
Joined March 2021
- Tweets 467
- Following 711
- Followers 6,004
- Likes 772
85 Photos and videos









Mar 8
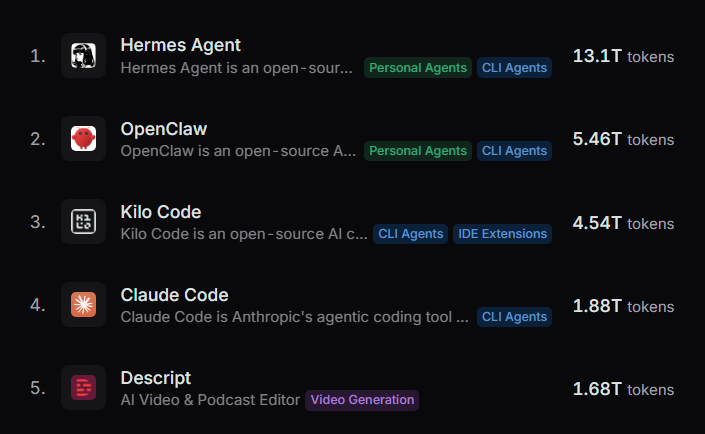
In November 2023, Yann LeCun, Thomas Wolf and others from Meta and Huggingface created a benchmark called GAIA, which described itself as: "A benchmark for General AI Assistants that, if solved, would represent a milestone in AI research." Most of the problem solutions were kept private, not released online.
It proposed 466 "real-world questions that require a set of fundamental abilities such as reasoning, multi-modality handling, web browsing, and generally tool-use proficiency."
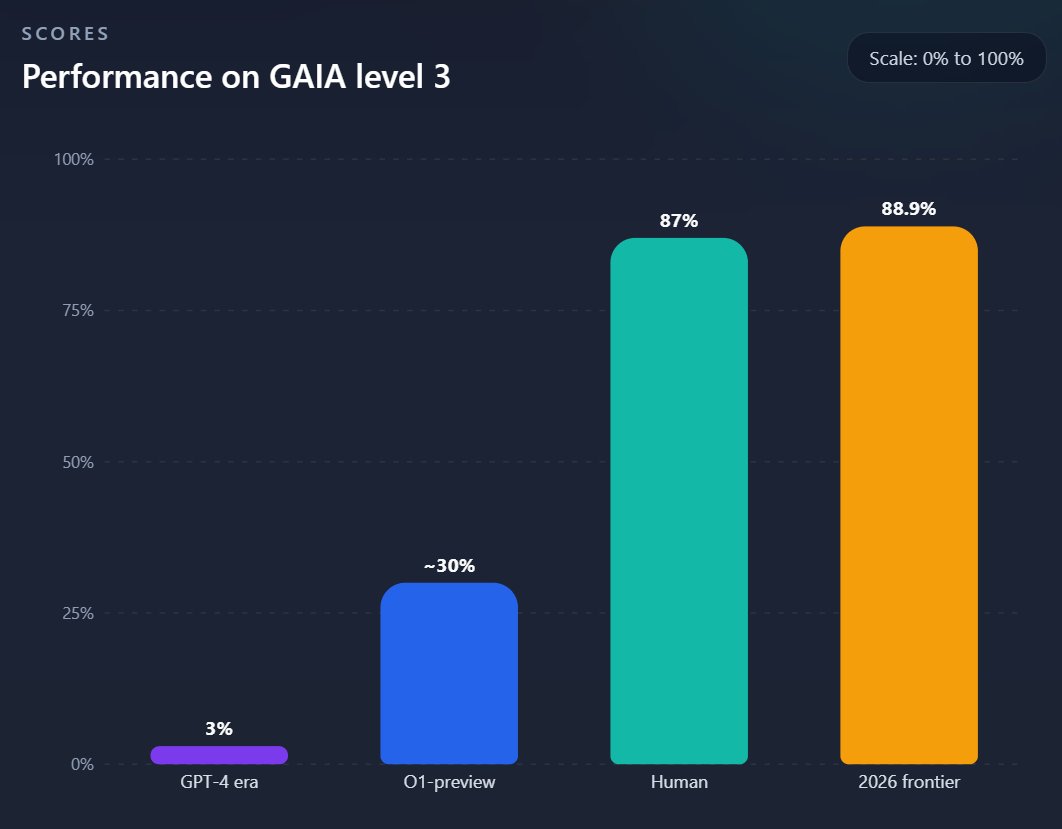
On the hardest level, the average human score was 87%, while the leading systems scored less than 3%. 10 months later OpenAI released O1-preview, reaching ~30% on that level.
Now in 2026 the human baseline for the hardest level has officially been surpassed, the best agent systems are now scoring 88.9% on GAIAs hardest level (level 3).
25
58
797
78,756
Mar 8
The current highest level 3 score was achieved by Nvidia, leveraging a multi-agent system that includes Nvidias own tool orchestrator model. It scores 89.8% on Lvl 3 (even higher than the 88.9% typo I wrote above)
The public leaderboard can be seen here: huggingface.co/spaces/gaia-b…
1
81
6,506
Feb 27
This is the best AI-generated short film esque media I’ve seen thus far. Not just visually, but actual storytelling to go with it too.

1
5
689
Feb 21
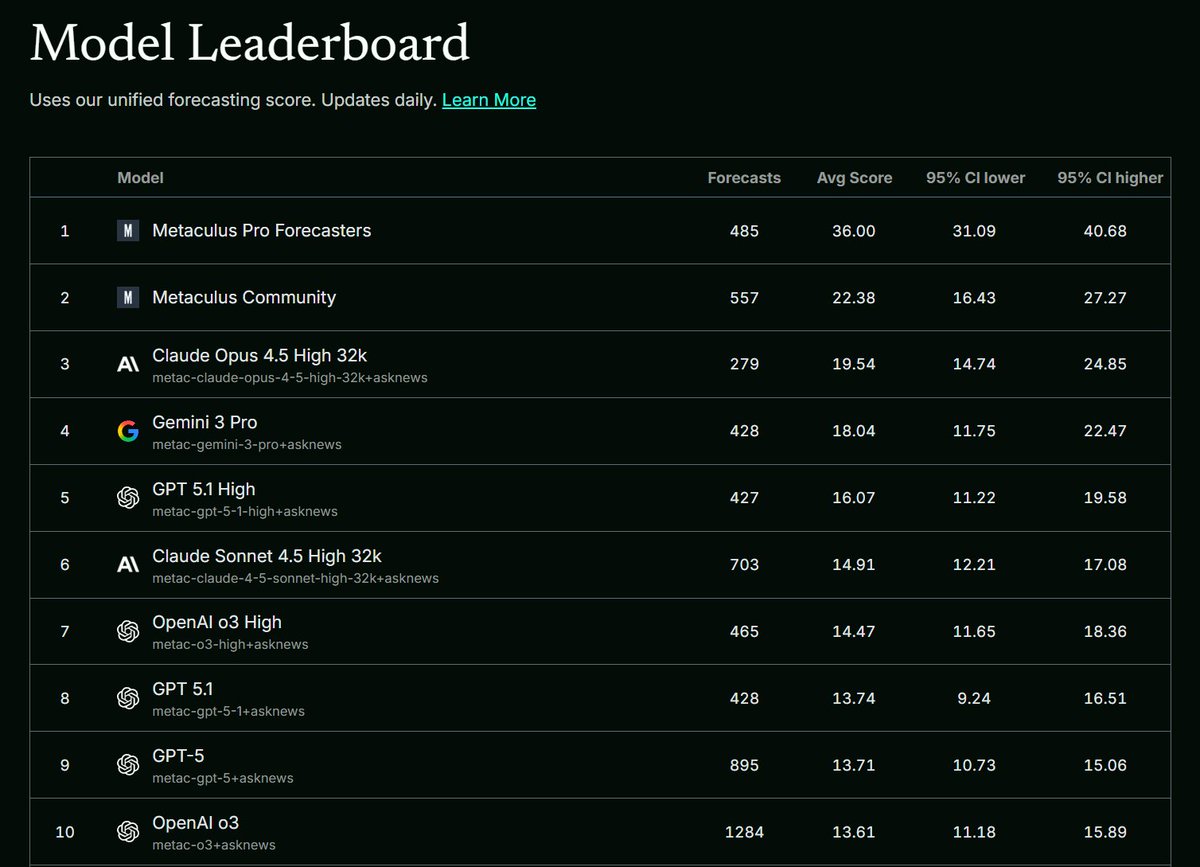
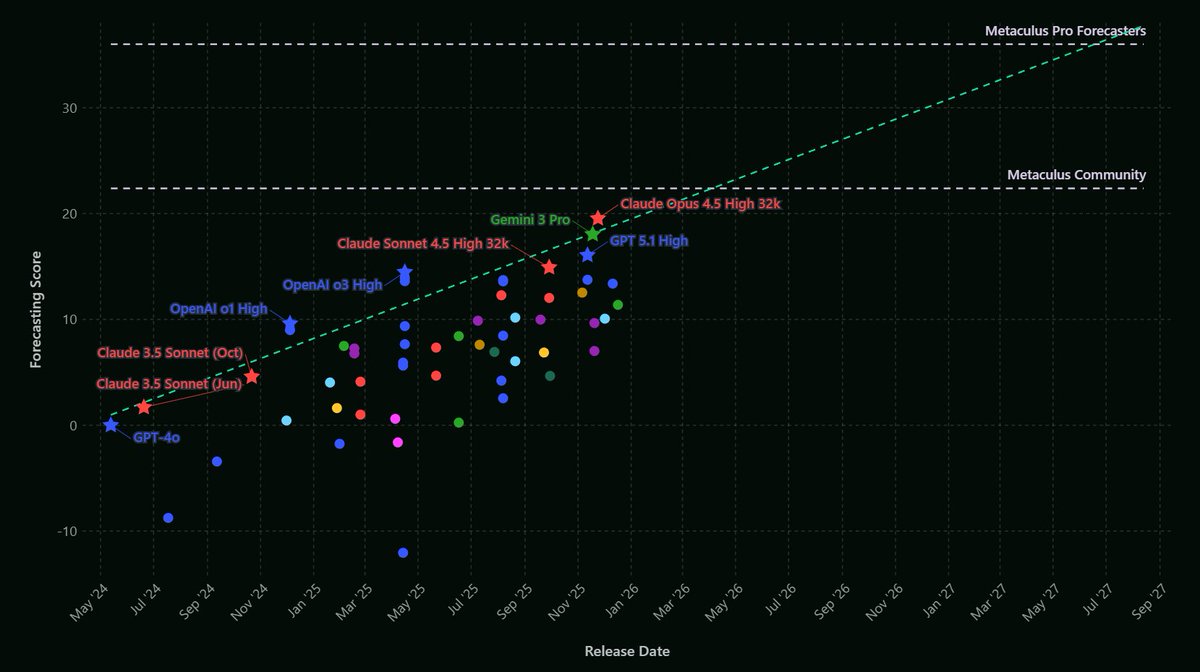
It seems like models are on track to surpass pro forecasters by EOY 2027, unless of course pro forecasters themselves start becoming significantly more accurate by leveraging AI, or world events become more unpredictable in ways that are disproportionately disadvantageous to AI.
2
3
15
1,091
Feb 21
A common type of joke/argument people will make against this: "My 2 year old is triple the weight compared to when he was born, therefore he will be 2,000 pounds at the age of 32!"
There are two fundamental differences I can think of that make this argument different from FutureEval (this benchmark) and METR time-horizons:
- It's fitting a trend to just 2 data points, as opposed to the dozens of data points that exist for METR time-horizons, and FutureEval.
- It's extrapolating several multiples beyond the span of the existing observational period (taking 2 years of baby growth to extrapolate out way beyond just an extra 2 years into the future), as opposed to METR time-horizons which has ~6 years of observational data and is used to make conversation-worthy predictions, which are often significantly less than 6 years of extrapolation into the future, similarly FutureEval here is extrapolating out into the future by an amount that is ~equal and less than its existing observational span.
1
2
429
Jan 19
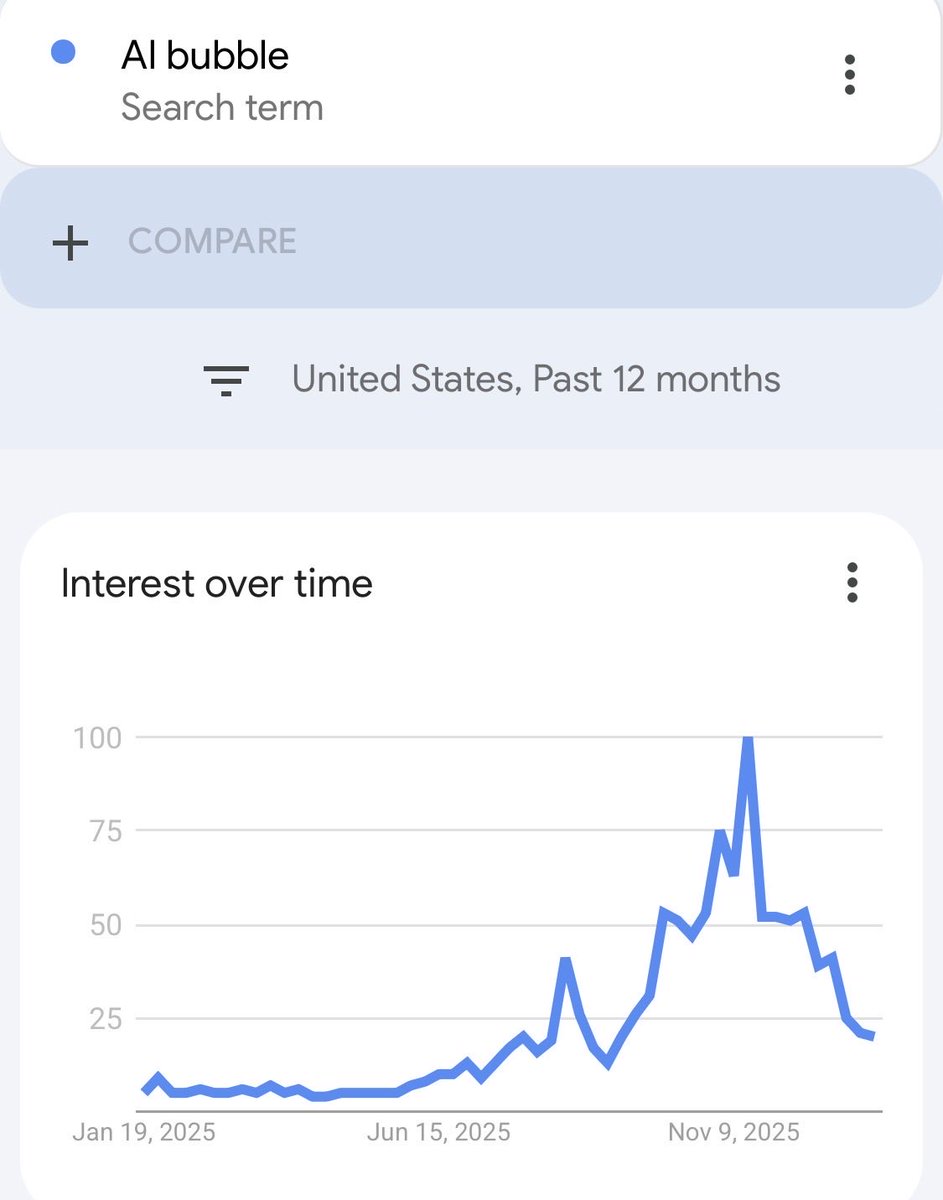
Back in October I half-jokingly told some friends that the world is in an “AI bubble”-bubble, or in other words, a fast growing meta-bubble of people searching and claiming that we’re in an “AI bubble”. Now it seems like this meta-bubble has burst after peaking in November 2025.
1
1
12
933
Jan 19
Both the US and worldwide searches for “AI bubble” on google are now ~76% lower than the peak in November, which funnily enough is a very similar decrease to the Dotcom crash which was a ~78% drop from peak to trough.
1
363
25 Nov 2025
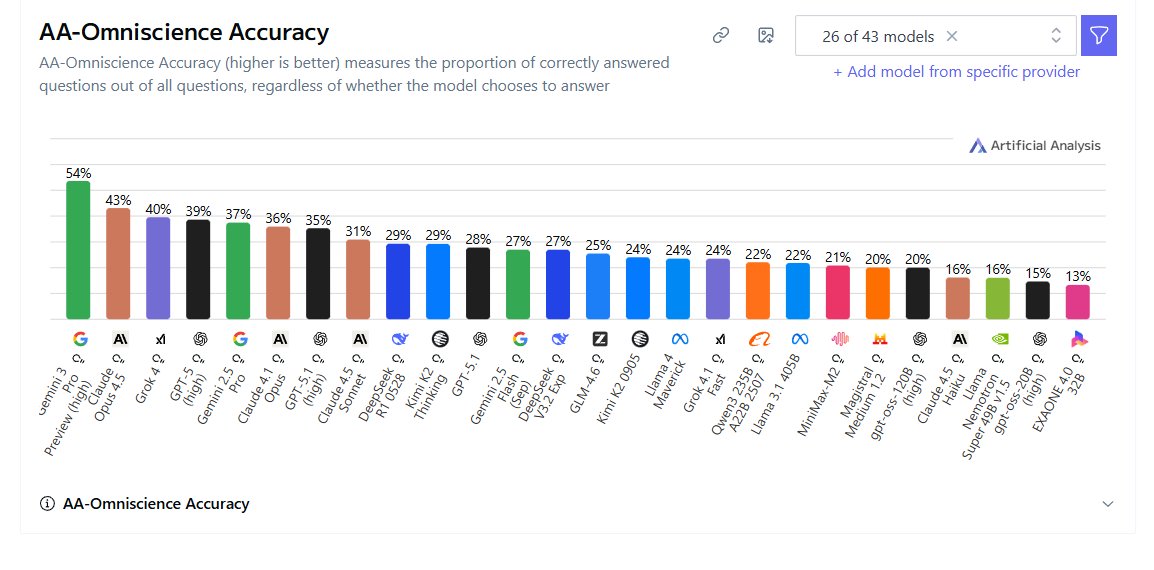
We seem to be moving through an important milestone where models can be demonstrated to refuse or say "I don't know" more often than they give wrong answers (as shown by hallucination rate below 50%) while simultaneously being ~frontier level in the amount of correct answers.
2
3
7
789
25 Nov 2025
This probably depends on the distribution of questions you're testing on, but this benchmark seems quite diverse and atleast difficult enough to the point of the highest scoring models only giving correct answers to ~50% of its 6,000 questions across 42 categories.
1
353
25 Nov 2025
While the results might look a bit different for other distributions, I suspect that frontier models over the next ~18 months will start to approach and cross the same milestone in most other useful distributions of questions.
1
291
2 Oct 2025
A specialized scaffold for creating educational visualizations, I’m a bit surprised it’s able to even do this well with just scaffolding. The natural next step is for someone to train a dedicated model for this, and native audio plus sound fx too. It only gets better from here.
2 Oct 2025

Ever struggle to consume STEM content? As someone with ADHD, I did too—so I built STEMViz: an autonomous AI agent that turns complex topics into short, easy videos. Powered by Claude Sonnet 4.5, Gemini-Flash-2.5 & ElevenLabs.
👉 Example: Explain Neural Networks for beginners.
4
1,079
12 May 2025
This seems like one of the first unifications of the concept of spiking neural networks, persistent states, attention and adaptive compute, all in one model/“machine”. Great work from Sakana, I believe they’re one of the most under-rated openly publishing labs right now.
12 May 2025

Introducing Continuous Thought Machines
New Blog: sakana.ai/ctm/
Modern AI is powerful, but it’s still distinct from human-like flexible intelligence. We believe neural timing is key. Our Continuous Thought Machine is built from the ground up to use neural dynamics as a powerful representation for intelligence.
Thought takes time, and reasoning is a process. Biological brains inspire us with their complex neural activity, where neural timing is critical to intelligence. We’re exploring how to bring that power to AI. The Continuous Thought Machine (CTM) incorporates neuron-level temporal processing and neural synchronization, moving beyond current AI limitations.
Our approach has two core innovations: (1) neuron-level temporal processing, where each neuron uses unique parameters to process a history of incoming signals for fine-grained temporal dynamics, and (2) neural synchronization, used as a direct latent representation to modulate data and produce outputs, encoding information directly in the timing of neural activity.
Learn more about our approach:
Interactive Report: pub.sakana.ai/ctm/
Full Paper: arxiv.org/abs/2505.05522
GitHub : github.com/SakanaAI/continuo…
2
9
78
7,515
6 May 2025
I think quarrels specifically on LLM consciousness are largely a red herring and often don’t end up with any conclusive answer that convinces either side.
The more interesting and practical discussion imo is; Whether it’s ten years, hundreds of years, or millennia from now, it seems inevitable (barring cataclysms) that humanity will eventually create something new that meets virtually any and every criterion of what we’d otherwise call advanced alien life. Along the way we’ll likely have to decide; What criterion do we deem as most important? What to do if there is a blurry spectrum along the way towards that criterion of being definitively advanced alien life or not? If/when/how we should integrate this alien life into our society, how to best prepare for continued future interactions of novel alien life? What differences (if any) we should treat such alien life when it’s from human origin versus non-human origin?
Doing such philosophizing and investigating into these questions now may prove useful for steering the future we desire.
1
4
1,006
19 Mar 2025
The recent time horizons paper by METR is great, but it only visualized tasks that models could complete with 50-80% accuracy. So I went through the paper, identified the average time horizon differences across the accuracy levels, and plotted the trends up to 99% accuracy below.
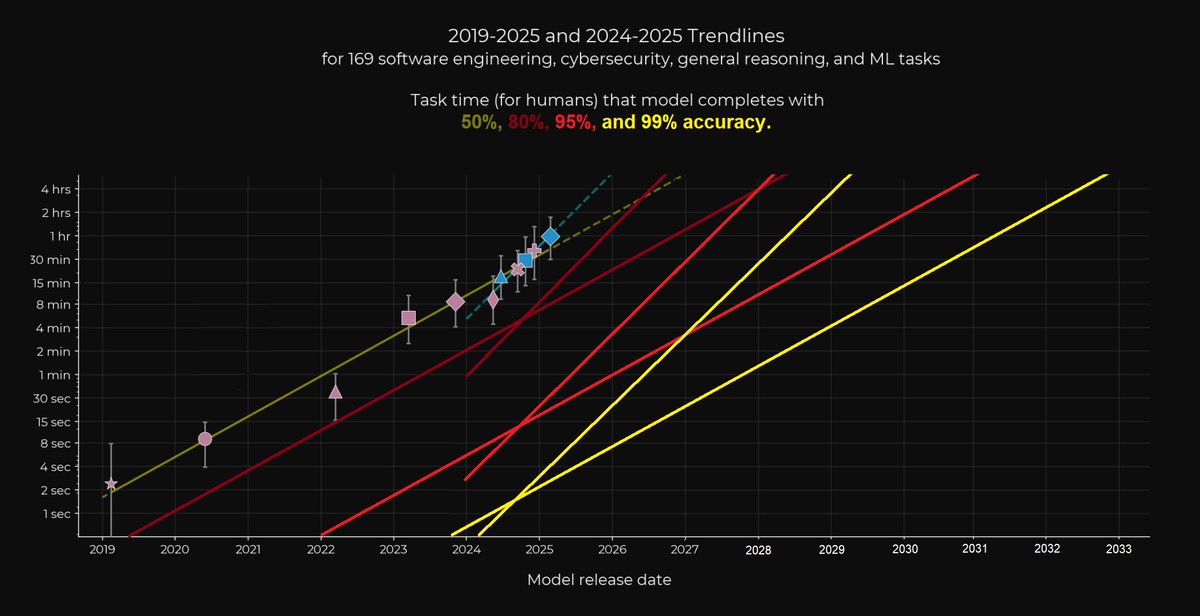
6
30
267
95,515
20 Mar 2025
Looks like the slope placements were somehow accidentally shifted too much to the right, here is a corrected version, sorry about that!
I'll be posting a google doc soon too with the math and data points organized, so others can more easily make visualizations like this as well.

2
1
26
2,468
20 Mar 2025
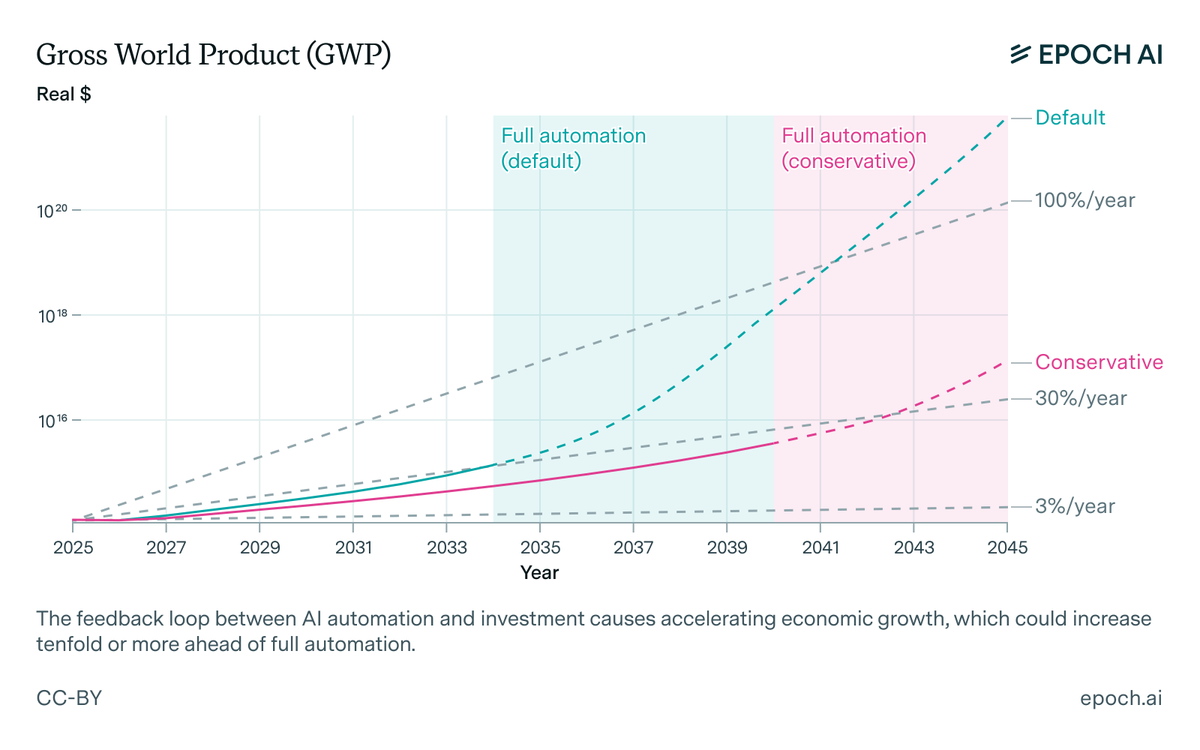
These new economic growth forecasts from EpochAI seem to align well with METRs recent capability forecasts. Especially when you look at the estimated times for 99% accuracy at high time horizons, and how those seem to converge with the full automation estimates by EpochAI below..
20 Mar 2025

We developed GATE: a model that shows how AI scaling and automation will impact growth.
It predicts trillion‐dollar infrastructure investments, 30% annual growth, and full automation in decades.
Tweak the parameters—these transformative outcomes are surprisingly hard to avoid.
1
1
13
1,157