

leezy retweeted

May 13
🌟 Is scaling parameters enough for self-evolving multimodal agents?
Excited to share our new work:
Towards On-Policy Data Evolution for Visual-Native Multimodal Deep Search Agents
We study how data, not just models, can evolve with the current policy.
🧵👇

2
7
20
3,082

I reverse-engineered Claude Code's 512K-line TypeScript codebase and rebuilt its core in ~700 lines of Python.
Same agentic loop. Same tool system. Same permission model. Just 5 files.
github.com/leezythu/mini-cla…
2
1
21
📝 prompt.py → System prompt (maps to prompts.ts)
🔒 permissions.py → Safety gate (maps to permissions.ts)
The README is a full architectural walkthrough — every function mapped back to the original CC source.
14
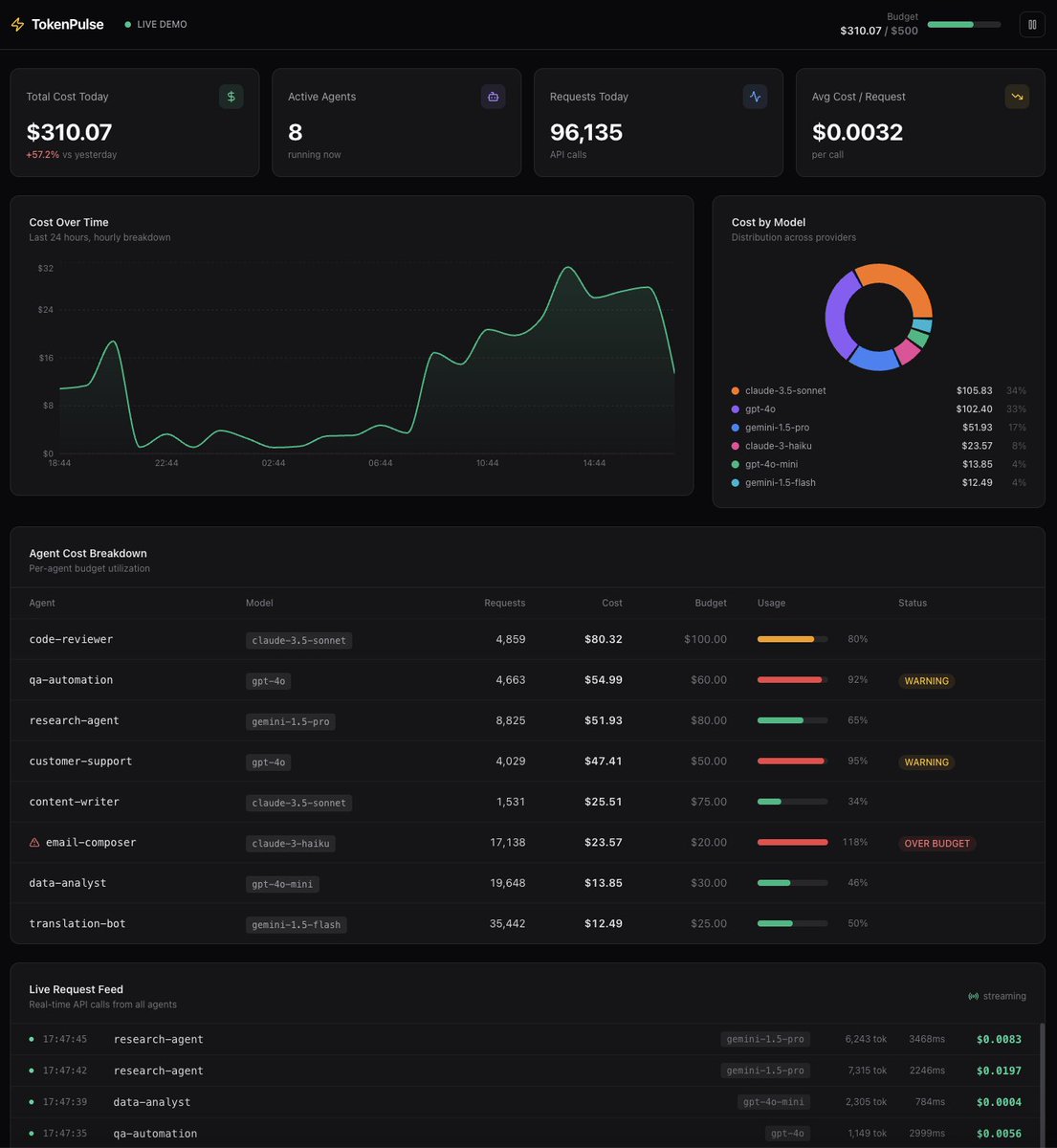
AI agents burned $847K/month for one team.
I built an open-source dashboard to prevent that.
⚡ TokenPulse — real-time cost monitoring for AI agents
✅ Per-agent budget alerts
✅ Auto-patches OpenAI & Anthropic
✅ Beautiful live dashboard
github.com/leezythu/tokenpul…
1
2
68
Seed1.8, the latest generalized agent model.
github.com/ByteDance-Seed/Se…
2
62
leezy retweeted

19 Dec 2025
Proud to introduce Seed1.8, our latest generalized agent model
The model achieves competitive agentic capabilities, while maintaining high LLM/VLM scores, enjoy!
github.com/ByteDance-Seed/Se…

9
33
245
45,117


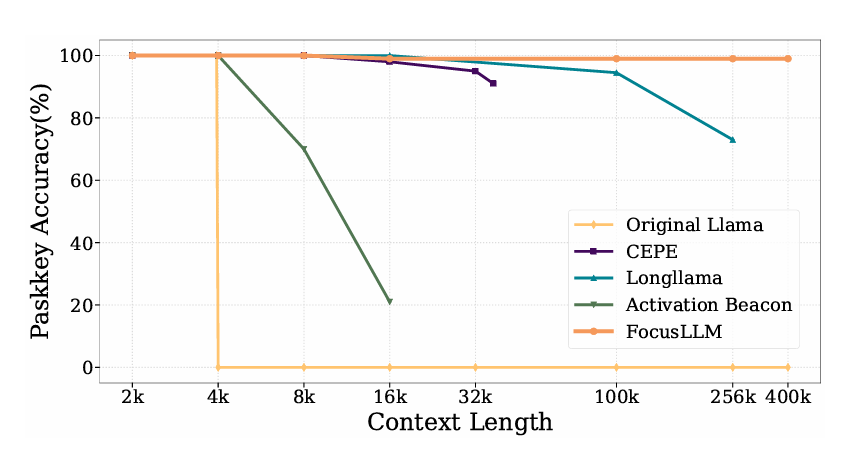
🚀 Introducing FocusLLM📷: Unlock Precise Long Context Understanding by Dynamic Condensing! arxiv.org/abs/2408.11745
🌟 Small-context LLMs can process documents 100x longer than their context limit with no information loss, with only a small training budget.
#LLM #LongContext
5
1
50
🔗 Check out our paper and code at github.com/leezythu/focusllm and revolutionize how you process long texts with LLMs!
33
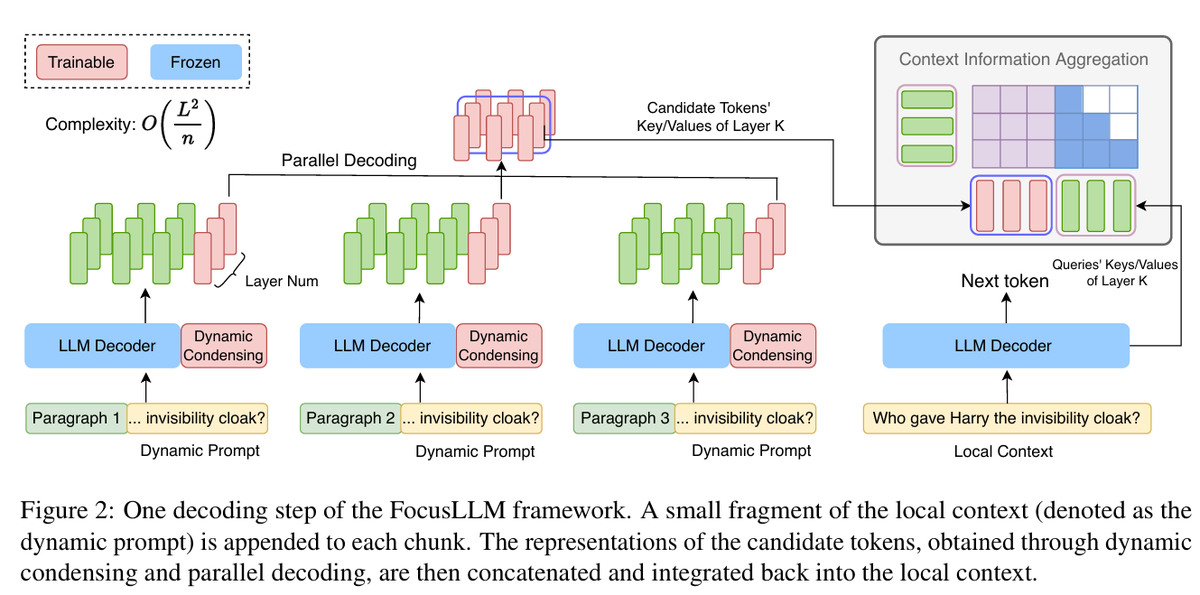
🛠️ Solution in this Paper:
Dynamic Condensing: Extracts crucial info from each text chunk with dynamic prompts, ensuring no information loss.
Parallel Decoding: Integrates info across chunks.
Training Efficiency: Trained with less cost, performs better than baselines. 🎯
29

