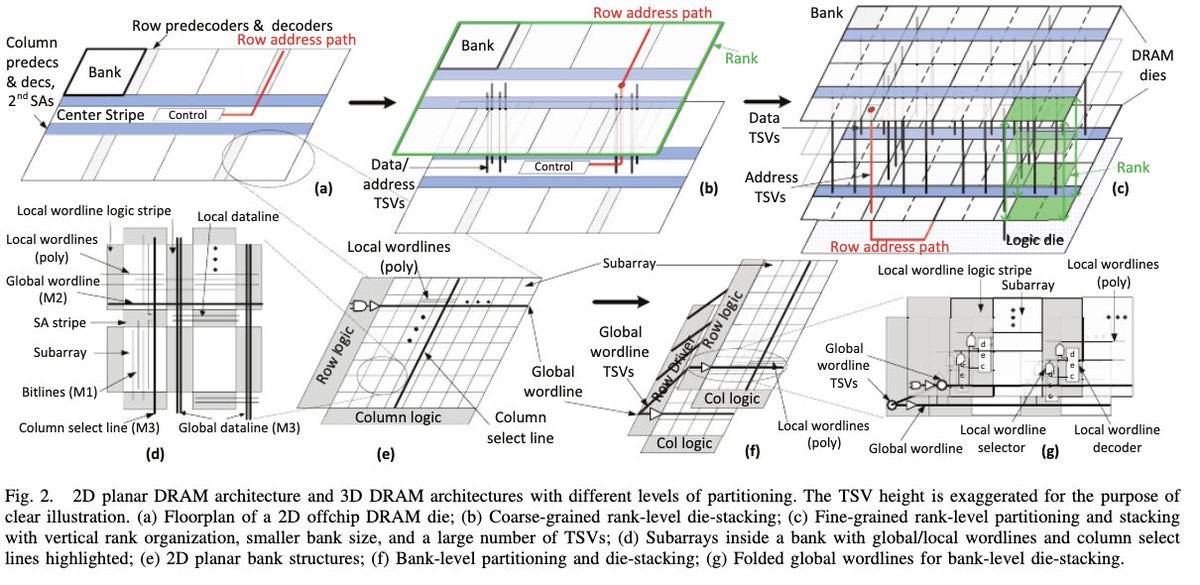
RAM exists as a 1-dimensional space. For programming…that’s kind of irritating.
All the important math happens in 2D arrays.
It’s simple(ish) to compress a higher level space into a single dimension (most languages today are row-major), but there’s a funny quirk.
At the *physical* DRAM layer, the actual bits *are* stored in a 2D array, rows and columns. (…well, when you add up all the layers, it’s more like a hierarchy of 2D arrays, but you get my point).
If this information was directly exposed to you…gosh there are all sorts of neat tricks you can get away with!
Unfortunately, keeping memory addresses in a 1-D space makes things much simpler from the OS perspective for memory management, not to mention code portability. There are nasty security problems too...certainly some valid reasons for keeping physical structure hidden.
Yet, think of how much of performance engineering / memory locality work could be shortcutted if it were trivial to understand the exact physical layout of how your arrays were stored!

79
157
2,476
91,301
Jun 1
I (sorta) did this with my latency-reducing project Tailslayer.
If you spend enough work making microbenchmarks, you can start to reverse engineer that 1-D array, finding some of the hidden 2-D structure…which let me use software tricks to avoid physical penalties (refresh cycles).
GPUs have much nicer primitives / more levers in the memory hierarchy to work with (tiles and such). Interesting to think about what programming would look like if regular (non-gpu) DRAM had access patterns closer to GPUs.
15
4
276
12,979
May 30
Quite surprising the amount of international viewers I get!
Apparently a Chinese dub / fan reupload of one of my videos has 90k views on Bilibili.
I wonder if there are low(ish) effort ways I could make the content easier to understand for non-english speakers. I’m not large enough (yet) to pay for full individual dubs/some big multilingual operation, but I wonder if anyone has ideas.
The largest international outliers in my stats seem to be Germany (although that should be mostly fine with english…I think), China, Brazil (Portuguese?).
Oh, and I’ve seem some reuploads on VK (Russia) too.

125
22
1,361
73,760
May 29
How aware are modern compilers of exact microarchitectural layouts?
Quite a lot…in one very specific way.
Intel x86 is *not* the same as AMD x86.
Sure…it’s the “same ISA” in the broadest sense, but the individual instructions often take different numbers of cycles.
You want to stall as little as possible, so the order your instructions are arranged is somewhat important. Technically, something like “AMD Zen 3” ordering on an Intel Skylake is sub-optimal.
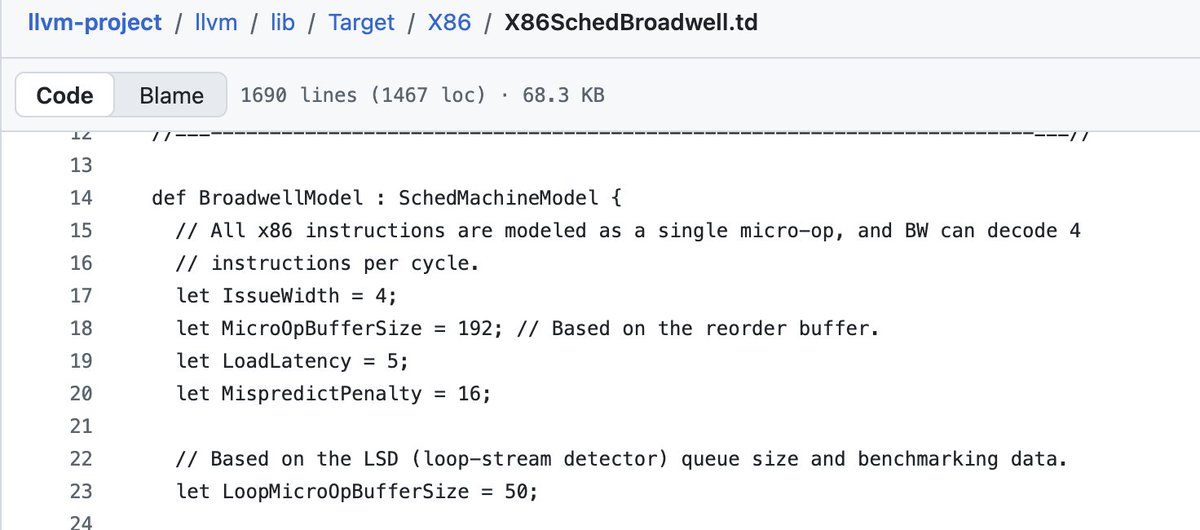
If you look at LLVM, you’ll notice these X86Sched*.td (TableGen) files. Just about every x86 CPU generation has their own version.
It defines things like ROB Size, issue width, and misprediction penalties (in terms of cycles). What’s fascinating is how much of this is “guessed” (reverse-engineered) vs “revealed” by the hardware vendors.
From what I understand, Intel/AMD/etc will *sometimes* lend a helping hand / give some hints…but less than you’d expect.
It’s a very weird situation when you think about it. I assume vendors are tight-lipped about exact latencies for competitive secrecy…yet those are the exact things you’d need to know to extract the most performance out of your compiler!
If anyone knows other reasons for the secrecy, I’d love to hear it!

62
112
1,678
78,468
May 29
Before you get the pitchforks, yes, I’m aware most big modern CPUs cores are OoO and will reorder the instructions at runtime.
But! Reorder buffers aren’t infinitely large, plus iirc llvm also uses these scheduling tablegen files for higher-level optimization passes as well, so there is indeed a point to the madness!
8
8
236
11,961