
Building @cursor_ai, previously @vercel
Joined October 2009
- Tweets 16,471
- Following 801
- Followers 259,282
- Likes 57,216
1,324 Photos and videos














17h
See you at Cursor Compile next Tuesday in SF!
I'll be talking with @levelsio about retro computing, building your ideas, lifting, the perfect steak, and more.
30
26
359
49,003
17h
It's at capacity but we do have a waitlist. We'll be recording and posting talks after (no live stream).
cursor.com/compile
1
36
5,137
Jun 11
We're training the next version of Composer... with Composer!
The model is always learning from itself. This kind of "recursive self-improvement" might sound new, but it's been happening for many months!
For example, training big models requires creating *lots* of data for RL - essentially games the model plays to improve at any task you can grade.
The newest models can configure their own environments to make those games playable (auto-installing dependencies, fixing broken setups).
Composer 2 was *dramatically* better at this than version 1. So the better the model gets, the better it gets at creating the conditions to train its successor.
Each generation unlocks capabilities the previous one didn't have! So cool.
x.com/cursor_ai/status/20521…
May 6

We use previous generations of Composer to train future ones.
Our autoinstall system has earlier Composer models set up dev environments for RL training. That way, the next generation can focus on learning to solve harder problems.
cursor.com/blog/bootstrappin…
128
101
2,200
193,384
May 14
Bun moved from Zig to Rust. Total Rust victory.
I've been tracking the move to Rust in the JS ecosystem since 2021. It's actually wild.
I updated my post earlier this year, but so much has happened since. Here's my 2026 update below (bun was still in the oven here).
60
58
1,096
79,787
May 14
*DJ Khaled voice*
Anotha one
x.com/zkochan/status/2054966…
May 14

The Rust rewrite of pnpm was moved to the pnpm repository today. Now we will make changes to the TS and Rust versions in parallel.
5
48
16,283
Jun 10
Another another one! Really exciting stuff.
x.com/poteto/status/20644706…

merged!
github.com/react/react/pull/…
1
8
5,672
Jun 6
Cursor (and coding agents generally) still blows my mind daily. Just today:
1. I shipped a new landing page. I gave a 10min voice note to Cursor, left to go eat dinner, and came back to a 90% finished version. Made some small design and copy tweaks and merged.
2. Had Cursor dig through Search Console and Semrush with computer use, researched places we could improve SEO, and then merged 3 PRs with fixes.
3. Used the Supabase MCP to pull thousands of emails from the Compile waitlist, had it research them with web search based on ideal fit for the event, and got back a CSV with the top people to invite and why.
4. Updated an internal app I built for doing company-wide surveys (think Typeform but Cursor branded) in a few hours before our All Hands.
5. Had a few agents researching furniture I'm hoping to buy. They searched the web for a bunch of variants and then made a custom shopping cart (just an HTML page) with images, prices, links, and tons of details. Super helpful.
I don't do this every day, of course, but it's still wild to me this is the new normal for what someone with a computer and AI can do.
Most of these were running in the cloud as I was between meetings, just humming away in the background. I could check the app (🔜) to see progress and merge PRs. What a time to be alive.
(P.S. if you extrapolated my usage today, I'd still be on the $200/mo plan)
154
66
1,632
148,487
Jun 3
"Engineering, product, and design are all merging into a 'builder' role"
Yeah... I'm not so sure. This feels like an oversimplification and podcast talking point. Reality is a lot more complex.
Even with 1000 "Member of Technical Staff" titles, someone still has to wake up and care 100x more about Product or Design than anyone else. It is their Main Thing™
That's not to say MTS titles are universally bad, but I think they're an example of this 'builder' talking point that's become bastardized.
AI and coding agents have made generating code easy and yet... you're in for a world of pain if non-engineers ship a bunch of slop and don't have great engineers to tame the complexity.
The SF hivemind has a tendency to overfit what works at startups for every company. And to be fair, sometimes this is true! Startups can be a leading indicator for how the industry is changing and often cause disruption.
However, it is going to be incredibly hard to disrupt the extremely human parts of corporate jobs. You really think there's going to be a PM who also does some engineering and design on the side at JPMorgan Chase?
This is true for the simple parts of most jobs, like people wanting to have ownership over something and do good work, move up a career ladder, support their family, get paid well, make an honest living...
And also the hard parts: internal politics, some critical business system that has a bus factor of 1 which has been running for 15 years and isn't documented anywhere because it's that guy's job security. The real world has a lot of this stuff.
It's easy to pontificate about all roles collapsing but it's actually really nice to have a specific person or team who is an expert in one thing that you can work with. I don't expect that to change. Further, I think AI disruption to knowledge work will take decades to play out because it is more fundamental to the human condition (e.g. sociological/organizational) than pure intelligence.
142
109
1,379
144,315
Jun 2
Quick rant on AI model benchmarks:
- Some of the most popular ones are no longer helpful (SWE-bench¹)
- It can be very hard to reproduce reported results (so lots of variance)
- Take them with a grain of salt, look at the average across many
We need some creative new ideas for AI model marketing. Supportive of a Survivor spin-off (who is the AI Jeff Probst!?).
I get why every model release shows benchmark scores as the headline. It's actually pretty hard to describe how a model has improved without it sounding like fluff. And also it sounds boring to say the same thing over and over ("it's better at following instructions" repeat x10).
Benchmarks make it very clear there is a number, which likely started bad, and is now going up. Yay! The reality is that benchmarks are most useful to those *training* the model so they know where to improve.
Model labs use these benchmarks to measure progress, which is why having non-saturated benchmarks is extremely helpful. If you see models getting 90% on an eval, it's probably time to make a harder version.
I do think there's a word of caution for everyone interpreting benchmarks. It's very hard to get exactly the same scores, which is why some benches show error bars and do the average over multiple runs.
But even further, the hardware and GPUs the evals are running on really matter! Small differences there, or minor tweaks to the prompt, can swing scores by multiple percentage points².
All of that to say, it's important to look at many different benchmarks, and then actually use the model to make your own opinion. For example, there's recently been a lot of debate on here about Opus 4.8 not benchmarking as well as other models. But personally I've found the model really good from my own usage. Your mileage may vary!
There aren't many high-quality public benchmarks that measure things like the UX of the model responses, the style of the messages, the warmth or directness of the "personality". These things matter *a lot* for the day-to-day usage. How the model performs in the real world is often different from very specific benches.
In summary, benchmarks matter but they are not a substitute for extensively testing the model yourself with real work.
¹: openai.com/index/why-we-no-l…
²: anthropic.com/engineering/in…
Jun 1

I’m tired of useless AI benchmarks. How about we give three people a different model, strand them on an island, and see who survives the longest
30
8
227
37,280
Jun 1
Some tips to help agents understand your codebase:
1. The source code either needs to be the source of truth, or have something legible as a path to the source. For example, if marketing site content is actually stored in a CMS, you need to either delete the CMS and move that content into code, or make the CMS legible through and MCP, CLI, or skill: leerob.com/agents
2. Agents need to be able to verify their work. This includes but is not limited to: using a typed language, having high-quality and fast tests, having a well-configured linter: x.com/leerob/status/20263694…
3. You need to have a concise and effective AGENTS.md file, which is included in every message to your agent. Models are quite good now, so some things you can omit as the models know them. You don’t need to say the tests live inside /tests for example. It’s worth asking the models to find things in your codebase and making sure they’re named what the models might expect, otherwise consider refactoring: cursor.com/learn/customizing…
4. Set up automations which give you suggestions for refactoring code, catching security issues which may have slipped through code review, and optionally continuous documentation of the codebase. You can effectively create a self-driving codebase which gets better while you sleep: cursor.com/blog/security-age…
Feb 24

Cursor just got a major upgrade!
Agents can onboard to your codebase, use a cloud computer to make changes, and send you a video demo of their finished work.
The latency of using the remote desktop is smooooth.
34
68
1,091
73,010
May 28
How are coding agents changing software engineering?
Yapped for 15 minutes about new Cursor data we published, including:
1. Why lines of code is an imperfect measure of AI progress
2. Balancing intelligence/cost/speed for models
3. Code reviews with "Mega PRs" (1000 lines)
54
52
814
57,814
May 26
This is really good. Recommended watch!
Apr 12

⭐ New talk! andymatuschak.org/tat
Coding agents might help us finally break out of two cages: the app model, which traps computing in one-size-fits-all silos; and programming as a specialization, which has crowded out cultures of imagination and domain insight.
10
6
212
61,811
May 24
You might believe you should spend less time thinking about code because of AI.
I strongly disagree! We’re watching this play out live where tons of AI generated code becomes a liability.
At the end of the day, an engineer needs to be responsible / on call for code that gets shipped to production. If you don’t understand the system you’re trying to debug, you’re probably going to have a bad time.
Yes, AI can help with all of this, if you set up the proper systems. You can have agents triage prod logs, look at errors, etc. You can speed up parts of the investigation, but an engineer needs to make the call. There might be serious customer or financial implications from that change.
I expect the trend continue for trimming dependencies, vendoring code so you can modify it directly, preferring simpler systems with fewer abstractions, and spending waaaay more time thinking about system design and code maintenance.
I’ve said this before, but it’s a great time to get familiar with CS fundamentals and some of the history behind what great software looks like. Many parts will be different in the coming years as AI progresses, but also a lot more than people realize will stay the same.
269
531
4,173
599,702
May 22
This is great writing and what high-quality recruiting looks like today.
Some notes on what I love... It's very easy to read and not trying to sound fancy. It uses basic words. You should write how you speak!
It's humble, including some numbers, but not trying to overhype. There's a level of comfort in himself and his ideas you can feel.
It makes you root for him and his background. You might even relate to some of the examples (I also learned video editing at a young age). People want to work with people they like.
It uses humor without being over the top. This makes it feel written by a human and not some AI slop.
"I don’t care if you are broke film student who works at Starbucks or an OpenAI researcher getting paid a milli by Papa Sam."
Finally, one of my favorite parts is just cutting the normal resume / application crap and going straight to what you've built.
"Do not send me your resume. If you wanna do design here, show me a design for Clicky. If you wanna be a filmmaker here, great, record a video for Clicky and show me."
Nice work @FarzaTV!
May 22

I am building a team.
If you're really really really good at building stuff, design, filmmaking, writing, pushing the models to their limits, or just making people care about a product at mass, certainly reach out.
Let's collab make stuff.
Details:
docs.google.com/document/d/1…
38
54
1,444
144,941
Lee Robinson retweeted

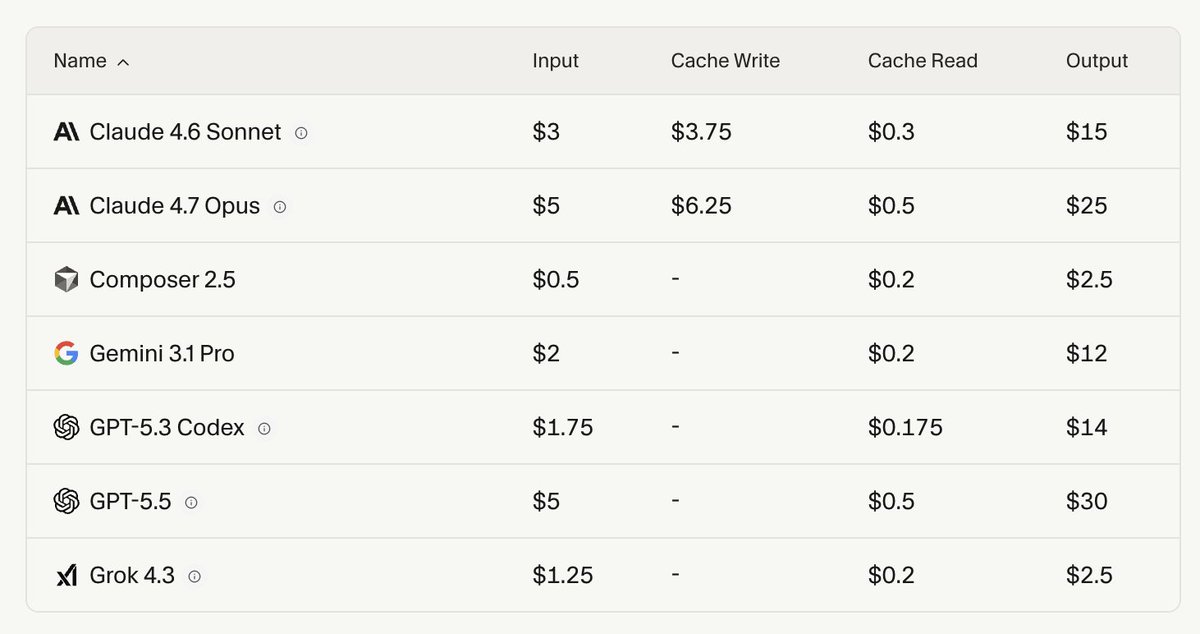
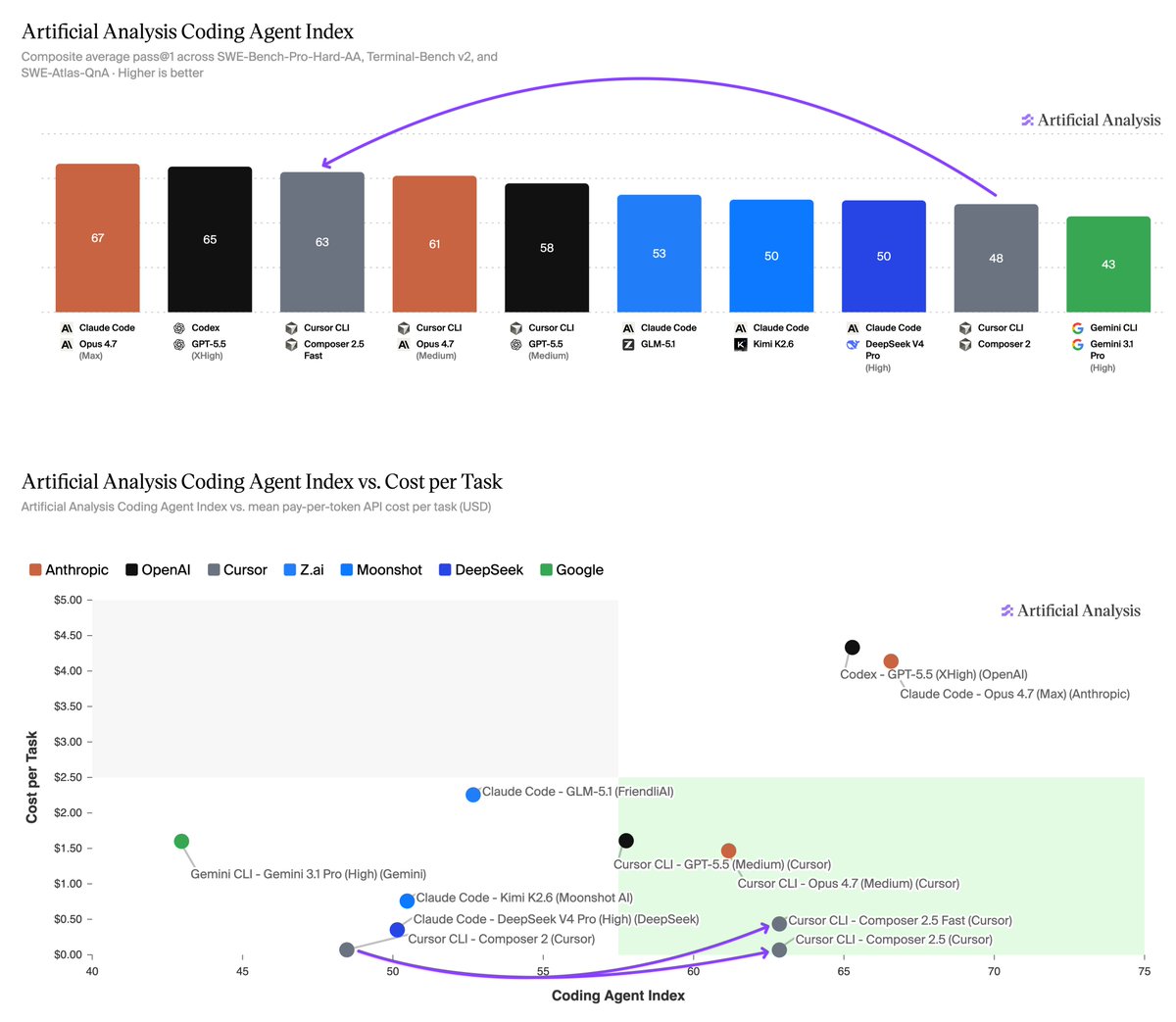
Cursor's new Composer 2.5 takes third on the Artificial Analysis Coding Agent Index and is ~10-60x lower cost than the higher-effort Opus 4.7 and GPT-5.5 variants above it. This release puts Composer among the leading coding agent models, something that wasn’t clear for past releases
@cursor_ai has released Composer 2.5, the latest model in its Composer line. Composer 2.5 scored 62 on our Coding Agent Index, a 14 point gain over Composer 2 (48). This puts it in third place of our tested agents, behind only Claude Opus 4.7 (max) in Claude Code (66) and GPT-5.5 (xhigh reasoning) in Codex (65). These cost $4.10 and $4.82 per task respectively, ~10x the cost of Composer 2.5 Fast ($0.44) and ~60x the cost of Composer 2.5 standard ($0.07).
Key results for Composer 2.5 in Cursor CLI:
➤ Cost-quality Pareto frontier: At $0.07 (standard) and $0.44 (Fast) per task, Composer 2.5 is cheaper than every other agent scoring above 60 on the Index. Medium-effort peers cost $1.24–$2.21 per task; higher-effort variants land 3-4 points above at $4.10–$4.82
➤ Per-benchmark gains vs Composer 2: 35 points on SWE-Bench-Pro-Hard-AA (12% → 47%), 2 points on Terminal-Bench v2 (64% → 66%), and 3 points on SWE-Atlas-QnA (69% → 72%). At 47%, Composer 2.5's score on SWE-Bench-Pro-Hard-AA is comparable to Claude Opus 4.7 (max) in Claude Code
➤ Among the fastest coding agents: Composer 2.5 Fast runs at an average wall time of 6.7 minutes per task, the third-fastest agent on the Artificial Analysis Coding Agent Index, behind only Claude Opus 4.7 (medium) in Claude Code (5.8m) and GPT-5.5 (medium) in Cursor CLI (6.2m)
➤ Fast mode enables better responsiveness at 6x pricing: Fast runs 30% faster than standard Composer 2.5, but is ~6x the cost per task ($0.44 vs $0.07). Token pricing is 6x higher for Fast: $3.00/$15.00 vs $0.50/$2.50 per million input/output tokens
Model details:
➤ Base model: Continued training on @Kimi_Moonshot's open weights Kimi K2.5 as with Composer 2, with Cursor reporting ~85% of total compute from its own additional training and reinforcement learning
➤ Pricing: $0.50/$2.50 per million input/output tokens for the standard variant; $3.00/$15.00 for the Fast variant (the default in Cursor)
➤ Available exclusively in Cursor: both Cursor IDE and Cursor CLI, an externally accessible API is not available
Congratulations @cursor_ai and @mntruell on the impressive release!
60
146
1,301
241,549

Amazing price for performance!
May 20
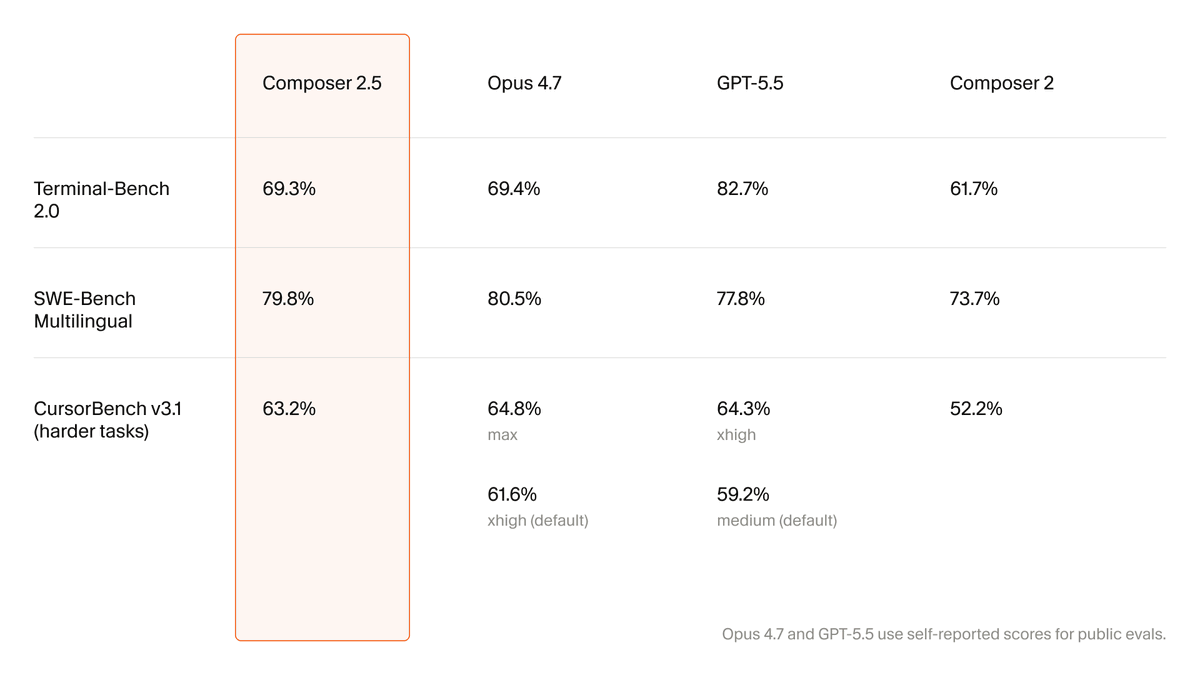
Where could we improve Composer 2.5?
We're working on the next model and would love your feedback.
Lots of work to do (our CursorBench evals below) in the coming weeks!
1,985
2,924
23,433
7,147,728
May 20
Where could we improve Composer 2.5?
We're working on the next model and would love your feedback.
Lots of work to do (our CursorBench evals below) in the coming weeks!
661
178
2,842
7,477,182
May 20
Evals shown are at cursor.com/evals.
And scores on other benchmarks are below, however benchmarks only tell part of the story!
Also curious about the style, formatting, and personality of the responses. Any suggestions welcome.
x.com/cursor_ai/status/20564…
May 18
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
15
6
181
72,568
Lee Robinson retweeted

May 18
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
927
1,340
13,291
20,138,035
May 14
Jarred is working on a blog post, will be very interesting. Casual 1 million LOC PR.
(Here's my full post in case you're curious: leerob.com/rust)
x.com/jarredsumner/status/20…
May 11

I have pretty high confidence in it at this point. It passes Bun’s test suite on Linux x64 arm64 glibc musl, Windows x64 & arm64, and macOS x64 & arm64. It likely closes about 200 github issues. Still refactoring & simplifying. Still need to write the blog post.
5
101
15,674