
Research Scientist at Mistral AI.
Joined August 2019
- Tweets 247
- Following 546
- Followers 1,189
- Likes 1,084
8 Photos and videos

Pinned Tweet

24 Jul 2024
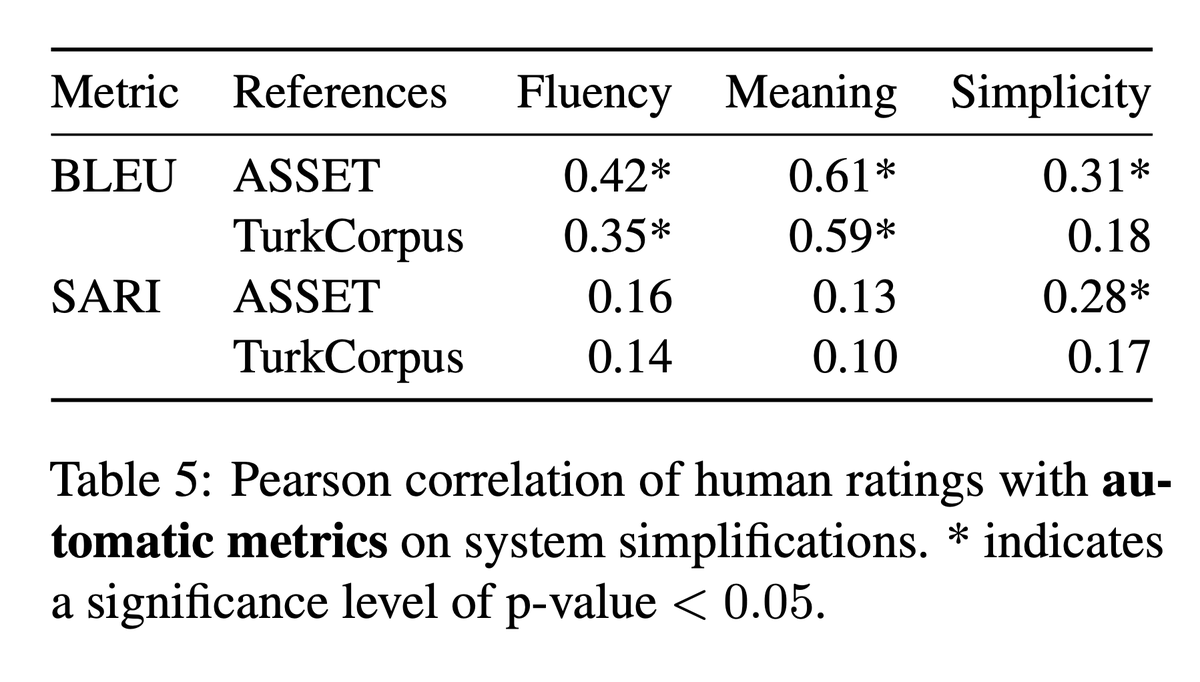
Mistral 2 is out 😍, try it out now on Le Chat: chat.mistral.ai/chat
mistral.ai/news/mistral-larg…
1
4
37
4,037
Louis Martin retweeted

4 Nov 2025
Full stack devs, SWEs, MLEs, forward deployed engineers, research engineers, applied scientists: we are hiring!
Join us and tackle cutting-edge challenges including physical AI, time series, material sciences, cybersecurity and many more.
Positions available in Paris, London, Singapore, Amsterdam, NYC, SF, or remote.
jobs.lever.co/mistral
90
97
1,167
156,322
Louis Martin retweeted
9 Sep 2025
We’ve raised €1.7B to accelerate technological progress with AI!
This Series C funding round, led by @ASMLcompany, fuels Mistral AI scientific research to keep pushing the frontier of AI to tackle the most critical technological challenges faced by strategic industries.
213
414
3,794
563,828
Louis Martin retweeted
12 Aug 2025
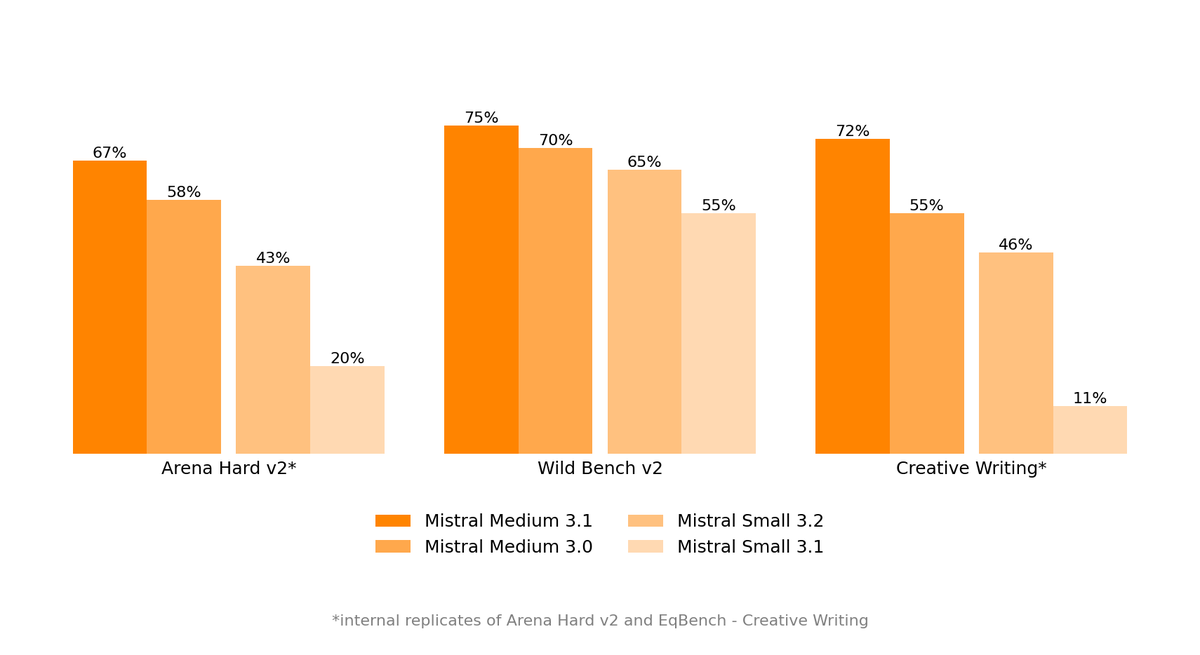
Introducing Mistral Medium 3.1.
Overall performance boost, tone improvement, smarter web searches.
Try it now in Le Chat (default model) or via our API (`mistral-medium-2508`).
107
238
2,215
296,672
Louis Martin retweeted
10 Jun 2025
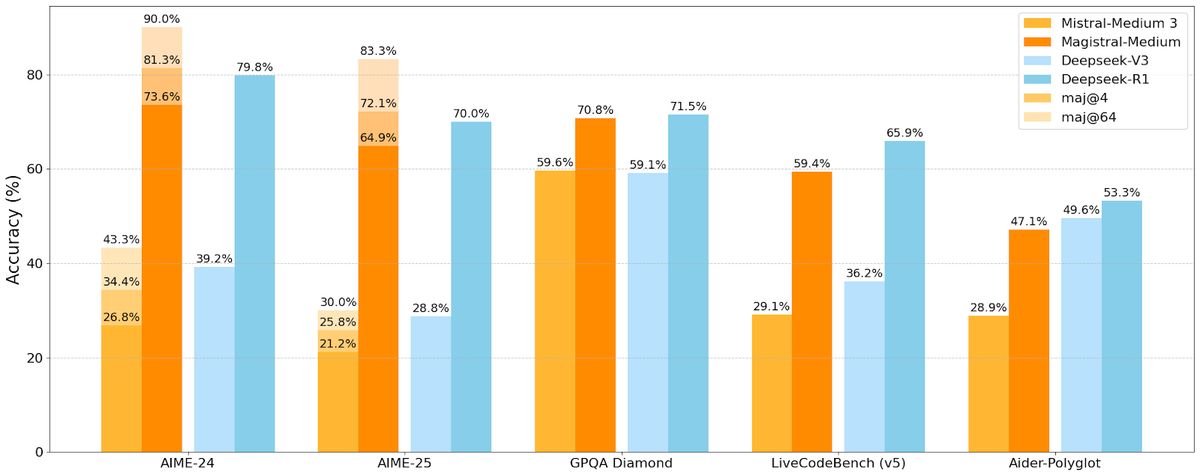
Announcing Magistral, our first reasoning model designed to excel in domain-specific, transparent, and multilingual reasoning.
103
436
3,042
733,193
Louis Martin retweeted

9 Feb 2025
Ne téléchargez pas Le Chat parce qu'il est français.
Téléchargez-le parce qu'il a le meilleur temps de réponse au monde ( 12x celui de ChatGPT) avec une qualité de modèle comparable (et même supérieure sur certains aspects).
L'offre est objectivement meilleure pour une bonne partie des cas d'usage. Si ce n'est pas le vôtre, ce n'est pas grave! Il nous reste du travail à faire.
Mais l'objectif est de vous faire une offre réellement compétitive sans avoir besoin de compter sur votre biais patriotique pour y parvenir.
225
444
3,726
830,004
Louis Martin retweeted

7 Feb 2025
Vive Le Chat ! 🇫🇷
6 Feb 2025

Introducing the all new Le Chat: your ultimate AI sidekick for life and work! Now live on web and mobile!
1,932
1,195
13,209
2,670,552
Louis Martin retweeted
6 Feb 2025
Le Chat is fast (1,100 tok/s for flash queries on an updated Mistral Large). Download it at mistral.ai/app/android or mistral.ai/app/ios
199
512
3,000
731,152
Louis Martin retweeted
6 Feb 2025
Introducing the all new Le Chat: your ultimate AI sidekick for life and work! Now live on web and mobile!
611
1,918
12,314
6,264,496
Louis Martin retweeted

6 Feb 2025
🚀 Announcing the all new @MistralAI Le Chat – your ultimate AI sidekick for life & work, now live on mobile!
So many exciting features 🧵:
47
52
558
51,384
Louis Martin retweeted
30 Jan 2025
magnet:?xt=urn:btih:11f2d1ca613ccf5a5c60104db9f3babdfa2e6003&dn=Mistral-Small-3-Instruct&tr=udp:/%2Ftracker.opentrackr.org:1337/announce&tr=http:/%https://t.co/ua2yzvEYLu:1337/announce
306
457
4,995
882,890
Louis Martin retweeted
18 Nov 2024
We're proud to introduce the next generation of le Chat. Search, PDF upload, coding, image generation, le Canevas... All in one place: chat.mistral.ai/
mistral.ai/news/mistral-chat…
147
517
3,274
597,348
Louis Martin retweeted

15 Nov 2024
CamemBERT 2.0: A Smarter French 🇫🇷 Language Model Aged to Perfection 👌
We release a much-needed update for the previous. SOTA French encoder LM.
We introduce two new models CamemBERTa-v2 and CamemBERT-v2, based on the DeBERTaV3 and RoBERTa recipe.
So what's new?
[1/8]
4
35
150
19,027
Louis Martin retweeted

5 Nov 2024
🌟 AI enthusiasts! Join @MistralAI and shape the future of generative AI! 🌟
We're hiring AI Scientists, Research Engineers, and more
🌐 Check out our openings: jobs.lever.co/mistral
🚀 Be part of a brilliant team working on cutting-edge projects. #AIJobs #TechCareers
7
30
153
19,320
Louis Martin retweeted

16 Oct 2024
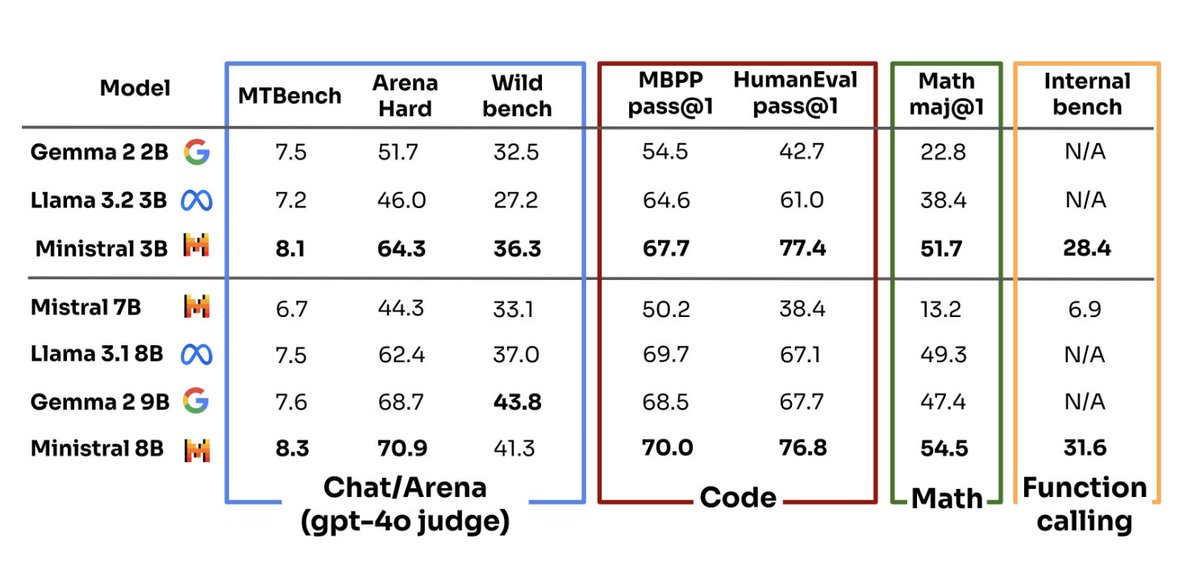
We just released two small models, with 3B and 8B parameters. Ministral 3B is exceptionally strong, outperforming Llama 3 8B and our previous Mistral 7B on instruction following benchmarks.
mistral.ai/news/ministraux/

18
75
584
92,208
Louis Martin retweeted

11 Sep 2024
state of ai twitter bubble
8
28
739
39,672
Louis Martin retweeted
11 Sep 2024
magnet:?xt=urn:btih:7278e625de2b1da598b23954c13933047126238a&dn=pixtral-12b-240910&tr=udp:/%2Ftracker.opentrackr.org:1337/announce&tr=udp:/%https://t.co/2UepcMHjvL:1337/announce&tr=http:/%https://t.co/NsTRgy7h8S:80/announce
311
585
5,046
1,139,745
Louis Martin retweeted
24 Jul 2024
Today, we release Mistral Large 2, the new version of our largest model. Mistral Large 2 is a 123B-parameter model with a 128k context window. On many benchmarks (notably in code generation and math), it is superior or on par with Llama 3.1 405B. Like Mistral NeMo, it was trained on a very large amount of source code and multilingual data. (1/N)
24 Jul 2024
47
259
2,164
534,882
Louis Martin retweeted

24 Jul 2024
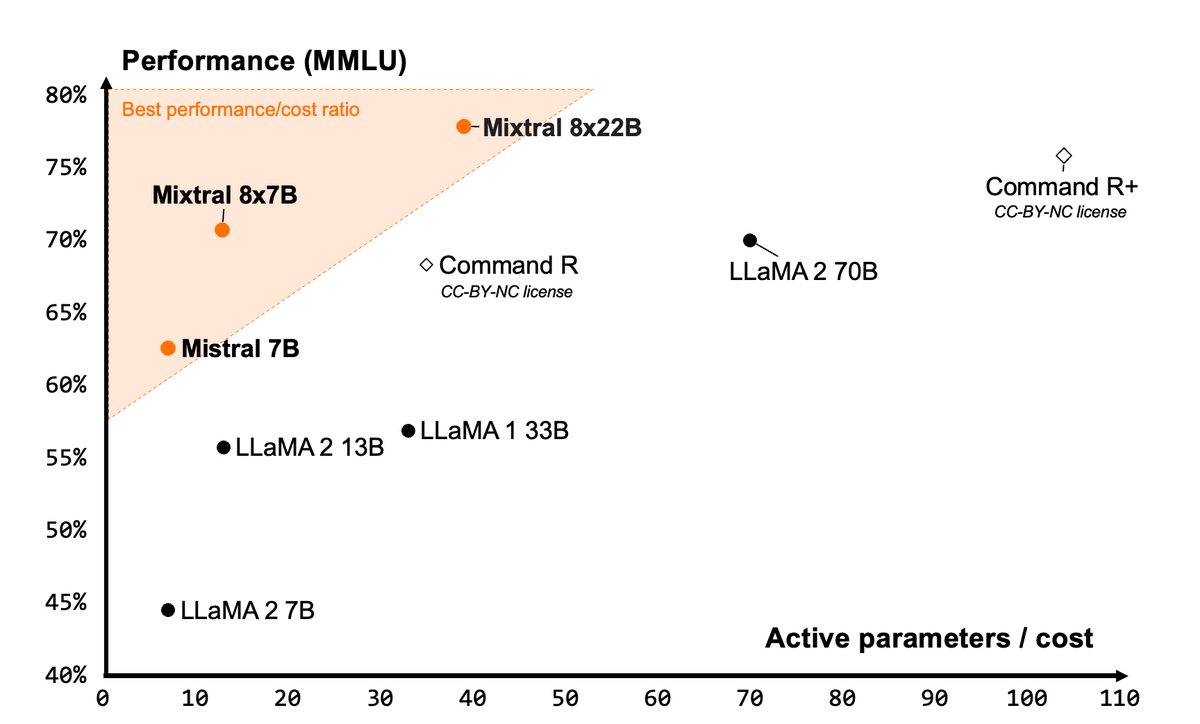
Largement sur le Pareto
24 Jul 2024
14
12
182
28,934
Louis Martin retweeted
24 Jul 2024
160
349
2,205
790,290