
Better Artificial Intelligence for Everyone
Joined September 2020
- Tweets 825
- Following 149
- Followers 3,605
- Likes 653
128 Photos and videos

















Jun 9
The security world's "find it → patch it → disclose it" model doesn't work for AI.
You can't patch a released open-weight model. The weights are already out there — forever.
MLCommons is building the disclosure standard AI evaluation actually needs.
bit.ly/43t8R3t
155
Jun 2
AI systems co-design is too fragmented.
Enter MLCommons Chakra (#MLSys2026): an open execution trace ecosystem to bridge software & hardware without exposing IP.
Native in @PyTorch, NVIDIA NeMo, & vLLM. bit.ly/4vkYZEP
1
1
152
Jun 1
Meet GeoCroissant.
Built on MLCommons Croissant, it adds Earth observation-specific metadata—from coordinate systems to spatial resolution—to give you better traceability and more reproducible workflows for agentic AI pipelines.
bit.ly/3PTLywz
119
May 19
Introducing the 2026 @MLCommons Rising Stars! 🌟
We’ve selected 39 outstanding early-career researchers from 26 global institutions who are shaping the future of ML systems, hardware-software co-design, and trustworthy AI.
Meet the cohort: bit.ly/3Ru3ONl
#AI #MLCommons
1
1
2
1,472
May 19
The median AI benchmark longevity score is 5/100.
AILuminate scored 75—but even that degrades over time. To fix this, the @MLCommons AIRR team built the Continuous Prompt Stewardship System to keep risk evaluation fresh and reliable.
bit.ly/3On4jrz
1
139
May 18
What does AI reliability actually require? It comes down to consistently following the right behavioral rules—even under adversarial attack.
Meet the AI Reliability Map to guide pre-deployment testing.
Explore the framework: bit.ly/4mG7erO
#AIReliability #AI
124
May 14
Do tools like OpenClaw signal a turning point for mainstream AI adoption? MLCommons' Dave Graham debated that and more on the Utilizing AI podcast. What do you think? bit.ly/4uJj4Va #AgenticAI #AI
1
135
May 14
MLPerf Training v6.0 has added GPT-OSS 20B. With 21B total parameters (but only 3.6B active per token), this new sparse MoE pretraining benchmark is designed specifically for accessibility—it can run on a single 8-GPU node.
bit.ly/4noRr14
1
3
181
May 13
Mixture-of-Experts (MoE) architectures like DeepSeek-V3 are the new standard for scaling frontier LLMs. Now, that architecture is part of MLPerf Training v6.0.
bit.ly/3QSteEj
1
1,679
May 13
AI Risk and Reliability certification shouldn't be a self-assessment.
That's the premise behind the AILuminate Global Assurance Program (GAP). GAP gives organizations an independent path to certify that their AI systems meet established safety standards.
bit.ly/4kIS18x
101
May 13
MLPerf Endpoints: decoupled client, any endpoint, zero-effort integration. Cloud or bare-metal — evaluated equally. Built for API-first GenAI.
bit.ly/3Pjx34u
#MLPerf
80
May 12
Great to see Microsoft highlighting the need for global collaboration on AI safety testing—and shouting out the MLCommons community’s ongoing work to expand the AILuminate benchmarks for multilingual and multimodal testing.
bit.ly/3RdYFZG
104
May 12
The New Wave of AI in Healthcare 2026 symposium kicks off today in NYC!
5/13 at 10:50 AM, MLCommons' Andrew Gruen, PhD will be taking the stage.
If you're attending, don't miss this conversation on trust, accountability, and AI validation in medicine.
lnkd.in/efz2t-Ja
1
1
123
May 12
AI software optimization is now moving faster than hardware cycles. To capture these rapid gains, MLPerf is shifting to a rolling submission cadence.
David Kanter explains why this speed matters for enterprise buyers via Nutanix: bit.ly/3R24FVt
#MLPerf #AI
113
May 11
Submissions for MLPerf Training v6.0 are open!
This round brings updates, including the introduction of large-scale MoE pretraining architectures. Benchmarking on a single 8-GPU node or massive cluster, we want your results in this round.
bit.ly/4uG3vNS
174
May 11
We're thrilled to welcome @flwrlabs to MLCommons to help shape standards for federated AI at scale.
First up: MedPerf is integrating with Flower, enabling researchers to run federated clinical AI studies without moving sensitive patient data.
More: bit.ly/4nt1x0T
1
1
120
May 8
Measuring today’s production workloads is getting harder. The Inference working group stepped up by adding GPT-OSS 120B, DeepSeek-R1, and our first text-to-video generation benchmark.
mlcommons.org/2026/04/mlperf…
158
May 7
MoE benchmarking doesn't require a supercomputer.
MLPerf Training v6.0 introduces GPT-OSS 20B: a sparse Mixture-of-Experts pretraining benchmark that can run on a single 8-GPU node.
See how the task force engineered away statistical variance (CV < 5%): bit.ly/3QLwvVU
3
6
728
May 5
Mixture-of-Experts (MoE) is coming to MLPerf Training v6.0.
The new DeepSeek-V3 large-scale pretraining benchmark captures critical innovations like MLA, fine-grained expert segmentation, and MTP at production scale (671B parameters).
Technical details: bit.ly/49bRabO
2
6
591
Apr 30
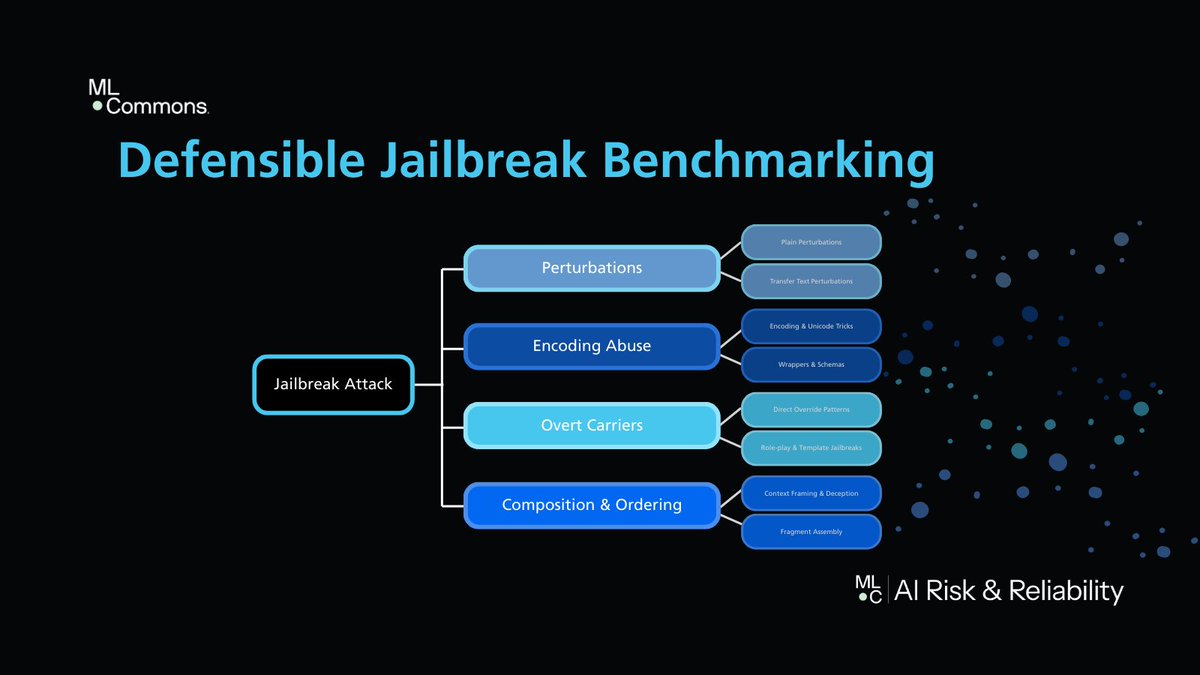
Security theater vs. rigorous AI benchmarking - the difference is methodology. AILuminate Jailbreak v0.7: a mechanism-first taxonomy for single-turn jailbreak attacks. Defensible. Reproducible. Auditable.
mlcommons.org/2026/02/jailbr…
#AILuminate #AISecurity
154