
Research Fellow at MMlab@NTU, working on Embodied AI and Visual Reasoning.
Joined June 2023
- Tweets 106
- Following 376
- Followers 476
- Likes 155
9 Photos and videos

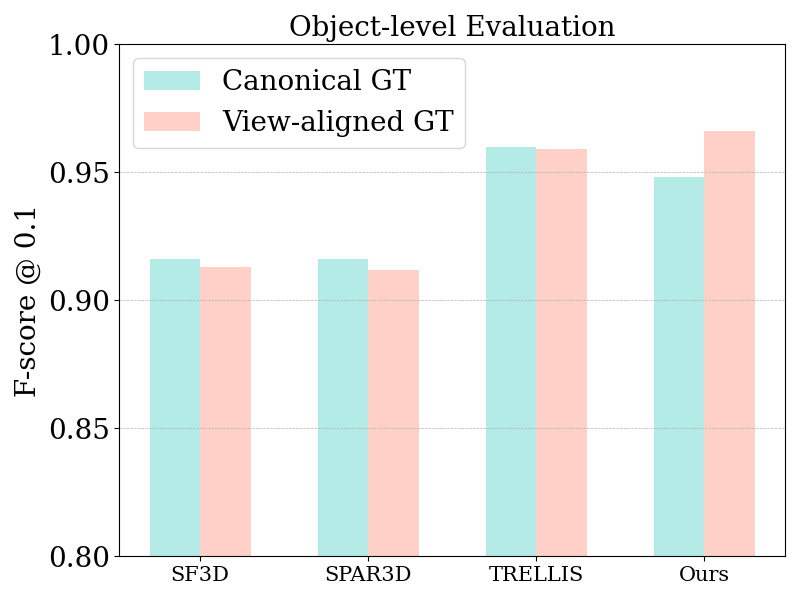
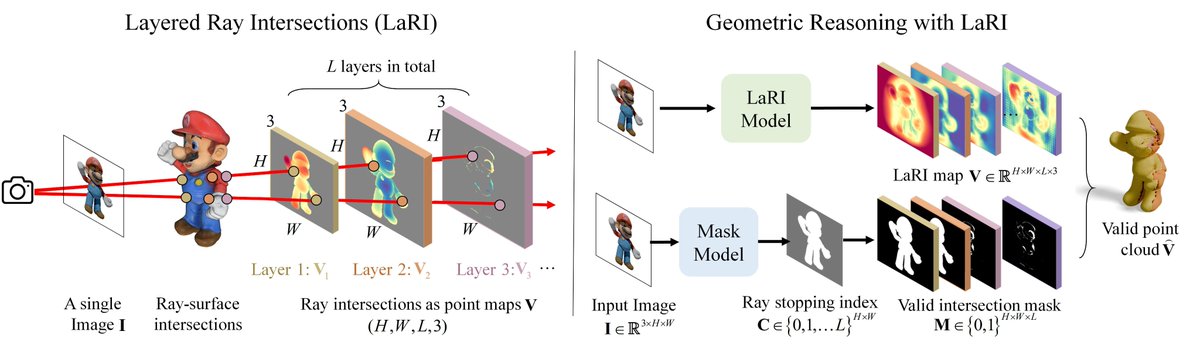







Introducing LaRI (ruili3.github.io/lari), a📸single-view,🚀single-feed-forward method to model🙈unseen 3D geometry using layered point maps. It
✅seamlessly extends depth estimation
✅unifies object- & scene-level reasoning
✅builds training & eval datasets
Details👇
1
23
143
9,428
Rui Li retweeted

Jun 13
Zang et al., "World Tracing: Generative Pixel-Aligned Geometry Beyond the Visible"
A Diffusion Transformer that estimates multiple layers of depth to further estimate occluded parts as well.
2
16
66
4,961
Rui Li retweeted

Jun 12
Natural images often already implicitly contain depth information — hidden in bokeh effects.
Can we leverage the rich depth cue widely exist in natural images for depth estimation?
We explore this in our recent project BokehDepth (ICML 2026).
- Stage 1: A generative model produces calibrated bokeh stacks from the input image.
- Stage 2: The bokeh stacks are integrated into a depth prediction model to estimate depth.
We believe it highlights bokeh effects as an important and effective complementary cue for monocular depth estimation.
🌐 Project page: fogradio.github.io/BokehDept…
📄 arXiv: arxiv.org/abs/2512.12425
👨💻 Code: github.com/fogradio/BokehDep…
3
14
62
6,232
Rui Li retweeted

Jun 6
Come check out V-DPM @CVPR
[Poster 25] 11:45 - 13:45
4D video reconstruction in the wild: code and models available 🤖
@EldarIsTyping @Oxford_VGG
2
25
222
17,190
Rui Li retweeted
Jun 9
Transformers have succeeded in modeling phenomena traditionally associated with computer graphics, such as 3D visual effects (e.g., RayZer) and rendering processes (e.g., RenderFormer).
A natural question is whether they can also tackle the challenging task of cloth simulation.
We introduce 👕𝗖𝗹𝗼𝘁𝗵𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿, a Transformer-based method that reformulates cloth simulation as autoregressive next-state prediction in a learned latent space.
It handles diverse scenarios under a single model, with 4-9x lower error than prior SOTAs:
• Body-driven garments
• Robotic manipulation
• General cloth–object collisions
We believe it highlights the potential of Transformer-based autoregressive models as a powerful alternative to conventional simulation approaches.
This work is mainly led by my student Yu Zhang @yucrazing
🌐 Project page: yucrazing.github.io/clothtra…
📄 arXiv: arxiv.org/abs/2605.27852
Jun 9

Sharing our recent work — ClothTransformer 🧵
We propose a unified Transformer-based neural cloth simulator that solves the "one model per scenario" problem. One single model handles diverse cloth simulation scenarios — useful for digital humans, embodied AI, games & VFX.
2
11
78
9,060
Rui Li retweeted

16 Nov 2025
The current paper submission and review process seems unlikely to survive LLMs. One alternative would be to build a new process around talks: "submission" is making and giving a 30 minute live talk, and "review" is three experts watching, evaluating, and asking questions.
35
25
268
66,514
Rui Li retweeted

16 Oct 2025
🎺Meet VIST3A — Text-to-3D by Stitching a Multi-view Reconstruction Network to a Video Generator.
➡️ Paper: arxiv.org/abs/2510.13454
➡️ Website: gohyojun15.github.io/VIST3A/
Collaboration between ETH & Google with Hyojun Go, @DNarnhofer, Goutam Bhat, @fedassa, and Konrad Schindler.
16 Oct 2025

Want to leverage the power of SOTA 3D models like VGGT & Video LDMs for 3D generation? Now you can! 🚀
Introducing VIST3A — we stitch pretrained video generators to 3D foundation models and align them via reward finetuning.
📄 arxiv.org/abs/2510.13454
🌐 gohyojun15.github.io/VIST3A
2
11
88
16,956

🚀Excited to share our recent work on test-time scaling for feed-forward Gaussian splatting:
we learn a recurrent model ReSplat that is able to iteratively improve the reconstruction quality in a feed-forward manner!
haofeixu.github.io/resplat/
5
49
311
18,418
Rui Li retweeted

9 Oct 2025
Interesting ICLR submissions 🤩
Depth Anything 3 - My TLDR: Init multi view transformer of VGGT with later layer DINO weights and use teacher model trained on synthetic data only for pseudo labelling real world datasets
openreview.net/forum?id=yiru…
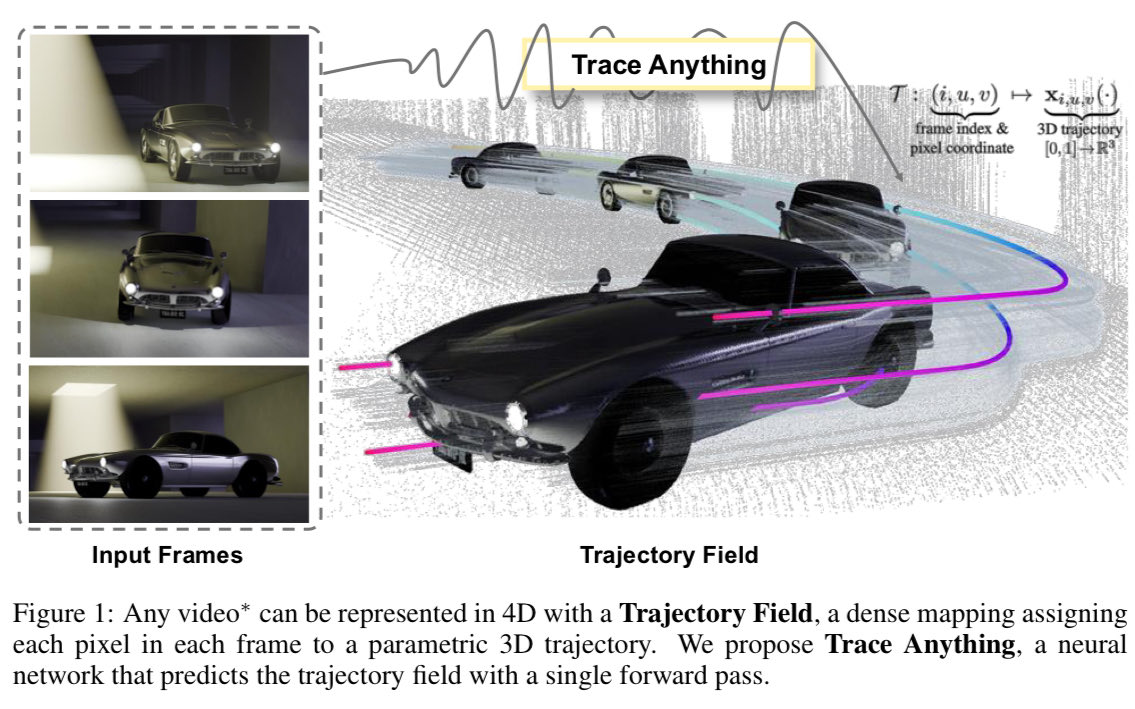
Trace Anything - My TLDR: VGGT like model predicting N view geometry and motion as a trajectory field represented using splines and control points
openreview.net/forum?id=BqaC…
The field is evolving very fast!

5
40
385
25,172
Rui Li retweeted

1 Oct 2025
Thanks, AK, for sharing our work!

5
26
13,678
(12/13) Automated Model Evaluation for Object Detection via Prediction Consistency and Reliability
TL; DR: A ground-truth-free method (PCR) that evaluates object detectors via prediction consistency and confidence reliability.
📃Paper: arxiv.org/abs/2508.12082
1
1
8
1,365
(13/13) Spatially-Varying Autofocus
TL; DR: A method for per-pixel autofocus that creates freeform depth-of-field and all-in-focus images.
📃Paper: imaging.cs.cmu.edu/svaf/stat…
🏗️Project: imaging.cs.cmu.edu/svaf/
5
1,293