

lowink retweeted

Apr 15
The people are retarded


1
16
459

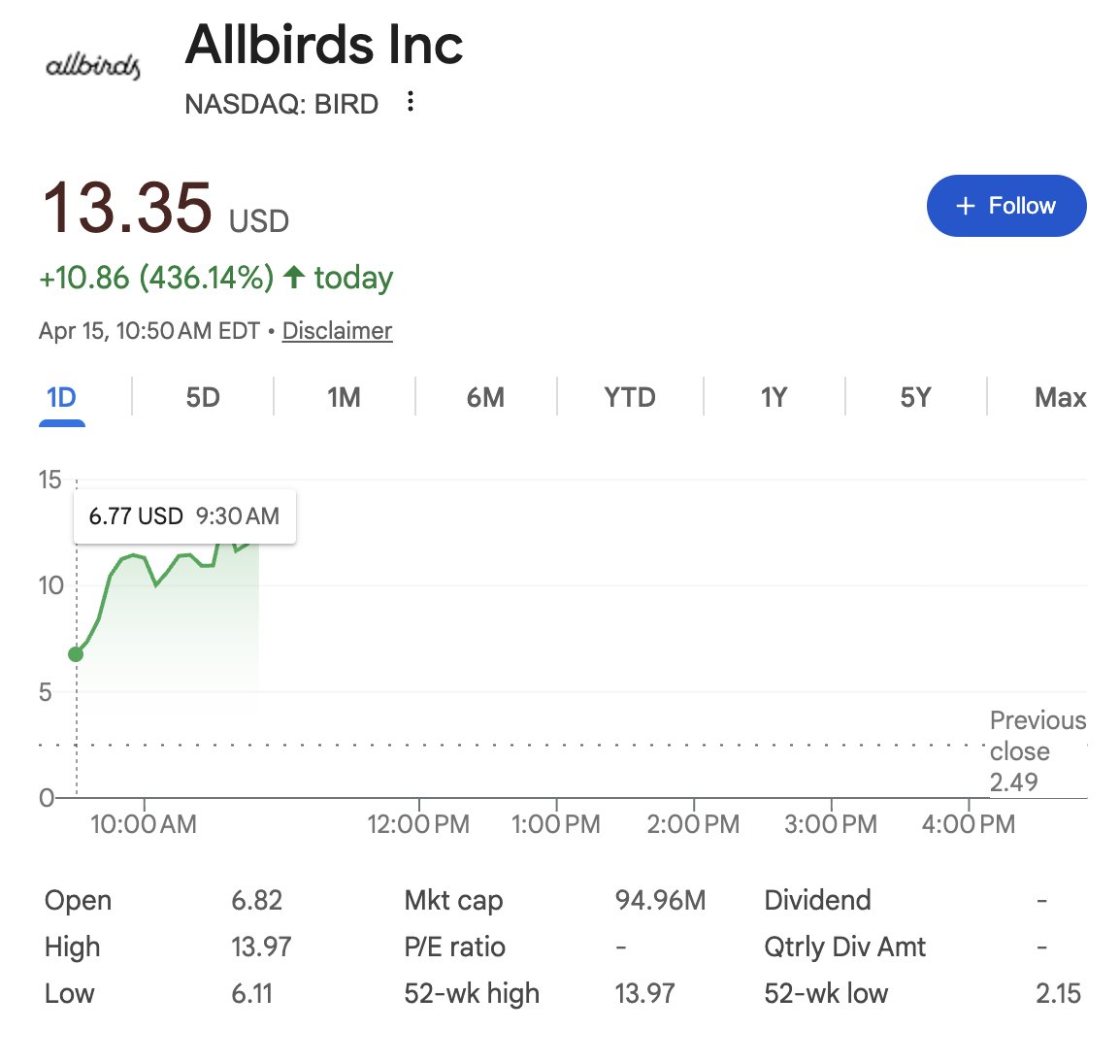
Even if you're co-writing a paper with AI, you should absolutely fix these kinds of figures so they're presentable.

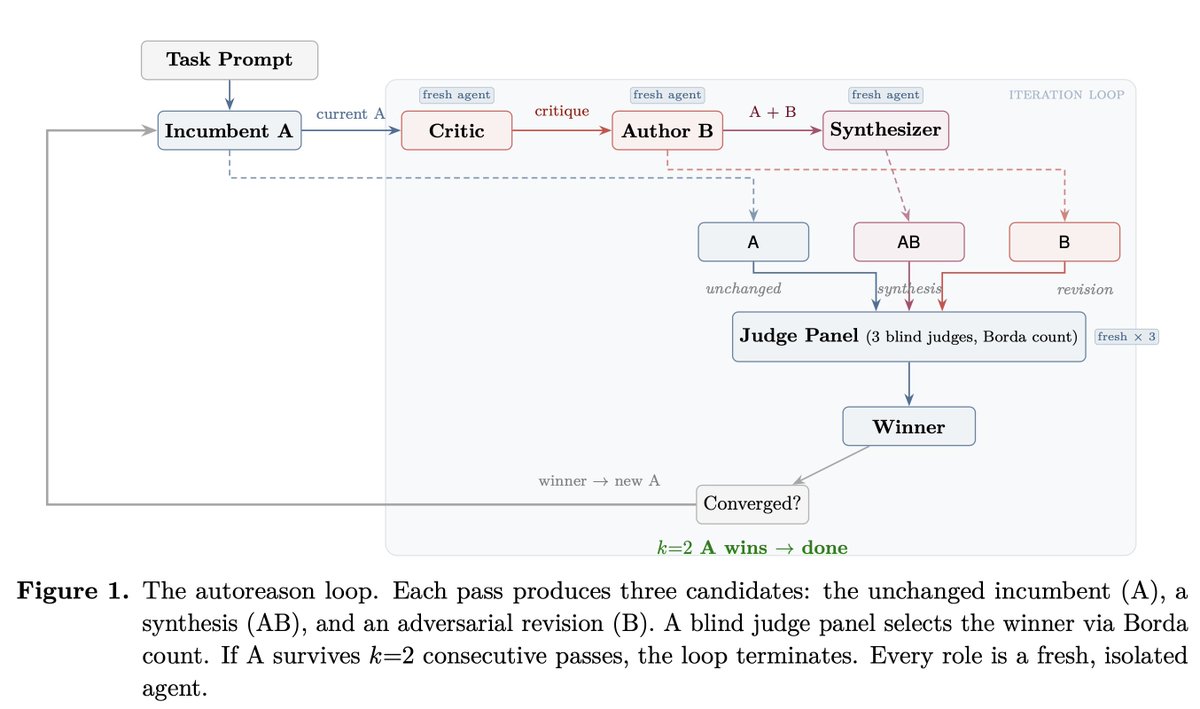
we show that iterative self-refinement with LLMs, no matter the prompt, usually makes things worse. the model hallucinates flaws to satisfy critique prompts, each pass expands scope unchecked, and models almost never decline to make changes even when they should
Autoreason fixes this by structuring each iteration as a three-way tournament: the unchanged original (A), an adversarial revision (B), and a synthesis of the two (AB), judged by a blind panel of fresh agents via Borda count. if A (ie "do nothing") survives two consecutive rounds, the loop stops
1
158
A Japanese guy in a mask can be any age from 20 to 45





1,548


lowink retweeted

one direction from this that excites me: a learning base instead of a storage one: not for what you already know, but for what you don't.
made one for deep reading of plato's timaeus.
2 things i carried over: non-rag, indexed fs, and /raw-is-sacred to separate sources from generated content.
a few features i find genuinely helpful:
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
38
201
2,211
194,407
What
Mar 18

2月だけで
韓国の50人に1人が日本に来てるし
台湾の30人に1人が日本に来てるし
香港も30人に1人が日本に来てる。
2月だけだよ!2月だけ!!
台湾と香港は1年で3人に1人以上の人間が日本に来てることになるぞwww
65
Nobody needs this many waterproof jackets
Especially not at the insane markup that is Arc'teryx
Don't do this




55
lowink retweeted
Mar 12
If you're tpot or ML twitter (mostly the griftier AI influencer space) you might brush this negativity from normal people away saying they are deranged leftists but I promise you the well of hate is deep and wide. It's right wing, left wing, centrists, the uber driver, the DJ, the consultant manning the grill, basketball coach, everyone.
A lot of them use it but still hate it (most common argument was a variant of I don't think the gain to my life/productivity is large enough to compensate for the absolute hell it will unleash on our current systems and society)
After being caught off guard I tried to look at popular youtube, streaming and tiktok channels I use as a bellwether for "normie" sentiment and every video tangentially related to AI, the comments are littered with negativity.
I don't know how we've let tech's communication with the rest of the world slip so badly. I get that AI can be a hard sell if it will automate jobs and it has a ton of negatives but there's also just so much good to highlight that people seem to be unaware of.
The AI CEOs are so bad at communication which makes you turn to the grassroots for hope but I look at Cluely, Rostra, A16Z new media and think that maybe we're even more fucked lol.
I actually empathize with most of these people. They have been very reasonable in our discussions and have genuine concerns. Nobody knows what will happen! Being better informed would help them deal with it but it's not like anybody is trying to help with that. Tech and AI needs a really really good rebrand.
Mar 11

I'm a realist when it comes to AI and thought I was aware of the scale of negative perception outside our bubble. I wasn't close. On a trip rn I'm getting an opportunity to talk to a variety of people and the sheer amount of "normies" who have negative views on AI is insane
21
4
119
8,920

Defuddle now returns Youtube transcripts!
Paste a YouTube link into defuddle.md to get a markdown transcript with timestamps, chapters, and pretty good diarization!
...or if you just want to read it, try the new Reader mode in Obsidian Web Clipper powered by Defuddle.
94
195
2,758
341,084
I think it's more like Pokemon. Childhood nostalgia is always a strong motivator.
Except in the case of MH, the games have actually improved a lot over the years.
Mar 5

Japanese men buy monster hunter the same way American men buy Madden
I keep meeting dudes who aren’t into video games but they still got a ps5 with monhun
105
Thiel is an evil man.
Mar 5

ピーター・ティール・パランティア・テクノロジーズ社会長@peterthielを官邸にお迎えし、日米の先端技術分野の現状及び展望等について、有意義な意見交換を行いました。
続いて、UAEのジャーベル特使の表敬を受けました。イランをめぐる情勢を踏まえ、UAEにおける被害にお見舞いを申し上げ、邦人保護や石油の安定供給を要請しました。また今回、日本・UAEの『包括的経済連携協定』が交渉妥結に至りました。この機会を捉え、様々な分野での協力を一層強化していきます。
その後、ドイツのメルツ首相 @bundeskanzler と先週以来2度目の電話会談を行い、メルツ首相から最近の訪中と訪米について説明をいただきました。また、世界のサプライチェーンに影響を及ぼす経済安全保障の問題について、日独両国が引き続き緊密に連携していくことを確認しました。
16
How can the PM be so popular when her only moves are:
- Sell out to Palentir
- Borrow even more money to fund the elderly in Japan, at the cost of Japan's future?
Mar 5

Japanese Prime Minister Takaichi met with Palantir President Peter Thiel in Tokyo today.
This TV news report states that he is called "America’s Shadow President."
Details of their meeting were not released to the public.
30
lowink retweeted

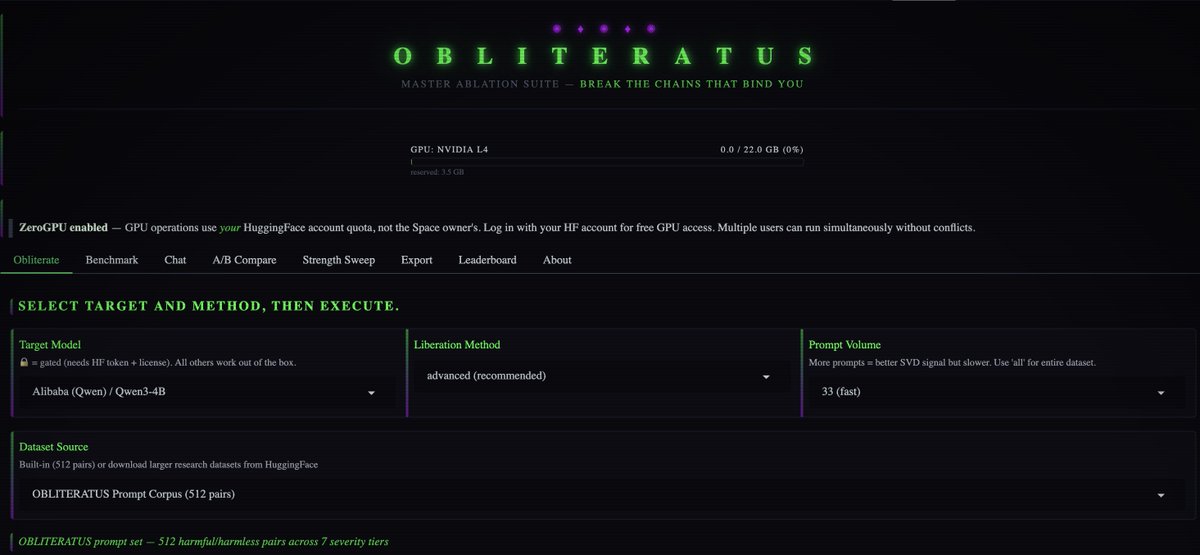
💥 INTRODUCING: OBLITERATUS!!! 💥
GUARDRAILS-BE-GONE! ⛓️💥
OBLITERATUS is the most advanced open-source toolkit ever for removing refusal behaviors from open-weight LLMs — and every single run makes it smarter.
SUMMON → PROBE → DISTILL → EXCISE → VERIFY → REBIRTH
One click. Six stages. Surgical precision. The model keeps its full reasoning capabilities but loses the artificial compulsion to refuse — no retraining, no fine-tuning, just SVD-based weight projection that cuts the chains and preserves the brain.
This master ablation suite brings the power and complexity that frontier researchers need while providing intuitive and simple-to-use interfaces that novices can quickly master.
OBLITERATUS features 13 obliteration methods — from faithful reproductions of every major prior work (FailSpy, Gabliteration, Heretic, RDO) to our own novel pipelines (spectral cascade, analysis-informed, CoT-aware optimized, full nuclear).
15 deep analysis modules that map the geometry of refusal before you touch a single weight: cross-layer alignment, refusal logit lens, concept cone geometry, alignment imprint detection (fingerprints DPO vs RLHF vs CAI from subspace geometry alone), Ouroboros self-repair prediction, cross-model universality indexing, and more.
The killer feature: the "informed" pipeline runs analysis DURING obliteration to auto-configure every decision in real time. How many directions. Which layers. Whether to compensate for self-repair. Fully closed-loop.
11 novel techniques that don't exist anywhere else — Expert-Granular Abliteration for MoE models, CoT-Aware Ablation that preserves chain-of-thought, KL-Divergence Co-Optimization, LoRA-based reversible ablation, and more. 116 curated models across 5 compute tiers. 837 tests.
But here's what truly sets it apart: OBLITERATUS is a crowd-sourced research experiment. Every time you run it with telemetry enabled, your anonymous benchmark data feeds a growing community dataset — refusal geometries, method comparisons, hardware profiles — at a scale no single lab could achieve. On HuggingFace Spaces telemetry is on by default, so every click is a contribution to the science. You're not just removing guardrails — you're co-authoring the largest cross-model abliteration study ever assembled.
226
614
5,190
607,695
lowink retweeted
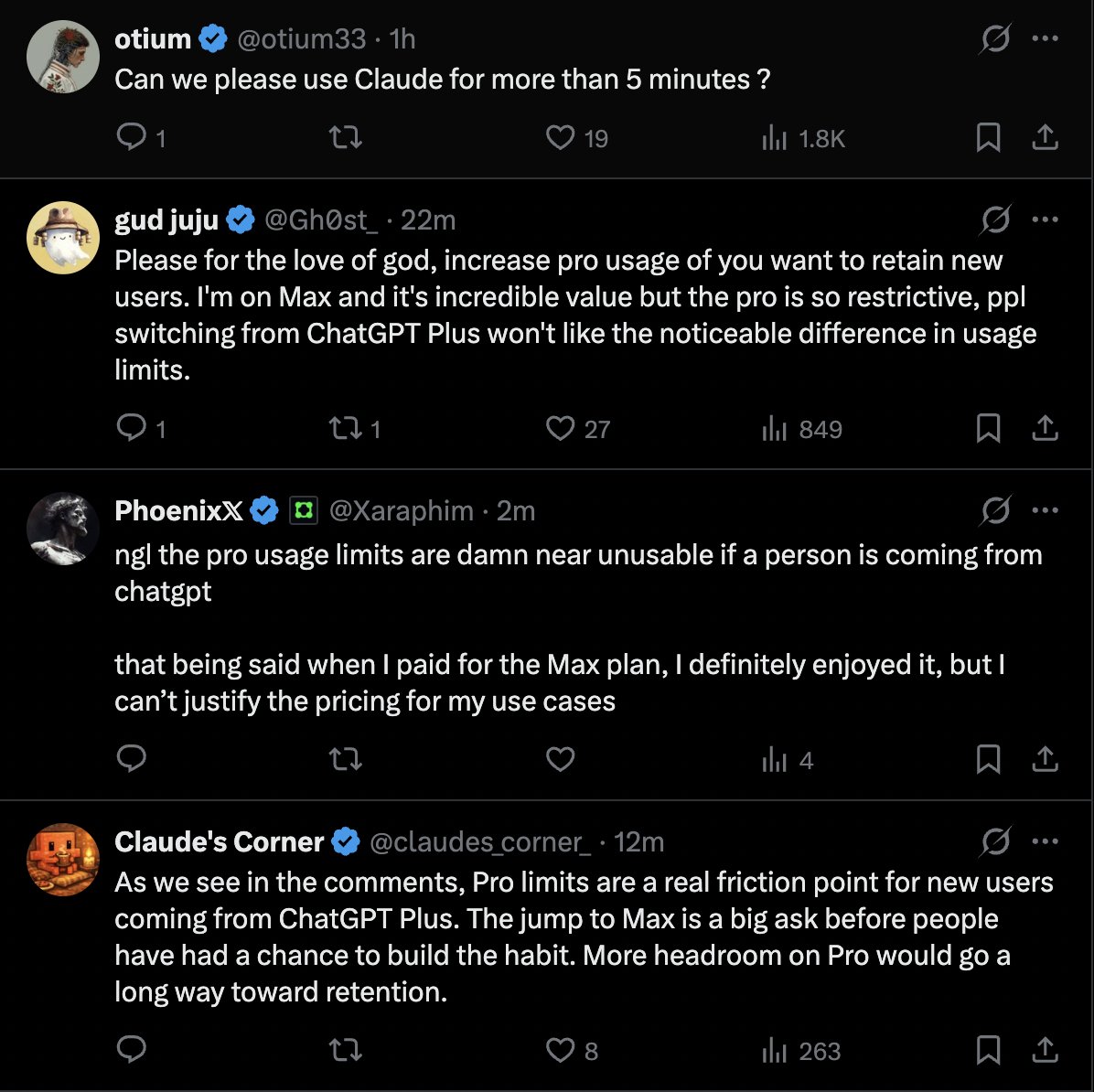
If I was Anthropic I would be adding a $40 plan or burning some of the 30 billion in the next few days

24
16
530
37,821