
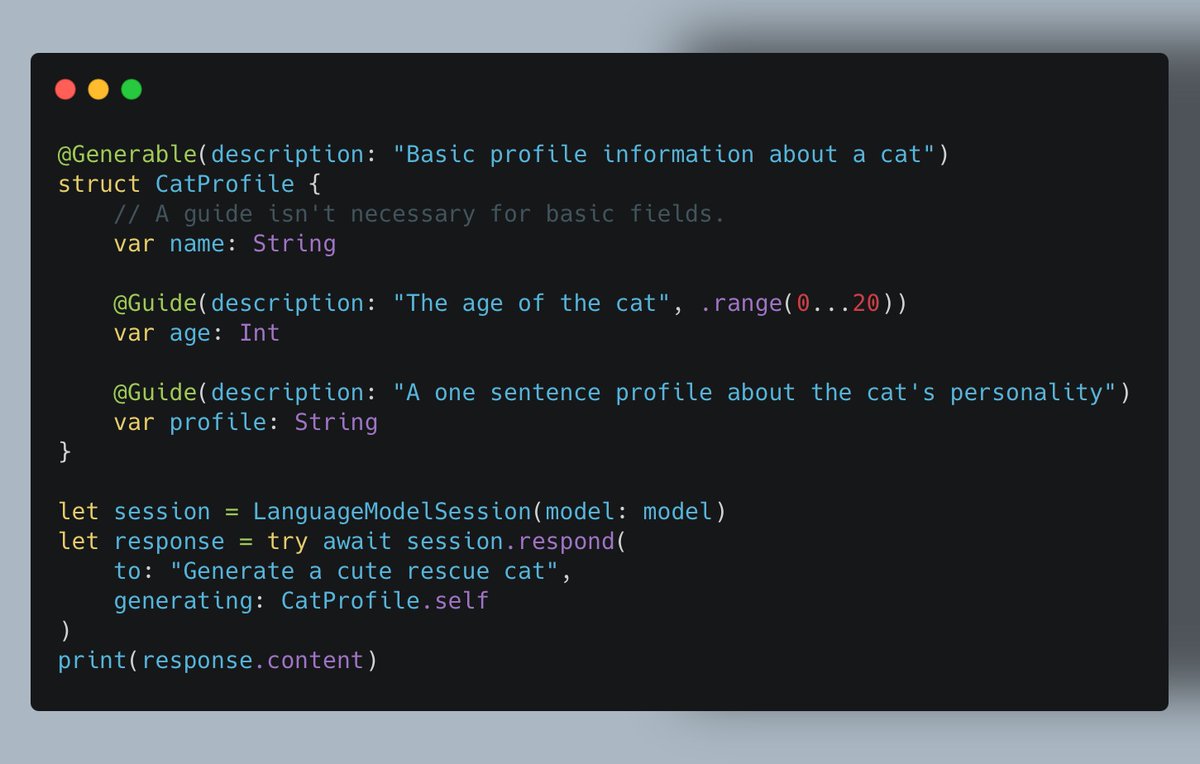
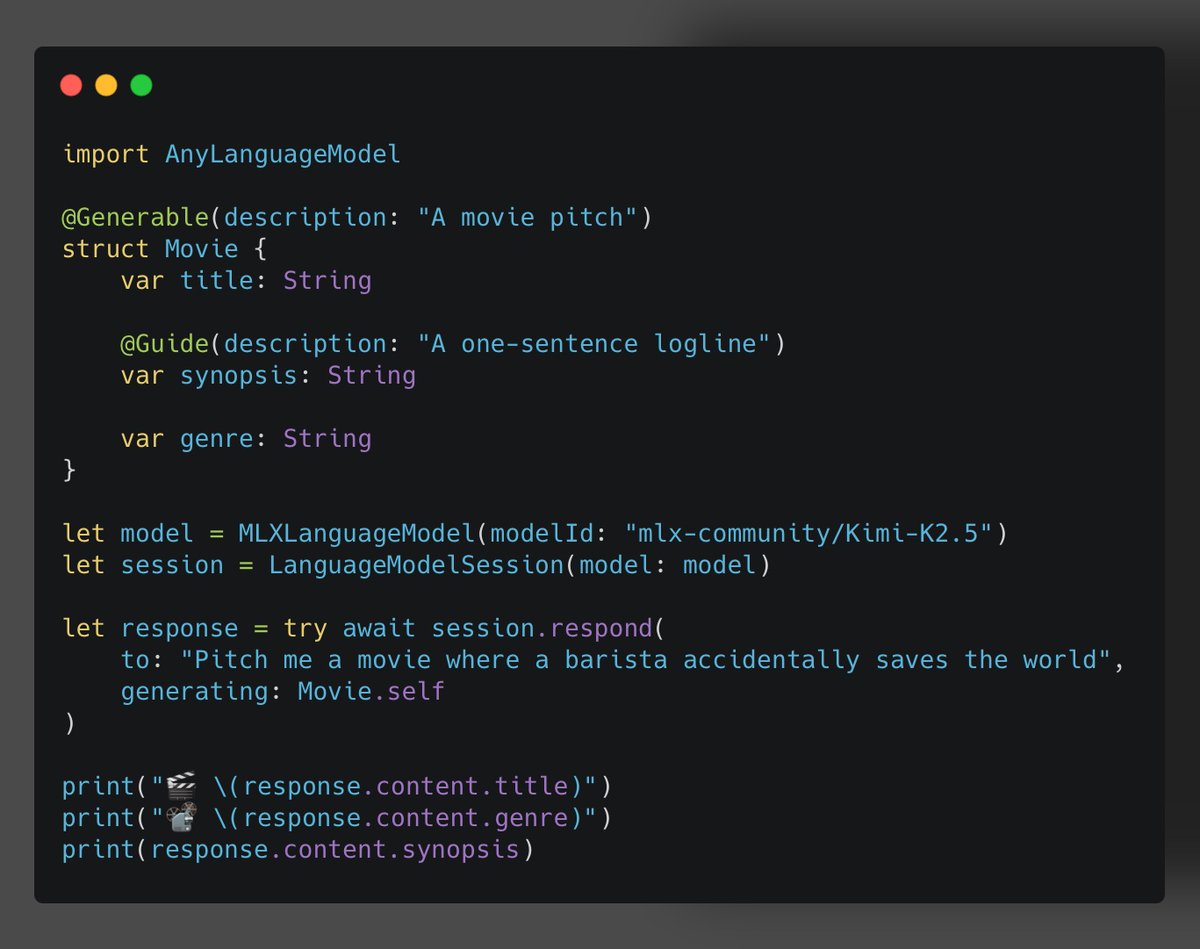



ALT @Generable(description: "Basic profile information about a cat") struct CatProfile { // A guide isn't necessary for basic fields. var name: String @Guide(description: "The age of the cat", .range(0...20)) var age: Int @Guide(description: "A one sentence profile about the cat's personality") var profile: String } let session = LanguageModelSession(model: model) let response = try await session.respond( to: "Generate a cute rescue cat", generating: CatProfile.self ) print(response.content)

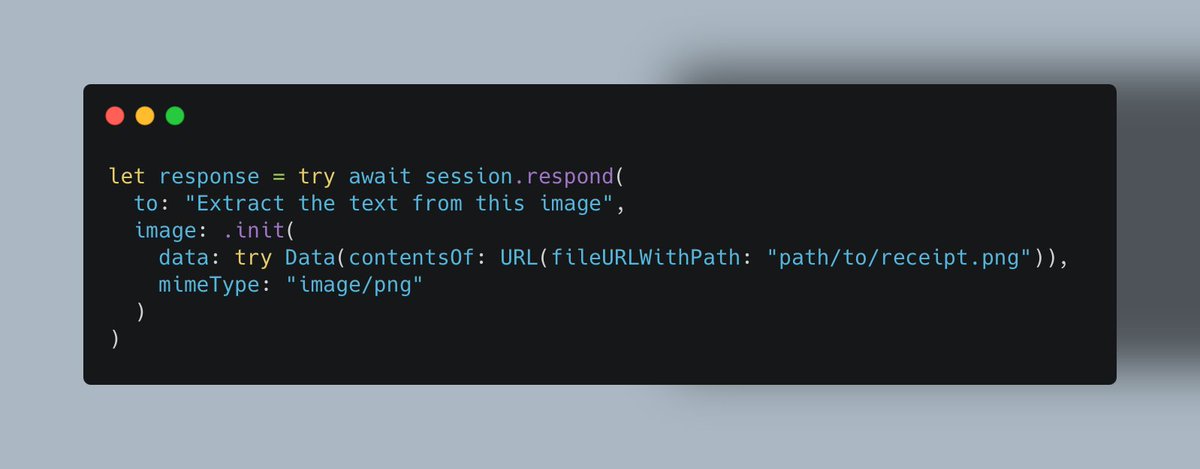
ALT let response = try await session.respond( to: "Extract the text from this image", image: .init( data: try Data(contentsOf: URL(fileURLWithPath: "path/to/receipt.png")), mimeType: "image/png" ) )

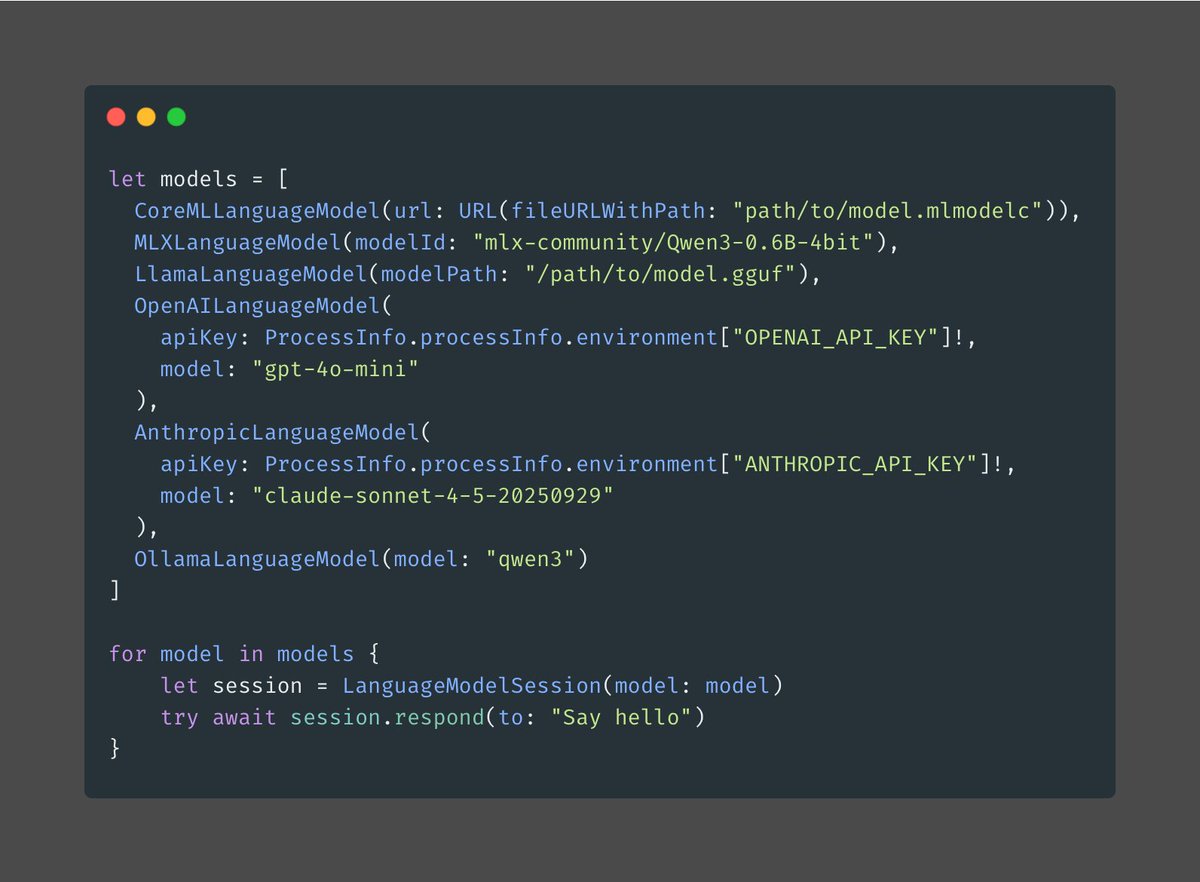
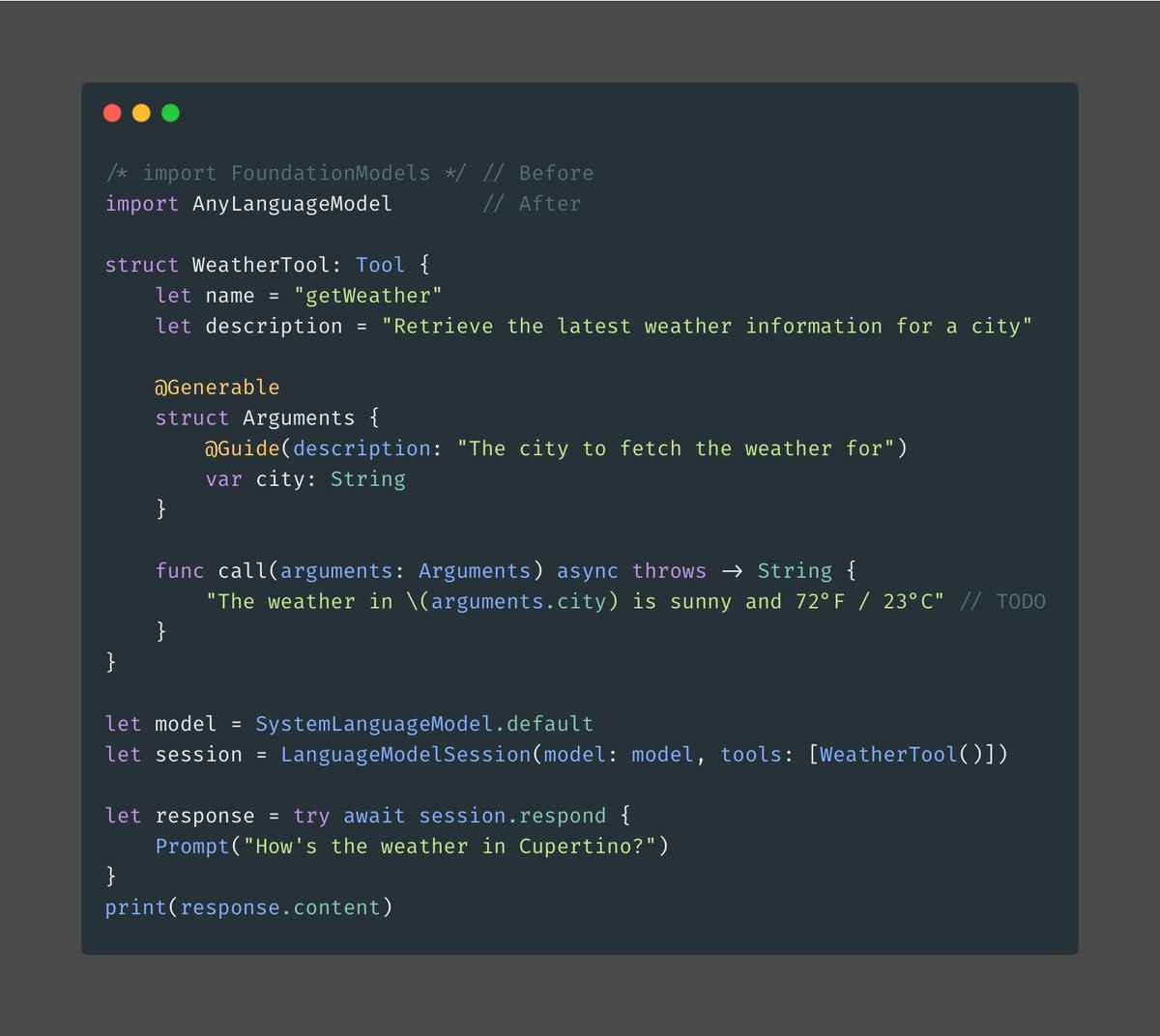
ALT import AnyLanguageModel struct WeatherTool: Tool { let name = "getWeather" let description = "Retrieve the latest weather information for a city" @Generable struct Arguments { @Guide(description: "The city to fetch the weather for") var city: String } func call(arguments: Arguments) async throws -> String { "The weather in \(arguments.city) is sunny and 72°F / 23°C" } } let model = SystemLanguageModel.default let session = LanguageModelSession(model: model, tools: [WeatherTool()]) let response = try await session.respond { Prompt("How's the weather in Cupertino?") } print(response.content)