
9 Photos and videos






Jun 13
This is what I wanted agent observability to feel like. Traces that end in a code change.
1
4
1,023
Jun 10
It was great working with @oliveholistic to improve their product experience! If you want faster and cheaper inference at frontier model quality, shoot me a DM.
Jun 10

Specialized models are becoming a practical path to better AI UX.
Olive moved from a frontier model to a custom model trained with Inference Catalyst for their food verdict workflow.
After a user scans a product, the model now delivers near-instant verdicts on what to watch out for, making the in-store experience faster and more seamless while cutting inference cost significantly.
Results:
- p50 latency: 2,721ms → 591ms
- p99 latency: 6,414ms → 998ms
- time to first word: ~0.25s
- inference cost: ~70% lower
Great working with @oliveholistic on this!
Full case study here: inference.net/case-study/oli…
1
38
Mike Pollard retweeted

May 20
Shout out to @samhogan @AmarSVS @francescodvirga @atbeme @mikepollard_dev and the rest of the Inference dot net team
May 20

A glimpse into our work with @inference_net thanks to @nvidia!
1
3
18
922
May 28
Install our SDK, collect traces, improve your agents.
May 28

3 weeks ago we open-sourced HALO
this led to talking with dozens of teams running agents at scale
we realized the current agent monitoring tools aren't built for the future that we so clearly see ahead of us
today we’re releasing native OpenTelemetry-compatible agent tracing on @inference_net, powered by the same open-source core behind HALO
37
Mike Pollard retweeted

Apr 17
We're releasing Schematron V2, a family of Specialized Language Models for converting messy HTML to structured JSON
frontier performance at 1/10th the cost
Schematron V2 was designed in partnership with some of the largest web-scraping companies in the world to meet the demands of their heaviest workloads
Schematron-V2-Turbo and Schematron-V2-Small are available today on @inference_net
Get started: docs.inference.net/workhorse…

Feb 4
I found out today that two of the largest web scraping companies in the world are using a custom Llama 3 model we released last year to process millions of webpages per day.
Schematron-3b: HTML -> JSON parsing
Frontier quality at dirt-cheap prices.
huggingface.co/inference-net…
6
8
74
13,563
Apr 14
Come train a custom model
Apr 14
Introducing Catalyst: a developer platform to monitor, train & deploy self-improving AI models
built for teams operating AI products at scale
Catalyst can automatically:
- collect traces from your agents
- curate training data & evals
- train & deploy models on par w/ Opus 4.6

38
Apr 10
More Inference events coming soon so stay tuned!

Absolute blast with @inference_net @sentry and @PlanetScale in SF. I need to work on recreating this in Austin 👀


2
56
Mar 18
PodSnacks is probably my favorite daily email. News from everything I’m interested in all in one place.

I'm biased but the Headlines email from @PodSnacks is my favorite source of news rn

1
3
155
Mar 17
Come hang out with @samhogan and I. These dinners are always a great time.
Mar 17
I’m hosting dinner parties again.
8-10 people, twice per month in San Francisco.
If you are a founder, and especially if you are NOT a founder, and you would like to come for an evening of good food and conversation, send me a DM
First dinner is March 27




2
1
20
4,020
Mike Pollard retweeted

Mar 11
Day Zero fine-tuning & hosting support for Nemotron 3 Super by @nvidia is now live
Fine-tune on real production traces & deploy on high-performance infrastructure optimized for Nemotron 3 Super
Your data, your weights, your performance edge
Learn more: inference.net/blog/nemotron-…
7
6
25
7,905
Mike Pollard retweeted
Mar 10
Going to open source our own internal version of this soon. It’s called Gator and it rocks

10
5
188
38,520
Mike Pollard retweeted
Mar 8
What if a codebase was actually stored in Postgres and agents directly modified files by reading/writing to the DB?
Code velocity has increased 3-5x. This will undoubtedly continue. PR review has already become a bottleneck for high output teams.
Codebase checked-out on filesystem seems like a terrible primitive when you have 10-100-1000 agents writing code.
Code is now high velocity data and should be modeled at such. Bare minimum, we need write-level atomicity and better coordination across agents, better synchronization primitives for subscribing to codebase state changes and real-time time file-level code lint/fmt/review.
The current ~20 year old paradigm of git checkout/branch/push/pr/review/rebase ended Jan 2026. We need an entirely new foundational system for writing code if we’re really going to keep pace with scale laws.
459
103
2,122
942,870
Mike Pollard retweeted

Feb 17
Introducing our new Schematron benchmark. We took some time to compare all of the latest open source models to see which one takes the crown.
The benchmark essentially measures the ability of LLMs to take raw HTML along with a JSON schema, and then fill out that schema. We measure things like recall/precision, hallucinations, and ability to handle ambiguity.
The benchmarks are graded with an ensemble of frontier models on a 5 point rubric.
We can see that GLM 5 is the best open source model currently for schema extraction. Surprisingly, GPT-OSS 120B does very well at these type of extraction tasks as well.
Another interesting result is we noticed degradation of quality using Qwen3.5 Plus on this task versus the original Qwen3.5 397B MOE.
The inputs can be up to 120K tokens, so this is akin to a long context benchmark, with an additional reasoning layer.
We will be open sourcing this benchmark if it gains sufficient traction. Also, more benchmarks coming from our side!
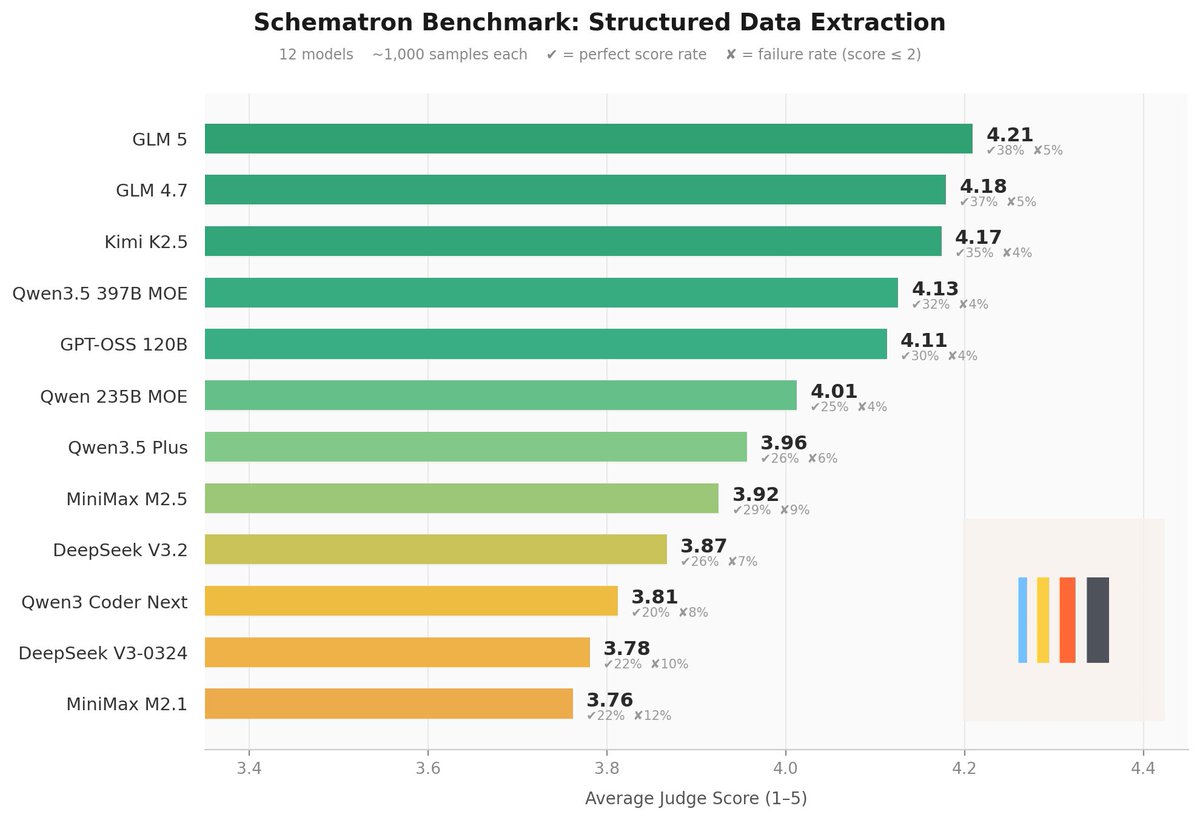
5
4
15
7,688

Mike Pollard retweeted
Feb 3
We're welcoming @mikepollard_dev to @inference_net as our Founding DevRel Engineer!
Mike and I won a pitch competition for my first company nearly 7 years ago
Life is long. When you find someone you love to work with, keep them close. You never know when your paths may cross


8
3
44
4,388
22 Sep 2025
Bought my gf an espresso machine and now I'm forced to drink 6 cups a day while she fine tunes the grind size and tamping methods
2
183
17 Sep 2025
Algorithmic short form videos aren't enough anymore. When can we get 0.5s AI-generated bursts that just cook the receptors directly?
1
3
180
10 Sep 2025
I am a machine that turns zyns and caffeine into half-finished b2b saas
3
187
Mike Pollard retweeted
23 Aug 2025
Dinner Number 1 was a resounding success!
Dinner Number 2 is Sept 5.
10 seats. Private dining room at a classic spot in the heart of SF.
DM me to come :)
Going to do 5 more of these and then throw a bangin’ party with everyone




18 Aug 2025
I’m hosting dinner parties again.
8-10 people, twice per month in San Francisco.
If you are a founder, and especially if you are NOT a founder, and you would like to come for an evening of good food and conversation, send me a DM.
First dinner is August 22nd!
15
2
140
40,652
8 Aug 2025
I like to refer to the ^ character in my package.json as the break your app randomly character.
2
102