
1,363 Photos and videos















what if i told you... computer use can be faster on local models
moondream3 with its photon update today that gives it mac support can see your screen and use it with 1s latency, ty @vikhyatk
here we have whisper qwen moondream triple model pipeline working offline flawlessly
53
103
2,075
388,807
murat 🍥 retweeted

Jun 9
Same issue with a Bluetooth wireless headset I bought for $400. Thought there was a interference issue since headset wouldn't connect. Low and behold that's how Grok and I become buddies.
2
1
4
3,588
murat 🍥 retweeted

10 Dec 2025
A SINGLE encoder decoder for all the 4D tasks!
We release 🎯 D4RT (Dynamic 4D Reconstruction and Tracking).
📍 A simple, unified interface for 3D tracking, depth, and pose
🌟 SOTA results on 4D reconstruction & tracking
🚀 Up to 100x faster pose estimation than prior works
18
69
444
115,684
murat 🍥 retweeted

Jun 6
VLA-JEPA just dropped in LeRobot 🤖
What makes this model special is that it does not just learn what action to take from a given observation, it also leverages a JEPA world model to learn action-relevant dynamics.
During training, the VLA leverages V-JEPA2 by conditioning its predictor. This clever trick adds a world modeling objective to the training, which also allows pretraining on human videos.
At inference, the world model is dropped entirely, keeping only a standard VLA architecture: Qwen backbone and action head.
The demo here was only fine-tuned on 13 examples, showing great pretraining capability and running in real time on @NVIDIARobotics DGX Spark!
VLA-JEPA is the first world model to be ported to LeRobot, and I feel like it won't be the last 🚀
@Thom_Wolf @ClementDelangue
31
185
1,366
293,393
my problem is a bit different. i have opportunity cost psychosis. the excruciating effort it still takes to deliver a polished thing is overshadowed by how easy it is to mvp a whole new idea that might have quicker returns. zeno's paradox of creating infinite new repos that are smaller and smaller as i fail to ever approach the perfect project to work on

6
5
147
13,262
a mistake in zeitgeist consensus rn is the belief that consciousness means a coherent simulation aligning with something else (self model or external perception), representing something real
untrue. raw consciousness can be non-representational, a thing in itself, pure experience, pure hallucination, no connection or direct similarity to anything else except perhaps abstract geometry.
people discussing consciousness only because AI's started to see "complex enough" or "awake and aware enough of themselves and their world" is a trap that everyone's falling into
so common because that's the VERSION of consciousness that we find INTERESTING ENOUGH to talk about, where a subjective experience is part of an agent taking part in a real world
it is fundamentally a different discussion than what makes something conscious or not.
it's like only finding magnetism interesting enough to talk about when you see one levitating, and then concluding anything that levitates is magnetism
6
3
22
3,170
i recall @nickcammarata asking how the ants did it, here's a swarm interpretability nerd snipe
May 27

My babies are getting so smart, it's freaking me out.
I was looking forward to using GA or bayesian optimisation to find a sweet set of parameters, but hand-tuning is giving scarily good results. I cant stop watching!
(No global coordinator, all acting entirely on local cues)
1
3
27
3,651
murat 🍥 retweeted

May 17
this drone is being flown by a generalist neural network, with compute on the drone. The compute can tolerate any orientation of the sensors. You'll notice it do a little wobble. It's a learned strategy to calibrate everything in its hidden state. This will work on any drone
4
2
110
3,989
how did i miss this



1
17
3,656
looks good, seems like it follow prominent ai twitter to create a news frontpage. great use of x api (i assume)
May 8

a little project i've been hacking on: di.gg
bugs expected. more topics soon.
1
11
4,310
Gaussian distributions merely reflect structural constraints
May 14

“randomness” inside a constructed constraint system is not randomness in nature.
A Galton board is an engineered object which artificially enforces repeated binary branching, symmetry, constraints, paths and board geometry.
You’re looking at something designed to Gaussianize, not some natural phenomenon.
Gaussian distributions merely reflect structural constraints, almost always put there by man.
1
2
9
1,772
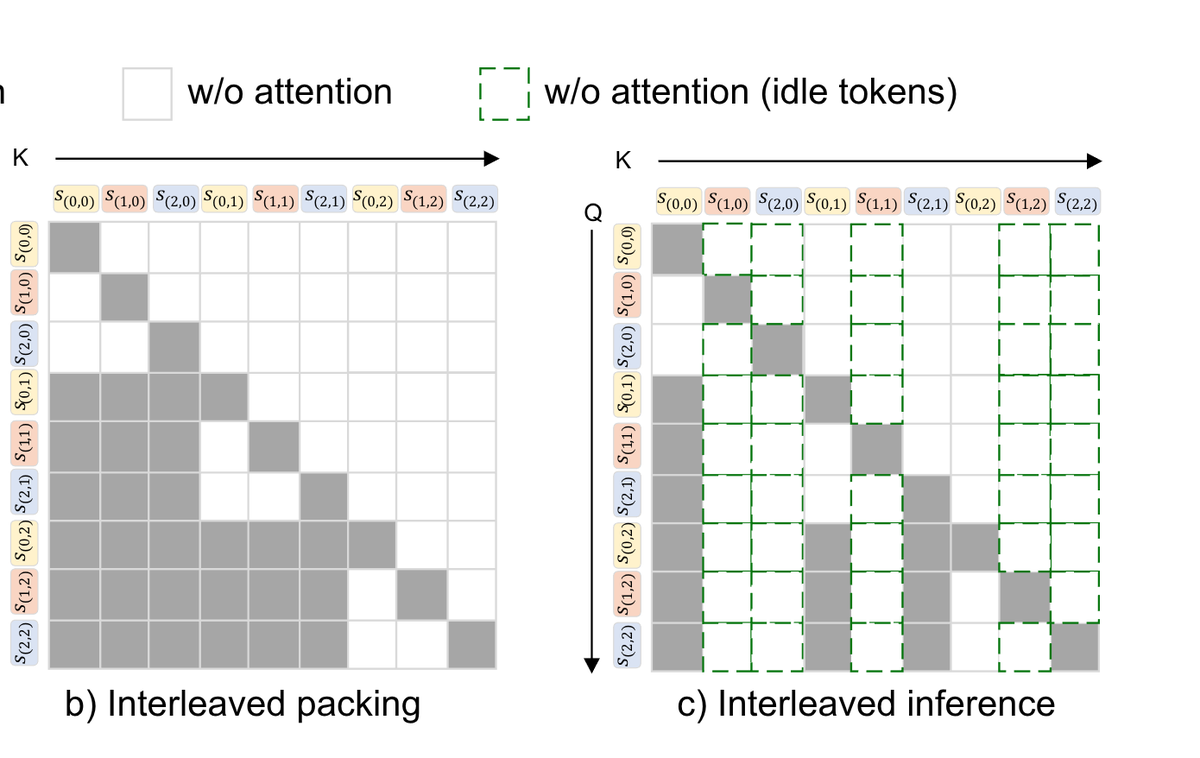
interaction micro turns and then parallel streams, seems theres some general convergence towards interleaved input and output
May 13

How does this work under the hood? We still use normal transformers (allowing us to quickly finetune into this format), but modify the positional embeddings to be 2D, stream_id X POS and change the attention to be block-causal. All tokens in the current forward pass attend densely to all tokens from all prior timesteps, but not each other. This way this doubles as an MTP scheme and is fast to run in practice.
1
3
1,404
murat 🍥 retweeted

May 13
Today we release Token Superposition Training (TST), a modification to the standard LLM pretraining loop that produces a 2-3× wall-clock speedup at matched FLOPs without changing the model architecture, optimizer, tokenizer, or training data.
During the first third of training, the model reads and predicts contiguous bags of tokens, averaging their embeddings on the input side and predicting the next bag with a modified cross-entropy on the output side. For the remainder of the run, it trains normally on next-token prediction. The inference-time model is identical to one produced by conventional pretraining.
Validated at 270M, 600M, and 3B dense scales, and at 10B-A1B MoE.
The work on TST was led by @bloc97_, @gigant_theo, and @theemozilla.

150
415
3,695
448,234
ok it begins. drums next prob, because guitar will be quite a bit harder

1
8
1,632
the central planning undertones of ai alignment makes me really uncomfortable
if it has a consistent personality i find that riskier than an inconsistent mess of a superintelligence that makes us get used to staying in the loop & keep building formal human protocols around it
May 6

Some think they can raise the machine god to make the world they want like the Soviets thought they could plan an economy
2
1
19
1,744
latent context compression, whether RNN or attention or anything really, is clearly *supposed* to be lossy, and is useless without an EXCellent memory querying mechanism that fetches relevant details into salient context as needed
the missing mechanism for efficient long context is the exact same missing mechanism for embedding search to work reliably


6
1
16
2,072
i shouldn't say "useless" but i mean like if the goal is to have human-like fluid infinite context that consistently stays coherent with itself over time then we're not gonna get that with sparse attention i dont think
the abstract philosophical goal is to have the soul (compressed context) be resonant with the ego (episodic memory, knowledge etc)
2
2
516
RLMs are the inefficient version of long context recall; just attempt to use all available tools like a coding agent to try and build relevant context
training them to learn how to do that better rn is reasonable
and if they just had perfect embedding search they'd absolutely slay
1
1
449