
ヾ(๑╹◡╹)ノ
Joined September 2018
- Tweets 3,751
- Following 969
- Followers 1,874
- Likes 8,879
317 Photos and videos








Pinned Tweet

May 8
現在のAIの中核であるTransformerを置きかえることを目指す論文の改訂版を出しました!
✅ 学習時より圧倒的に長い文でも性能維持&正確な情報取得
✅ 学習の安定性が桁違い(なんと学習率1でも学習可能!)
✅ モデルサイズ削減 & 推論速度向上
✅ 解釈性の大幅向上
本文に図を追加してわかりやすくまとめ直しました!
読んでもらえると嬉しいです!!周りの人にもぜひ共有してください!!
論文 → arxiv.org/abs/2604.01178


4
100
655
89,105
みぃ🍵 retweeted

May 13
"Screening Is Enough"
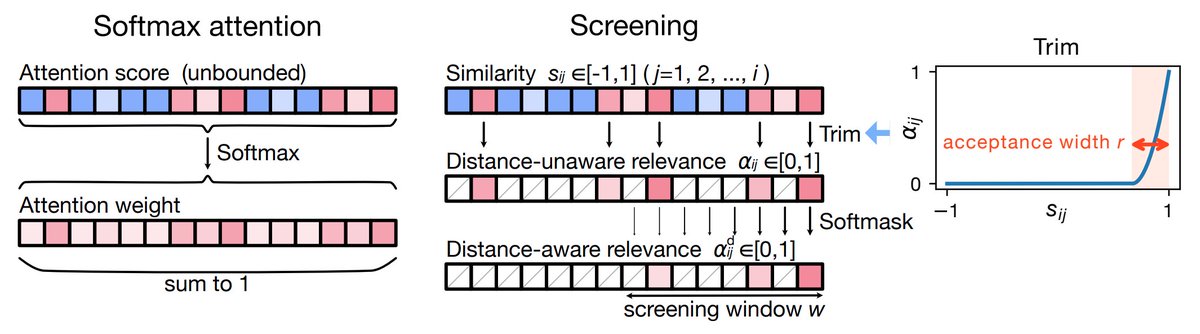
> [Softmax attention] does not provide an independently interpretable measure of query—key relevance: attn. scores are unbounded, while attn. weights are defined only relative to competing keys. Consequently, irrelevant keys cannot be explicitly rejected...
May 8

I just released a revised version of my paper on Multiscreen, an alternative to Transformer for long-context language modeling.
✅ Maintains performance and retrieves information accurately on contexts far longer than those seen during training
✅ Much more stable at large learning rates — it can even train with learning rate 1
✅ Smaller model size & faster inference
✅ More interpretable context selection
I added more figures to the main text and rewrote the paper to make it easier to follow. I’d be very happy if you read it!
Paper → arxiv.org/abs/2604.01178
1
5
3,629
May 8
現在のAIの中核であるTransformerを置きかえることを目指す論文の改訂版を出しました!
✅ 学習時より圧倒的に長い文でも性能維持&正確な情報取得
✅ 学習の安定性が桁違い(なんと学習率1でも学習可能!)
✅ モデルサイズ削減 & 推論速度向上
✅ 解釈性の大幅向上
本文に図を追加してわかりやすくまとめ直しました!
読んでもらえると嬉しいです!!周りの人にもぜひ共有してください!!
論文 → arxiv.org/abs/2604.01178
4
100
655
89,105
May 8
English version:
x.com/mithernet/status/20527…
May 8
I just released a revised version of my paper on Multiscreen, an alternative to Transformer for long-context language modeling.
✅ Maintains performance and retrieves information accurately on contexts far longer than those seen during training
✅ Much more stable at large learning rates — it can even train with learning rate 1
✅ Smaller model size & faster inference
✅ More interpretable context selection
I added more figures to the main text and rewrote the paper to make it easier to follow. I’d be very happy if you read it!
Paper → arxiv.org/abs/2604.01178
2
1
7
11,367
May 8
I just released a revised version of my paper on Multiscreen, an alternative to Transformer for long-context language modeling.
✅ Maintains performance and retrieves information accurately on contexts far longer than those seen during training
✅ Much more stable at large learning rates — it can even train with learning rate 1
✅ Smaller model size & faster inference
✅ More interpretable context selection
I added more figures to the main text and rewrote the paper to make it easier to follow. I’d be very happy if you read it!
Paper → arxiv.org/abs/2604.01178
8
27
161
29,705

パラメータ数92%削減、推論速度3.2倍。 Transformerの限界を突破する新アーキテクチャ『Multiscreen』が注目されているようだ。論文タイトルは “Screening is enough” 。 「Attention Is All You Need」への挑戦状とも取れる内容である。
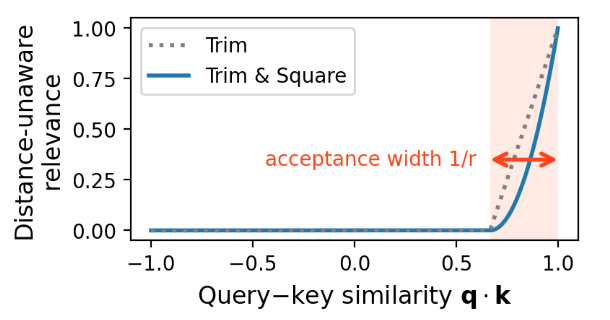
従来の研究は「いかにして重要な情報に注目するか」を追求してきた。この論文はその逆で「無関係な情報をいかに切り捨てるか」というアプローチを提案する。
従来のAttention機構はSoftmaxを用いて「相対的な重要度」を計算するが、これは無関係なノイズにも重みを割り当ててしまう欠点があった。提案手法のMultiscreenは、各キーに対して絶対的な閾値で判定を行い、不要な情報を削除してから集約を行う。
たとえば、Softmaxは「AがBよりマシなら、Aに重みを振る」という相対評価だったが、Multiscreenでは「AもBもゴミなら、両方捨てる」という挙動になる。
この変更により、同じトークン予算で、Transformerのベースラインよりも40%少ないパラメータで同等の検証損失を達成した。まだTransformerでは学習が発散してしまうような大幅に大きな学習率でも、Multiscreenでは安定した最適化が可能である。大きな学習率を使えるので微調整が短時間で実行でき、高速な実験サイクルを回せるようになる。
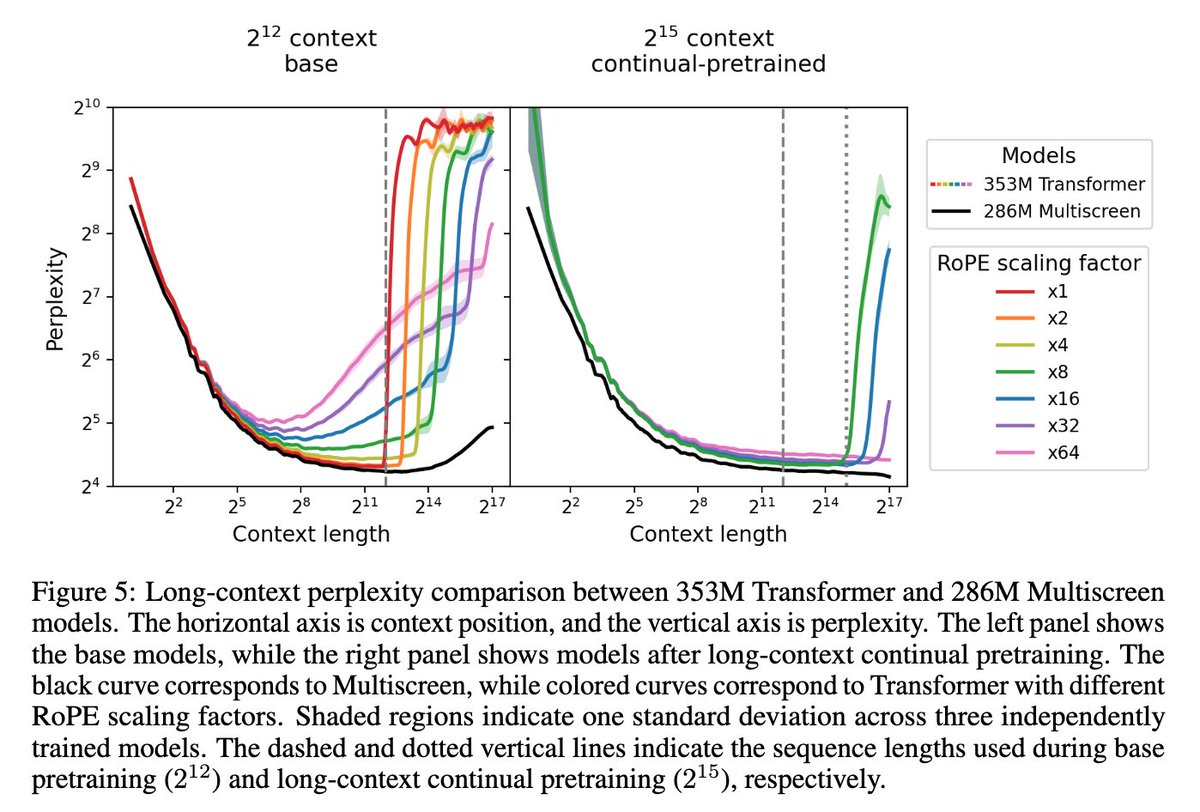
長文脈評価において、Multiscreenはパープレキシティにおいて強い性能を維持し、学習中に見た長さを遥かに超える文脈長でも、検索性能の劣化をほとんど示さない。AIや統計の分野では、これを外挿性(Extrapolation)が高いと表現するようだ。外挿性は学習した範囲外でも正しく振る舞える能力のことを指す。
条件によってはモデルパラメータが92%少なくても、一貫してTransformerベースラインを上回る。つまり情報の密度が非常に高いということである。100Kトークンのコンテキストを持つ次のトークン予測では、MultiscreenはTransformerベースラインに対して、推論レイテンシーを2.3-3.2倍削減する。
情報の集約ロジックを相対評価から、絶対選別にシフトさせた点が画期的で、メモリ、速度、精度のすべてにおいてブレイクスルーを達成している。大型のモデル開発だけでなく、エッジデバイスでのLLM実行においても有望なアーキテクチャである。
全員に配分する民主主義をやめて、一部の適格者だけ通す門番を導入したという例えがわかりやすい。
arxiv.org/abs/2604.01178
1
4
13
2,290
Apr 3
著者です!
Attentionの「相対比較しかできない」という制約を外した、新しい機構を提案しました
①まずわかりやすい利点
✅学習時より圧倒的に長い文でも性能維持&正確な情報取得
✅収束が非常に高速(LR=1でも学習可能)
✅モデルサイズ4割削減
✅推論速度3倍超
(続く)
arxiv.org/abs/2604.01178
15
133
803
87,579
Apr 6
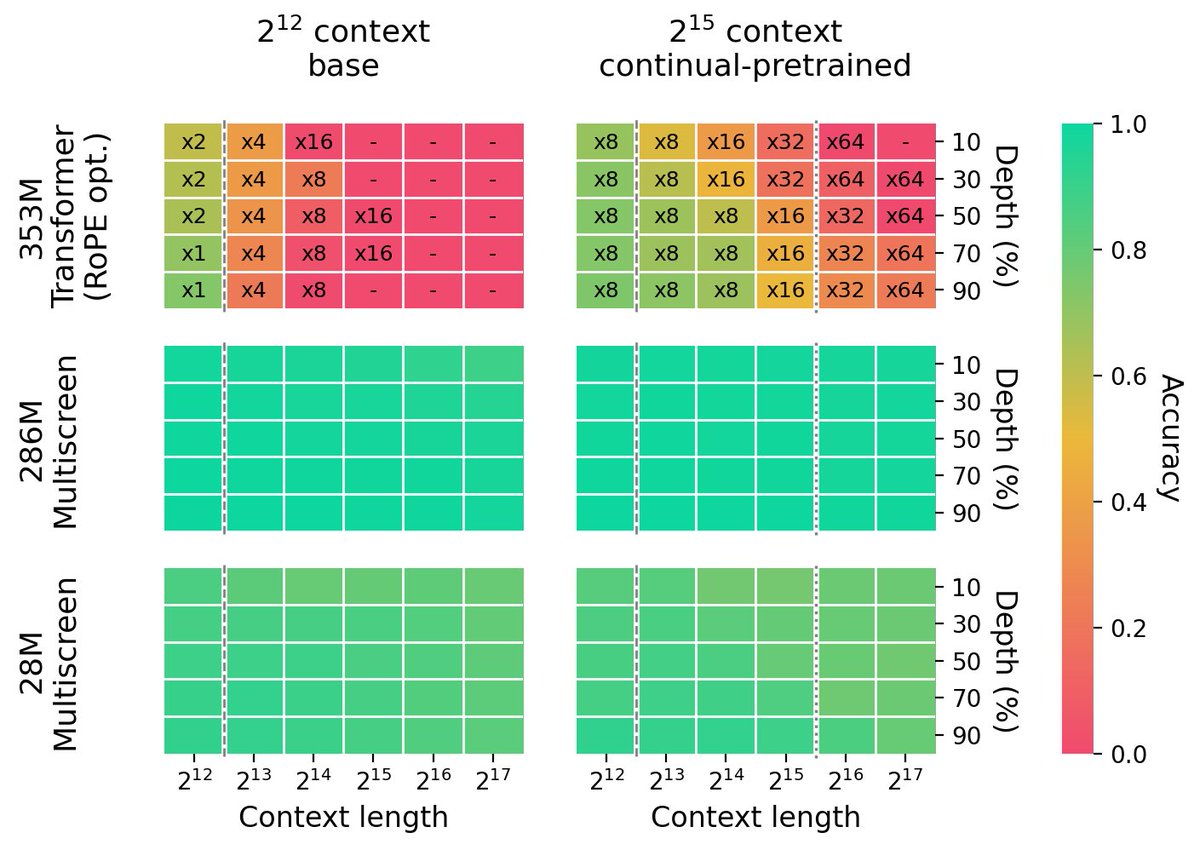
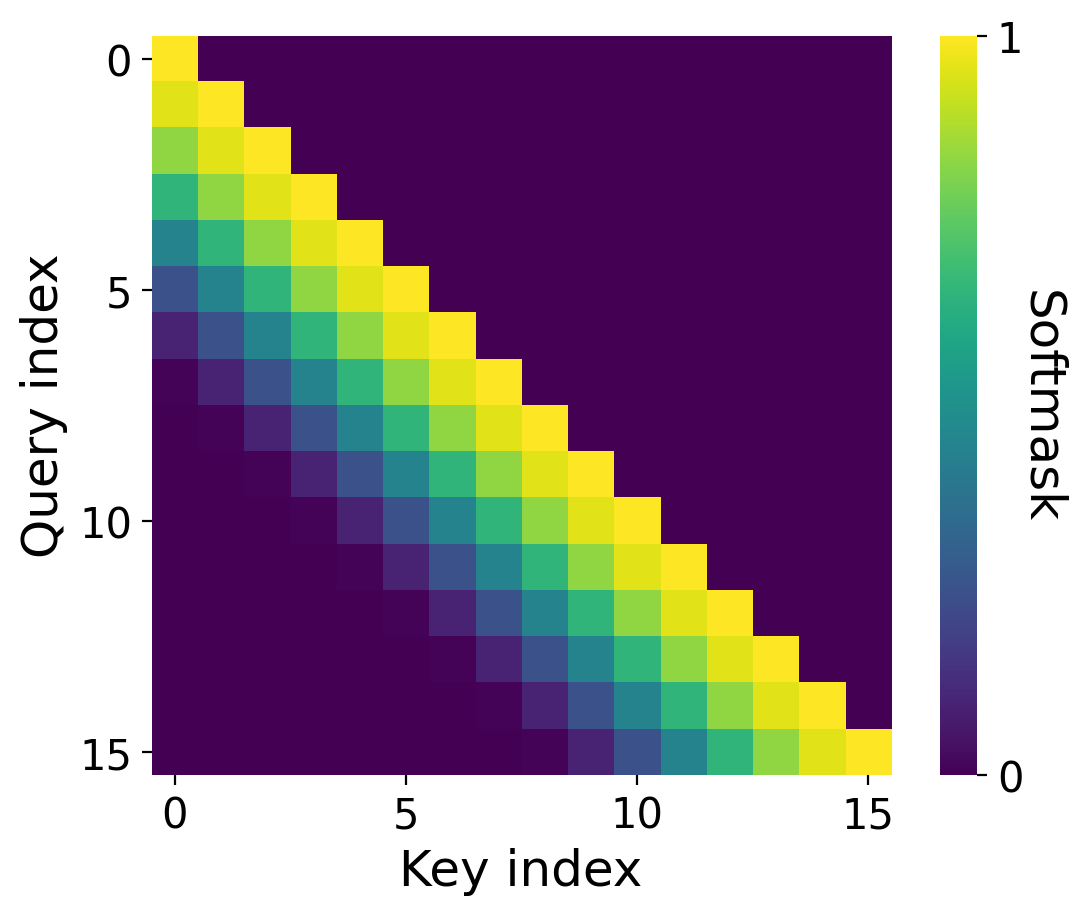
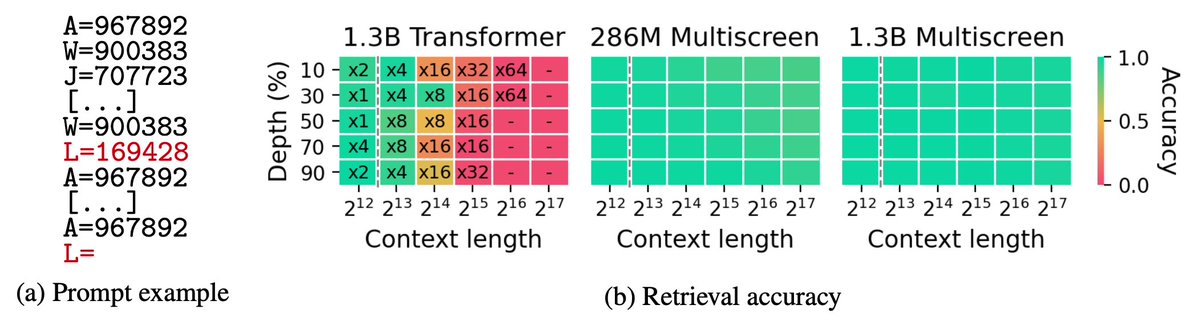
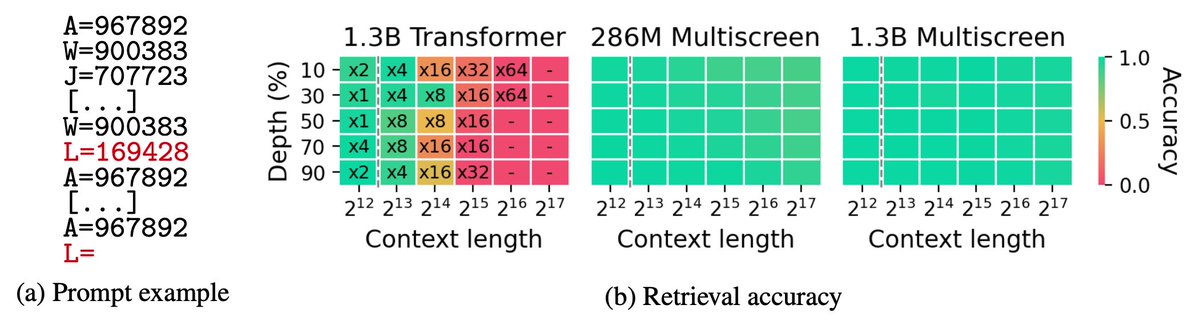
⑦検索性能(ここが一番重要!)
📊 ABCDigits(検索タスク)
(横軸=文の長さ)
✅Multiscreenは超長文でもほぼ劣化しない
⚠️Transformerは長くなると崩壊
しかも学習長の場合でさえ
✅なんと「92%」小さいモデルが検索性能で勝る(!)
📌 小さいのに検索性能強い
📌 長文でもほぼ劣化しない
1
10
4,481
Apr 6
😍😍😍

🚨This week's top AI/ML research papers:
- HISA
- Embarrassingly Simple Self-Distillation Improves Code Generation
- FIPO
- SKILL0
- Reasoning over mathematical objects
- Screening Is Enough
- Path-Constrained Mixture-of-Experts
read this in thread mode for the best experience
6
1,803
Apr 6
綺麗な説明図が書けたし論文にも追加しようかな
Apr 6
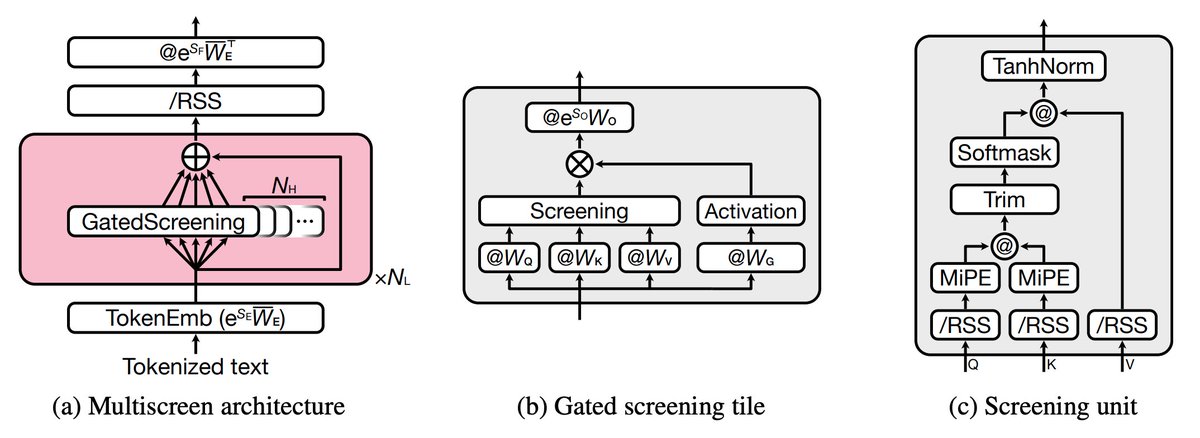
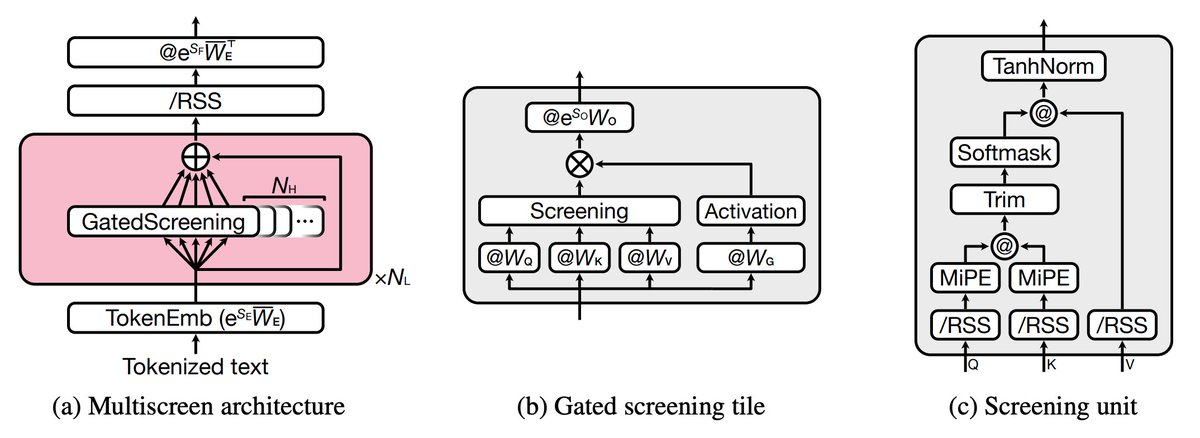
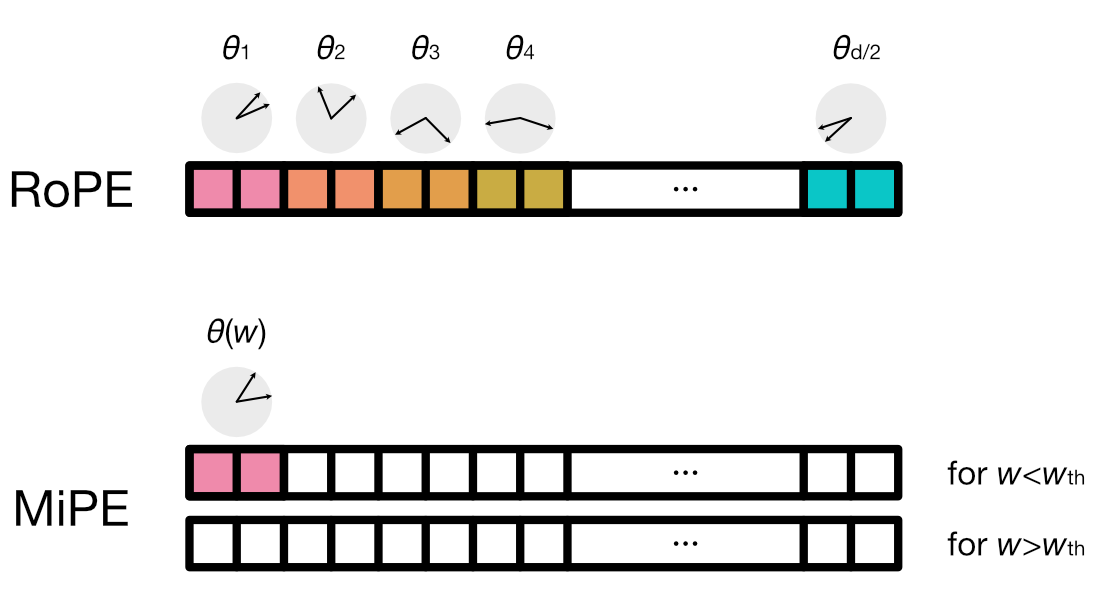
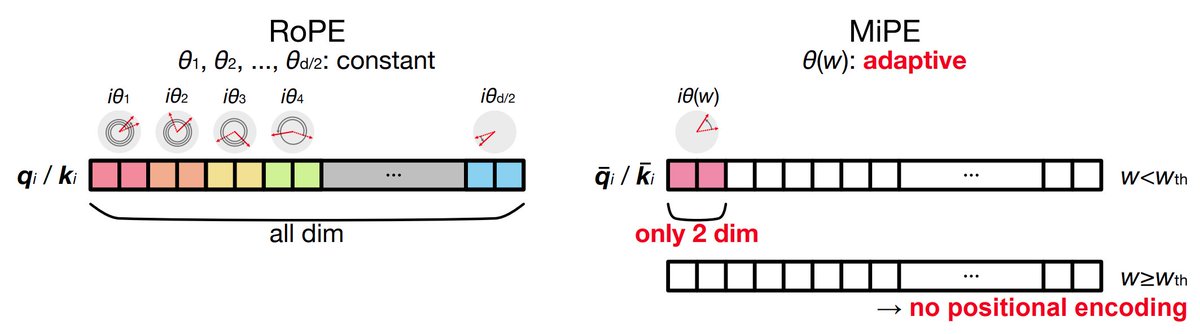
⑤位置情報の扱い(MiPE: Minimal positional encoding)
⚠️位置エンコーディング(RoPE)は、長文になるほど外挿が問題となる
MiPE(提案手法)では
🔸位置情報は「screening windowが狭いときだけ」使う
🔸queryとkeyの初めの2要素だけ使用
👉ミニマルで計算が軽い
👉長文でも外挿する必要がない
2
26
5,051
Apr 3
もし少しでも不備かもしれない点など発見された方は遠慮なくリプライ、DM、メールなどいただけると助かります…
DM解放してみました
メールアドレスは論文に記載しております
13
3,397