
40 Photos and videos



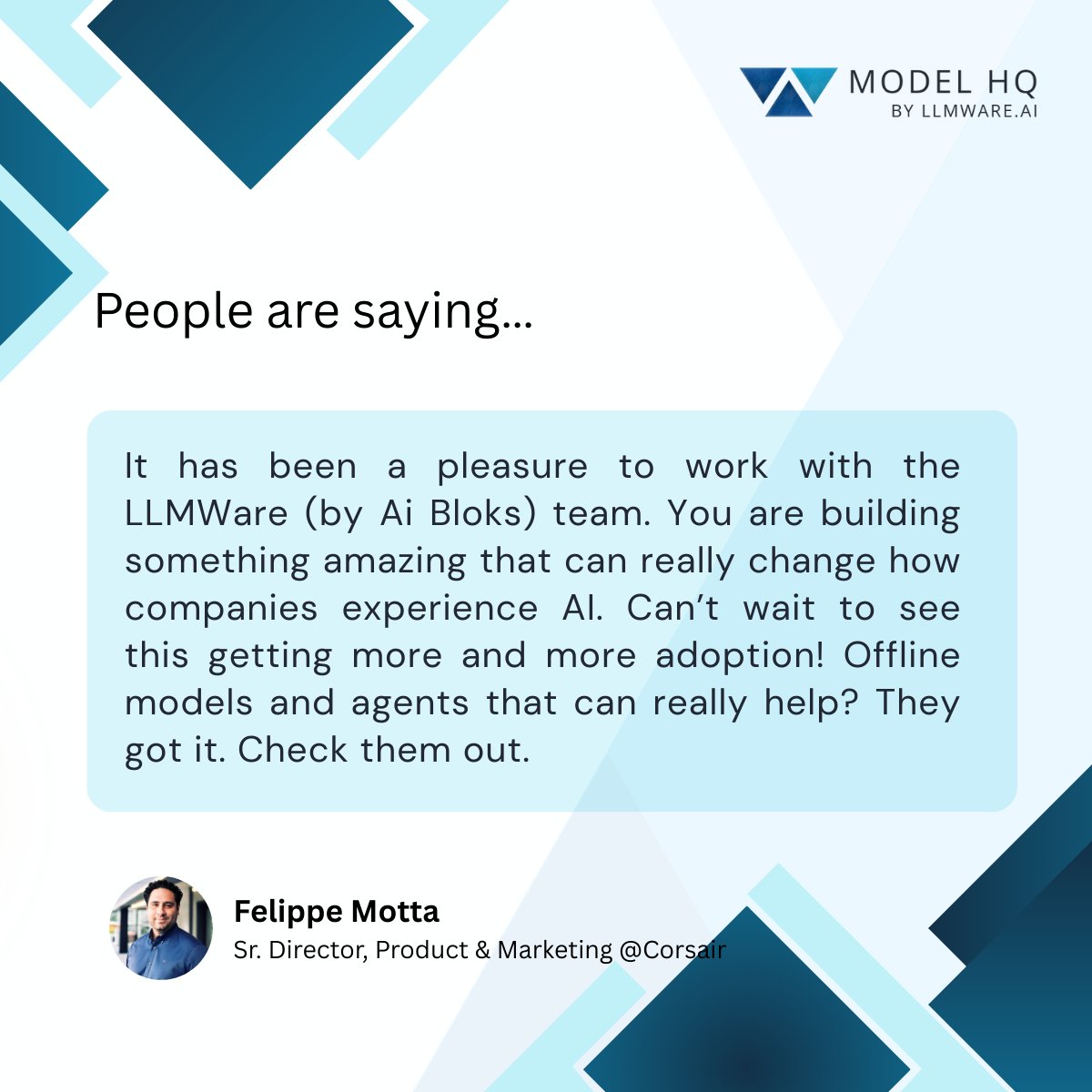





What if your AI agents ran fully local with zero cloud dependency?
With Model HQ, build no code agents that analyze contracts, extract key terms with RAG, and run batch workflows directly on device.
Private. Practical. Enterprise ready.
Download Model HQ and start building today
1
1
4
84
Visit LLMWare: llmware.ai
Model HQ Docs: model-hq-docs.vercel.app/
Join us on YouTube: youtube.com/@llmware
𝗪𝗮𝘁𝗰𝗵 𝘁𝗵𝗶𝘀 𝘃𝗶𝗱𝗲𝗼 𝗼𝗻 𝗬𝗼𝘂𝗧𝘂𝗯𝗲: youtu.be/9n7gXz6knbM?si=uTnO…
2
55
Visit LLMWare: llmware.ai
Model HQ Docs: model-hq-docs.vercel.app/
Join us on YouTube: youtube.com/@llmware
𝗪𝗮𝘁𝗰𝗵 𝘁𝗵𝗶𝘀 𝘃𝗶𝗱𝗲𝗼 𝗼𝗻 𝗬𝗼𝘂𝗧𝘂𝗯𝗲: youtu.be/zP2v8DixQaA?si=LDin…
3
23
Visit LLMWare: llmware.ai
Model HQ Docs: model-hq-docs.vercel.app/
Join us on YouTube: youtube.com/@llmware
𝗪𝗮𝘁𝗰𝗵 𝘁𝗵𝗶𝘀 𝘃𝗶𝗱𝗲𝗼 𝗼𝗻 𝗬𝗼𝘂𝗧𝘂𝗯𝗲: youtu.be/R1fAogEIDMc?si=gqlC…
2
25
Visit LLMWare: llmware.ai
Model HQ Docs: model-hq-docs.vercel.app/
Join us on YouTube: youtube.com/@llmware
𝗪𝗮𝘁𝗵 𝘁𝗵𝗶𝘀 𝘃𝗶𝗱𝗲𝗼 𝗼𝗻 𝗬𝗼𝘂𝗧𝘂𝗯𝗲: youtu.be/yNkcSH73vKc?si=The5…
2
18
How do you choose the right LLM before deployment?
Model HQ by LLMWare lets teams test and compare models locally with no code and no Wi Fi. Generate custom test sets, measure quality and latency, and validate models for real workflows.
Watch the demo and try Model HQ.
1
1
4
34
Visit LLMWare: llmware.ai
Model HQ Docs: model-hq-docs.vercel.app/
Join us on YouTube: youtube.com/@llmware
𝗪𝗮𝘁𝗰𝗵 𝘁𝗵𝗶𝘀 𝘃𝗶𝗱𝗲𝗼 𝗼𝗻 𝗬𝗼𝘂𝗧𝘂𝗯𝗲: youtu.be/JazySdXT2IE?si=VIwV…
2
16
Stop guessing. Test AI models locally and deploy with certainty.
In this walkthrough, we will show that Model HQ by LLMWare lets you download and test 150 AI models on a no-code, fully local platform. Compare accuracy, speed, and hallucination behavior across NPU and GPU.
1
1
3
54
Visit LLMWare: llmware.ai
Model HQ Docs: model-hq-docs.vercel.app/
Join us on YouTube: youtube.com/@llmware
𝗪𝗮𝘁𝗰𝗵 𝘁𝗵𝗶𝘀 𝘃𝗶𝗱𝗲𝗼 𝗼𝗻 𝗬𝗼𝘂𝗧𝘂𝗯𝗲: youtu.be/XT5wZ4TAsHM?si=p6Lj…
1
20
Just built a contract analysis AI agent with Model HQ - no code needed!
Started with a basic template, customized it for music licensing agreements, and deployed it across multiple docs in minutes.
All running locally for max security.
medium.com/@nameeoberst/buil…
1
4
98
LLMWare retweeted

25 Sep 2025
Model HQ just dropped a game-changing hybrid inferencing demo!
Run LLMs seamlessly between AI PCs and private servers with zero cloud dependency.
Key patterns we tested:
• Local AI PC inference
• Server-side API calls
• Hybrid agent deployment
Best part? No per-token fees.

1
2
5
93
Just tested Model HQ's new hybrid inferencing - game-changing flexibility for enterprise AI.
Run workloads on local AI PCs or private servers, zero cloud dependency.
See how we built a secure RAG system with on-device inference server vector store.
{ LINK IN COMMENTS }
1
2
4
86
𝗥𝗲𝗮𝗱 𝗙𝘂𝗹𝗹 𝗕𝗹𝗼𝗴 𝗵𝗲𝗿𝗲: medium.com/p/13b842b5d49d
𝗧𝗿𝘆 𝗠𝗼𝗱𝗲𝗹 𝗛𝗤 𝗳𝗿𝗲𝗲 𝗳𝗼𝗿 𝟵𝟬 𝗱𝗮𝘆𝘀: llmware.ai/enterprise#develo…
2
13
LLMWare retweeted
23 Sep 2025
Just ran Phi-4 14B on three different setups using Model HQ by @llmware : Xeon CPU server, Lunar Lake NPU, and GPU.
Zero cloud costs, fully local inference across all modes.
Perfect for enterprise deployment flexibility.
{ FULL ARTICLE IN THE COMMENTS }

1
2
4
65
𝗥𝗲𝗮𝗱 𝗕𝗹𝗼𝗴 𝗵𝗲𝗿𝗲: medium.com/p/80653a1e3fe6
𝗧𝗿𝘆 𝗠𝗼𝗱𝗲𝗹 𝗛𝗤 𝗳𝗿𝗲𝗲 𝗳𝗼𝗿 𝟵𝟬 𝗱𝗮𝘆𝘀: llmware.ai/enterprise#develo…
2
9