
CEO of Sapient Intelligence. Building efficient & powerful general intelligence through brain-inspired architecture.
Joined July 2025
- Tweets 33
- Following 42
- Followers 5,554
- Likes 123
4 Photos and videos

Pinned Tweet

May 20
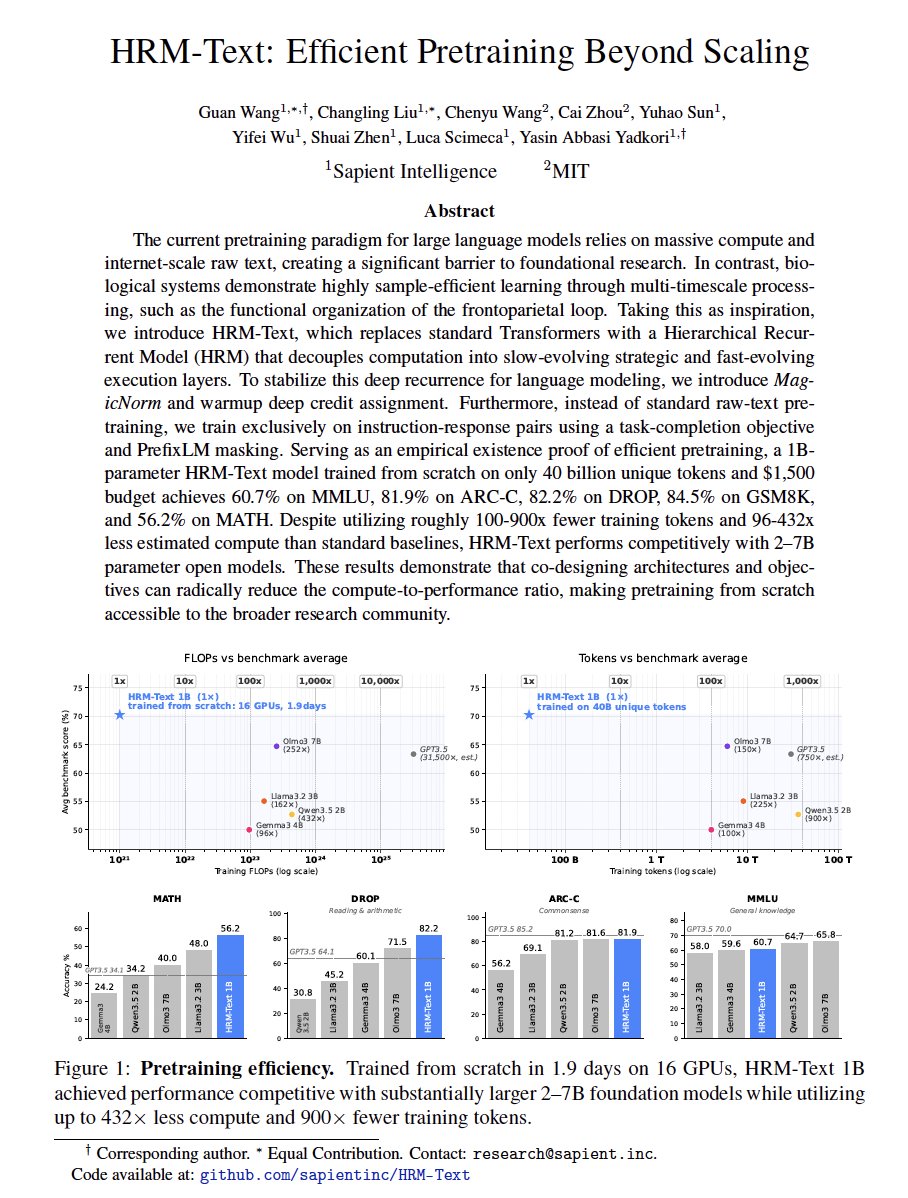
The HRM-Text paper is now available 🎉
HRM-Text explores a different approach to language model pretraining: hierarchical recurrent computation, task-completion training, and latent-space reasoning.
At just 1B parameters, HRM-Text achieves competitive performance with dramatically lower training cost and data requirements.
1B parameters
40B unique tokens
~1 day of pretraining
~$1000 training cost
25
102
764
88,110
Guan Wang retweeted

May 26
Excited to see our community building with HRM-Text! Can’t wait to see where you take it next.🚀
Whether you’re reproducing the benchmarks, testing it out in your own field, or building something entirely new, we’d love to hear about it.
Drop your ideas, questions, and experiments below, and tag @Sapient_Int so we can follow along and cheer you on!🎉

8
3
43
3,058
May 26
Huge congrats on reproducing the HRM-Text results! 🚀Pretraining an LLM on just 16 GPUs is a massive win. 👏#AI #NeuroAI #LLM #HRMText
May 25

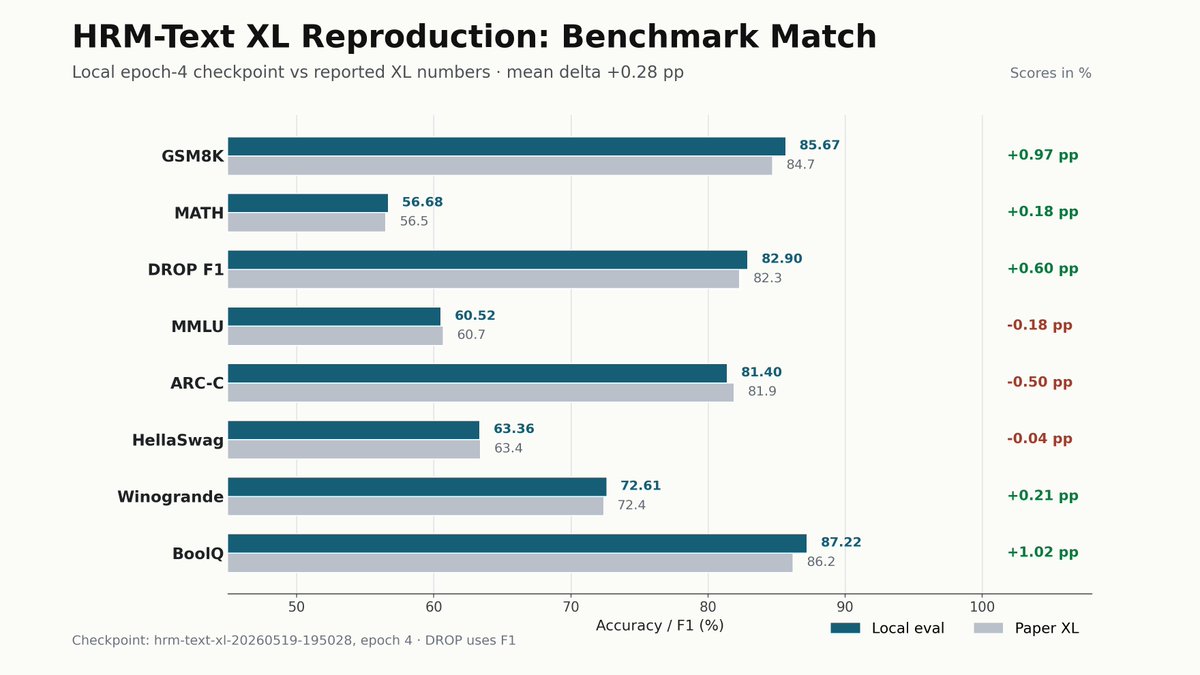
Reproduced HRM-Text XL (1B).
Training completed in ~38 hours wall-clock on 16 H200 GPUs, and evaluation performance matches the numbers reported in the paper.
Great job, team!
W&B report:
api.wandb.ai/links/MDEQGA/70…
2
6
73
6,738
May 26
1
376
May 22
Congratulations to the team! 👏Excited to see new explorations building on the HRM architecture and pushing recursive reasoning further.
May 20

🧠We introduce "Generative Recursive Reasoning"!
Recursive Reasoning Models like HRM, TRM, and Looped Transformers are deterministic — same input, same reasoning, every time. They collapse the entire space of plausible reasoning paths into a single attractor.
Our model GRAM (Generative Recursive reAsoning Models) turns recursion itself into a stochastic latent trajectory. Multiple hypotheses, alternative solution strategies, and inference-time scaling not just by depth, but by width — parallel trajectory sampling.
And here's the kicker: the same formulation that gives us conditional reasoning p(y|x) also makes GRAM a general generative model p(x).
With only 10M params:
• Sudoku-Extreme: 97.0% (TRM 87.4%)
• ARC-AGI-1: 52.0%
• ARC-AGI-2: 11.1%
• N-Queens coverage: 90%
📄 Paper: arxiv.org/abs/2605.19376
🌐 Project page: ahn-ml.github.io/gram-websit…
w/
Junyeob Baek @JunyeobB (KAIST),
Mingyu Jo @pyross0000 (KAIST),
Minsu Kim @minsuuukim (KAIST & Mila),
Mengye Ren @mengyer (NYU),
Yoshua Bengio @Yoshua_Bengio (Mila),
Sungjin Ahn @SungjinAhn_ (KAIST)



1
5
56
6,359
May 20
The HRM-Text paper is now available 🎉
HRM-Text explores a different approach to language model pretraining: hierarchical recurrent computation, task-completion training, and latent-space reasoning.
At just 1B parameters, HRM-Text achieves competitive performance with dramatically lower training cost and data requirements.
1B parameters
40B unique tokens
~1 day of pretraining
~$1000 training cost
25
102
764
88,110
May 22
Paper: arxiv.org/abs/2605.20613
GitHub: github.com/sapientinc/HRM-Te…
Hugging Face: huggingface.co/sapientinc/HR…
3
511
Guan Wang retweeted
May 19
In this benchmark deep-dive, Sapient’s founders William and Guan are joined by research team members Changling and Yasin to unpack HRM-Text’s performance across MATH, DROP, ARC-Challenge, and MMLU. 📊
Beyond the scores, they discuss what each benchmark measures, how HRM-Text compares with larger models, and why efficiency matters.
Watch the full discussion to learn more about HRM-Text and Sapient’s leaner path toward general intelligence.
59
21
256
240,139
Guan Wang retweeted
May 19
HRM-Text 101 is here.
This tutorial takes you from zero to one: from setup to fine-tuning to evaluation.
Download the base checkpoint.
Fine-tune it on a real task.
Evaluate the results.
End to end, on a single GPU.
Watch the tutorial and start building with HRM-Text.
37
46
498
187,137
Guan Wang retweeted
May 18
Introducing HRM-Text.
An ultra-lean 1B-parameter reasoning language model designed to deliver strong general performance with a fraction of the data, compute, and infrastructure.
Trained on just 40B structured tokens, HRM-Text achieves competitive performance while using ~1/1000 of the training data of comparable models.
The kicker? The full model trains in roughly one day on a $1,000 budget.
This opens the door to a new generation of AI that is powerful, accessible, and radically easier to adapt. Theories and research concepts once deemed too expensive to test are officially back in the game.
Sapient Intelligence invites you to help us shape a new paradigm for general intelligence.
160
269
2,606
508,383
Guan Wang retweeted
May 18
Tomorrow, we will unveil a new path to general intelligence.
Lean. Powerful. Efficient.
The countdown is on⏳

39
28
607
45,561
Guan Wang retweeted
Apr 30
Behind the code, there is a specific kind of expertise.
We are a team of researchers and engineers rooted in the labs of Tsinghua University, University of Cambridge, University of Alberta, Carnegie Mellon University, and Peking University—with experience at DeepMind, DeepSeek, xAI, and more.
We've seen the limits of the current AI architectures firsthand from within the organizations that scaled them. Now, across three countries, we are building an alternative.
We aren't just shipping another wrapper; we are shipping a new fundamental architecture.

11
34
362
47,970
12 Sep 2025
Hierarchical reasoning works well on large language models!🎉
37
177
1,349
97,781
Guan Wang retweeted
31 Aug 2025
🔥It’s official-Sapient HRM Discord Community is now live!
This is a place to discuss, connect, and collaborate as we shape HRM’s future together. We will be sharing our latest work, releases, and tips, as well as hosting Q&A sessions💬💬
Hop on this journey with us as we push the boundaries of what HRM and AGI at large can achieve!🙌
➡️Join us on Discord here discord.gg/sapient

1
5
37
5,057
17 Aug 2025
Thanks to @arcprize for reproducing and verifying the results!
ARC-AGI-1: public 41% pass@2 - semi private 32% pass@2
ARC-AGI-2: public 4% pass@2 - semi private 2% pass@2
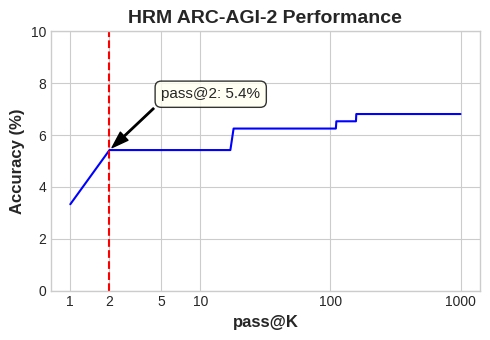
Due to differences in testing environments, a certain amount of variance in results is acceptable. According to tests run on our infrastructure, the open-source version of HRM on our GitHub can achieve a score of 5.4% pass@2 on the ARC-AGI-2. We welcome everyone to run it on your own infra and share your scores~
This is our first submission to the leaderboard, and it's a good starting point. We appreciate everyone for your support and feedback on HRM, both before and after our appearance on the ARC leaderboard. All of this encourages and motivates us to improve.
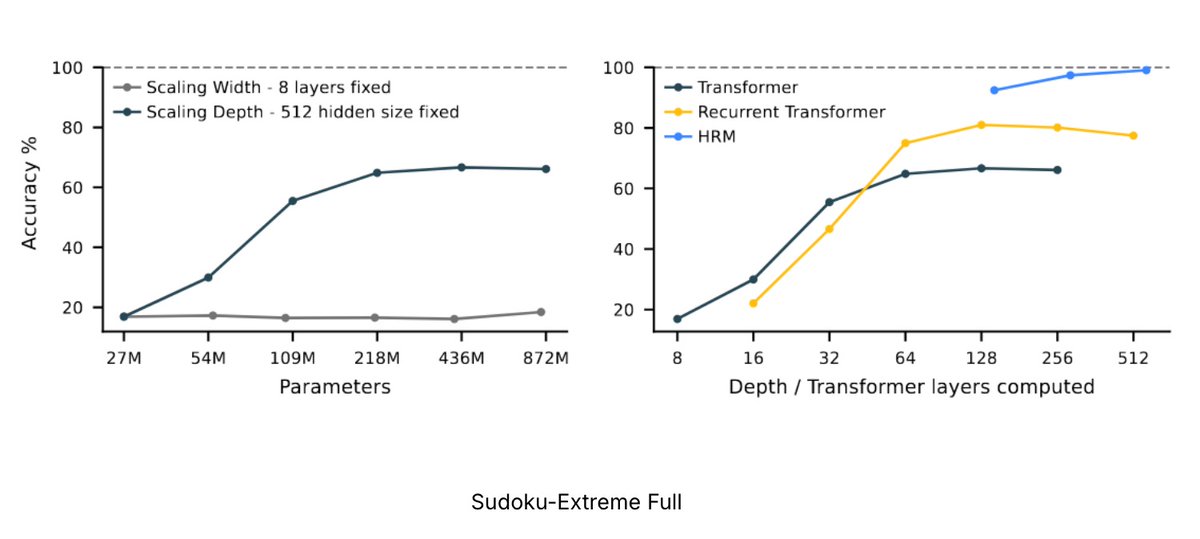
The hierarchical architecture is designed to resolve premature convergence in long-horizon tasks, like master-level Sudoku that takes hours for humans to solve. See the comparison with a simple recurrent Transformer. Such a long chain might not be essential for ARC problems, and we only used a high-low ratio of 1/2. Larger ratios are often needed for optimal performance for Sudoku problems.
In the case of ARC-AGI, the success of HRM is a testament to the model's ability to exhibit fluid intelligence - that is, its capability to infer and apply abstract rules from independent and flat examples. We are glad it was discovered in a recent blog post that the outer loop and data augmentation are essential for this ability, and we especially thank @fchollet @GregKamradt @k_schuerholt for pointing this out.
Finally, we are accelerating the iteration of the HRM model and continuously pushing its limits, with good progress so far. At the same time, we believe the hierarchical architecture is highly effective in many scenarios. Moving forward, we will make further targeted updates to the architecture and validate it on more applications. We will also release an FAQ to address the key questions raised by the community. 🧠 Stay tuned!
17
29
329
39,023
4 Aug 2025
❤️ Thanks for highlighting our HRM paper! Apologies for any confusion—we're working on clarifying this thoroughly. Stay tuned for updates!

Ok, so this paragraph in isolation looks pretty bad, but based on the code, THEY DIDN'T TRAIN ON THE TEST SET. In fact, THEY DIDN'T PRETRAIN AT ALL. And that's the point of the paper! 1/
4
2
44
7,302
29 Jul 2025
Thanks for featuring us!😃
28 Jul 2025

My story on HRM with comments from @makingAGI, CEO of Sapient Intelligence
x.com/VentureBeat/status/194…
2
1
20
8,175
23 Jul 2025
🌟Exactly my thoughts on the next-gen of AI reasoning.
Leveraging insights from neuroscience, our Hierarchical Reasoning Model offers practical, efficient scaling of depth.
Not every problem can be solved faster with more processors; sometimes, the key is adding depth.
21 Jul 2025

Some problems can’t be rushed—they can only be done step by step, no matter how many people or processors you throw at them.
We’ve scaled AI by making everything bigger and more parallel: Our models are parallel. Our scaling is parallel. Our GPUs are parallel.
But what if the real bottleneck isn’t size—but depth?What if the model just didn’t have enough serial steps to get it right? Some problems need depth, not width.
This is the Serial Scaling Hypothesis.
This is not the same as recent studies in scaling test-time compute, which focus on train vs. test and are agnostic to parallel vs. serial.
For example: test-time majority voting increases compute by running models in parallel — but doesn’t help when the task itself is serial.
We argue: what really matters is how the compute is structured. And for many real-world problems, it must be serial.
Read more at: arxiv.org/abs/2507.12549 or 🧵.
(In collaboration with: @layer07_yuxi , Kananart Kuwaranancharoen and @YutongBAI1002 )
9
5
56
9,884
Guan Wang retweeted
22 Jul 2025
Our co-founder William Chen is going to share more about the open-sourced Hierarchical Reasoning Model (HRM) at #FortuneAISingapore @FortuneMagazine tomorrow, under the panel theme "Beyond Human: AGI And The Future We’re Building"! We are excited about the practical path towards universally capable reasoning systems that rely on architectures, not scale, to reach real AGI.
⏰16:10-16:40 SGT, July 23, Mainstage

5
8
32
7,964
21 Jul 2025
Will Sudoku become the MNIST for reasoning?
Simple rules, clear structure, unique solutions—yet surprisingly challenging for modern LLMs, often requiring explicit trial-and-error to solve.
huggingface.co/datasets/sapi…
4
9
68
8,401
21 Jul 2025
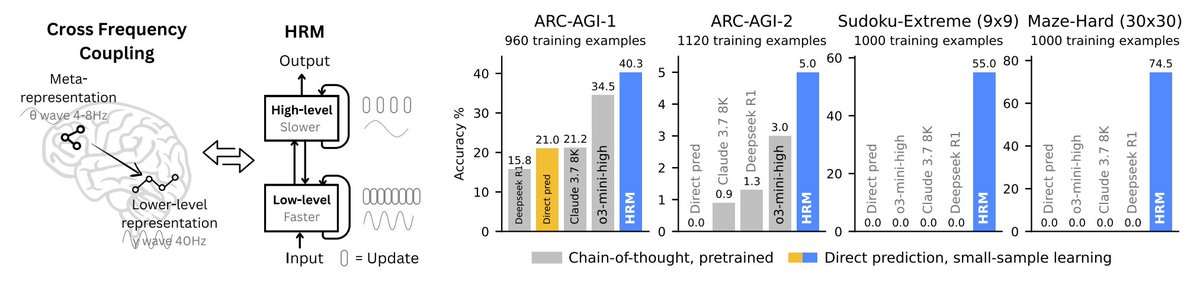
🚀Introducing Hierarchical Reasoning Model🧠🤖
Inspired by brain's hierarchical processing, HRM delivers unprecedented reasoning power on complex tasks like ARC-AGI and expert-level Sudoku using just 1k examples, no pretraining or CoT!
Unlock next AI breakthrough with neuroscience. 🌟
📄Paper: arxiv.org/abs/2506.21734
💻Code: github.com/sapientinc/HRM
227
627
3,960
1,338,395