
Joined August 2008
- Tweets 4,942
- Following 2,587
- Followers 4,377
- Likes 5,619
240 Photos and videos







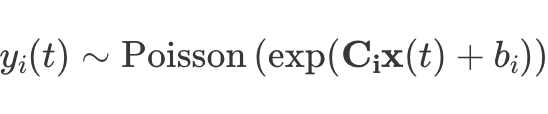
Pinned Tweet

5 Aug 2024
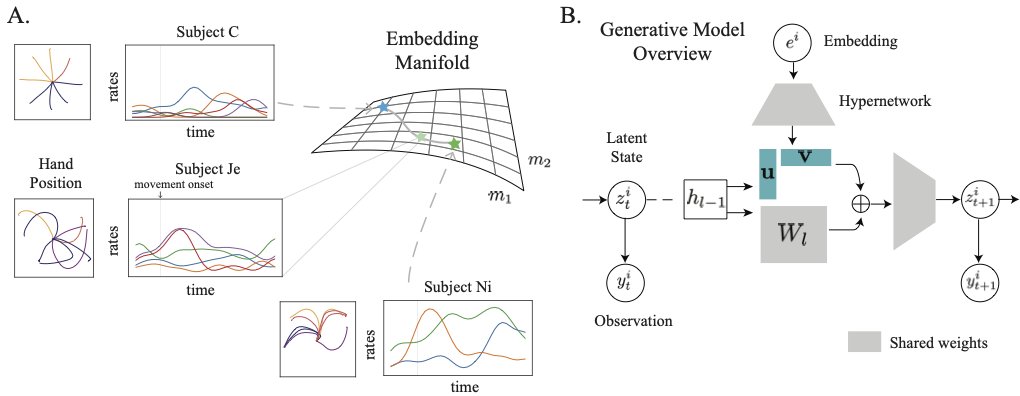
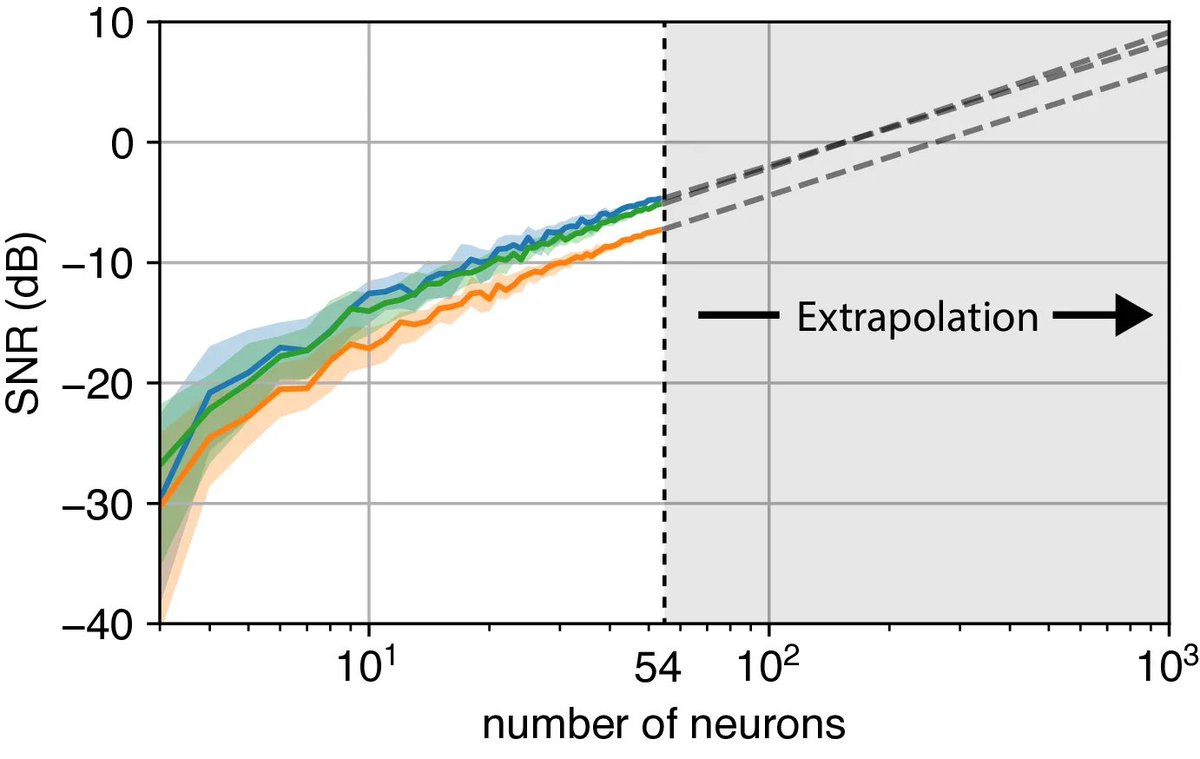
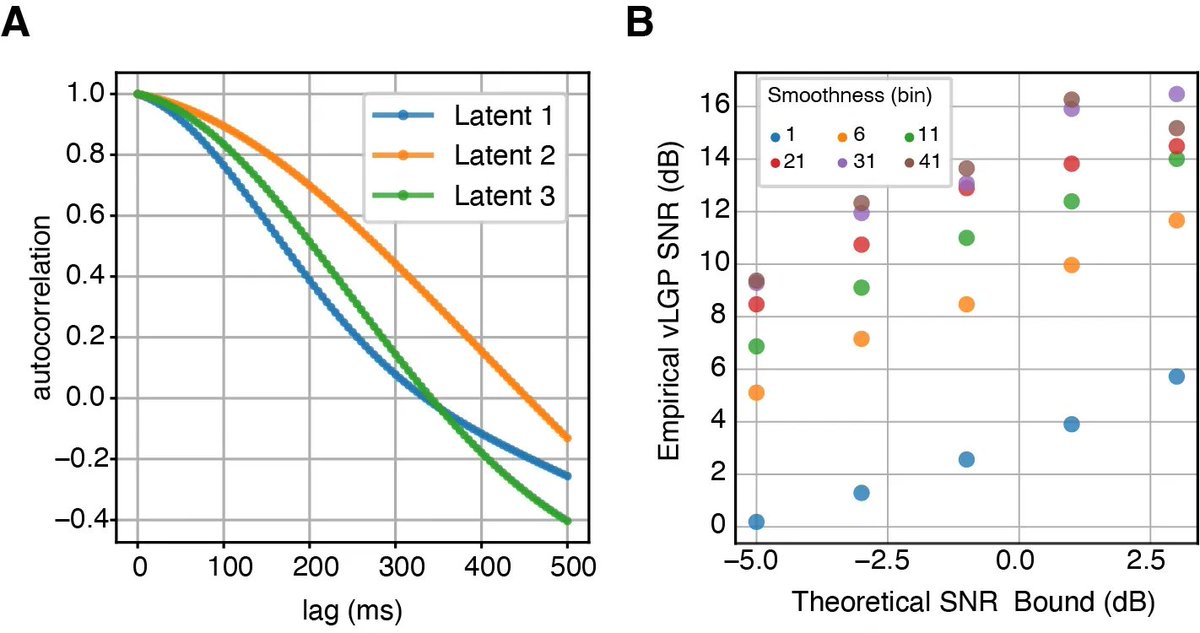
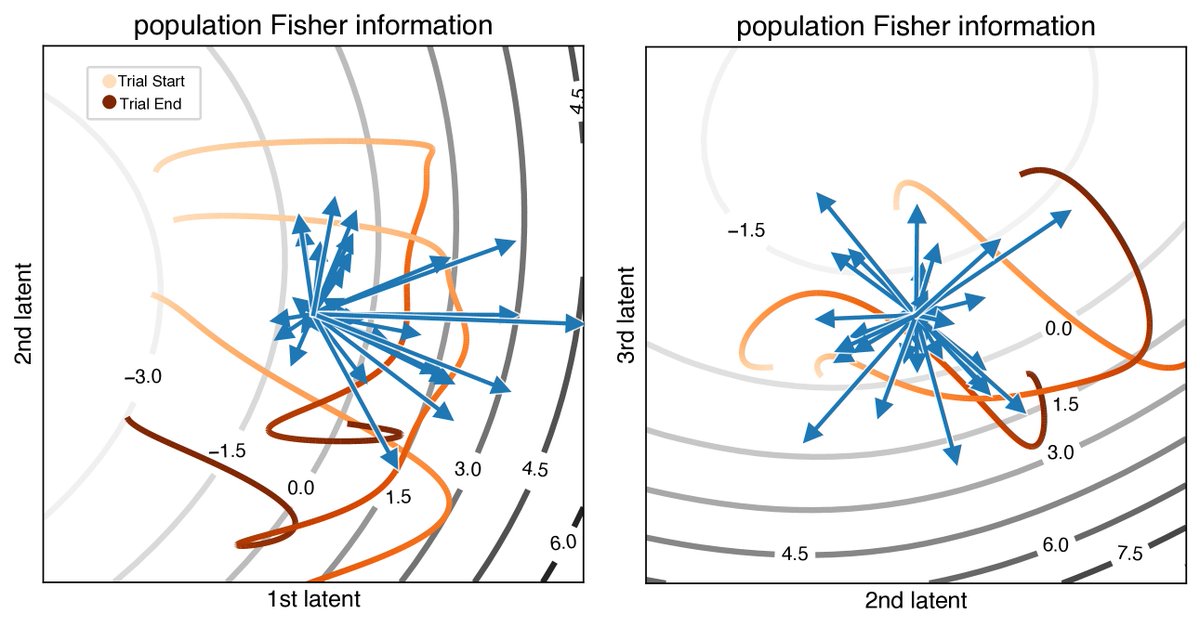
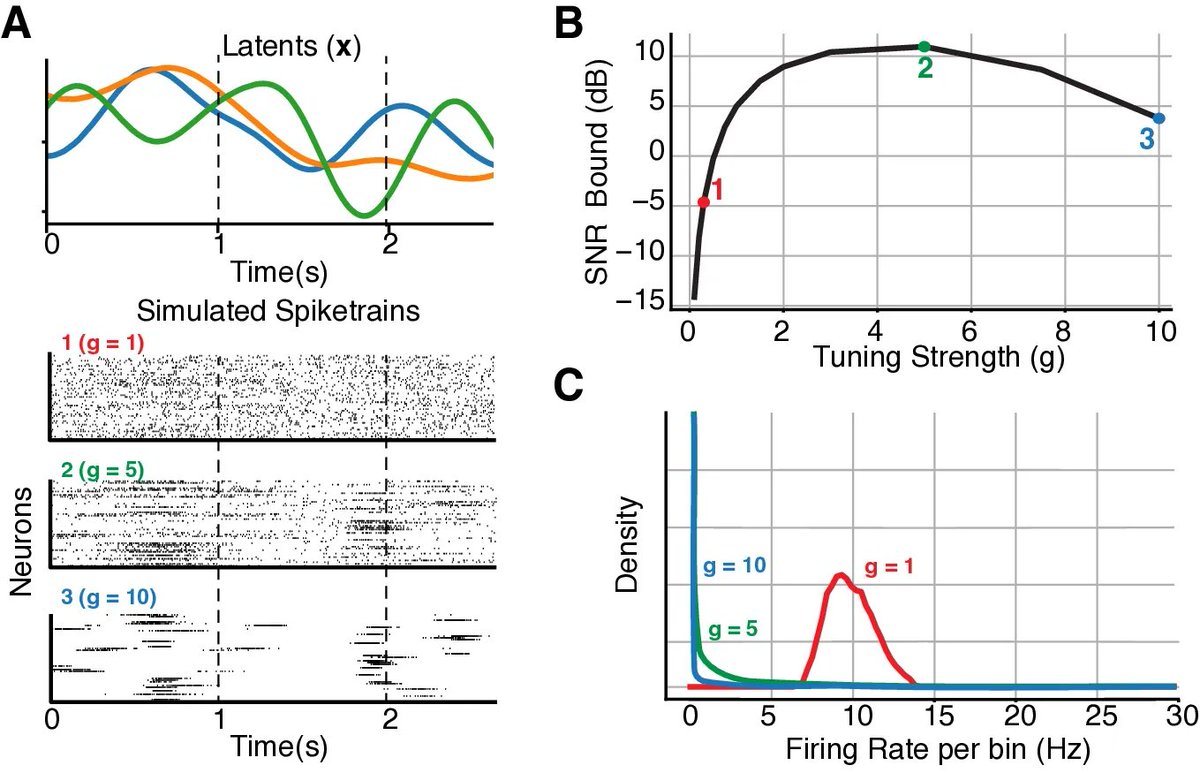
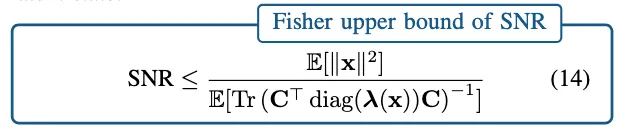
A new preprint that revives the theory of continous attractors that may be surprising to you! Despite their mathematical fragility, we show that they are functionally *robust*. No wonder we see approximate continuous attractors in neuroscience often. arxiv.org/abs/2408.00109
4
38
114
16,355
Il Memming Park retweeted

🧠🗣️ Ever stumbled over your words, realizing only after speaking them outloud? Your brain might not have followed the plan. New preprint on the neural ensemble organization of speech motor plans and what it means for speech BCIs doi.org/10.64898/2026.04.27.… 1/10
1
34
136
10,259
Apr 16
I've been a happy customer of @TheBrainTech product since 2015 or before, using the free tier which had basic cloud sync function. I finally upgraded to the PRO version and paid $200 and I can no longer use the basic sync function... am I doing something wrong?
1
381
Mar 13
If you are at #cosyne2026 come see poster [2-152] Dynamical archetype analysis: Autonomous computation. Ábel Ságodi is presenting how you can compare dynamical systems at behaviorally relevant timescale while keeping the interpretability!
1
13
810
Mar 11
Are you at #cosyne2026 and looking for a postdoc position? We are hiring! Send me a message or find me! catniplab.github.io/postdoc-…
2
5
14
2,697
Il Memming Park retweeted

Jan 11
Happy to share that our new paper is out in Nature Communications with Zoe Ashwood, @IntlBrainLab, and @jpillowtime!
We study how animals switch between internal decision-making states in non-stationary environments using a GLM-HMM framework.
nature.com/articles/s41467-0…
9
21
2,848
Il Memming Park retweeted

Joint junior faculty position in Computational Neuroscience, split between Ctr for Computational Neuroscience at @FlatironInst and the CUNY Graduate Center @GC_CUNY. Application deadline: 16 Jan 2026!
simonsfoundation.org/flatiro…
1
15
36
5,406
Jan 5
How can I accelerate breakdown of caffeine in my body? I will need to increase CYP1A2 (P450) activity (without smoking). Vigorous exercise over 30 days was shown to increase it up to 70%? pubmed.ncbi.nlm.nih.gov/1394…
284
Jan 2
Learning a lot while preparing for a lecture on RNNs for neuroscience.
13
615
30 Dec 2025
Gonçalo M. Tavares's poetry book, "Mr. Swedenborg and the Geometrical Investigations" is *not* available on amazon.com... ISBN: 9896419981
amzn.to/3YQB4yK
1
322
20 Dec 2025
What should the opposite of twisting be called?
0%
De-twisting
100%
Un-twisting
10 votes • Final results
329
16 Dec 2025
Applications are now open for the International Neuroscience Doctoral Programme (INDP) at Champalimaud Foundation, Lisbon, Portugal.
Deadline for application: Jan 31, 2026
fchampalimaud.org/champalima…
The programme includes an initial year of classes three lab rotations.
1
1
234
16 Dec 2025
We seek motivated applicants from all areas of neuroscience, as well as physics, math, computer science, electrical/biomedical engineering, and related quantitative backgrounds. English is the working language. It's an American-style graduate program in Europe.
1
195
16 Dec 2025
The research labs you can join through INDP range from systems neuroscience, computational neuroscience and clinical neuroscience, to neocybernetics, neuroethology, and natural intelligence.
To learn more about the culture and value, check out: fchampalimaud.org/about-cr
181
12 Dec 2025
One advantage of monosemantic, sharply-tuned, grandmother-cell, axis-aligned, neuron-centric representation as opposed to polysemantic, mixed-selective, oblique population code is that it can benefit from evolution. Genes are good at operating at the cell level. #neuroscience
4
627
7 Dec 2025
Some of my favorites from #NeurIPS2025
more neg max Lyapunov exp => faster parallelized RNN convergence
Gonzalez, X., Kozachkov, L., Zoltowski, D. M., Clarkson, K. L., & Linderman, S. Predictability Enables Parallelization of Nonlinear State Space Models. openreview.net/forum?id=7AGX…
3
14
51
8,655
7 Dec 2025
score/flow matching diffusion models only starts memorizing when trained for long enough
Bonnaire, T., Urfin, R., Biroli, G., & Mezard, M. (2025). Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training. openreview.net/forum?id=BSZq…
1
1
3
437
7 Dec 2025
Theoretical Insights on Training Instability in Deep Learning TUTORIAL
uuujf.github.io/instability/
gradient flow-like regime is slow and can overfit while large (but not too large) step size can trasiently go far, converge faster, and find better solutions #optimization #NeurIPS2025
1
2
398
4 Dec 2025
Melanie Mitchell's keynote reminds us that it is not easy to evaluate intelligence (AI, babies, animals, etc) and benchmarks can be VERY misleading. #NeurIPS2025
6
576