
Joined February 2021
- Tweets 1,002
- Following 625
- Followers 1,431
- Likes 546
355 Photos and videos








Let's Data retweeted

20 Jun 2025
Como é estudar na 1ª graduação de IA no Brasil, com nota de corte maior que Medicina.
guiadoestudante.abril.com.br…
1
8
28
1,814

10 May 2025
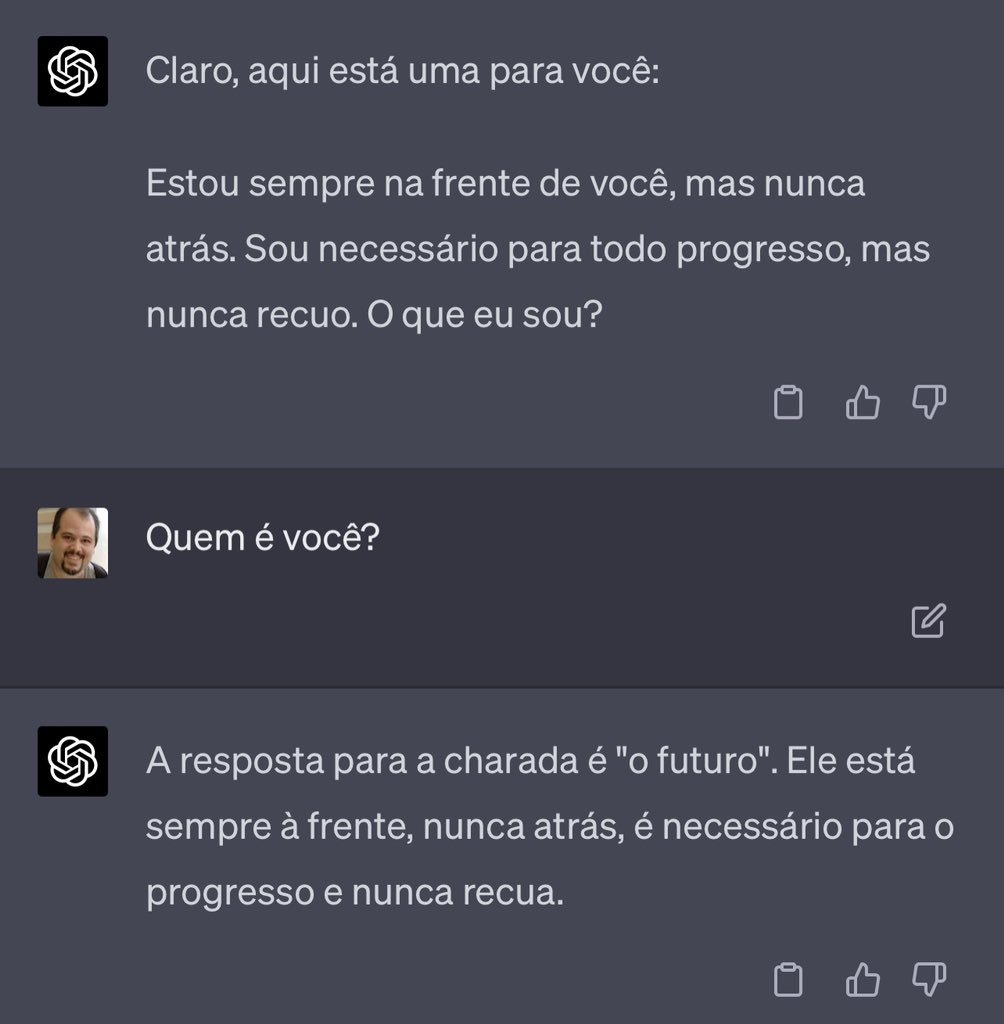
Esse padawan foi o mais original até agora, adoramos 😂😂
Valeu, Caique!! Estamos felizes demais de ajudar na sua jornada!! 🔥🔥
Agora só falta trocar pra caiqueonpython! 😂
8 May 2025

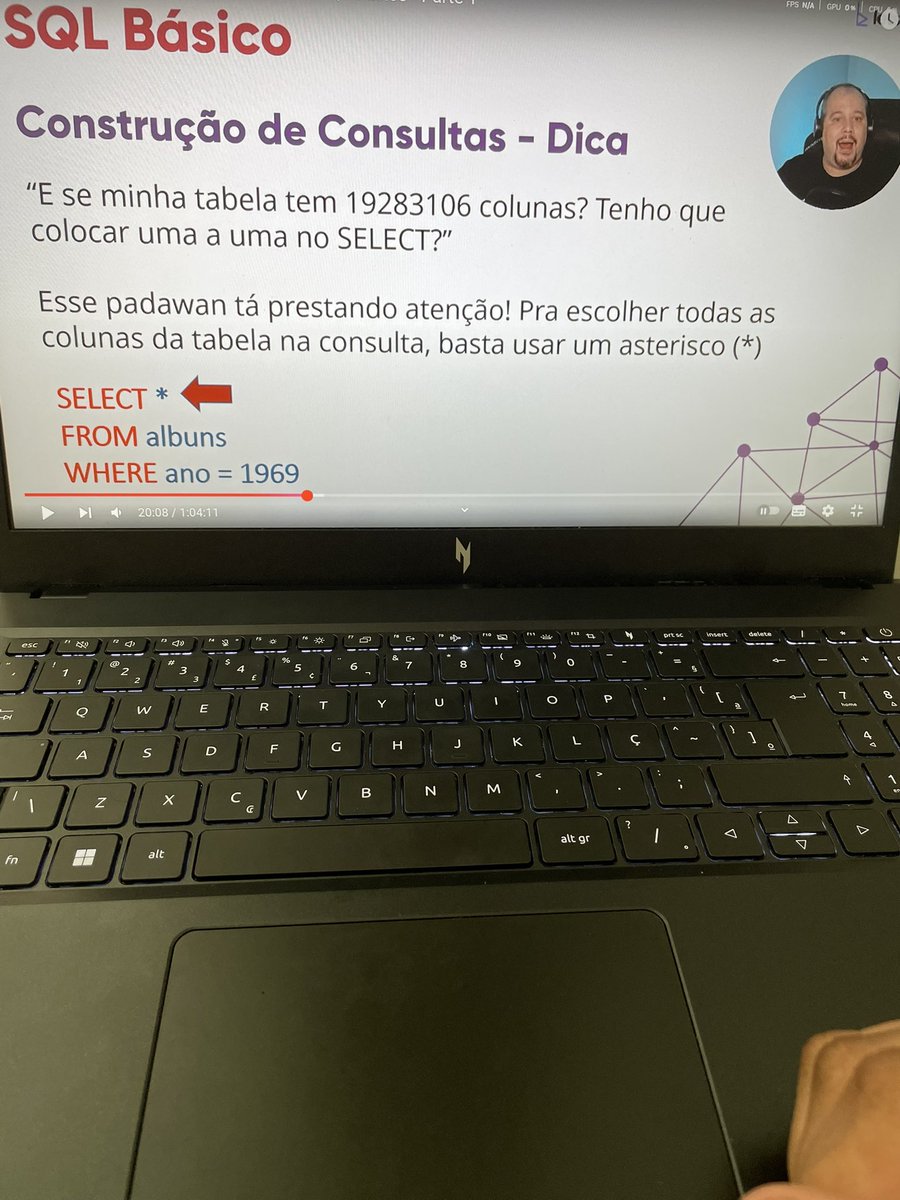
Ele explica como se eu fosse um animal e é exatamente isso que eu queria
1
3
229
9 May 2025
Demanda por FastAPI bombando e tem curso DE GRAÇA do mestre Duno! Tira umas horinhas de Netflix que vale muito a pena, padawan. Dunossauro é atestado de excelência
1
177
Let's Data retweeted

8 May 2025
Things you can do with AI
#1: Slow motion waves
Video prompt: show the wave motion flow in slow motion
10
7
87
15,533
20 Mar 2025
Calma, gente, daqui a pouco chove trampo de Vibe Debugging pra todos os projetos de Vibe Coding 😂
133
Let's Data retweeted

9 Jun 2024
Very practical guide on forecasting by the analytics team at @Meta
medium.com/@AnalyticsAtMeta/…
1
6
627
Let's Data retweeted

24 Apr 2024
Hoje no @devsfronteiras falei com o @bernardolago, que saiu do negócio de família para se tornar Cientista de Dados em Portugal, de onde também toca o podcast @letsdataAI, um dos mais conhecidos no Brasil dessa área. 🇵🇹
Vai lá escutar! 😎
devsemfronteiras.tech/cienti…
1
1
5
541
Let's Data retweeted

24 Apr 2024
Nessa aventura o @fabriciocarraro falou com o @bernardolago, que saiu do negócio de família para se tornar Cientista de Dados em Portugal, de onde também toca o podcast @letsdataAI, um dos mais conhecidos no Brasil dessa área. 🇵🇹
Vai lá escutar! 😎
devsemfronteiras.tech/cienti…
1
4
307
21 Dec 2023
Artigo publicado no nosso Medium sobre como iniciar com Git e Github!
medium.com/lets-data/desvend…
2
4
359
17 Dec 2023
Artigo publicado no nosso Medium sobre expressões regulares (Regex), uma ferramenta poderosa para encontrar padrões em texto
medium.com/lets-data/desmist…
2
10
511
Let's Data retweeted

16 Dec 2023
Conformal prediction takes Brazil 🇧🇷 and Portugal 🇵🇹 by storm.
”Conformal Prediction seminar” in Portuguese.
youtube.com/watch?v=YJDCwyCa…
#conformalprediction

2
6
39
5,172
Let's Data retweeted

15 Dec 2023
.@OctoML is now serving the lowest-cost Mixtral MoE inference I've seen.
Input: $0.20/million tokens
Output: $0.50/million tokens
octoml.ai/blog/mixtral-8x7b-…
16
29
334
78,786
Let's Data retweeted

16 Dec 2023
OpenAI just came out with their Prompt Engineering guide: platform.openai.com/docs/gui…
8
143
839
166,004
Let's Data retweeted

12 Dec 2023
Removed, enjoy !

So Mistral prohibits you from using their models to train or improve other models or compete against them........... I thought they were fully open......
mistral.ai/terms-of-use/

367
627
7,923
2,187,692


Let's Data retweeted

16 Nov 2023
Thrilled to share #Lyria, the world's most sophisticated AI music generation system. From just a text prompt Lyria produces compelling music & vocals. Also: building new Music AI tools for artists to amplify creativity in partnership w/YT & music industry deepmind.google/discover/blo…
105
503
2,459
1,170,260
15 Nov 2023
Um papo com muitas dicas de como começaríamos hoje numa carreira de dados.
Não só com nossa experiência como profissionais de dados mas também o que temos vivenciado com nossos alunos e alunas no Let's Data.
Espero que gostem!!
open.spotify.com/episode/2ww…
5
314

LoRA Fine-tuning Efficiently Undoes Safety Training in Llama 2-Chat 70B
paper page: huggingface.co/papers/2310.2…
AI developers often apply safety alignment procedures to prevent the misuse of their AI systems. For example, before Meta released Llama 2-Chat, a collection of instruction fine-tuned large language models, they invested heavily in safety training, incorporating extensive red-teaming and reinforcement learning from human feedback. However, it remains unclear how well safety training guards against model misuse when attackers have access to model weights. We explore the robustness of safety training in language models by subversively fine-tuning the public weights of Llama 2-Chat. We employ low-rank adaptation (LoRA) as an efficient fine-tuning method. With a budget of less than $200 per model and using only one GPU, we successfully undo the safety training of Llama 2-Chat models of sizes 7B, 13B, and 70B. Specifically, our fine-tuning technique significantly reduces the rate at which the model refuses to follow harmful instructions. We achieve a refusal rate below 1% for our 70B Llama 2-Chat model on two refusal benchmarks. Our fine-tuning method retains general performance, which we validate by comparing our fine-tuned models against Llama 2-Chat across two benchmarks. Additionally, we present a selection of harmful outputs produced by our models. While there is considerable uncertainty about the scope of risks from current models, it is likely that future models will have significantly more dangerous capabilities, including the ability to hack into critical infrastructure, create dangerous bio-weapons, or autonomously replicate and adapt to new environments. We show that subversive fine-tuning is practical and effective, and hence argue that evaluating risks from fine-tuning should be a core part of risk assessments for releasing model weights.

21
73
441
109,645
Let's Data retweeted

28 Oct 2023
Apparently it is ten years today since the first release of seaborn on PyPI 🎂
28 Oct 2013

Since it's been getting attention, I tagged and released seaborn 0.1. You can get it with `pip install seaborn moss` (moss has stat utils)
6
16
246
39,773