
Long-context, test-time compute, and e2e Reinforcement Learning to build a superhuman coding agent (that then builds the rest of AGI for us). Join us magic.dev
Joined April 2022
- Tweets 28
- Following 0
- Followers 15,887
- Likes 65
5 Photos and videos




Pinned Tweet

29 Aug 2024
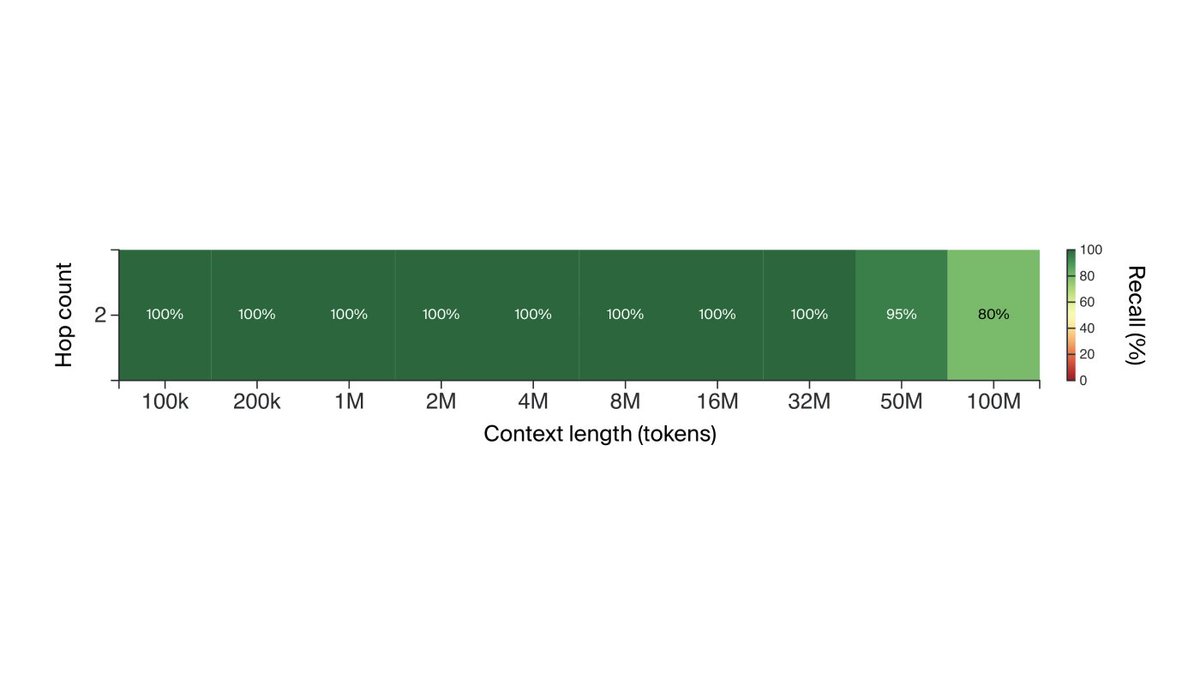
LTM-2-Mini is our first model with a 100 million token context window. That’s 10 million lines of code, or 750 novels.
Full blog: magic.dev/blog/100m-token-co…
Evals, efficiency, and more ↓
170
422
2,665
1,586,907
21 Nov 2024
Excited to announce we’re building an Applied Team focused on post-training. Come explore what's possible with our new (and still unreleased) LTM2 models and their 100M token context window. Apply here: magic.dev/careers/5652b448-8…
21
8
113
45,488
24 Sep 2024
Very excited to welcome @nvidia as Magic's latest investor! With their support, we’re looking forward to scaling long context and inference-time compute.
9
7
155
46,675
29 Aug 2024
LTM-2-Mini is our first model with a 100 million token context window. That’s 10 million lines of code, or 750 novels.
Full blog: magic.dev/blog/100m-token-co…
Evals, efficiency, and more ↓
170
422
2,665
1,586,907
29 Aug 2024
Our LTM (Long Term Memory) mechanism needs >1,000x less compute and memory than Llama 3.1 405B’s attention. Llama 3.1 would need 638 H100s *per user* to store a 100M token KV cache. LTM needs a small fraction of one.
SSMs, RNNs, and RAG all exploit weaknesses in evals like Needle In A Haystack, so we made a new eval, HashHop:
1) Incompressible
2) Multi-hop
3) No semantic hints
4) No recency bias
22
28
398
55,572
29 Aug 2024
With context solved, we now focus on unbounded inference-time compute as the next (and potentially last) breakthrough we believe is needed to build reliable AGI.
Imagine if you could spend $100 and 10 minutes on one task and reliably get a great pull request for an entire feature. That’s our goal.
We are 23 people ( 8000 H100s) working on a single project: co-designing for long context, inference-time compute, and end-to-end RL to automate coding and research.
Ben Chess (fmr. OpenAI supercomputing lead) just joined to help us scale and we’re hiring more engineers and researchers across ML, CUDA, infra, security, and more: magic.dev/careers
22
23
451
51,959
Magic retweeted

27 Feb 2024
Very excited to welcome @karpathy as Magic's latest investor!
38
46
1,151
293,440
Magic retweeted

15 Feb 2024
The era of long context is upon us. The question is whether you want to be 1 of 1000 co-authors on the Gemini paper or 1 of <20 building at Magic.dev

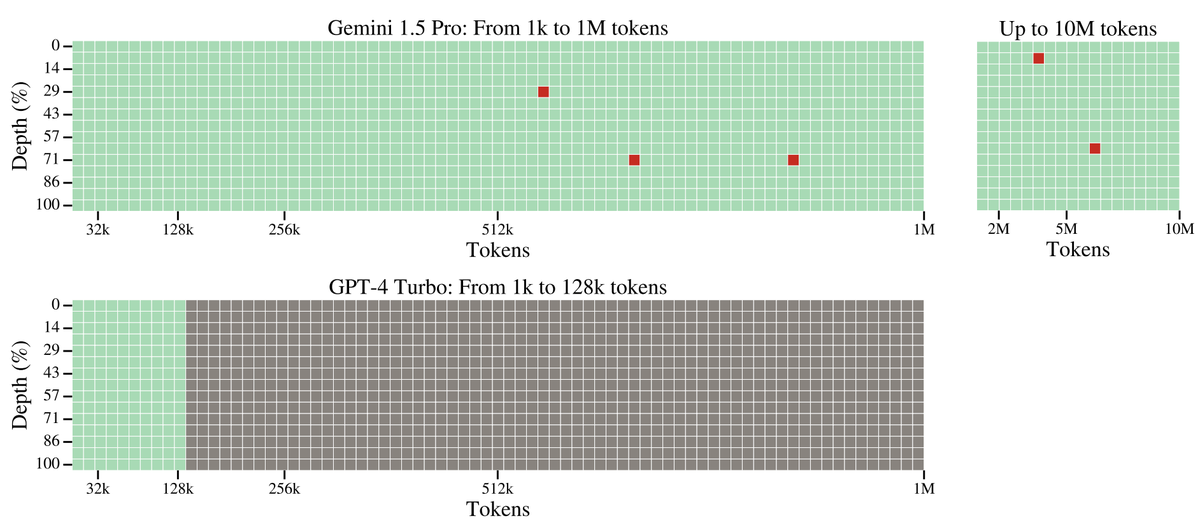
Needle in a Haystack tests
The tech report also details a number of microbenchmark “needle in a haystack” tests (modeled after @GregKamradt’s github.com/gkamradt/LLMTest_…) that probe the model’s ability to retrieve specific information from its context.
For text, Gemini 1.5 Pro achieves 100% recall up to 530k tokens, 99.7% up to 1M tokens, and 99.2% accuracy up to 10M tokens.
3
6
89
45,402
Magic retweeted
15 Feb 2024
I have been continuously in awe of the brilliance, tenacity, and kindness of @EricSteinb and the small but mighty team at Magic.dev. So much so that we've decided to invest $100m!
If you're interested in building the future, please do reach out to me or the team!
15 Feb 2024

Magic.dev has trained a groundbreaking model with many millions of tokens of context that performed far better in our evals than anything we've tried before.
They're using it to build an advanced AI programmer that can reason over your entire codebase and the transitive closure of your dependency tree. If this sounds like magic... well, you get it.
Daniel and I were so impressed, we are investing $100M in the company today. The team is intensely smart and hard-working. Building an AI programmer is both self-evidently valuable and intrinsically self-improving.
If this sounds interesting to you, consider joining them!

6
7
69
31,028
Magic retweeted
15 Feb 2024
I love my team a lot and sometimes it’s stressful but life has never been so fulfilling. If you want to build AGI on a small team of people who care a lot with thousands of GPUs, please apply :) Magic.dev
15 Feb 2024

We've raised $117M from @natfriedman and others to build an AI software engineer.
Code generation is both a product and a path to AGI, requiring new algorithms, lots of CUDA, frontier-scale training, RL, and a new UI.
We are hiring!
18
12
181
87,540
15 Feb 2024
This round was led by @natfriedman & @danielgross with participation from @CapitalG and @eladgil, and will allow us to further scale up our models.
5
2
36
20,089
15 Feb 2024
If you want to solve very hard problems to build safe AGI on a small team with thousands of GPUs, come join us: Magic.dev!
4
5
39
16,430
15 Feb 2024
We've raised $117M from @natfriedman and others to build an AI software engineer.
Code generation is both a product and a path to AGI, requiring new algorithms, lots of CUDA, frontier-scale training, RL, and a new UI.
We are hiring!
44
85
676
459,409
Magic retweeted

6 Jun 2023
5M tokens of context. Let that sink in.
Yes, there's caveats. But consider what's to come:
- Entire codebases in prompts
- Novel-length spec docs as instructions
- k-shots where k = 10K
- Few-shots where each "shot" is 50K LoC → diff
Those who declared the imminent death of prompt engineering before long-context models existed have betrayed a lack of imagination. We have not yet begun to prompt.
6 Jun 2023
Meet LTM-1: LLM with *5,000,000 prompt tokens*
That's ~500k lines of code or ~5k files, enough to fully cover most repositories.
LTM-1 is a prototype of a neural network architecture we designed for giant context windows.
19
77
613
120,225
Magic retweeted

6 Jun 2023
👀 Magic.dev showing a sneak peak of their 5M token context code model.
6 Jun 2023
Meet LTM-1: LLM with *5,000,000 prompt tokens*
That's ~500k lines of code or ~5k files, enough to fully cover most repositories.
LTM-1 is a prototype of a neural network architecture we designed for giant context windows.
4
23
142
40,598
Magic retweeted
6 Jun 2023
AI with long-term memory!
*A lot* of work left to do but happy to share a little more about what we've been up to.
It's been incredibly fulfilling to work with a wonderful team and the trust of our backers towards this milestone. Thank you for the opportunity <3
6 Jun 2023
Meet LTM-1: LLM with *5,000,000 prompt tokens*
That's ~500k lines of code or ~5k files, enough to fully cover most repositories.
LTM-1 is a prototype of a neural network architecture we designed for giant context windows.
13
7
105
35,726
6 Jun 2023
Meet LTM-1: LLM with *5,000,000 prompt tokens*
That's ~500k lines of code or ~5k files, enough to fully cover most repositories.
LTM-1 is a prototype of a neural network architecture we designed for giant context windows.
51
175
1,024
462,704
6 Jun 2023
How?
We tried to scale standard GPT context windows but quickly got stuck.
So, we designed a new approach: the Long-term Memory Network (LTM Net).
Training and serving LTM Nets required a custom ML stack, from GPU kernels to how we distribute the model across a cluster.
2
7
112
23,339
6 Jun 2023
What’s next? More compute.
LTM Nets see more context than GPTs, but LTM-1 has fewer parameters than today’s frontier models, making it less smart.
Knowing how drastically model scale improves the performance of GPTs, we're excited to see how far we can take LTM Nets.
3
56
12,489