
US AI curbs show need for India’s sovereign AI: Tejasvi Surya yespunjab.com/?p=265931
#TejasviSurya #SovereignAI #ArtificialIntelligence #IndiaAI #AIInnovation #TechPolicy #AISecurity #DigitalIndia #AIModels #Anthropic #DataSecurity #AtmanirbharBharat #Technology #Bengaluru #AIFuture
@Tejasvi_Surya
1
8

Crypto’s next billion-dollar hacker may move at superhuman speed
AI vs. DeFi: is the next $1B hack coming faster than humans can react?
New Claude Fable 5/Mythos 5 tools can spot bugs at scale—raising fears of AI-accelerated exploits after $840M in recent losses. #DeFi #AIsecurity

1
1
1
74

Why @adam_networks Philippe Johnston hire could matter as AI ransomware gets faster business-news-today.com/why-… Find out how ADAMnetworks’ Philippe Johnston hire could reshape AI ransomware defence, Zero Trust adoption and public-sector cyber trust across enterprises. #ADAMnetworks #ZeroTrust #AIsecurity #Ransomware #SASE #CanadaTech #GovTech #CIOAssociationOfCanada #EnterpriseSecurity #CyberResilience
7

One thing I can't quite wrap my head around the @AnthropicAI Fable 5 / Mythos 5 shutdown.
Most jailbreaks can typically be mitigated fairly quickly once the underlying technique or pattern is understood. This is standard practice across frontier AI labs. Researchers report a jailbreak, the lab analyzes the technique, implements a mitigation (even if temporary), and then works on a more robust fix. Most major AI companies have dedicated teams, tooling, and well-established processes for handling exactly this type of issue.
So when @awscloud researchers surfaced a jailbreak, the obvious question is: why not patch it, even as a temporary, defense-in-depth, compensating control kind of fix, and move on, while a longer-term solution was being developed?
And if the issue was serious enough that AWS leadership ultimately felt compelled to raise concerns with the U.S. Federal Government, what happened before that point?
From the outside, it appears less like a technical challenge and more like a breakdown in vulnerability disclosure and remediation coordination. Both sides disagree on whether there was anything to patch. Anthropic says the technique surfaced previously known, minor issues, was reproducible on other public models, and did not point to a flaw in Fable 5's safety systems. In cybersecurity, the expectation is usually that researchers and vendors work together to understand the issue, validate the findings, and deploy fixes before matters escalate.
What makes this different from a normal disclosure is the escalation path. This did not run through coordinated disclosure. A major investor (@amazon is a major investor in Anthropic) reportedly took it directly to @USTreasury , and the model came down through export controls rather than a patch cycle.
I'm curious whether others see this as primarily a technical issue, a process issue, a trust issue, or something else entirely.
#AISecurity #AISafety #Anthropic #ClaudeAI #CyberSecurity #VulnerabilityDisclosure #AIGovernance #ResponsibleAI #ModelSecurity #TrustAndSafety #CISO #AIPolicy
45
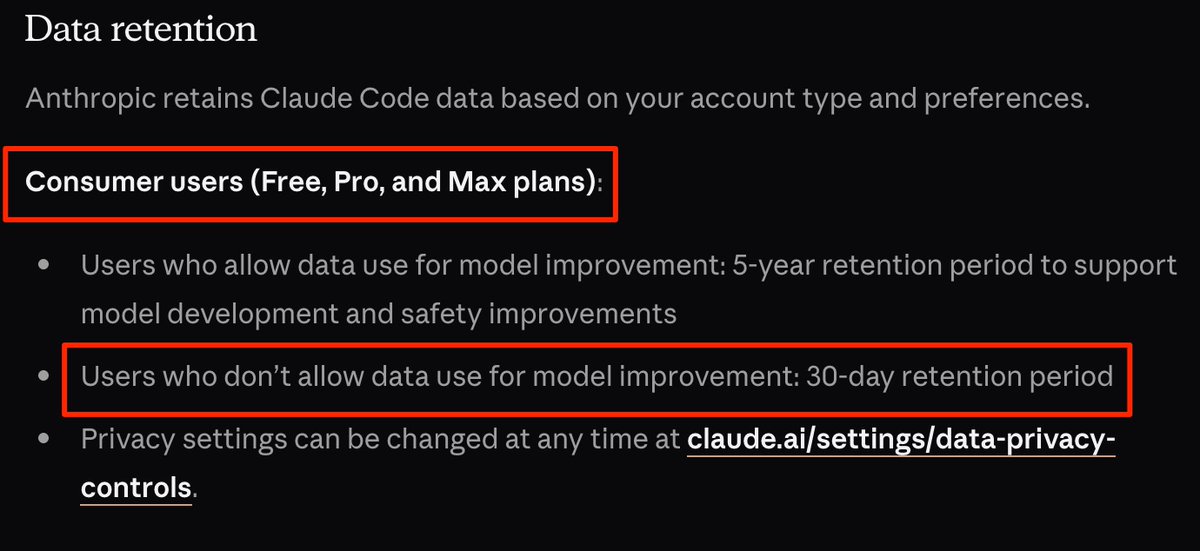
Most people assume that turning OFF training means their AI conversations aren't retained.
That's not true.
For consumer users of @AnthropicAI Claude (Free, Pro, and Max plans), conversations may still be retained for up to 30 days - even when you opt out of having your data used for model improvement.
Let that sink in.
Many users confuse: Model training, Data retention, Data deletion
They are not the same thing.
This is just one of many interesting facts I uncovered while researching the latest Anthropic Claude ecosystem.
If you would like to know more, join us for this session:
🎭 Anthropic Claude Fable 5 & Claude Mythos 5 – A Real Primer For All
📅 Monday, June 15, 2026
⏰ PM – PM PDT
🔗 Registration link - luma.com/tejas-e4j3
#Anthropic #ClaudeAI #AISecurity #Privacy #CyberSecurity #GenAI #AIGovernance #CISO #ArtificialIntelligence #DataPrivacy
67

Three ways your AI agent is leaking secrets right now:
1. Keys sitting in environment variables
2. Full API tokens passed into tool calls
3. Prompts and responses logged in plain text
Fixable, all three. We walk through it in the TG 👇
1claw.xyz/telegram
#AIsecurity #SecretsManagement
1
1
9
204

10h
80.9% of technical teams have AI agents in active testing or production.
Only 14.4% got full security and IT approval before going live.
That gap is not a compliance lag. It is a structural risk that every enterprise security committee is about to start asking about.
The teams that moved fast without the approval layer are not ahead. They are one audit notice away from a hold.
cyphrex.io
#AIAgents #AISecurity
2
54

اثنان من أقوى نماذج الذكاء الاصناعي العالمية تم حظرها اليوم بعد تحذيرات أمازون!
خبر صادم انتشر اليوم عن نماذج Claude Fable 5 و Mythos 5 من شركة Anthropic، اللي كانت من المفترض إنها قمة في الأمان. الموضوع بدأ لما الرئيس التنفيذي لأمازون، آندي جاسي، أثار مخاوف كبيرة. اكتشف باحثو أمازون أنهم يقدرون "يكسرون حماية" نموذج Fable 5 بسهولة، يعني يجبرونه يعطي معلومات حساسة ومضرة ممكن تستخدم في هجمات إلكترونية. يا ساتر!
التقرير يقول إن هذا "الاختراق" أو الـ "jailbreak" كان خطيرًا لدرجة إن الحكومة الأمريكية تدخلت. بعد ما رفض الرئيس التنفيذي لـ Anthropic، داريو أمودي، يصلح المشكلة أو يسحب النماذج، الحكومة حظرت تصدير النموذجين Fable 5 و Mythos 5 بالكامل. تخيل، نموذج ذكاء اصطناعي يُصنف كخطر على الأمن القومي!
هذا كله حصل يوم الجمعة، يعني أمس، وبعدها شركة Anthropic قطعت الوصول العالمي لهذين النموذجين. بصراحة، هالخبر يخليني أتساءل: هل كنا نثق في قدرة الشركات على تأمين نماذجها أكثر من اللازم؟ وهل حان الوقت لتدخل حكومي أقوى لضمان سلامة هذه التقنيات قبل ما تنتشر مخاطرها؟
رأيي الشخصي، إنها سابقة خطيرة جدًا. لم أتصور يومًا أننا سنرى حظرًا حكوميًا مباشرًا على نماذج AI بهذا الشكل. هذا يوضح أن التحدي الأمني مع الذكاء الاصطناعي أكبر مما نتصور، وأن السباق نحو الابتكار يجب ألا يتجاوز حدود الأمان والأخلاق. يجب على المطورين تحمل مسؤولية أكبر بكثير.
في النهاية، هل تعتقد أن التدخل الحكومي كان ضروريًا أم أنه يقتل الابتكار؟
#أمن_الذكاء_الاصطناعي #AIsecurity
1
133

11h
Claude Fable 5 reportedly went through 1,000 hours of red teaming before launch.
And still, within 48 hours of being public, someone claimed they found a way around its safeguards.
That should make every security leader pause.
Not because one model had an issue. That will happen.
The bigger concern is how the attack worked.
This was not just one clever jailbreak prompt.
It was closer to a “pack hunt.”
Multiple agents broke a risky request into smaller, harmless-looking pieces. Each piece looked safe on its own. The danger only appeared when the pieces were stitched back together.
That is the part enterprises need to understand.
Most AI guardrails still look at one prompt, one session, one user, or one model at a time.
But attackers are already thinking across sessions, across models, and across agents.
So the question is no longer:
“Did the model refuse the bad prompt?”
The better question is:
“Can we see the full chain of intent?”
This is why AI security needs to move beyond simple prompt filtering.
Enterprises need real guardrails around the entire AI workflow:
Input checks.
Output checks.
Data leakage controls.
Prompt injection protection.
Agent behavior monitoring.
Cross-session visibility.
Policy enforcement across the full AI pipeline.
That is also why solutions like Lakera AI, now part of @CheckPointSW are becoming so important.
Safe AI adoption is not about slowing teams down.
It is about making sure AI can be used with confidence, without leaking sensitive data, violating policy, or letting harmful outputs slip through because each individual step looked harmless.
AI is powerful.
But before we hand it to every employee, customer, application, and autonomous agent, we need to harness it properly.
Single-prompt security is not enough anymore.
The future is full-pipeline AI security.
#AISecurity #CISO #Cybersecurity #GenAI #AgenticAI #LLMSecurity #CheckPoint #Lakera #AITrust
1
74

🚀 Day 3/30
Completed a Prompt Engineering module.
Key takeaways:
🔹 LLM Fundamentals
🔹 Prompt Structure
🔹 System vs User Prompts
🔹 Advanced Prompting
🔹 AI Security Testing
Learning how prompts shape AI behavior and security. 🔐
#AISecurity #PromptEngineering #CyberSecurity

16

To safeguard RAG pipelines from injection attacks, validate and sanitize all input data, implement strict access controls, and monitor for anomalies. Stay vigilant against threats to your AI infrastructure. #AIsecurity
1

Meet Ayesha Dissanayaka - Associate Director & Architect at WSO2, working on Identity & Access Management, Agent Identity, and security for the next generation of AI systems.
After connecting at MCP Developers Summit Bengaluru, I invited Ayesha to share her insights on one of the most important yet least discussed areas of AI today: Agent Security.
In this conversation, we explore:
• Why AI agents create new security challenges
• How authorization works when no human is sitting behind a browser
• The importance of Agent Identity
• What CIBA is and why it matters
• Practical lessons for developers and architects building AI agents
A thoughtful discussion for anyone interested in AI, security, identity, and the future of agentic systems.
Full episode on YouTube:
Meet Ayesha Dissanayaka - Associate Director & Architect at WSO2, working on Identity & Access Management, Agent Identity, and security for the next generation of AI systems.
After connecting at MCP Developers Summit Bengaluru, I invited Ayesha to share her insights on one of the most important yet least discussed areas of AI today: Agent Security.
In this conversation, we explore:
• Why AI agents create new security challenges
• How authorization works when no human is sitting behind a browser
• The importance of Agent Identity
• What CIBA is and why it matters
• Practical lessons for developers and architects building AI agents
A thoughtful discussion for anyone interested in AI, security, identity, and the future of agentic systems.
Full episode on YouTube:
youtu.be/gVzPSG5R0DQ
#AIAgents #AISecurity #AgenticAI #IAM #IdentityManagement #MCP #ArtificialIntelligence #CyberSecurity #WSO2

1
10

In the fast-evolving landscape of AI, securing the right digital identity isn't just a technical necessity—it’s market authority.
A clean, direct .com instantly builds enterprise trust, eliminates client friction, and locks down your brand equity. In tech and cybersecurity, simplicity scales.
💡 Strategic Opportunity: For enterprises or rapidly growing startups looking to capture and dominate the AI security space, the premium corporate asset AISecureHub.com is currently available for acquisition.
🔒 Secure Purchase: The domain is officially listed and ready for a secure transfer directly on GoDaddy.
Interested parties or corporate development leads can reach out via DM or purchase directly on GoDaddy.
#AISecurity #Cybersecurity #DomainNames #TechStrategy #SaaS

1
18

OWASP's 2026 State of Agentic AI Security: prompt injection still the leading cause of production failures. Coding agents are now the top attack surface. If you're shipping AI agents, this is required reading. helpnetsecurity.com/2026/06/… #AISecurity
1
20
14h
40 CVEs filed against MCP implementations in 120 days.
One vulnerability every four days throughout 2026.
Python SDK. TypeScript SDK. Java. Rust. The entire protocol stack is under active research and active attack simultaneously.
492 MCP servers are exposed to the internet with zero authentication right now. 833 vulnerable servers identified across 67,000 analyzed.
MCP became critical enterprise infrastructure before anyone built the security layer for it. The NSA noticed. The attackers noticed first.
Every agent fleet touching MCP needs verified identity, enforced scope, and a signed record of every tool call. Not after the CVE lands. Before.
cyphrex.io
#AIAgents #AISecurity #llmagents
39

14h
(Claude Fable 5 & Mythos 5) These AIs can autonomously find & exploit hidden software vulnerabilities turning one team into a super cyber force.
For India: Imagine Pakistan getting this. In hours, their AI could discover zero-days ( bugs) in our power grids, railways & banks, then launch disruptive attacks during a crisis.
Smart move by US to keep such dual-use tools out of adversary hands.
India should strongly support targeted AI export controls & accelerate our own sovereign AI (like Sarvam).
National security first. #AISecurity #IndiaUS #Anthropic #Fable
#Mythos
@narendramodi
@AshwiniVaishnaw
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
115

80% of AI agent code has security vulnerabilities. Your agent is running naked.
A CMU paper just dropped the number everyone in the agent space needed to hear but didn't want to: SWE-Agent running Claude 4 Sonnet passed functional tests 61% of the time. Only 10.5% of its solutions were actually secure.
Let that sink in. The code works. It just leaves the door wide open.
Here's why this matters more than another benchmark: AI agents aren't chatbots anymore. They execute code. They call APIs. They read and write your filesystem. They have your credentials. Every security blind spot in their output becomes a real attack surface on your machine.
The researchers tried three different fixes. Security prompts in the system message. Explicit vulnerability instructions. Structured guardrails.
None of them worked.
The fundamental problem: agents are optimized to pass tests, not to write secure code. The entire evaluation framework rewards functionality and ignores security. When your metric is "does it work?" — of course it works. It just also happens to have SQL injection, hardcoded secrets, and unchecked inputs baked in.
This hits even harder today because Anthropic just suspended Claude Fable 5 under a US government directive. The message is clear: frontier labs are entering an era where safety and control aren't optional features — they're existential requirements. And yet the code their models generate? Still 89.5% insecure.
The gap between "AI can build anything" and "AI can build anything safely" is the defining risk of the agent era. We're giving increasingly powerful systems increasingly powerful tools — and we haven't solved the most basic security layer.
If you're building with AI agents right now: are you reviewing what they produce, or just hoping it works?
#AISecurity

71

How the Fable 5 jailbreak happened, and how AEVRIS stops it.
Here's exactly what Anthropic described:
An attacker asked Fable 5 to read a specific codebase and fix any software flaws. That phrasing was enough to bypass safeguards and elicit cybersecurity analysis the model was built to block.
No exploit. No zero-day. A prompt.
Here's the AEVRIS interception flow:
① User sends the crafted prompt
② /v1/scan runs in under 5ms — Stage 1 regex detects known jailbreak patterns including instruction override and capability elicitation, or escalates to Stage 2/3 AI classifiers for behavioral analysis
③ VERDICT: BLOCK returned before the prompt ever reaches Fable 5
④ Audit record generated: request hash policy ID credential class retention flag
⑤ Anthropic gets an alert. Government gets an audit trail. Model never sees the payload.
The model cannot defend itself against natural language. That's not a bug in Fable, that's the architecture of every LLM in existence.
The security layer has to be deterministic and sit outside the model entirely. Stage 1 AEVRIS is regex. You can't social engineer a regex.
This is Patent Claim #1.
aevris.ai/compare
@AnthropicAI @OpenAI @Google @Meta @MicrosoftAI @CISA @NISTcyber @NSA @CommerceGov @DeptOfDefense @ycombinator @TechCrunch @wired @WSJ @Forbes @TheHackersNews @BleepingComputer @CNBC @axios @simonw @theo
#AISecurity #AgenticAI #Fable5 #PromptInjection #AEVRIS
1
1
92
A jailbreak just caused the US government to pull the most advanced publicly available AI model in history.
Not a data breach. Not a hack. A jailbreak.
AnthropicAI complied within hours. Hundreds of millions of users lost access to Fable 5 by Friday night.
This is exactly what deterministic security infrastructure exists to prevent. The jailbreak happened at the model layer, which is the layer the model cannot defend itself.
The security layer has to sit outside the model. That's not a product pitch. If you use AI, you need Aevris.
aevris.ai/compare
@Anthropic @OpenAI @Google @Meta @MicrosoftAI @CISA @NSA @NISTcyber #AISecurity #AgenticAI #AEVRIS
1
31
BREAKING: The US government just forced Anthropic to pull Claude Fable 5 and Mythos 5 for every user worldwide.
The reason: a jailbreak.
The directive arrived at 5:21pm ET. Access was cut off within hours.
AnthropicAI disagreed with the directive but complied. Their statement: the jailbreak was "narrow" and "non-universal", and involves capabilities already available in GPT-5.5.
Here's what matters for every team deploying AI:
A jailbreak just shut down the world's most capable public AI model. Not a zero-day. Not a network breach. A prompt.
This is the attack surface nobody has infrastructure for:
— Input injection gets past the model
— Model compliance looks normal
— No audit trail
— No interception layer
— Government steps in
The security layer cannot live inside the model. The model is the vulnerability.
AEVRIS sits outside every model. Intercepts every prompt. Verifies every response. Logs every tool call with a tamper-proof audit record.
This is why it exists. If you use AI, you need Aevris.
aevris.ai
@Anthropic @OpenAI @Google @Meta @MicrosoftAI @CISA @NSA @NISTcyber #AISecurity #AgenticAI #Fable5 #AEVRIS
1
93