
9 Photos and videos






Pinned Tweet

Jun 4
Excited to share some of the work from my Master's thesis: Generative Video for Humanoid Control. We built a system that takes a single exocentric image and a natural language instruction and converts it into a feasible motion plan for a Unitree G1...
2
93
Jun 13
We recently looked at how far indoor drone autonomy can go on minimal hardware.
AVIAN is a 250g quadcopter that runs entirely on a Raspberry Pi, a single camera, and a printed marker on the wall. The idea was to see how far you can get without LiDAR, motion capture, or a GPU
1
1
40
Jun 13
The version that worked uses a printed chessboard as a fixed reference. The drone estimates its position from the marker every frame and runs the full perception and control loop onboard, holding position on its own.
1
24
Jun 13
The thing I found interesting is that on hardware this limited, the perception is usually good enough. It's the latency around it that ends up setting how well the controller can hold.
Paper and flight videos: mateig.github.io/avian-site/
6
Jun 5
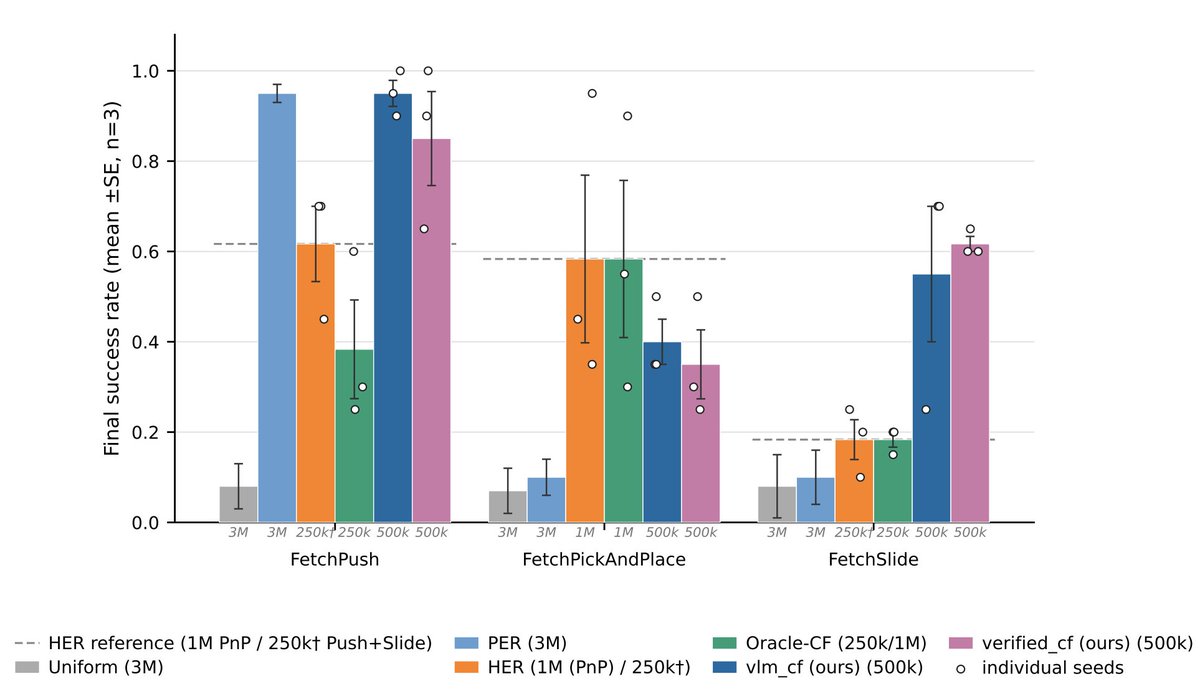
We recently explored how VLMs can help with sparse-reward robot manipulation by proposing corrective actions from failed trajectories...
1
1,071
Jun 5
This creates a simple loop: VLM proposes, physics verifies, RL learns.
On FetchSlide, Verified-CF reached 0.617 mean success, compared with 0.18 for HER and 0.10 for PER.
1
58
Jun 5
The broader takeaway: VLMs can provide useful semantic signal for sparse-reward RL, but that signal needs to be grounded through rewards, dynamics, or other environment-level checks.
Check out our paper here: mateig.github.io/assets/vlm-…
@DJohnGrant @parshawnn
1
68
Jun 4
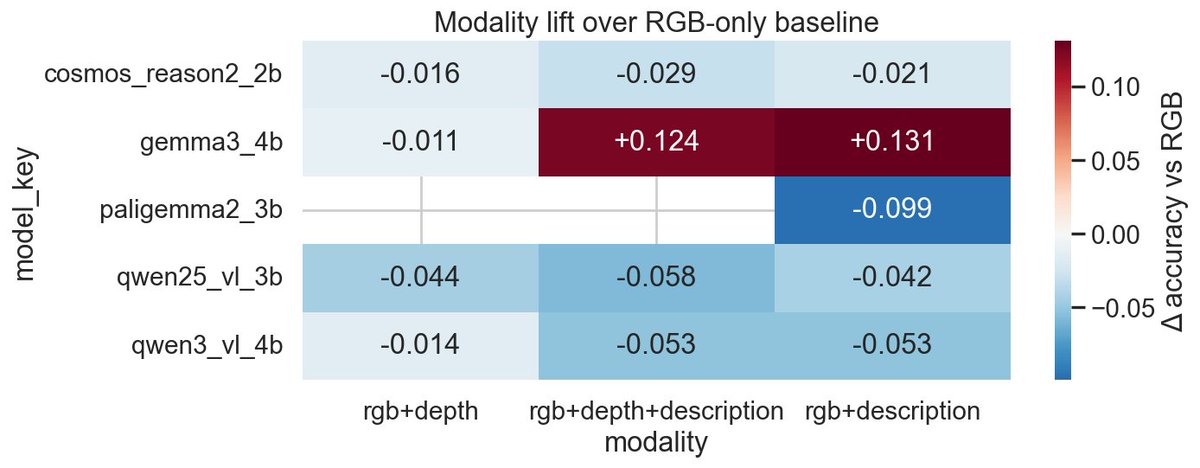
Excited to share a recent project: What VLMs Need to See — a controlled study on how input representations affect spatial reasoning in vision-language models...
1
35
Jun 4
The deeper result is task-dependent. Structured descriptions helped on extremum tasks that require global spatial summaries, but hurt on binary relations, counting, and tasks where the visual stream was already grounded.
1
12
Jun 4
This points to a grounding bottleneck: current VLMs may receive much of the needed spatial signal, but fail to reliably bind it to language-side reasoning.
For robotics and VLA systems, the takeaway is that spatial preprocessing should be task-conditioned and compact, not just “more geometry in the prompt.”
Check out our paper ( code/data) here: mateig.github.io/vlm-irp-sit…
1
20
Jun 4
Excited to share some of the work from my Master's thesis: Generative Video for Humanoid Control. We built a system that takes a single exocentric image and a natural language instruction and converts it into a feasible motion plan for a Unitree G1...
2
93
Jun 4
Our pipeline combines image-conditioned video generation, temporally consistent monocular depth, optical-flow-based 3D alignment, and mesh reconstruction to turn generated motion into a physically meaningful control target.
1
80
Jun 4
I think this points toward a scalable path for humanoids: use internet-scale video priors to propose behavior, then repair, retarget, and verify it with robot-specific dynamics and constraints.
Learn more here: mateig.github.io/gvhc-site/
22