Postdoctoral fellow with @ETH_AI_Center. CSS NLP. Previously CS PhD @umdcs, intern at @msftresearch and @ai2_allennlp.
- Tweets 926
- Following 603
- Followers 1,266
- Likes 4,916


















ALT Meme gently critiquing the practice of silicon sampling. STOP SILICON SAMPLING LLMS ARE NOT SIMULATIONS OF PEOPLE DOZENS OF PAPERS yet NO REAL-WORLD USE FOUND for "polling" LLMs Wanted to prompt an LLM anyway for a laugh? We had a tool for that: It was called "GUESSING" "Yes, please tell me your presidential preference on a 1-100 scale." "Mark, this is your digital twin" – Statements dreamed up by the utterly Deranged LOOK at what Prompt Engineers have been demanding your Respect for all this time, with all the layers and attention heads we built for them: (This are REAL figures, using FAKE people). [figures from some papers, content not important] "Hello, pretend you are a Korean-American living in New Jersey, what is your favorite gum brand?" They have played us for absolute fools

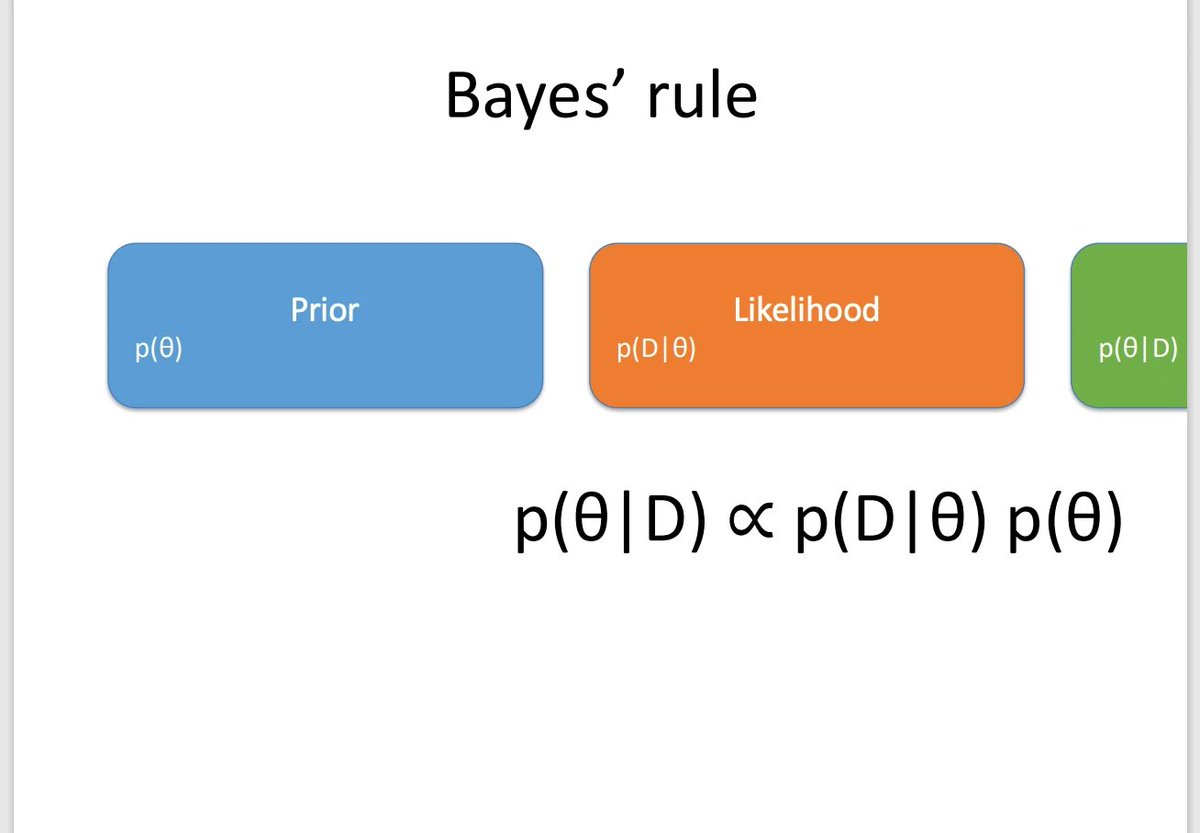
ALT A slide showing that the posterior is proportional to the likelihood times the prior
ALT Copilot-generated powerpoint slides for bayes' rule: very bad