
Discover and run open models 👾 we are hiring lmstudio.ai/careers
Joined May 2023
- Tweets 2,590
- Following 83
- Followers 57,729
- Likes 8,400
193 Photos and videos














LM Studio retweeted

Jun 9
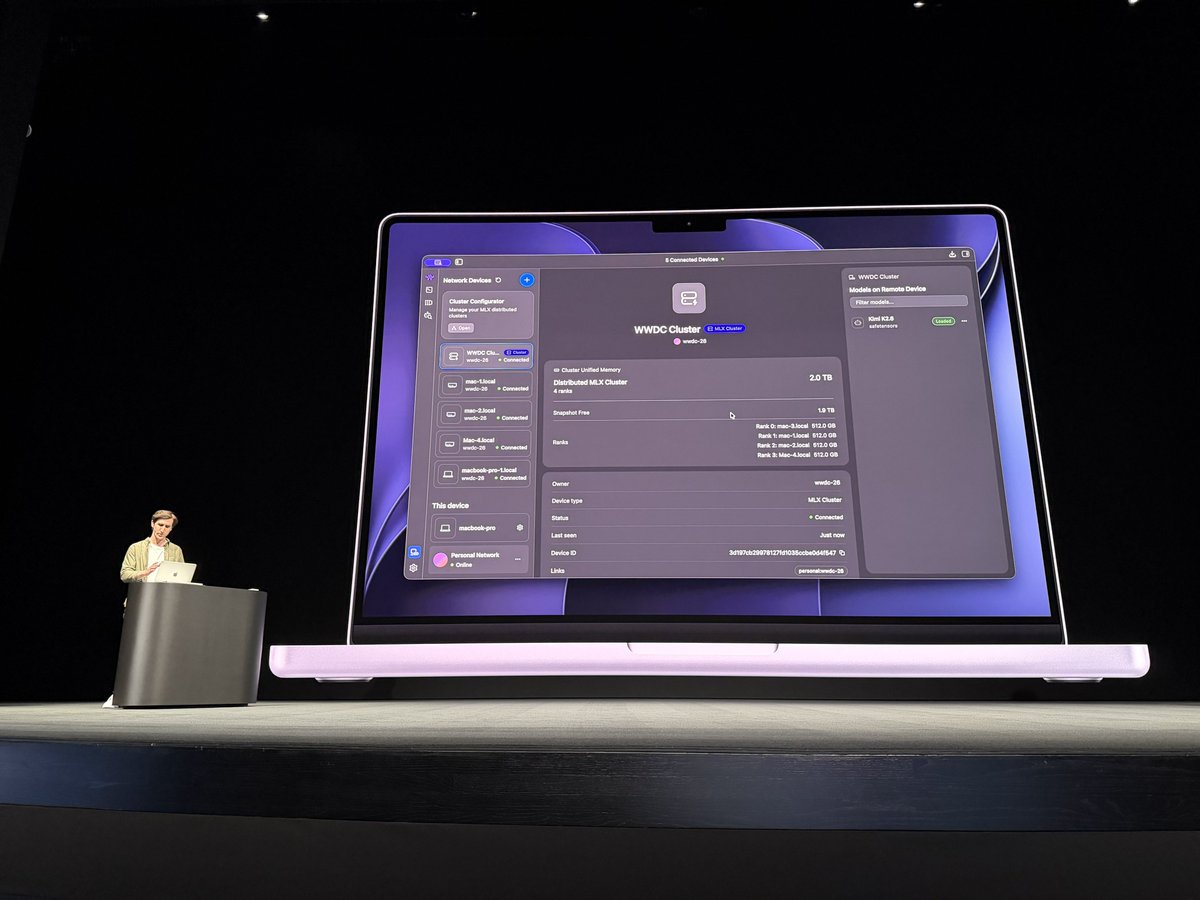
LM Studio on stage for WWDC at the Steve Jobs Theater demonstrating MLX distributed on 4 Mac Studio!
Coming later this year @lmstudio 👾
26
40
803
38,412
LM Studio retweeted

We made @lmstudio's MLX Engine a lot faster in the latest release.
Read the technical deep dive from @ostensiblyneil.
P.S. it's all open source!

17
50
543
49,933
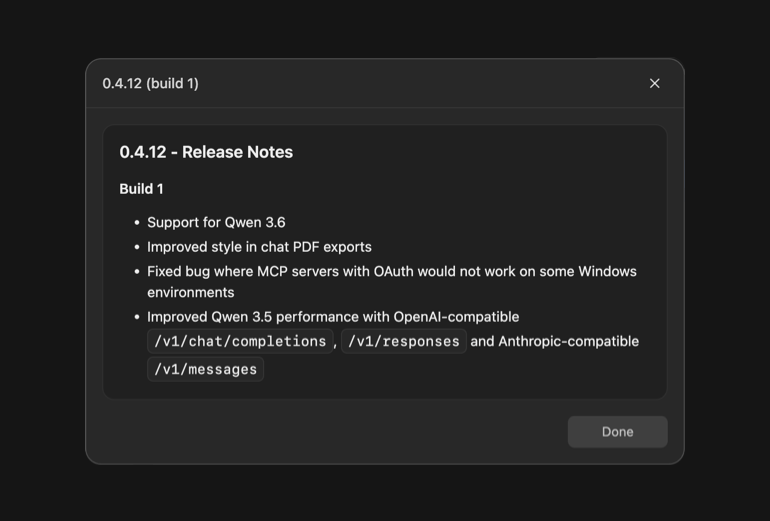
Gemma 4 QAT is here.
Available for all sizes of Gemma 4, optimized with Quantization-Aware Training (QAT) to reduce memory requirements while preserving performance.
Live now in LM Studio. lmstudio.ai/models/gemma-4
24
103
1,068
66,251
Locally is now LM Studio’s mobile app. And today we're bringing LM Link to iPhone.
Use your largest local models over a secure, end-to-end encrypted connection, anywhere you go.
Download the app now: lmstudio.ai/locally
38
42
414
53,359
Gemma 4 model load issues fixed in engine version 2.20.1.
lms runtime update --all

Gemma 4 12B is here!
Dense, mid-sized Gemma that fits right on your laptop - released by @google under Apache 2.0
Available now in LM Studio lmstudio.ai/models/google/ge…
20
27
514
42,609
Gemma 4 12B is here!
Dense, mid-sized Gemma that fits right on your laptop - released by @google under Apache 2.0
Available now in LM Studio lmstudio.ai/models/google/ge…
48
132
1,507
131,788
Make sure to update your runtime first!
> lms runtime update --all
Learn more about this model release x.com/googlegemma/status/206…
Jun 3

Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

11
6
47
15,227
MTP means Multi Token Prediction. It's a speculative decoding technique that can result in large inference speedups in many cases.
1. Update to LM Studio 0.4.14
2. Download a model that supports MTP like Qwen3.6-35B-A3B-MTP-GGUF or Qwen3.6-27B-MTP-GGUF
3. Enable it when loading the model
Supported for GGUF/llama.cpp models 🚀
13
6
156
9,833
LM Studio retweeted
May 20
Subagents running locally and simultaneously on MacBook Pro M5 with Codex CLI @lmstudio to review code and find bugs using Qwen 3.6
Powered by the updated MLX engine with batching in beta in the app
The batching speed boost is noticeable
36
32
656
74,570
Use your LM Studio models to code locally in @zeddotdev 🚀
May 19

Local model usage grew 3x in Zed's agent in the last 10 weeks. Cameron Mcloughlin on why he prefers local:
"I worry about over-reliance on providers that operate like SaaS platforms, where a change of pricing or setup makes them unfeasible to use. With a local model, you always have access."
Read more: zed.dev/blog/local-ai-in-zed
10
10
149
25,442
Batching for vision models is now available in Beta with our latest MLX engine update 👾
The updated engine also brings major improvements to caching for faster inference overall.
Turn on Developer Mode, choose the beta runtime channel, and select LM Studio MLX v1.8.1.
22
30
353
47,066
Event with @googlegemma next week!
Hang out with the fellow builders and members of the Gemma LM teams at LM Studio HQ in NYC.
When: Monday, May 11th
RSVP: required, link below
High likelihood of pizza and cool demos
13
17
213
17,543
Very few spots available. Grab yours: luma.com/3r7i1557
3
2
14
6,288
Hermes Agent LM Studio 👾🪽
Apr 30

LM Studio is the most popular way to run open-source LLMs on your own hardware.
Your Hermes Agent now runs natively on @lmstudio: auto-discovering your models, loading them on demand with the right context size, and using the right reasoning level for each model.
34
90
1,055
83,346
Dive into the docs to get started lmstudio.ai/docs/integration…
2
1
43
5,804