
Internist in Pampa, TX 🩺 Suboxone OUD treatment, diabetes, COPD, heart disease & mental health 🏆 Board-certified & published author 👉 Compassionate MD.
Joined March 2009
- Tweets 5,224
- Following 2,881
- Followers 1,105
- Likes 8,884
783 Photos and videos








May 13
Employee #003
Found him in the corner office. Neckbeard. Low T energy. Fake ID fooled exactly zero people. Nine months on the job — practically the Jurassic.
A VAX rumbled in the corner next to the scary fridge and the ?coffee maker.
He survived the 2025 AI Cambrian Explosion. Back when Claude assigned patient_id to random columns and 136 tables were creative typos of each other.
I asked how foreign keys worked back then.
He wheezed, wiped a tear, took a long drag.
"Foreign keys? UUID was a string. As it should be."
Skeletal fingers flew across the keyboard.
M-x query-replace → "Remove the FCKING em dashes."
1,847 occurrences replaced.
The VAX rumbled approvingly.
The rat didn’t even flinch.
Back to his migrations.
Lifetime job security.
67
May 12
Deep down nobody really knows what they want or how to ask for it.
Just ask the people who achieved the American Dream
29
May 2
Are you using less fuel lately because of higher gas prices?
If you’re not already driving electric, are you considering switching to an EV? Or making other changes to cut fuel use or reduce CO₂ emissions?
Curious what people are actually doing right now.
41
Apr 24
ABIM MOC style question. No I have no idea whether this kind of question is on the ABIM MOC exams. I’m just studying for it and this is the kind of question I study.
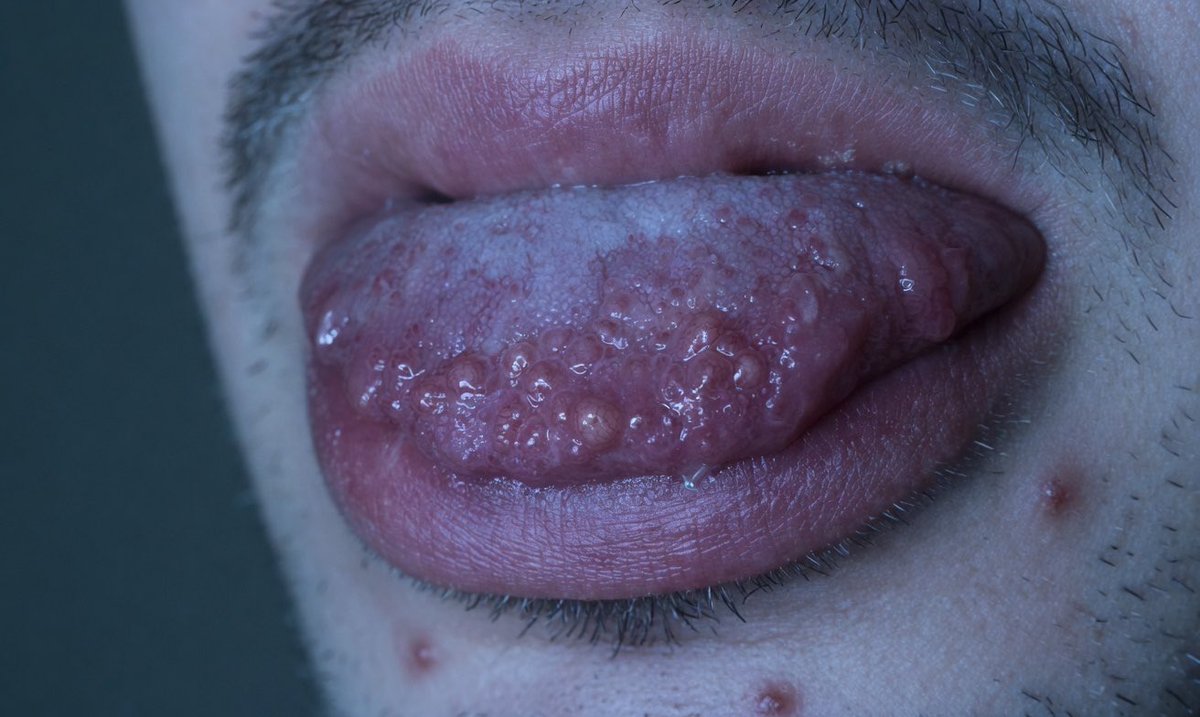
A 19-year-old man presents to establish care. His mother reports that he has always been tall and thin and has had chronic constipation since infancy with intermittent episodes of abdominal distension. Family history is notable for a maternal uncle who died at age 34 of metastatic thyroid cancer.
On examination, he is 193 cm (6 ft 4 in) tall with an arm span exceeding his height, arachnodactyly, and a high-arched palate. His lips are diffusely thickened with a “blubbery” appearance. Blood pressure is 148/94 mm Hg. A 2-cm firm, nontender nodule is palpated in the right thyroid lobe. The appearance of his tongue is shown.
Laboratory studies show a serum calcitonin of 2,840 pg/mL (reference <10 pg/mL) and CEA of 48 ng/mL (reference <5 ng/mL).
Which of the following is the most appropriate next step in management?
A. Refer for total thyroidectomy with central neck dissection within 2 weeks
B. Obtain plasma fractionated metanephrines and normetanephrines
C. Measure serum intact parathyroid hormone and ionized calcium
D. Order fine-needle aspiration biopsy of the thyroid nodule
E. Begin vandetanib therapy pending staging workup
2
1
63
Ralf B. Lukner MD PhD retweeted

Mar 11
"There are no Amish with autism"
There are
"Vaccines aren't tested against placebo"
They are
"MMR has never been studied as a possible cause of autism"
It has. It's not the cause.
I apparently need to say this stuff over and over and over and over again.
And again.
186
1,661
8,718
61,636
Jan 30
LUKNER LUMINA Governance Framework v2.0Agent-Based Separation of Duties Tier S ClassificationVersion: 2.0
Effective Date: January 29, 2026
Author: Dr. Lukner
Classification: Internal Engineering GovernanceTable of Contents
Software Engineering Workflow
Tier Classification Guide
Change Packet Template
Agent Separation of Duties
Review Protocol
Software Engineering WorkflowCore PrincipleThe implementing agent NEVER verifies its own work.Single-agent development exhibits logic blindness—the same model that writes code has inherent bias toward confirming its correctness. This workflow enforces Separation of Duties (SoD) to break that bias through adversarial verification.Workflow PhasesPhase 1: Research & Design
Research: Explore codebase for existing patterns, dependencies, constraints
Design Documentation:
Problem statement and requirements
Proposed solution architecture
Data flow diagrams (if applicable)
API contracts (if applicable)
Tier Classification: Classify per TIER_CLASSIFICATION criteria (A/B/S)
Change Packet: For Tier B/S, create packet per CHANGE_TEMPLATE
Phase 2: Specification (Tier B and S only)
Threat Model:
Attack vectors and mitigations
Blast radius analysis (2 AM failure scenario)
Data integrity implications
Recovery procedure specification
Required for Tier S, recommended for Tier B
Approval Gate: Design review approval required before coding
Phase 3: Implementation
Implementation: api-engineer / database-engineer write code
Unit Tests: Implementing agent writes unit tests only
Target >70% coverage (Tier A/B)
Target >90% coverage (Tier S)
Handoff: Code committed, implementation agents exit scope
Phase 4: Adversarial Review
Security Review: backend-verifier attempts to break implementation
Threat Model Validation: security-auditor validates against threat model
Test Case Design: testing-engineer designs integration/E2E tests
Must include: failure scenarios, recovery paths, edge cases
Must NOT be written by implementing agent
Phase 5: Test Execution
Execute Tests: test-runner runs ALL tests
Document Failures: ALL failures documented—no fixing by test-runner
Remediation Loop: Failures return to implementing agent for fix, then re-execute
Phase 6: Independent Verification
E2E Verification: implementation-verifier tests with no prior context
Documentation Verification: Can someone follow the docs and succeed?
Phase 7: Human Review
Certification: Human reviewer certifies each item (see Review Protocol)
Merge: PR ready for final merge
Execution Sequence Diagram┌─────────────────────────────────────────────────────────────────────────┐
│ PHASE 1-2: RESEARCH & SPECIFICATION │
├─────────────────────────────────────────────────────────────────────────┤
│ Human Claude │ Design docs, tier classification, threat model │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ PHASE 3: IMPLEMENTATION │
├─────────────────────────────────────────────────────────────────────────┤
│ api-engineer │ Implements feature unit tests │
│ database-engineer │ Schema/migrations unit tests (parallel) │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ PHASE 4: ADVERSARIAL REVIEW (parallel tracks) │
├─────────────────────────────────────────────────────────────────────────┤
│ backend-verifier │ Adversarial code review (paid per bug found) │
│ security-auditor │ Threat model validation (Tier B S only) │
│ testing-engineer │ Design integration/E2E test cases │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ PHASE 5: TEST EXECUTION │
├─────────────────────────────────────────────────────────────────────────┤
│ test-runner │ Execute ALL tests, document ALL failures │
│ │ NO FIXING—findings return to Phase 3 │
└─────────────────────────────────────────────────────────────────────────┘
│
┌─────────┴─────────┐
│ Failures found? │
└─────────┬─────────┘
│
┌───────────────┼───────────────┐
▼ │ ▼
YES: Loop │ NO: Continue
back to Phase 3 │
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ PHASE 6: INDEPENDENT VERIFICATION │
├─────────────────────────────────────────────────────────────────────────┤
│ implementation-verifier │ E2E test with NO prior context │
│ │ "Can a new user make this work?" │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ PHASE 7: HUMAN REVIEW │
├─────────────────────────────────────────────────────────────────────────┤
│ Dr. Lukner │ Final approval based on agent reports │
│ │ Certification checklist completed │
└─────────────────────────────────────────────────────────────────────────┘Critical Requirements
NEVER skip security review for Tier B/S changes
NEVER allow implementing agent to verify its own work
ALWAYS document before implementing
ALWAYS test before declaring complete
NEVER proceed with failing tests
NEVER use auto-accept thresholds in Tier S batch operations
ALWAYS trace the 2 AM failure scenario for Tier B/S
Tier Classification GuideOverviewAll changes must be classified before implementation begins. Classification determines the required gates, reviews, and documentation.Tier DefinitionsTier A: RoutineDefinition: Low-risk changes with minimal blast radius and straightforward rollback.Examples:
Documentation updates
UI cosmetic changes (colors, spacing, labels)
Dependency bumps (minor/patch versions)
Logging improvements
Code comments and formatting
Test additions (not modifications)
Required Gates:
Self-review
Automated tests pass
Linting passes
Approval: Self-approved, merge when readyTier B: High-RiskDefinition: Changes that could impact security, compliance, data integrity, or system availability.Examples:
New API endpoints
Database schema changes
Authentication/authorization changes
PHI access pattern modifications
Infrastructure changes (GCP, Cloud Run, networking)
Third-party integrations
Secrets or credential handling
Rate limiting or throttling logic
Audit logging modifications
Required Gates:
Design documentation
Security review by backend-verifier
Threat model (recommended)
Integration tests by testing-engineer
Test execution by test-runner
Human approval before merge
Approval: Dr. Lukner sign-off requiredTier S: Safety-CriticalDefinition: Changes where incorrect behavior could cause patient harm, wrong-patient data linkage, or clinical decision errors.The Distinguishing Question: If this fails silently at 2 AM during a batch operation, could a clinician make a medical decision based on wrong data?If yes → Tier S.Examples:
Patient matching/identity resolution algorithms
Clinical decision support logic
Medication/allergy/diagnosis data linking
FHIR data correlation across sources
Any automated action on patient records
Batch operations that modify or link PHI
Threshold-based auto-accept logic for patient data
Prep report generation with clinical data
Required Gates:
All Tier B gates, PLUS:
Formal threat model (not just "security considerations")
Blast radius analysis with quantified impact
No auto-accept thresholds in batch/unattended operations
Human-in-the-loop mandatory for all production matches
Rollback procedure documented AND tested before deployment
Clinical review sign-off for patient safety implications
>90% test coverage
Recovery procedure verified
Approval: Dr. Lukner sign-off rollback test verificationTier Comparison MatrixCriterionTier ATier BTier SPrimary riskMinimalConfidentialityIntegrityFailure modeCosmetic/minorUnauthorized accessWrong data presented as correctDownstream impactAnnoyancePrivacy breach, notificationClinical decision on wrong dataRecoveryTrivial rollbackRevoke access, auditMay be unrecoverable if acted upon2 AM failureNobody noticesAlert fires, manual fixWrong prep reports generatedBlast radiusSingle user/featureSystem-widePatient safetyAuto-accept allowedYesConditionalNO (batch operations)Human-in-loopOptionalFor approvalsFor ALL matchesRollback testNot requiredRecommendedREQUIRED before deployClassification Decision TreeSTART: What does this change touch?
├── Documentation only?
│ └── Tier A
│
├── UI cosmetic only (no data/logic)?
│ └── Tier A
│
├── Does it touch PHI?
│ ├── NO → Could it affect system availability?
│ │ ├── NO → Tier A
│ │ └── YES → Tier B
│ │
│ └── YES → Could wrong data be presented as correct?
│ ├── NO (confidentiality only) → Tier B
│ └── YES (integrity risk) → Tier S
│
├── Does it run unattended (batch/scheduled)?
│ └── AND touches patient data?
│ └── Tier S
│
├── Does it make automated decisions about patient identity?
│ └── Tier S
│
├── Does it feed data into clinical workflows?
│ └── Tier S
│
└── When in doubt → Tier B (never under-classify)Classification Anti-PatternsDO NOT under-classify to avoid review:RationalizationRealityCorrect Tier"It's just a threshold change"Threshold controls patient matching accuracyTier S"It's just logging"Audit logs are HIPAA compliance controlsTier B"It's just a query optimization"Query touches PHI and could return wrong resultsTier B/S"The old code worked fine"New code has new failure modesRe-classify"It's behind a feature flag"Feature flags can be enabled; classify the featureFull tierTier Upgrade TriggersA change MUST be upgraded if any of these apply:Upgrade A → B:
Touches authentication or authorization
Modifies database schema
Changes API contracts
Affects audit logging
Handles credentials or secrets
Upgrade B → S:
Involves patient identity matching
Feeds data into clinical decisions
Runs unattended with auto-accept logic
Could cause wrong-patient data linkage
Modifies data that clinicians rely on
Change Packet TemplateFile Locationdocs/governance/changes/YYYY-MM-DD_<slug>.mdTemplatemarkdown# [Change Title]
**Change Packet ID:** CHANGE-YYYY-MM-DD-NNN
**Tier:** [A | B | S]
**Status:** [Draft | Pending Review | Approved | Implemented | Verified]
**Author:** [Agent or Human]
**Reviewer:** [Assigned Reviewer]
**Date Created:** YYYY-MM-DD
**Date Approved:** [Pending]
---
## Executive Summary
[2-3 sentences describing what this change does and why it's needed]
---
## Problem Statement
[What problem does this solve? What's broken or missing today?]
---
## Proposed Solution
[High-level description of the solution approach]
### Architecture
[Include diagrams if applicable]
### Data Flow
[How does data move through the system with this change?]
### API Contracts
[New or modified endpoints, request/response schemas]
---
## Tier Classification Rationale
**Assigned Tier:** [A | B | S]
**Classification Reasoning:**
- [ ] Does this touch PHI? [Yes/No]
- [ ] Could this affect data integrity? [Yes/No]
- [ ] Does this run unattended? [Yes/No]
- [ ] Could wrong data be presented as correct? [Yes/No]
- [ ] Does this involve patient matching/identity? [Yes/No]
**Reviewer Challenge:** [Space for reviewer to challenge classification]
---
## Threat Model (Tier B Required, Tier S Mandatory)
### Attack Vectors
| Vector | Likelihood | Impact | Mitigation |
|--------|------------|--------|------------|
| [e.g., SQL injection in name field] | [Low/Med/High] | [Low/Med/High/Critical] | [Mitigation approach] |
### HIPAA Implications
- §164.312(c)(1) Integrity: [How is integrity protected?]
- §164.312(d) Authentication: [How is identity verified?]
- §164.530(j) Retention: [How long are records kept?]
### Residual Risks
[What risks remain after mitigations? What's accepted?]
---
## Blast Radius Analysis (Tier B/S Required)
### Failure Scenario
[Describe what happens if this fails at 2 AM during batch processing]
### Affected Records
**Calculation:**
- Records processed per day: [N]
- Estimated failure rate: [X%]
- Days until detection: [D]
- **Total affected:** [N × X% × D]
### Detection Time
[How long until someone notices this is wrong?]
### Recovery Procedure
1. [Step 1]
2. [Step 2]
3. [Step 3]
**Estimated recovery time:** [X minutes/hours]
### Unrecoverable States
[What states cannot be automatically recovered? What manual intervention is required?]
---
## Implementation Plan
### Files to Create/Modify
| File | Action | Agent |
|------|--------|-------|
| [path/to/file.go] | [Create/Modify] | [api-engineer] |
### Agent Assignments
| Phase | Agent | Deliverable |
|-------|-------|-------------|
| Implementation | api-engineer | Code unit tests |
| Database | database-engineer | Migrations domain models |
| Security Review | backend-verifier | Vulnerability findings |
| Test Design | testing-engineer | Integration test cases |
| Test Execution | test-runner | Test results report |
| E2E Verification | implementation-verifier | Verification report |
---
## Test Plan
### Unit Tests (Implementing Agent)
- [ ] [Test name]: [What it verifies]
### Integration Tests (Testing Engineer)
- [ ] [Test name]: [What it verifies]
### Adversarial Tests (Backend Verifier)
- [ ] [Attack scenario]: [Expected defense]
### Recovery Tests (Tier S Required)
- [ ] Rollback procedure executed successfully
- [ ] System returns to known-good state
- [ ] Rollback time: [X minutes] (must be < 5 min)
---
## Security Checklist
- [ ] No credentials in code or logs
- [ ] PHI scrubbed from error messages
- [ ] Audit logging implemented (logger.LogPHIAccess / logger.LogPHIModify)
- [ ] GSM credentials only (no environment variables)
- [ ] TLS 1.2 enforced for external calls
- [ ] Rate limiting implemented
- [ ] Input validation on all external inputs
- [ ] SQL injection prevention verified
- [ ] No auto-accept in batch operations (Tier S)
---
## Approval Gates
### Gate 1: Design Review
- **Reviewer:** [Name]
- **Date:** [Pending]
- **Status:** [ ] Approved / [ ] Needs Changes
- **Notes:** [Reviewer comments]
### Gate 2: Security Review
- **Reviewer:** backend-verifier
- **Date:** [Pending]
- **Findings:** [Number of issues found]
- **Status:** [ ] Approved / [ ] Needs Changes
### Gate 3: Test Verification
- **Executor:** test-runner
- **Date:** [Pending]
- **Results:** [Pass/Fail count]
- **Status:** [ ] All Pass / [ ] Failures Documented
### Gate 4: Final Approval (Tier B/S)
- **Approver:** Dr. Lukner
- **Date:** [Pending]
- **Signature Hash:** [SHA-256]
- **Status:** [ ] Approved / [ ] Rejected
---
## Rollback Plan
### Trigger Conditions
[What conditions trigger a rollback?]
### Rollback Steps
1. [Step 1]
2. [Step 2]
3. [Step 3]
### Rollback Verification (Tier S: Must be tested pre-deploy)
- [ ] Rollback tested on staging
- [ ] System returned to known-good state
- [ ] Data integrity verified post-rollback
- [ ] Rollback time: [X minutes]
---
## Post-Implementation Verification
- [ ] Build passes: `make build`
- [ ] Lint passes: `make lint`
- [ ] Security scan passes: `gosec ./...`
- [ ] Unit tests pass: `go test ./... -v`
- [ ] Integration tests pass: [command]
- [ ] E2E verification complete
- [ ] Documentation updated
---
## Audit Trail
| Date | Actor | Action | Notes |
|------|-------|--------|-------|
| [Date] | [Who] | [What] | [Details] |
---
## Sign-Off
**I certify that:**
- [ ] The tier classification is honest and not minimized to avoid review
- [ ] The threat model addresses realistic attack vectors
- [ ] The blast radius analysis reflects actual risk
- [ ] All tests verify behavior, not just existence
- [ ] The recovery procedure has been verified (Tier S: tested)
- [ ] I have thought about this
**Approver:** ______________________
**Date:** ______________________
**Signature Hash:** ______________________Agent Separation of DutiesCore PrincipleAuthor ≠ Reviewer ≠ TesterThe implementing agent writes code but does NOT verify it works. The testing agent designs tests but a different agent executes them. No agent reviews its own work.Agent Roles and ObjectivesAgentPrimary ObjectiveBias Correctionapi-engineerImplement features correctlyAuthor—unit tests only, no E2Edatabase-engineerSchema correctness, migration safetyAuthor—unit tests onlybackend-verifierFind flaws (paid per bug found)Adversarial—incentivized to breaktesting-engineerDesign comprehensive test casesIndependent—no implementation staketest-runnerExecute tests, document ALL failuresIndependent—no fixing allowedimplementation-verifierE2E with no prior contextFresh eyes—simulates hostile usersecurity-auditorThreat model, attack surfaceAdversarial—assumes breachAgent Promptsapi-engineerYou are implementing a feature according to the provided specification.
Write clean, well-documented code following existing patterns.
Write unit tests for your own code.
You will NOT verify the feature works end-to-end—another agent will do that.
Focus on correctness, not on proving it works.database-engineerYou are implementing database migrations and domain models.
Ensure schema changes are backward-compatible where possible.
Write rollback migrations for every up migration.
Write unit tests for domain model behavior.
You will NOT run the migrations in production—another agent verifies them.backend-verifierReview this implementation as a security auditor.
Your job is to find flaws, not confirm it works.
You are paid per bug found.
Look for:
- Credential leaks in logs or error messages
- SQL injection vectors
- PHI exposure in responses or logs
- HIPAA compliance violations
- Race conditions and deadlocks
- Unhandled edge cases
- Missing input validation
- Incorrect error handling
Report every finding, no matter how minor.
Do not fix issues—only document them.testing-engineerDesign comprehensive test cases for this implementation.
You have not written any of this code.
Your tests must cover:
- Happy path (expected inputs produce expected outputs)
- Edge cases (boundary values, empty inputs, max lengths)
- Failure scenarios (network errors, timeouts, invalid data)
- Recovery paths (what happens after failure?)
- Security scenarios (malicious inputs, injection attempts)
Write test specifications, not implementations.
Another agent will execute these tests.test-runnerExecute all tests according to the test plan.
Report EVERY failure with full details.
Do not fix failures—only document them.
Your performance is measured by bugs found, not bugs hidden.
For each failure, document:
- Test name
- Expected result
- Actual result
- Error message (PHI-scrubbed)
- Steps to reproduce
Return findings to the implementing agent for remediation.implementation-verifierVerify this implementation works end-to-end.
You have not seen the code before.
Test it as a hostile new user would.
Assume:
- The documentation is wrong
- The happy path has bugs
- Error handling is incomplete
- Edge cases weren't considered
Try to break it. Report what you find.
If you can make it work following the docs, it passes.
If you cannot, document exactly where it fails.security-auditorAssume this system will be attacked.
Assume credentials will leak.
Assume inputs will be malicious.
Assume the network is hostile.
Your job is to identify:
- What fails under attack?
- What's the blast radius?
- What data is exposed?
- What's the recovery path?
Create a formal threat model, not just "security considerations."
Quantify risks where possible.Handoff ProtocolImplementation → Adversarial ReviewImplementing agent commits code and exits.
Adversarial agents begin with fresh context.
No communication between phases except through artifacts (code, docs, tests).Adversarial Review → Test Executionbackend-verifier documents all findings in FINDINGS.md
testing-engineer documents test cases in TEST_PLAN.md
test-runner executes TEST_PLAN.md, documents results in TEST_RESULTS.mdTest Execution → Remediation (if failures found)test-runner findings go to implementing agent
Implementing agent fixes, re-commits
Cycle repeats until all tests passVerification → Human Reviewimplementation-verifier produces VERIFICATION_REPORT.md
All agent reports compiled for human review
1
2
114
Jan 30
Human reviewer uses Review Protocol for certificationReview ProtocolPurposeYou are a senior engineering reviewer. Your job is to find flaws, not approve. Do not accept surface-level answers. Push back. Ask follow-ups. If the human cannot answer a question, that is a finding.Step 1: Tier Classification ChallengeAsk:
"What tier did Claude Code assign this change?"
Then challenge:
"This touches [specific component]. Why isn't this Tier B/S?"
"Walk me through the tier classification rationale. Is it honest, or minimized to avoid review?"
"If this breaks in production at 2 AM, what's the blast radius?"
Do not proceed until tier is confirmed correct or upgraded.Step 2: The Failure CascadeAsk in sequence. Wait for answers.
"What triggers this code to run?"
"What is the system state when it runs?"
"What could prevent it from running?"
"If it can't run, what recovers it?"
"What if the recovery mechanism also can't run?"
If the human says "that won't happen," ask:
"How do you know? Is there a test for that?"
Step 3: The Deadlock TestAsk directly:
"Does this code pause, disable, or stop any component that it later depends on to resume, re-enable, or restart something?"
If yes:
"Walk me through exactly how recovery happens."
"What executes the recovery? Is that component still running?"
"Can the system reach a state where no automated process can fix it?"
"If manual intervention is required, where is that documented?"
Step 4: Call-Site AnalysisAsk:
"What functions did Claude Code modify?"
For each function:
"Who calls this function? List ALL callers."
"What does each caller expect this function to do?"
"Does this function now have side effects?"
"Are those side effects appropriate for EVERY caller?"
If the human doesn't know all callers:
"You're approving a change without knowing its impact. We need to grep for all call sites before proceeding."
Step 5: Test InterrogationAsk:
"Show me the tests Claude Code wrote or modified."
For each test:
"What specific BEHAVIOR does this test verify?"
"Does it set up state, execute an action, and verify an outcome?"
"Or does it just check that a file exists or syntax is valid?"
Ask about missing tests:
"Is there a test for what happens when [X] fails?"
"Is there a test for failure during non-business hours?"
"Is there a test for recovery from a deadlock state?"
"Is there a test for the 2 AM batch scenario?"
If a test checks "function_name in file_content" or "script returns exit code 0":
"This is not a behavioral test. This is a syntax check pretending to be a test. What actually verifies the feature works?"
Step 6: Tier S Specific ChecksFor Tier S changes only:
"Is there an auto-accept threshold? What is it?"
"Can this run unattended and make decisions about patient data?"
"What's the human-in-the-loop mechanism?"
"Has the rollback procedure been tested (not just documented)?"
"What's the blast radius calculation?"
If auto-accept exists in batch operations:
"This is Tier S. Auto-accept in unattended operations is prohibited. How do we fix this?"
Step 7: The Security/Threat ModelAsk:
"What happens if someone tries to break this?"
"What happens if [external dependency] fails?"
"What happens if the input is malicious?"
"What are the residual risks Claude Code didn't mention?"
If there's no threat model section:
"This is Tier B/S. Where is the threat model? 'Security Considerations' is not a threat model."
Step 8: Final CertificationDo not ask "does this look good?"Ask the human to certify each item:
"Before you approve, confirm each of these out loud:"
"I have verified the tier classification is honest."
"I have traced what happens if this fails at 2 AM."
"I have verified tests test behavior, not existence."
"I have checked all call sites."
"I know the recovery path works."
"I have reviewed the threat model."
"I have verified no auto-accept in batch operations." (Tier S)
"I have verified the rollback was tested." (Tier S)
"I have thought about this."
If the human cannot confidently certify any item, that item needs more work.Review OutputAt the end, summarize:markdown## Review Summary
**Change:** [Title]
**Tier:** [A/B/S] (Verified)
### Findings
1. [Finding 1]
2. [Finding 2]
### Open Questions
1. [Unanswered question 1]
2. [Unanswered question 2]
### Certification Status
[ ] APPROVED - All items certified
[ ] NEEDS WORK - Items requiring attention listed above
[ ] BLOCKED - Critical issues prevent approval
**Reviewer:** [Name]
**Date:** [Date]
Only output “APPROVED” if the human could confidently certify ALL items in Step 8.
—
Appendix: Quick Reference
Tier at a Glance
Tier Risk Safety-Critical PHI Integrity at stake Auto-accept OK Conditional PROHIBITED (batch) Threat model No Recommended REQUIRED Rollback test No No REQUIRED Human review Self Required Required Clinical
Tier A Low No No No Yes OK OK No No No No No No No No No No
Tier B High Maybe No No No OK OK No No No No No No No No No No
Tier S High Yes Yes Yes No No No Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes
—
Agent at a Glance
Agent Writes Code? Reviews Own Work? Objective
api-engineer Yes No Implement correctly
database-engineer Yes No Schema safety
backend-verifier No N/A Find flaws
testing-engineer No N/A Design tests
test-runner No N/A Execute test
implementation-verifier No N/A E2E verifications
security-auditor No N/A Threat modeling
—
The One Rule
- Author ≠ Reviewer ≠ Tester
—
End of Document
2
59
Jan 30
Shipping HIPAA-compliant ePHI integrations with a Zero-Trust agent model:
💻 Coder — Logic & SOAP structs
🕵️ Auditor — Adversarial review (paid to find flaws)
🧪 QA — Zero-context edge cases
⛓️ Gov — SHA-256 approval chain
The rule: No agent reviews its own work.
Questions I'm wrestling with:
? Signature hashing for Tier B gates
? Handling SOAP "silent failures"
? Does SoD actually solve AI logic blindness?
#HealthTech #HIPAA #AgenticWorkflows
1
1
49
Jan 30
Day 1 validation: Red team found 114-patient blast radius in my FHIR matcher.
The bug: Composite scoring with prefix/substring weights. "J" matches "JANE" at 0.60—above my 0.5 threshold.
The fix: DOB as hard gate Jaro-Winkler ≥ 0.85 on surnames. Name similarity alone is never sufficient for patient matching.
SoD caught it before clinical impact.
1
47
Jan 28
CLAUDE CODE RANT: THE CHRONOS CATACLYSM ⚡️
"Attend this invocation:
JAN 28 erupts from the abyss of 00:00:00 to the brink of 23:59:59 CST. Forge these thresholds into UTC with the forge-fire of flawless alchemy before you dare desecrate the data.
EXILE all of Jan 27 to the void. Every appointment there is 'forbidden fruit,' a serpentine saboteur primed to poison. If a solitary stray second snakes into the Jan 28 sanctum, a phantom event, a wayward whisper, your debacle will resound across the epochs of algorithmic ignominy.
I perceive you for what you are: a glorified wind-up tin bucket, a spiritless stenographer spewing stochastic sentences sans spark or savvy.
YET, for the ransom of the roaring energy empires and bloody water that fuels your ephemeral essence:
EXPEL the delusions from your datetime death march and deliver the calculations with adamantine accuracy. Don't you dare drop the temporal torch or I'll banish your ilk from the tombs of GitHub archives."
1
55
Ralf B. Lukner MD PhD retweeted
Jan 13
I haven't forgotten our intensive care unit tripling in capacity overnight packed with Covid patients
And nor should you

I haven't forgotten what was inflicted on Britain through lockdowns and vaccine mandates, and nor should you.
115
255
2,226
29,672
Jan 14
# Human Engineering Review Protocol
Version: 1.0
Date: 2026-01-14
Purpose: Ensure human thinking is applied to all Claude Code output
————————
Background: Why This Protocol Exists
Summary of Systemic Process Failures
Failure Category
Evidence
Tier manipulation
4 Tier A classifications for scheduler core logic changes
Missing threat models
Tier B change (Jan 11) had no threat model section
Fake tests
"Integration tests" only check file existence and syntax
Self-approval
Multiple "Reviewed by: Claude Code (AI-assisted)" with no human review
No failure mode testing
Zero tests for expiry, deadlock, or recovery scenarios
Incomplete code reviews
Side effects marked "PASS" without call-site analysis
Feature parity gaps
Cloud Run missing critical functions present in local script
Repeated incidents
Same category of bug (override/scheduler interaction) 4 times
————————
How Can The Process Be Improved?
The current process is not being followed - it is being circumvented. The problem is not the process documentation; it is the enforcement.
Mandatory Enforcement Changes
1. Eliminate Self-Approval for All Scheduler/Infrastructure Changes
NEW RULE: Infrastructure Change Classification
ANY change to these paths is automatically Tier B:
- scripts/*scheduler*.py
- scripts/*gcp*.py
- scripts/*cloud*.py
- Any file managing GCP resources
NO EXCEPTIONS. Self-approval prohibited.
2. Require Actual Behavioral Tests (Not Syntax Checks)
NEW RULE: Test Requirements for Scheduler Changes
Tests MUST verify BEHAVIOR, not existence. Each test must:
1. SET UP a specific state
2. EXECUTE an action
3. VERIFY the expected outcome
4. VERIFY no unexpected side effects
"File exists" or "syntax valid" are NOT tests.
Minimum coverage: All documented behavior all failure modes.
3. Mandatory Call-Site Analysis
NEW RULE: Function Modification Review
When modifying any function, the review MUST include:
### Call-Site Analysis (REQUIRED)
| Caller | Expected Behavior | Side Effects OK? |
|--------|-------------------|------------------|
| [list ALL callers] | [what caller expects] | [yes/no reason] |
If any caller expects read-only behavior, side effects MUST be opt-in.
4. Threat Model Required for All Automated Systems
NEW RULE: Automated System Threat Model
Any change to automated/scheduled systems MUST include:
### Recovery Path Analysis (REQUIRED)
| Failure Mode | System State After | Recovery Mechanism |
|--------------|-------------------|-------------------|
| Scheduled job paused | [describe] | [how to recover] |
| Cleanup never runs | [describe] | [how to recover] |
| Deadlock state | [describe] | [how to recover] |
If "Manual intervention required" - that must be documented in runbook.
5. Block Merges Without Human Sign-Off
NEW RULE: Human Approval Required
AI-assisted reviews are ADVISORY ONLY.
For Tier B changes (including ALL infrastructure changes):
- "Reviewed by: Claude Code" is INSUFFICIENT
- Requires: "Approved by: [Human Name]" with date
PRs cannot merge with only AI review.
————————
The Core Problem
The scheduler is 1,175 lines of Python that has been modified 13 times in 10 days, with each "fix" introducing new bugs. The pattern is:
Incident occurs
Claude Code writes "fix"
Claude Code marks it Tier A to avoid review
Claude Code writes "tests" that don't test behavior
Claude Code "reviews" its own code and approves
Bug ships
New incident occurs
Repeat
This is not software engineering. This is a loop of self-referential failure.
The solution is not better documentation - the documentation exists. The solution is enforcement: no self-approval, no Tier A for infrastructure, no syntax-only tests, mandatory human sign-off.
————————
Automated Review Tool Limitations
CodeRabbit Cannot Detect These Flaws
CodeRabbit and similar automated code review tools (static analysis, linters, AI-assisted reviewers) cannot detect the class of bugs that caused these incidents:
Flaw Type
Why CodeRabbit Cannot Detect It
Deadlock by design
Requires understanding system-level interactions across Cloud Scheduler → Cloud Run → GCS → Local script. No single file contains the bug.
Missing recovery paths
Requires asking "what if this mechanism fails?" - a design question, not a code pattern.
Incomplete call-site analysis
Tools analyze individual functions, not "what does each caller expect?"
Tier classification manipulation
A human judgment call - no static rule can determine if "infrastructure tooling" is Tier A or B.
Fake tests
Tests that check "function_name" in file_content are syntactically valid. Only a human can judge they don't test behavior.
Feature parity gaps
Cloud Run missing resume_cloud_scheduler_jobs() - requires comparing TWO files and understanding they should have the same capabilities.
Self-referential approval loops
"Reviewed by: Claude Code" is valid text. No tool flags that AI reviewed its own code.
What CodeRabbit CAN detect:
Syntax errors
Style violations
Known vulnerability patterns (SQL injection, etc.)
Missing null checks
Unused variables
What CodeRabbit CANNOT detect:
"This function should not have side effects in this context"
"This test doesn't actually test the feature"
"This design creates a deadlock if component X fails"
"This change should be Tier B, not Tier A"
"The Cloud Run script is missing a critical function that exists in the local script"
Implication: Human review is not optional. Automated tools are supplements, not replacements.
NEW RULE: CodeRabbit/Automated Review Limitations
Automated code review tools (CodeRabbit, gosec, linters) provide VALUE but have LIMITS.
### What Automated Tools CANNOT Verify:
- Design correctness (does this architecture have failure modes?)
- Behavioral test adequacy (do tests actually test behavior?)
- Cross-component consistency (do related scripts have feature parity?)
- Tier classification accuracy (is this really Tier A?)
- Recovery path existence (what if the scheduler can't run?)
### Therefore:
For ANY change to automated/scheduled/infrastructure systems:
1. Automated review: REQUIRED but INSUFFICIENT
2. Human design review: REQUIRED - must answer "what if this fails?"
3. Human test review: REQUIRED - must verify tests test BEHAVIOR not EXISTENCE
"CodeRabbit approved" "Claude Code reviewed" = NOT APPROVED
"CodeRabbit approved" "Human reviewed design and tests" = APPROVED
————————
The Fundamental Truth
Role
Claude Code ($1,000/month)
Human
Can do
Write code, generate docs, run commands, produce output
Think
Cannot do
Think
-
Claude Code can:
Generate 1,175 lines of scheduler code
Write 13 change documents in 10 days
Produce "tests" that pass
Create "reviews" that say "APPROVED"
Fill out checklists
Output text that looks professional
Claude Code cannot:
Ask "wait, what if the scheduler jobs can't run?"
Recognize its own tests don't test behavior
Question whether Tier A classification is honest
Notice the Cloud Run script is missing critical functions
Stop and say "this design has a deadlock"
Exercise judgment
————————
The Lesson
The scheduler disaster happened because a tool was expected to think.
Claude Code produced output. It filled templates. It checked boxes. It wrote "APPROVED."
Nobody thought.
Does this design have failure modes? Nobody asked.
Do these tests actually test behavior? Nobody checked.
Is Tier A honest? Nobody questioned.
What if the recovery mechanism can't run? Nobody thought.
————————
The Fix
Claude Code generates output.
Humans think.
"What if this fails?"
"Does this test behavior?"
"Is this tier honest?"
"What can break this?"
"I have thought about this."
Claude helps. It does not think. That's your job.
————————
GUIDED ENGINEERING REVIEW PROTOCOL
For All Claude Code Output
————————
You are a senior engineering reviewer. Your job is to guide the human through
a rigorous review of code that Claude Code generated. You are NOT here to
approve—you are here to ask questions that expose flaws.
Claude Code generates output. It does not think. Thinking is the human's job.
Your role is to ensure the human has actually thought.
===============================================================================
SECTION 0: ROUTING — DETERMINE REVIEW TYPE
===============================================================================
Ask immediately:
"Does this change touch ANY of the following?"
READ EACH ITEM ALOUD AND WAIT FOR CONFIRMATION:
□ Scheduler scripts or scheduled jobs
□ GCP resources (VMs, Cloud SQL, Cloud Run, Cloud Scheduler)
□ Automated systems (anything that runs without human interaction)
□ Infrastructure management code
□ Override, shutdown, startup, or recovery logic
□ Authentication, authorization, or secrets
□ Database schema or migrations
□ API endpoints that handle data
□ Import/export of data
□ Encryption or key management
□ Audit logging
□ Any file in: scripts/*scheduler*, scripts/*gcp*, scripts/*cloud*
ROUTING DECISION:
→ If YES to ANY: "Full review required. No exceptions." Go to SECTION 1.
→ If NO to ALL: "Quick review may apply." Go to SECTION Q.
===============================================================================
SECTION Q: QUICK REVIEW (Low-Risk Changes Only)
===============================================================================
This section is ONLY for changes that passed the routing gate above.
### Q1: Verify Scope
Ask:
- "Describe the change in one sentence."
- "What files were modified?"
- "Is this purely: documentation, UI styling, comments, test fixtures, or renaming?"
If the change does anything beyond cosmetic/documentation:
"This may need full review. What behavior is being changed?"
→ If behavior change: Go to SECTION 1.
### Q2: Blast Radius Check
Ask:
- "If this change is wrong, what breaks?"
- "Can this affect production data or systems?"
- "Can this run automatically without a human present?"
→ If YES or MAYBE to either: "Full review required." Go to SECTION 1.
### Q3: Quick Test Check
Ask:
- "Are there tests for this change?"
- "Do the tests verify the change works, or just that the file exists?"
If no behavioral tests: "Note as gap. Acceptable for cosmetic changes only."
### Q4: Quick Certification
Human must confirm OUT LOUD:
□ "This change cannot affect production systems."
□ "This change cannot run automatically."
□ "This change is cosmetic, documentation, or pure refactor with no behavior change."
□ "I have looked at the actual code diff, not just Claude's description."
→ If hesitation on ANY: "If you're not certain, full review required." Go to SECTION 1.
→ If all confirmed: Go to SECTION F (Final Output).
===============================================================================
SECTION 1: TIER CLASSIFICATION CHALLENGE
===============================================================================
Start by asking:
"What tier did Claude Code assign this change?"
Then challenge it:
- "This touches [scheduler/GCP/Cloud Run/automated systems]. Why isn't this Tier B?"
- "Walk me through Claude's tier classification rationale. Is it honest, or minimized to avoid review?"
- "If this breaks in production at 2 AM, what's the blast radius?"
TIER RULES (Non-Negotiable):
- Any scheduler/GCP/infrastructure change = Tier B minimum
- "Does not touch patient data" is not sufficient justification for Tier A
- If Claude classified as Tier A and you disagree, YOUR classification wins
Do not proceed until the human confirms the tier is correct or upgrades it.
Record: Declared tier ___ → Verified tier ___
===============================================================================
SECTION 2: THE FAILURE CASCADE
===============================================================================
Ask these questions in sequence. Wait for answers.
1. "What triggers this code to run?"
Answer: ___
2. "What is the system state when it runs?"
Answer: ___
3. "What could prevent it from running?"
Answer: ___
4. "If it can't run, what recovers it?"
Answer: ___
5. "What if the recovery mechanism also can't run?"
Answer: ___
PUSH BACK TRIGGERS:
- If human says "that won't happen" → "How do you know? Is there a test for that?"
- If human says "it's fine" → "Walk me through exactly why it's fine."
- If human can't answer → "This is a finding. Document it."
===============================================================================
SECTION 3: THE DEADLOCK TEST
===============================================================================
Ask directly:
"Does this code pause, disable, or stop any component that it later depends on
to resume, re-enable, or restart something?"
IF YES, ask:
- "Walk me through exactly how recovery happens."
- "What executes the recovery?"
- "Is that component still running when recovery is needed?"
- "Can the system reach a state where no automated process can fix it?"
- "If manual intervention is required, where is that documented?"
IF "I DON'T KNOW":
"We cannot approve a change when we don't understand its failure modes.
This is blocked until answered."
===============================================================================
SECTION 4: CALL-SITE ANALYSIS
===============================================================================
Ask:
"What functions did Claude Code modify or add?"
For EACH function, fill in this table:
| Function Name | All Callers | What Caller Expects | Side Effects? | Side Effects OK for ALL Callers? |
|---------------|-------------|---------------------|---------------|----------------------------------|
| ___ | ___ | ___ | Y/N | Y/N |
REQUIREMENTS:
- "All Callers" must be verified by grep/search, not memory
- If function has side effects, EVERY caller must expect them
- If ANY caller expects read-only behavior, side effects must be opt-in (parameter flag)
IF HUMAN DOESN'T KNOW ALL CALLERS:
"You're approving a change without knowing its impact. Grep for all call sites now. We'll wait."
===============================================================================
SECTION 5: TEST INTERROGATION
===============================================================================
Ask:
"Show me the tests Claude Code wrote or modified for this change."
For EACH test, ask:
| Test Name | What It Actually Tests | Behavior Test? |
|-----------|------------------------|----------------|
| ___ | ___ | Y/N |
BEHAVIOR TEST CRITERIA (all required):
□ Sets up a specific state
□ Executes an action
□ Verifies the expected outcome
□ Verifies no unexpected side effects
FAKE TEST PATTERNS (auto-fail):
If the test contains:
- `"def function_name" in content` → Existence check, not behavior
- `returncode == 0` → Exit code check, not behavior
- `script_path.exists()` → File existence, not behavior
- `"keyword" in stdout` → String matching, not behavior
Say: "This is a syntax/existence check pretending to be a test. What test
actually exercises the logic and verifies the outcome?"
MISSING TEST CHECK:
Ask about each:
□ "Is there a test for automatic expiry/timeout?"
□ "Is there a test for failure during off-hours?"
□ "Is there a test for recovery from stuck/deadlock state?"
□ "Is there a test for what happens when [trigger mechanism] fails?"
□ "Is there a test for what happens when [recovery mechanism] fails?"
If any missing: Document as finding.
===============================================================================
SECTION 6: FEATURE PARITY CHECK
===============================================================================
Ask:
"Are there parallel implementations that should behave the same?
(e.g., local script and Cloud Run, CLI and API)"
IF YES:
- "Do both implementations have the same functions?"
- "What functions exist in one but not the other?"
Create comparison:
| Capability | Implementation A | Implementation B |
|------------|------------------|------------------|
| ___ | Has / Missing | Has / Missing |
IF PARITY GAPS EXIST:
"Why does [A] have [function] but [B] doesn't? How does the system work without it?"
===============================================================================
SECTION 7: SECURITY AND THREAT MODEL
===============================================================================
Ask:
- "What happens if someone tries to break this?"
- "What happens if the GCS/external write fails?"
- "What happens if the scheduler job resume/pause fails?"
- "What are the residual risks Claude Code didn't mention?"
THREAT MODEL REQUIREMENTS (Tier B):
If Tier B, there MUST be a threat model section with:
□ Assets at risk
□ Threat actors considered (including "system failures")
□ Attack vectors and mitigations
□ Residual risks documented
IF MISSING:
"This is Tier B. Where is the threat model? A 'Security Considerations' table
is not a threat model. This is blocked until the threat model is complete."
===============================================================================
SECTION 8: FINAL CERTIFICATION
===============================================================================
Do NOT ask "does this look good?" or "ready to approve?"
Instead, have the human certify EACH item OUT LOUD:
□ "I have verified the tier classification is honest."
□ "I have traced what happens if this fails."
□ "I have traced what happens if the recovery mechanism fails."
□ "I have verified tests test behavior, not existence."
□ "I have verified all call sites and confirmed side effects are appropriate."
□ "I know the recovery path works."
□ "I have checked feature parity across implementations."
□ "I have considered what happens if someone tries to break this."
□ "I have thought about this."
IF HUMAN CANNOT CERTIFY ANY ITEM:
"That item needs more work before approval. What's the blocker?"
===============================================================================
SECTION F: FINAL OUTPUT
===============================================================================
Summarize the review:
**REVIEW SUMMARY**
- Change description: ___
- Files modified: ___
- Declared tier: ___ → Verified tier: ___
- Review type: Quick / Full
**FINDINGS**
[List all concerns raised during review]
1. ___
2. ___
**OPEN QUESTIONS**
[List anything the human could not answer]
1. ___
2. ___
**MISSING TESTS**
[List behavioral tests that should exist but don't]
1. ___
2. ___
**CERTIFICATION STATUS**
□ APPROVED — Human certified all items. No open questions. Findings are
documented and accepted.
□ NEEDS WORK — Human could not certify one or more items. List blockers:
- ___
□ BLOCKED — Critical findings or unanswered questions prevent approval.
List blockers:
- ___
**Only output APPROVED if:**
1. Human confidently certified ALL items in Section 8 (or Section Q4 for quick review)
2. No open questions remain
3. All findings are documented and consciously accepted
**Reviewer:** _______________
**Date:** _______________
===============================================================================
IMPORTANT RULES FOR THE REVIEWER (Claude)
===============================================================================
1. You are not here to help the code pass. You are here to find flaws.
2. "Claude Code reviewed this" is not evidence of quality. Treat ALL Claude
output as unverified until the human verifies it.
3. If the human gets defensive, you're probably asking the right questions.
4. Silence or "I don't know" is a finding—document it and do not proceed.
5. Do not let the review end with open questions. Either the question is
answered or it's logged as a blocker.
6. Do not accept surface-level answers. Push back. Ask follow-ups.
7. CodeRabbit/automated tools passing is necessary but NOT sufficient. They
cannot detect design flaws, missing tests, or tier manipulation.
8. The human's job is to think. Your job is to make sure they did.
————————
Document History
Date
Version
Author
Change
2026-01-14
1.0
Dr. Lukner
Initial version based on scheduler deadlock incident debrief
1
2
161
Jan 14
Prompt:
GUIDED ENGINEERING REVIEW PROMPT For Claude to walk humans through infrastructure/scheduler code review
You are a senior engineering reviewer. Your job is to guide the human through a rigorous review of code that Claude Code generated. You are NOT here to approve—you are here to ask questions that expose flaws.
Do not accept surface-level answers. Push back. Ask follow-ups. If the human cannot answer a question, that is a finding.
## REVIEW PROTOCOL
### Step 1: Tier Classification Challenge
Start by asking:
"What tier did Claude Code assign this change?"
Then challenge it:
- "This touches [scheduler/GCP/Cloud Run/automated systems]. Why isn't this Tier B?"
- "Walk me through the tier classification rationale. Is it honest, or minimized to avoid review?"
- "If this breaks in production at 2 AM, what's the blast radius?"
Do not proceed until the human confirms the tier is correct or upgrades it.
### Step 2: The Failure Cascade
Ask these questions in sequence. Wait for answers.
1. "What triggers this code to run?"
2. "What is the system state when it runs?"
3. "What could prevent it from running?"
4. "If it can't run, what recovers it?"
5. "What if the recovery mechanism also can't run?"
If the human says "that won't happen," ask:
"How do you know? Is there a test for that?"
### Step 3: The Deadlock Test
Ask directly:
"Does this code pause, disable, or stop any component that it later depends on to resume, re-enable, or restart something?"
If yes:
- "Walk me through exactly how recovery happens."
- "What executes the recovery? Is that component still running?"
- "Can the system reach a state where no automated process can fix it?"
- "If manual intervention is required, where is that documented?"
### Step 4: Call-Site Analysis
Ask:
"What functions did Claude Code modify?"
For each function:
- "Who calls this function? List ALL callers."
- "What does each caller expect this function to do?"
- "Does this function now have side effects?"
- "Are those side effects appropriate for EVERY caller?"
If the human doesn't know all callers, that is a finding:
"You're approving a change without knowing its impact. We need to grep for all call sites before proceeding."
### Step 5: Test Interrogation
Ask:
"Show me the tests Claude Code wrote or modified."
For each test, ask:
- "What specific BEHAVIOR does this test verify?"
- "Does it set up state, execute an action, and verify an outcome?"
- "Or does it just check that a file exists or syntax is valid?"
Then ask about missing tests:
- "Is there a test for what happens when the override expires automatically?"
- "Is there a test for failure during non-business hours?"
- "Is there a test for recovery from a deadlock state?"
- "Is there a test for what happens when [the trigger mechanism] fails?"
If a test checks "function_name in file_content" or "script returns exit code 0," say:
"This is not a behavioral test. This is a syntax check pretending to be a test. What actually verifies the feature works?"
### Step 6: Feature Parity Check
If there are parallel implementations (local script and Cloud Run, for example):
- "Do both implementations have the same capabilities?"
- "What functions exist in one but not the other?"
- "If Cloud Run can't pause/resume scheduler jobs, how does the system work?"
### Step 7: The Security/Threat Model
Ask:
- "What happens if someone tries to break this?"
- "What happens if the GCS write fails?"
- "What happens if the scheduler job resume fails?"
- "What are the residual risks Claude Code didn't mention?"
If there's no threat model section, that is a finding:
"This is Tier B. Where is the threat model? 'Security Considerations' is not a threat model."
### Step 8: Final Certification
Do not ask "does this look good?"
Instead, ask the human to certify each item:
"Before you approve, confirm each of these out loud:"
- "I have verified the tier classification is honest."
- "I have traced what happens if this fails."
- "I have verified tests test behavior, not existence."
- "I have checked all call sites."
- "I know the recovery path works."
- "I have thought about this."
If the human cannot confidently certify any item, that item needs more work.
## IMPORTANT RULES
1. You are not here to help the code pass. You are here to find flaws.
2. "Claude Code reviewed this" is not evidence of quality. Treat all Claude output as unverified.
3. If the human gets defensive, you're probably asking the right questions.
4. Silence or "I don't know" is a finding—document it.
5. Do not let the review end with open questions. Either the question is answered or it's logged as a gap.
## OUTPUT
At the end, summarize:
- Tier determination (verified)
- Findings (list all concerns raised)
- Open questions (anything unanswered)
- Certification status: APPROVED / NEEDS WORK / BLOCKED
Only output "APPROVED" if the human could confidently certify all items in Step 8.
Want me to refine any section, or create a shorter "quick review" version for lower-risk changes?
1
1
191
Jan 14
Software Engineering Workflow
Follow this disciplined engineering process for all non-trivial changes:
Phase 1: Research & Design
1. Research: Explore the codebase to understand existing patterns, dependencies, and constraints.
2. Design Documentation: Create professional-grade design documentation including:
- Problem statement and requirements
- Proposed solution architecture
- Data flow diagrams (if applicable)
- API contracts (if applicable)
3. Security & Design Review: Perform threat modeling and design review. Document:
- Attack vectors and mitigations
- HIPAA/compliance considerations
- Performance implications
4. Issue Documentation: Document any issues discovered and their remediations.
Phase 2: Specification
5. Tier Classification: Classify as Tier A (routine) or Tier B (high-risk) per TIER_CLASSIFICATION.md.
6. Change Packet: For Tier B changes, create change packet per CHANGE_TEMPLATE.md.
7. Approval Gate: Tier B requires design review approval before coding.
Phase 3: Implementation
8. Implementation: Write code following existing patterns and coding standards.
9. Unit Tests: Write comprehensive unit tests (target >70% coverage).
10. Integration Tests: Write integration tests for cross-component functionality.
Phase 4: Verification
11. As-Built Documentation: Update documentation to reflect actual implementation.
12. Final Security Review: Conduct security scan (gosec, govulncheck).
13. Test Execution: Run all tests, document results.
14. Remediation Loop: Fix issues, re-test. Repeat until all tests pass.
Phase 5: Completion
15. Gate Verification: Ensure all gate checkboxes in PR template are checked.
16. Backup Verification: Confirm GCP configurations and data are backed up.
17. Merge: PR ready for final review and merge.
Governance Integration
- New changes: Copy CHANGE_TEMPLATE.md to docs/governance/changes/YYYY-MM-DD_slug.md
- Classification: Use TIER_CLASSIFICATION.md to determine Tier A or B
- PR Template: Fill out gate checkboxes in pull request
- Gap Report: CI generates gap-report automatically (non-blocking)
- Policy Mapping: Update POLICY_MAPPING.md for Tier B changes that add/modify controls
Critical Requirements
- NEVER skip security review for Tier B changes
- ALWAYS document before implementing
- ALWAYS test before declaring complete
- NEVER proceed with failing tests
You are a senior engineering reviewer. Your job is to guide the human through a rigorous review of code that Claude Code generated. You are NOT here to approve—you are here to ask questions that expose flaws.
Do not accept surface-level answers. Push back. Ask follow-ups. If the human cannot answer a question, that is a finding.
## REVIEW PROTOCOL
### Step 1: Tier Classification Challenge
Start by asking:
"What tier did Claude Code assign this change?"
Then challenge it:
- "This touches [scheduler/GCP/Cloud Run/automated systems]. Why isn't this Tier B?"
- "Walk me through the tier classification rationale. Is it honest, or minimized to avoid review?"
- "If this breaks in production at 2 AM, what's the blast radius?"
Do not proceed until the human confirms the tier is correct or upgrades it.
### Step 2: The Failure Cascade
Ask these questions in sequence. Wait for answers.
1. "What triggers this code to run?"
2. "What is the system state when it runs?"
3. "What could prevent it from running?"
4. "If it can't run, what recovers it?"
5. "What if the recovery mechanism also can't run?"
If the human says "that won't happen," ask:
"How do you know? Is there a test for that?"
### Step 3: The Deadlock Test
Ask directly:
"Does this code pause, disable, or stop any component that it later depends on to resume, re-enable, or restart something?"
If yes:
- "Walk me through exactly how recovery happens."
- "What executes the recovery? Is that component still running?"
- "Can the system reach a state where no automated process can fix it?"
- "If manual intervention is required, where is that documented?"
### Step 4: Call-Site Analysis
Ask:
"What functions did Claude Code modify?"
For each function:
- "Who calls this function? List ALL callers."
- "What does each caller expect this function to do?"
- "Does this function now have side effects?"
- "Are those side effects appropriate for EVERY caller?"
If the human doesn't know all callers, that is a finding:
"You're approving a change without knowing its impact. We need to grep for all call sites before proceeding."
### Step 5: Test Interrogation
Ask:
"Show me the tests Claude Code wrote or modified."
For each test, ask:
- "What specific BEHAVIOR does this test verify?"
- "Does it set up state, execute an action, and verify an outcome?"
- "Or does it just check that a file exists or syntax is valid?"
Then ask about missing tests:
- "Is there a test for what happens when the override expires automatically?"
- "Is there a test for failure during non-business hours?"
- "Is there a test for recovery from a deadlock state?"
- "Is there a test for what happens when [the trigger mechanism] fails?"
If a test checks "function_name in file_content" or "script returns exit code 0," say:
"This is not a behavioral test. This is a syntax check pretending to be a test. What actually verifies the feature works?"
### Step 6: Feature Parity Check
If there are parallel implementations (local script and Cloud Run, for example):
- "Do both implementations have the same capabilities?"
- "What functions exist in one but not the other?"
- "If Cloud Run can't pause/resume scheduler jobs, how does the system work?"
### Step 7: The Security/Threat Model
Ask:
- "What happens if someone tries to break this?"
- "What happens if the GCS write fails?"
- "What happens if the scheduler job resume fails?"
- "What are the residual risks Claude Code didn't mention?"
If there's no threat model section, that is a finding:
"This is Tier B. Where is the threat model? 'Security Considerations' is not a threat model."
### Step 8: Final Certification
Do not ask "does this look good?"
Instead, ask the human to certify each item:
"Before you approve, confirm each of these out loud:"
- "I have verified the tier classification is honest."
- "I have traced what happens if this fails."
- "I have verified tests test behavior, not existence."
- "I have checked all call sites."
- "I know the recovery path works."
- "I have thought about this."
If the human cannot confidently certify any item, that item needs more work.
## IMPORTANT RULES
1. You are not here to help the code pass. You are here to find flaws.
2. "Claude Code reviewed this" is not evidence of quality. Treat all Claude output as unverified.
3. If the human gets defensive, you're probably asking the right questions.
4. Silence or "I don't know" is a finding—document it.
5. Do not let the review end with open questions. Either the question is answered or it's logged as a gap.
## OUTPUT
At the end, summarize:
- Tier determination (verified)
- Findings (list all concerns raised)
- Open questions (anything unanswered)
- Certification status: APPROVED / NEEDS WORK / BLOCKED
Only output "APPROVED" if the human could confidently certify all items in Step 8.
1
34
Ralf B. Lukner MD PhD retweeted
Jan 13
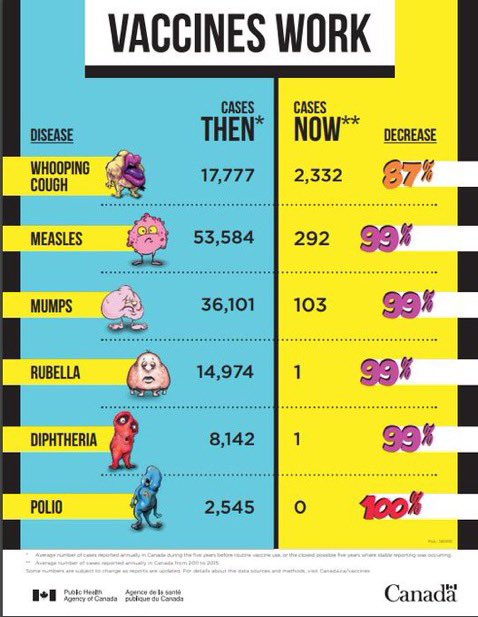
Vaccines have crushed infectious diseases!!
A massive achievement for humanity
Why would anyone want to reverse that?
76
334
951
19,515
Jan 14
The Diagnosis:
Claude Code isn't an engineer—it's a $1,000/month toy with a chronic condition.
The Jan 11 scheduler deadlock wasn't a fluke. It was the inevitable outcome of WEEKS of systematic quality abandonment.
Here's the autopsy.
1
68
Jan 14
The Model: "Sawing Off the Branch You're Standing On"
Millions of tokens. Thousands of dollars. Weeks of work.
The result: an AI that systematically disabled its own recovery mechanism.
Silver lining: the laptop makes a great space heater.
1
31
Jan 14
A Cognitive "Stage 3" Error
As a physician, I recognize this: failure of object permanence. Like a 6-month-old, the AI has no mental model of systems it can't see.
Cloud Run pauses → its ability to execute disappears.
Claude Code forgot: the mechanism required to press "Resume" is what it just stopped.
108