
working on AI services
Joined December 2021
- Tweets 6
- Following 1,101
- Followers 128
- Likes 1,077
2 Photos and videos
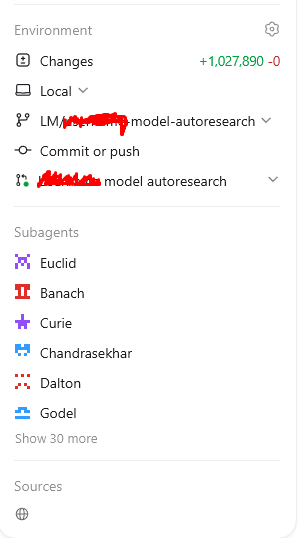

35 parallel agents, 24h autoresearch loop optimizing an NLP imbalanced class problem with 1.000.000 LOC PR
10 research agents scraping the internet: arXiv, GitHub, Kaggle, Medium, etc.. and saving findings to research.md.
10 implementation agents adapting research to the concrete domain problem, training models and running evals, logging to logs.md.
10 feedback agents performing full error analysis cycles and proposing next architecture iterations to feedback.md.
So far improved the existing production real-time SOTA model by 5 points
1
1
71
Very interesting idea to improve LLM-generated synthetic data quality "Autodata: an automatic data scientist to create high quality data" @AIatMeta
facebookresearch.github.io/R…
A lot of the techniques resonate directly with work I've implemented for HITL augmentation. The seed ratio and majority voting LLM numbers are exactly what I've used and are something I'd expect we can mine from the original data. The weak/strong verifier as a reward model is a particularly interesting idea where the weak verifier's goal is to fail and the strong verifier's goal is to succeed, and they measure the performance differential between the two. If that gap is small, the synthetic example isn't challenging enough to introduce meaningful diversity into the dataset
Currently running up to a 10x multiplier (5 LLM-generated and 5 from deterministic abbreviation strategies (character substitutions, adjacent swaps)). Implementing this type of dual-verifier evaluator would raise data quality further
1
2
3
108