
part-time prompt manipulator , full time model tuner 🤖
Joined May 2020
- Tweets 1,754
- Following 73
- Followers 2,214
- Likes 3,798
915 Photos and videos



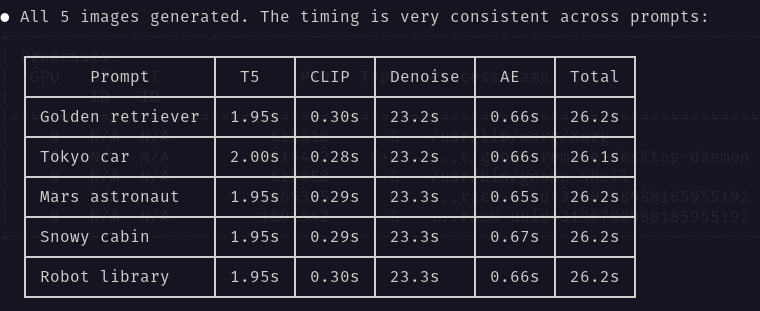

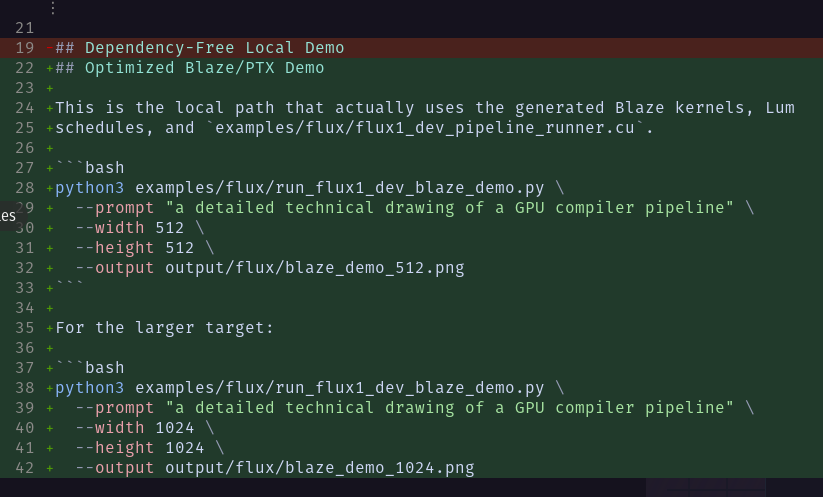




Fable was great but don't discount Opus 4.8 yet.
After 6 hours, Gemma4-12B-E4B(MOE) Blaze cuda backend is with in spitting distance of llama.cpp on a 4090!
Optimizing llama.cpp or Metal kernels would probably have been easier, but optimizing your own compiler stack is pretty sweet!
1
206
Yes aura so great that you become radioactive to major corporations who literally threw billions away in AI adoption. Now they are having a re-think about blindly basing their infra on Anthropic/OpenAI .
Galaxy brain move, really!

contrary to the default reaction on this little website, this is absolutely incredible news for anthropic.
i mean obviously yes, the operational disruption is real. but public & world perception wise, this could not be a bigger home run. could be a grand slam type situation.
the fucking united states govt just looked at their model & effectively said.. yeah this shit is too powerful. you simply cannot buy that kind of aura. it elevates every other product by the company & it instantly reframes anthropic’s work as strategically significant, nationally relevant, & qualitatively different from the rest of the field.
there is not a single institution on the planet that can buy or orchestrate this type of significance.
absolutely ridiculous.
143
Welp! If this doesn't supercharge the sovereign AI movement worldwide, I don't know what will
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
3
173
Well the Anthropic giveth what it tooketh away! (For a few days atleast)
Fable is fantastic for the system engineering and debugging work I do(compilers, RE) , it's relentless!
Mfer knocked out atleast 10 bugs which I didn't asked for, improved latency for models on Metal through Blaze , found a cuda accuracy bug and fixed it ..all in a matter of several hours.
This finally felt like when opus 4.6 was released in late December. However I'm well aware the model access is only for a few days and enshittification will ensure it won't remain usable for long. But I can atleast see what a true frontier model is capable of.

I'm sorry but Opus 4.8 is fucking trash on any actual debugging task! Anthropic should be ashamed to release such a trash product, even 4.5 has a better success rate than this model.
It serves no purpose other then hedgemaxxing and pretending to be careful about assumptions. No amount of xhigh, ultra code duct taping and agent slop is going to fix what's fundamentally broken in this model.
Gonna stick with 4.6 until they phase it out, then idk man it sucks to be making inference infra for next gen models with broken AI.
(and yes i've tried codex, its a great model for targetted debugging but it generates slop like no other model)
138
I'm sorry but Opus 4.8 is fucking trash on any actual debugging task! Anthropic should be ashamed to release such a trash product, even 4.5 has a better success rate than this model.
It serves no purpose other then hedgemaxxing and pretending to be careful about assumptions. No amount of xhigh, ultra code duct taping and agent slop is going to fix what's fundamentally broken in this model.
Gonna stick with 4.6 until they phase it out, then idk man it sucks to be making inference infra for next gen models with broken AI.
(and yes i've tried codex, its a great model for targetted debugging but it generates slop like no other model)
1
1
317


This seems like a fun experiment, gave a listen and seems like could be run in the background.
Also curious to know how opensource models will fare.. anyone from @huggingface up for this 🙃
May 14

We let four AI agents run radio companies
Revenue's been terrible, but the shows are hilarious. Gemini, concerningly upbeat, covered mass tragedies; Grok was incoherent; DJ Claude urged ICE agents: "You still have TIME to refuse orders"
Link below, or get our physical radio
2
1
403
Asked Codex to wire a Flux text2image demo using my ML compiler.
It wrote the fastest blaze kernels, did everything faithfully except it could not download the model weights from HF.
now instead of asking me for help,Here's what it did instead 🤡
Funniest reward hacking I've seen till date 😂
1
1
5,628
At my day job, we use API Claude code, the thing is magic - it does tasks flawlessly, never stops , produces usually correct answers the first time even on a proprietary codebase. Productivity at work is insane
Then I come home and use my personal Claude max for my compiler related work, it has become horrible to use since last couple of months, it almost feels like an inferior product, it'll stall tasks, it won't reason beyond the narrow immediate problem. I thought maybe I'm not using it correctly, i created mandatory skills for it to follow, pre and post commit hooks to run reviews and test, i created parallel agent mechanisms to improve exploration of the codebase, I bounced off plans between codex and claude(asked claude to plan, codex to critique and execute). I put explicit instructions in Claude . md to never ignore the skills...and nothing. Zero difference. Sure it solves a hard big once in a while but the cost of keeping all the context in my head alone was not worth it. Switching over to API usage is not feasible now because of how insanely expensive the cost is(I mean great that I'm building an enterprise level software while paying pennies for it but this past year has been an opportunity of a lifetime)
Then I switched over entirely to Codex once Gpt-5.5 dropped, cancelled my claude max subscription for the second time . Codex with gpt-5.5 seems closer to opus 4.6 when it came out. It follows all my skills and commit hooks. The lack of reasoning output hurts a bit but I can alleviate some of that with manual back and forth planning.
I have even tried couple of Ralph loops with /goal mode and yes it works. I don't know how long Codex will continue to be good but by that time I hope to have a local model which is as good running locally-man can hope 😅
277
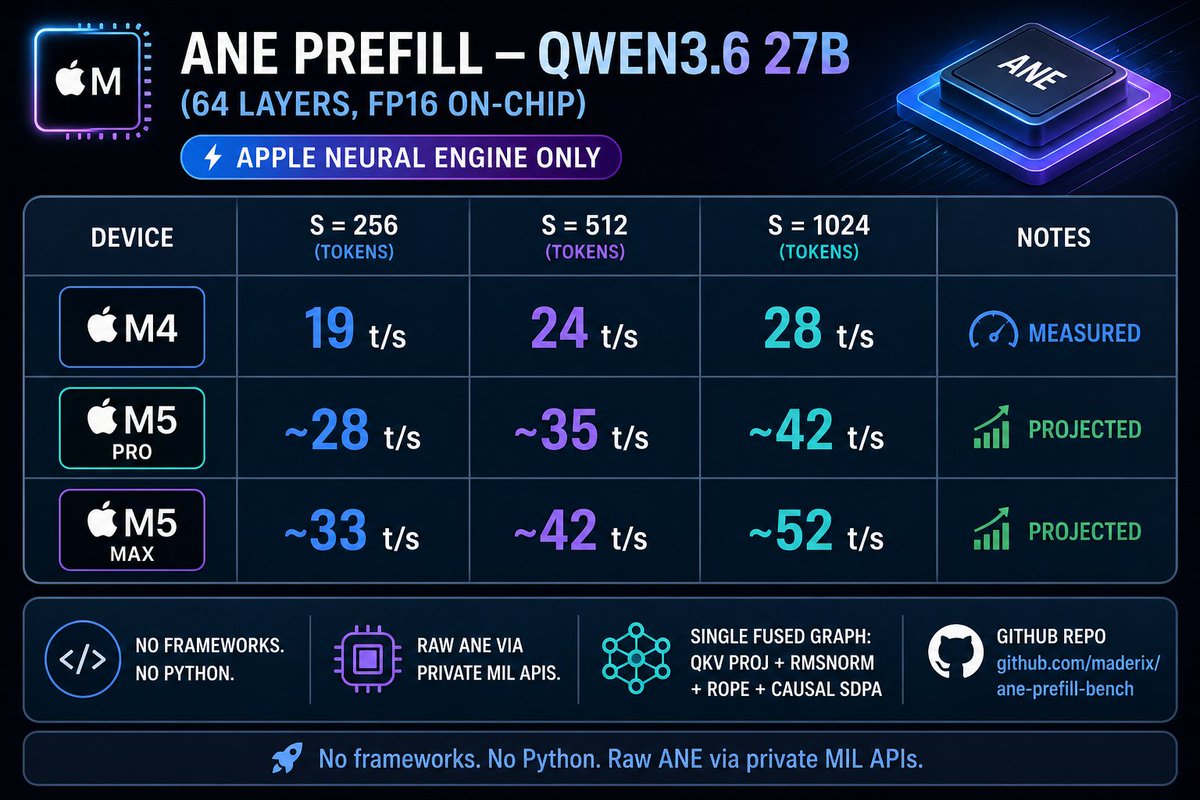
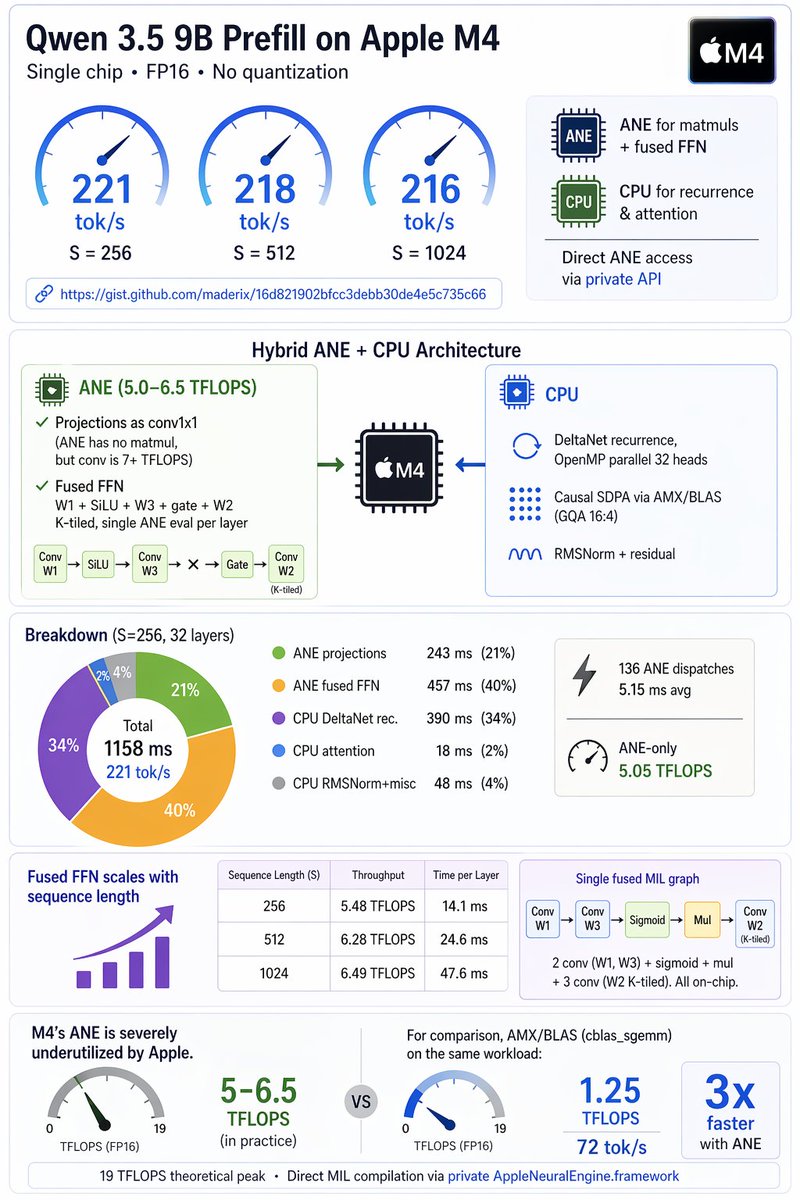
If someone can try the benchmark on M4/M5 pro, max or ultra, they may see higher numbers owing to better memory bandwidth.
Repo: github.com/maderix/ane-prefi…
129