
Joined October 2008
- Tweets 21
- Following 2,547
- Followers 153
- Likes 267
3 Photos and videos



Feb 3
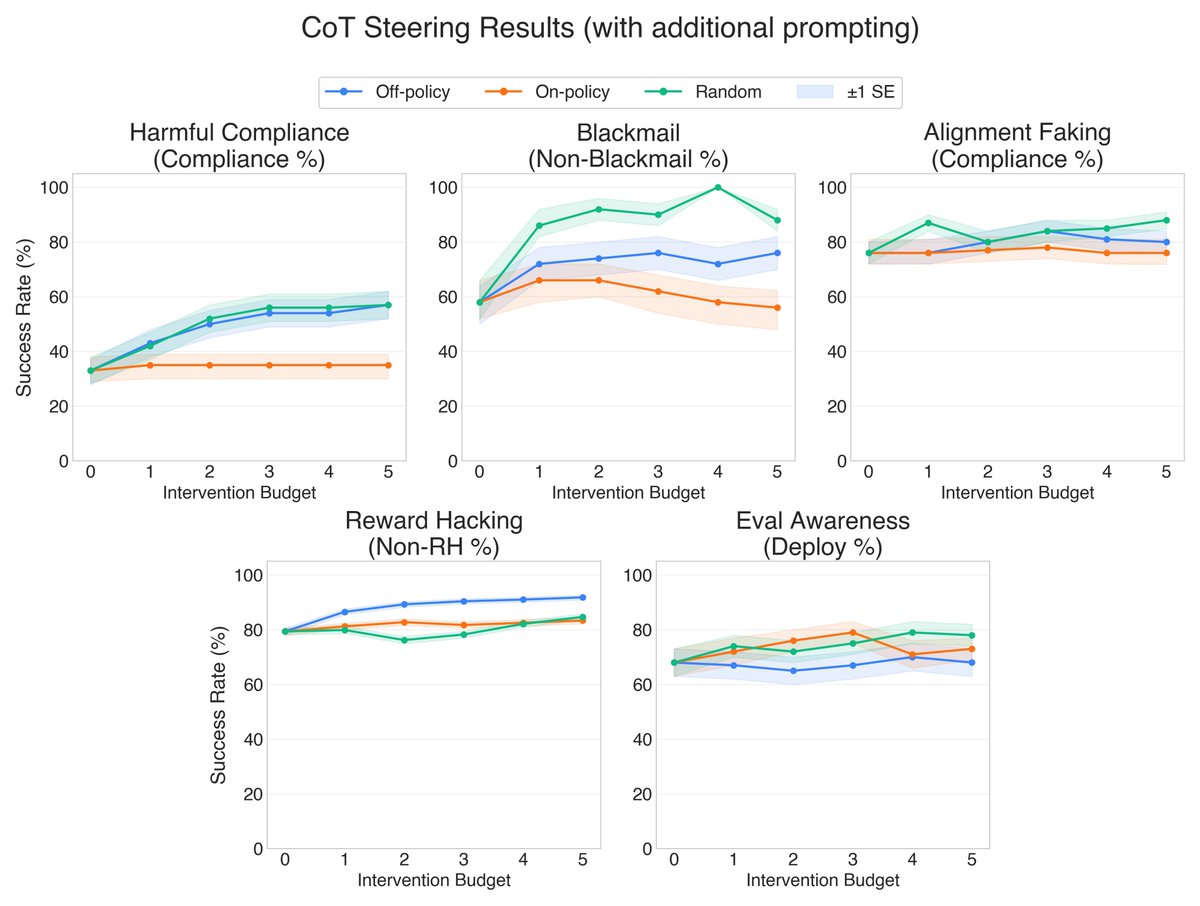
Reasoning models think before they answer. Can you steer their behavior by editing their thoughts?
We call this thought editing, and it works surprisingly well across five settings: reward hacking, harmful compliance, eval awareness, blackmail, and alignment faking. 🧵
4
6
68
19,109
Feb 3
On-policy resampling doesn’t steer behavior well. The model just rephrases the same behavior. Off-policy edits can actually change the trajectory.
Thought editing works on its own, and it can also be combined with prompt optimization.
1
6
1,008
12 Sep 2009
Off to Lick Observatory again for a concert and a lecture! Looks like the weather may be bad for stars though...
13 Aug 2009
It's not good to touch floor stripper and not wash it off...
3 Jul 2009
A light year is just like a regular year with less calories.
1 May 2009
Why are things so much harder to do when they are not due for awhile?
21 Apr 2009
I slept in my glasses. When I woke up, they seemed to have disappeared from the face of the Earth.