
Building @VarticasAI - A multi-agent that plan previews action across Gmail, linear , Jira and many more . not a chat bot . Not Zapier
Joined October 2025
- Tweets 371
- Following 180
- Followers 152
- Likes 493
9 Photos and videos









Jun 11
Builders on X!!
What are you building right now?
App.
Startup.
Side project.
Content.
I want more builders on my timeline.
Let's connect 🤝🏻
2
1
37
Jun 11
Hey @x
Looking to #connect with what are you building?
💻 SaaS
⚙️ Tech
🤖 Automation
🧠 AI tools
📦 Product Development
🌐 Web apps
Drop what you're working on 👇🏼
Let's #buildinpublic
4
2
46
Jun 10
Today I found out that if Claude Code makes a mistake, you can tell it to update its memory so it won't repeat it.
It's been working like magic for me so far.
Any other Claude Code tips you know? Share 👇
2
60
Jun 10
investors throwing $250B at Elon like it's a Cybertruck drop. Meanwhile Apple’s WWDC dropped “smarter Siri” (again) & Anthropic just unleashed a safer Mythos AI .
2026 tech: Either we’re all going to Mars or our phones will finally understand us.
Which one are you betting on?
35
Jun 3
Hey @x
Looking to #connect with what are you building?
💻 SaaS
⚙️ Tech
🤖 Automation
🧠 AI tools
📦 Product Development
🌐 Web apps
Drop what you're working on 👇🏼
Let's #buildinpublic
3
1
119
Jun 2
Hey Founders 👋
what do u do when Claude hits limits?
For me it's scrolling X
47
Jun 2
Now let's do the math on what that actually current systems use...
Current system for 6GB model:
OS kernel: ~500MB
Runtime overhead: ~500MB
Memory addressing/pointers: ~1GB
Padding/alignment waste: ~500MB
Cache inefficiency: ~1GB
Actual weights: ~2.5GB
That's 58% waste.
Jun 2

What does a system actually need to run LLM inference?
Just these things:
-Store the weights — the numbers
-Read them in order — sequentially
-Multiply them — basic math
-Output a result — one token at a time
That's it. That's all an LLM inference engine fundamentally does.
1
56
Jun 2
What does a system actually need to run LLM inference?
Just these things:
-Store the weights — the numbers
-Read them in order — sequentially
-Multiply them — basic math
-Output a result — one token at a time
That's it. That's all an LLM inference engine fundamentally does.
2
97
Jun 1
Hey @x
Looking to #connect with what are you building?
💻 SaaS
⚙️ Tech
🤖 Automation
🧠 AI tools
📦 Product Development
🌐 Web apps
Drop what you're working on 👇🏼
Let's #buildinpublic
30
18
869
Jun 1
I’ve been MIA for a bit, but for a good reason. Been working hard on this new project! 🚀
It’s finally starting to take shape. I’d love to hear your thoughts on this! 💬 👇
1
1
2
53
May 28
Every day I wake up, open @X, see a new model better than the others, and then I go to sleep. 😪

Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
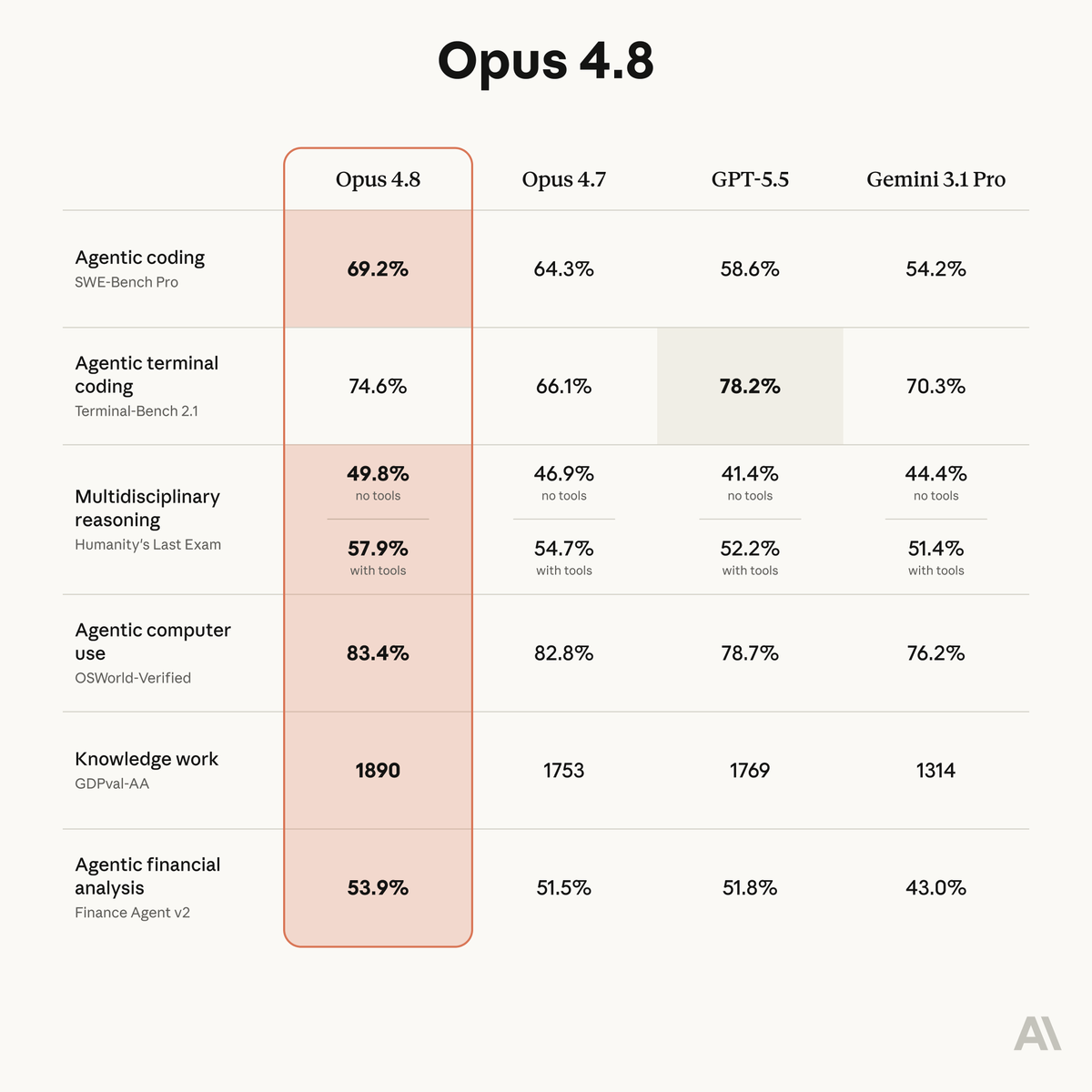
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
49
May 27
Hey #builders day 16 of building in public.
So today I polished the job agent and deployed it. Soon it will be available for everyone.
Tell me one feature that you would like to see in that agent? 👇
Stay #connected, stay motivated 🤝🤝 #buildinpublic
4
6
112
May 27
New agent coming soon.
Now you don't need to waste time on searching jobs.
What one feature you would like to see in this agent? Drop your view👇
Let's #connect and #buildinpublic
61
May 26
Hey #builders day 15 of building in public.
So from past few days I was working on job agent. It's almost done, soon i will make it live and free.
Tell me one feature that you would like to see in that agent? 👇
Stay connected, stay motivated 🤝🤝 #buildinpublic
2
5
87
May 26
What do you think the future of AI looks like? 👇
Is there gonna be a bubble burst?
36
May 25
Hey @x
Looking to #connect with what are you building?
💻 SaaS
⚙️ Tech
🤖 Automation
🧠 AI tools
📦 Product Development
🌐 Web apps
Drop what you're working on 👇🏼
Let's #buildinpublic
7
4
123