
Research in NLP @illuintech, CS MSc @epfl
Joined September 2024
- Tweets 34
- Following 94
- Followers 47
- Likes 124
6 Photos and videos


Max Conti retweeted

May 19
if you write some really good code these days everyone thinks you did it with Claude Code. if you lose a lot of weight everyone thinks you did it with Ozempic. at least you can still be really good at dancing. they don't make ozempic or Claude Code for being good at dancing
40
60
1,390
30,673
Max Conti retweeted

May 18
okay maybe it's a good time? We have a small colbert model trained at pplx, it is a continue-training of pplx-embed-0.6b, so native multilingual, just made it open and added a section how to use MaxSim kernel:
huggingface.co/perplexity-ai…
May 18

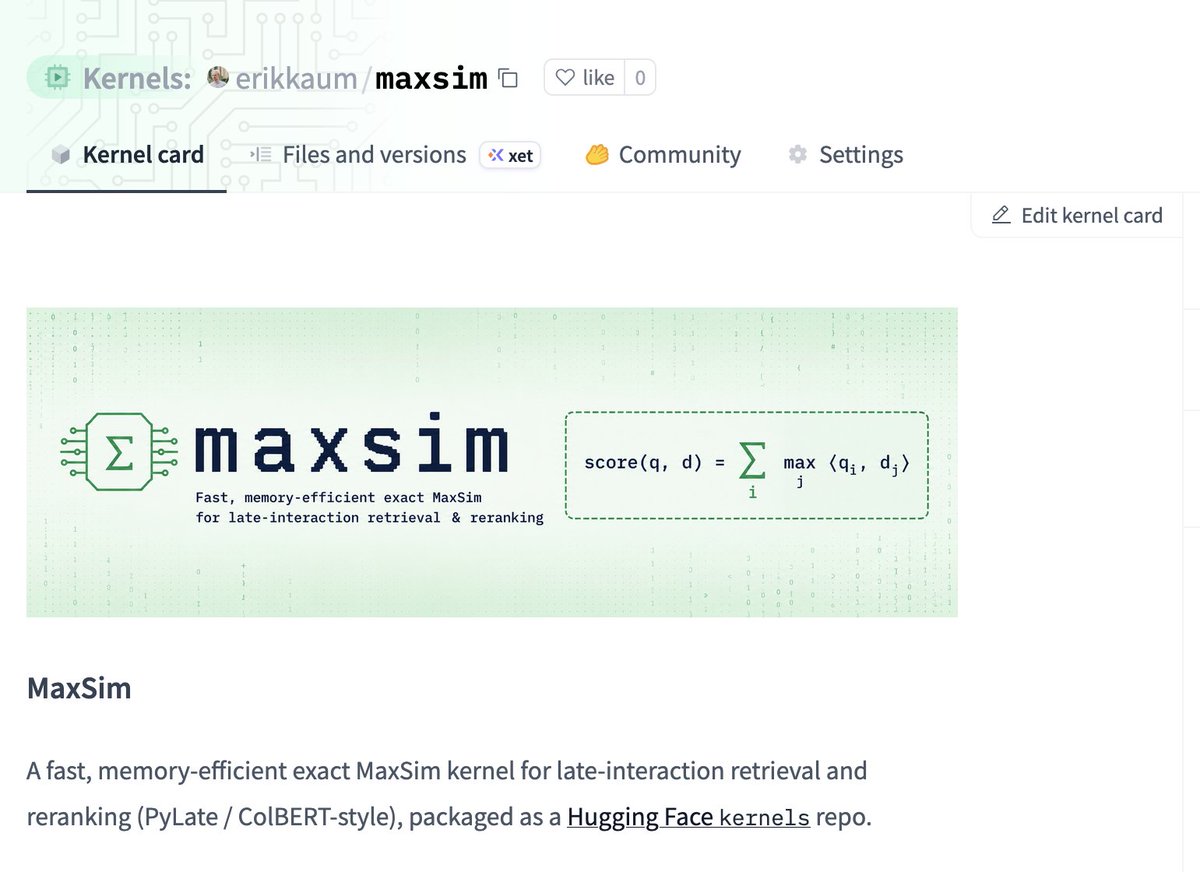
Releasing my first kernel on @huggingface:
MaxSim
Late-interaction retrieval (ColBERT / PyLate) bottlenecks on materializing the full similarity matrix. This kernel avoids it by using tiled scoring with simdgroup_matrix (Metal) and WMMA.
Result is 3–5× speedup compared to naive PyTorch.
Try it out 👇
7
18
100
24,244

Exciting publication alert!! Congrats to the whole team for the nice ideas and thorough execution 🎯
Hyped to take the time to deep-dive into every part :)
May 15

🚨 Do LLMs need to store everything they read in memory?
To reduce KV cache size and improve decoding speeds, we propose Self-Pruned KV attention, a mechanism where the model learns to decide which KVs to write in the persistent KV cache, discarding all the rest! @AIatMeta🧵

2
58
Max Conti retweeted

Apr 21
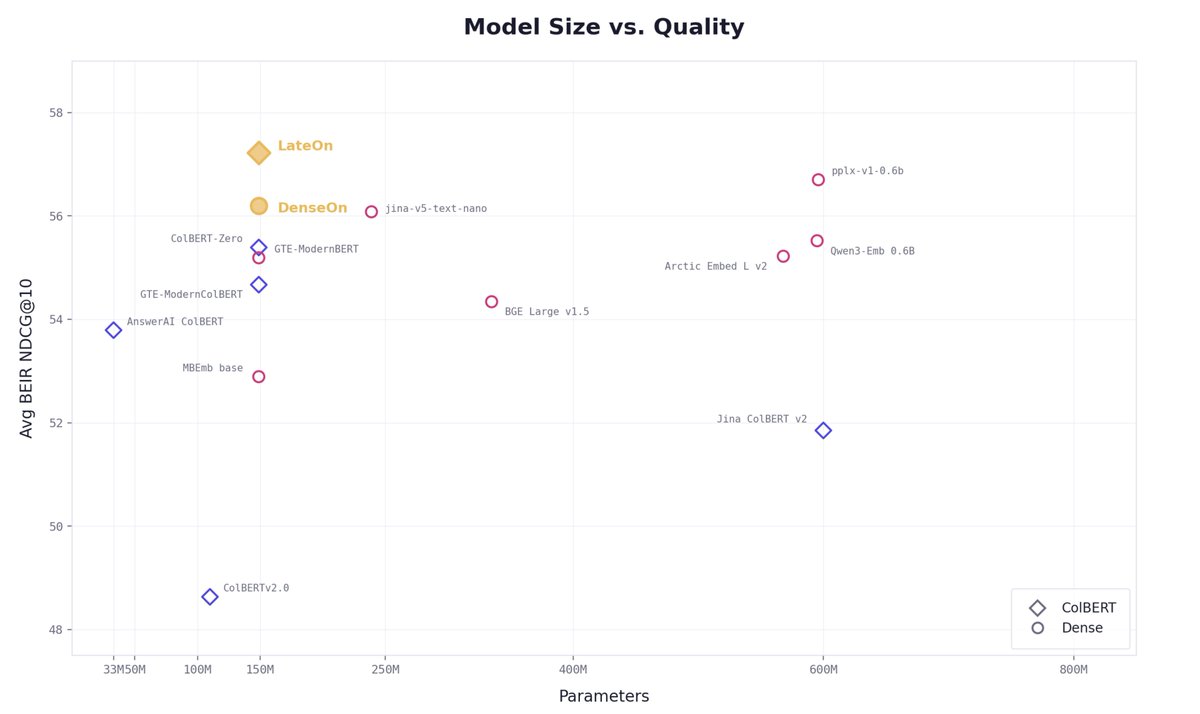
We're releasing LateOn and DenseOn today. Two open retrieval models, 149M parameters each.
LateOn (ColBERT, multi-vector): 57.22 NDCG@10 on BEIR.
DenseOn (dense, single-vector): 56.20.
Both beat models up to 4× larger
We're open-sourcing the weights under Apache 2.0 🧵👇
2
27
169
9,924
Max Conti retweeted

Apr 21
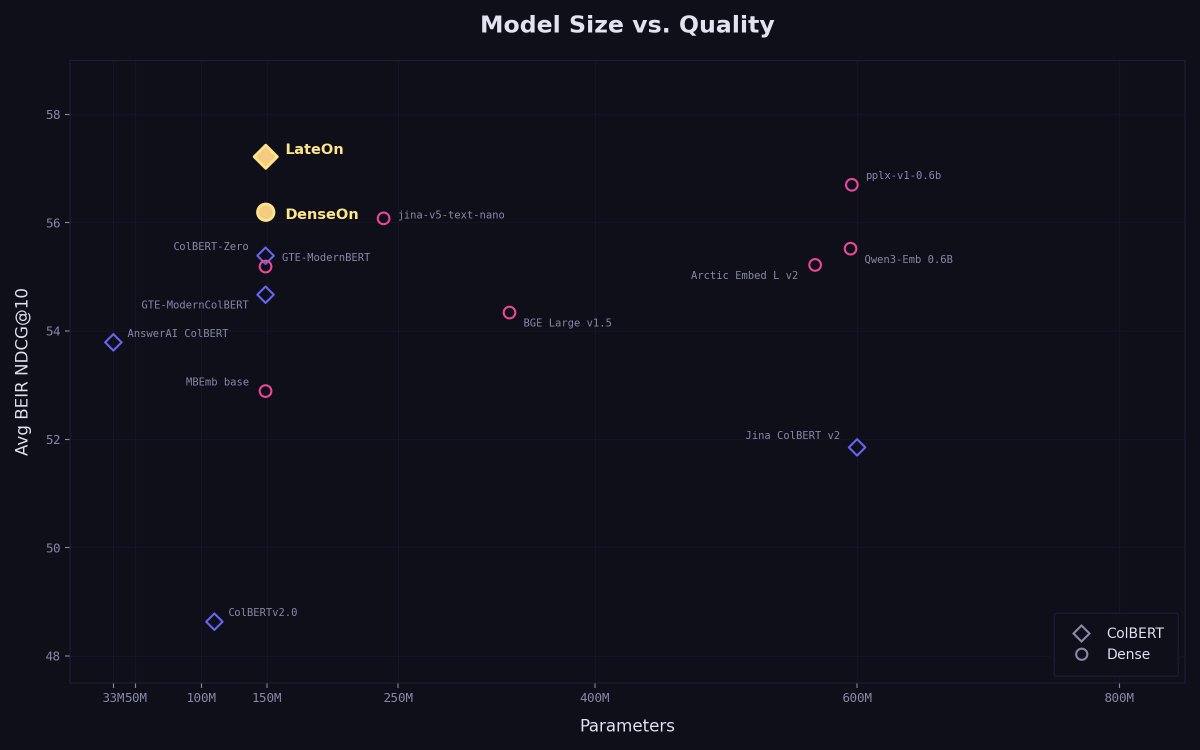
The new generation of open state-of-the-art single and multi-vector retrieval models is here
It's time, DenseOn with the LateOn 🎶
@LightOnIO releases models that leap past existing ones, and everything you need to do the same!
13
52
224
39,928
Max Conti retweeted

Apr 3
Update on the Late-Interaction Workshop @ ECIR2026: it was amazing! 🇳🇱
So cool to meet late-interactors IRL for the first time, I enjoyed every bit of that day 🤗 And congrats & huge thanks to the organizers again.
Link to our work poster below ⬇️



3
8
35
3,096
Looking forward to meeting fellow late interactors! 🤓🇳🇱
Mar 30

@mlpc123, @MaceQuent1 and I will be at the Late Interaction Workshop at #ECIR2026 on Thursday 🤗 See you in Delft 🇳🇱
1
53
Max Conti retweeted

Mar 3
Great work from @weaviate_io that compares the performances of text retrievers and multimodal ones.
It appears that their errors are complementary, which makes their combination in hybrid search promising.
Check their paper!
arxiv.org/pdf/2602.17687
Feb 27

Most teams build RAG systems that only see text.
But a lot of queries 𝘳𝘦𝘲𝘶𝘪𝘳𝘦 visual understanding to answer correctly.
Most RAG systems treat PDFs the same way: OCR the text, chunk it, embed it, done. But that approach misses 𝗳𝗶𝗴𝘂𝗿𝗲𝘀, 𝘁𝗮𝗯𝗹𝗲𝘀, 𝘀𝗽𝗮𝘁𝗶𝗮𝗹 𝗹𝗮𝘆𝗼𝘂𝘁, 𝗮𝗻𝗱 𝘃𝗶𝘀𝘂𝗮𝗹 𝗿𝗲𝗹𝗮𝘁𝗶𝗼𝗻𝘀𝗵𝗶𝗽𝘀 that are a core part of the data.
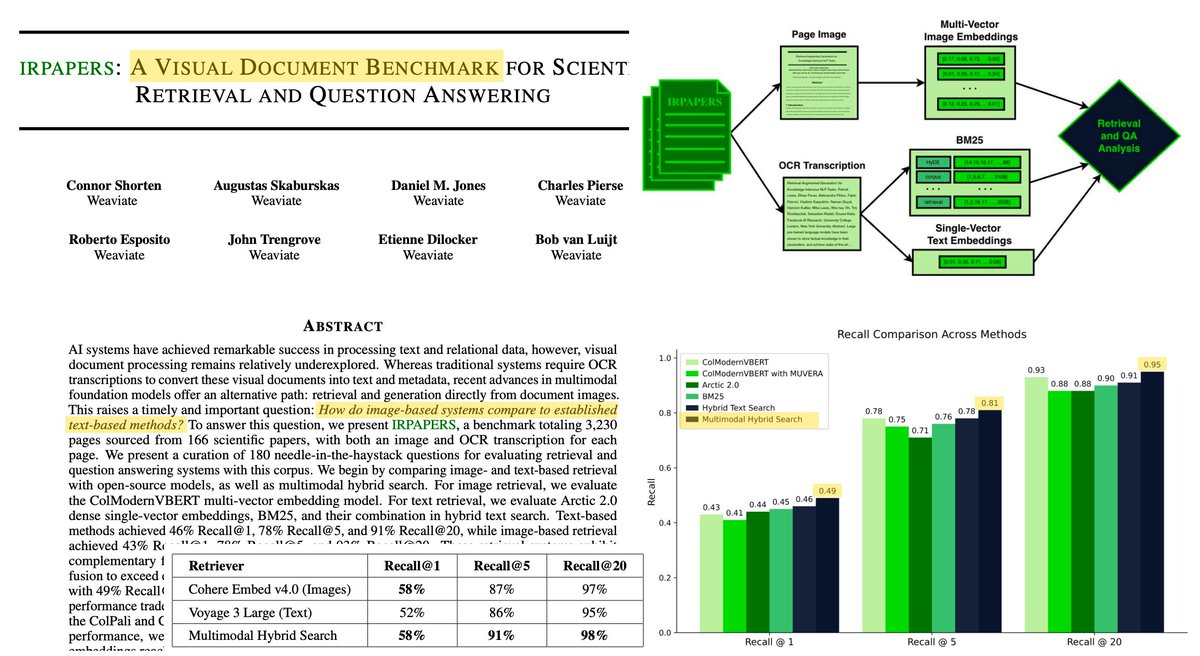
My colleagues at @weaviate_io just published IRPAPERS, a benchmark that directly compares text-based vs. image-based retrieval over 3,230 pages from 166 scientific papers.
The setup is straightforward: take the same PDFs and process them two ways. For text-based retrieval, run OCR with GPT-4.1, then embed with Arctic 2.0 BM25 hybrid search. For image-based retrieval, embed the raw page images with ColModernVBERT multi-vector embeddings. Then test both on 180 needle-in-haystack questions targeting specific methodological details.
Text-based retrieval edges out images at the top rank (46% vs 43% Recall@1), but images match or exceed text at deeper recall levels (93% vs 91% Recall@20).
But these two approaches fail on 𝘥𝘪𝘧𝘧𝘦𝘳𝘦𝘯𝘵 𝘲𝘶𝘦𝘳𝘪𝘦𝘴.
At Recall@1:
• 22 queries succeed with text but fail with images
• 18 queries succeed with images but fail with text
This complementarity is what makes 𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗛𝘆𝗯𝗿𝗶𝗱 𝗦𝗲𝗮𝗿𝗰𝗵 so effective. By fusing scores from both text and image retrieval, they achieved 49% Recall@1 and 95% Recall@20 - beating either modality alone.
𝗧𝗵𝗶𝘀 𝗶𝘀𝗻'𝘁 𝗮 𝘀𝗶𝗺𝗽𝗹𝗲 "𝗶𝗺𝗮𝗴𝗲𝘀 𝘃𝘀 𝘁𝗲𝘅𝘁" 𝘀𝘁𝗼𝗿𝘆. Text-based retrieval provides stronger precision and works for most content. But image-based retrieval can use visual structure and handle abstract visualizations way better. This is why once again (multimodal) hybrid search beats out either option alone - getting you the best of both worlds.
The most promising direction seems like it might be agentic systems that dynamically weight text vs image signals based on query characteristics, to emphasize image retrieval when more visually grounded information is needed, and text when you need keyword precision.
Paper: 𝗮𝗿𝘅𝗶𝘃.𝗼𝗿𝗴/𝗮𝗯𝘀/𝟮𝟲𝟬𝟮.𝟭𝟳𝟲𝟴𝟳
1
4
9
1,316
Max Conti retweeted
Feb 27
Love this from @weaviate_io!
Feb 26

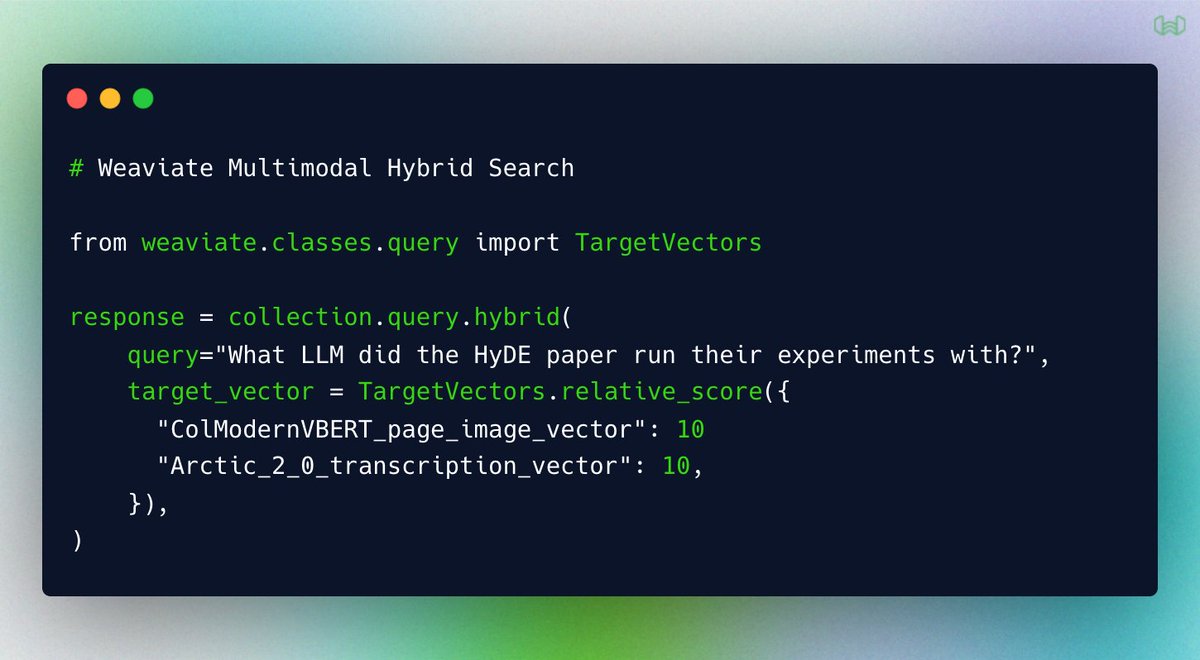
Multimodal Hybrid Search is one line of code in Weaviate (in the code golf sense⛳️)
Search with ColModernVBERT page image vectors, Arctic 2.0 text transcription vectors, and BM25!
This is an especially interesting case of a multimodal, multimodel 😆 future of search. Derive embeddings from images AND text (with two different models), and combine their retrieval scores. 🧬
What makes this possible at depth is that Weaviate's Named Vectors give you a lot of control over the underlying storage engine. In a naive case, you could have two HNSW indexes in-memory, with your metadata and inverted indexes handled with LSM buckets. 🏗️
Add MUVERA encoding with ColModernVBERT and Weaviate will now add an HNSW index with the FDE vectors in memory, and the full precision multi-vectors in an LSM bucket. 🪣
One object, one query. As many retrieval scores as you want 👇
1
5
13
1,849
Max Conti retweeted

Feb 14
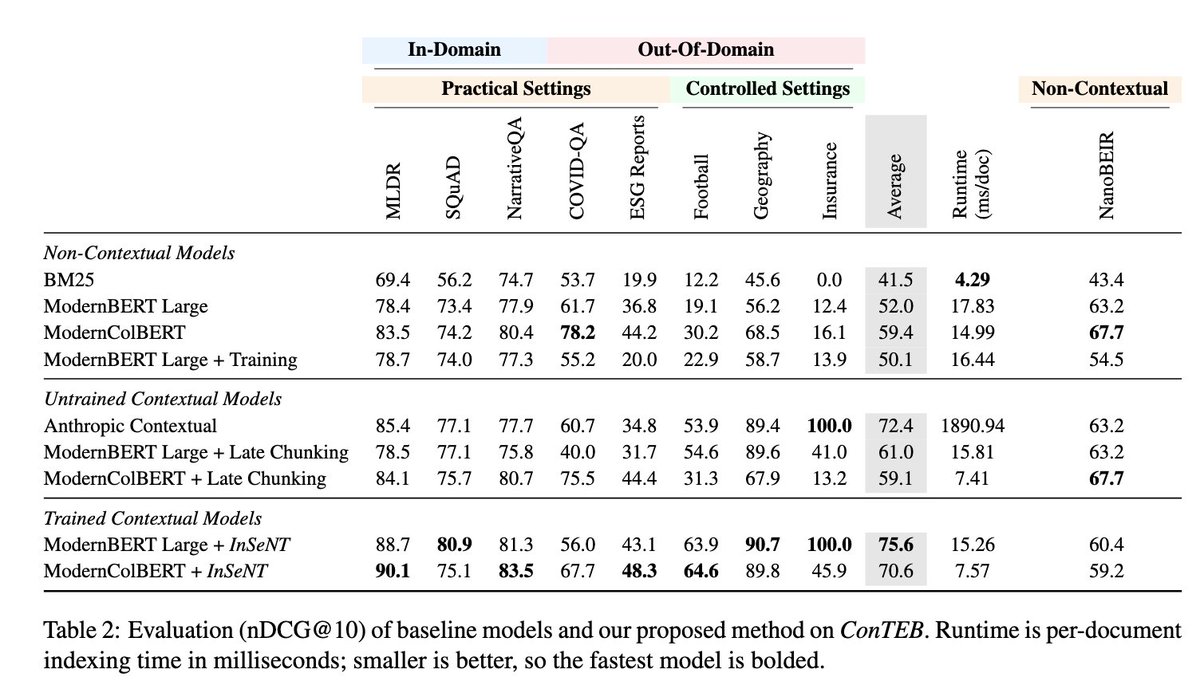
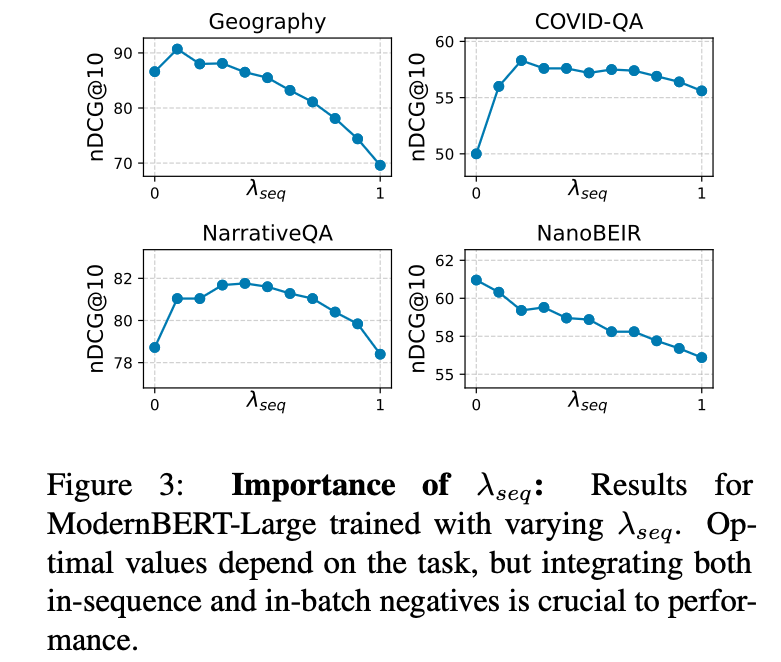
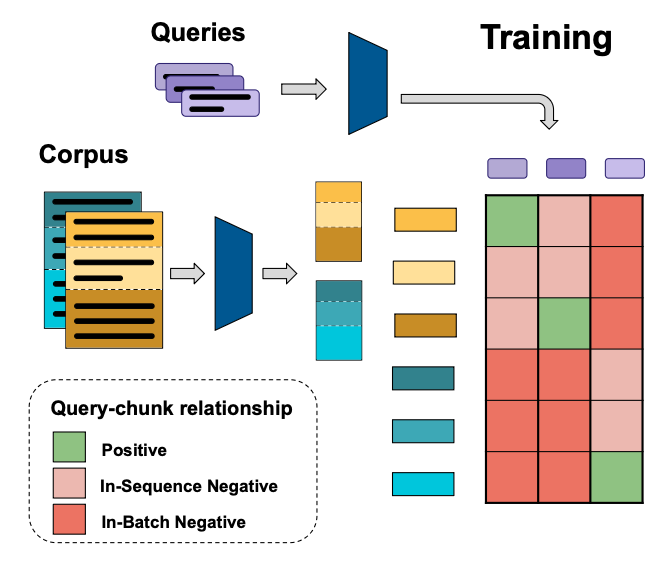
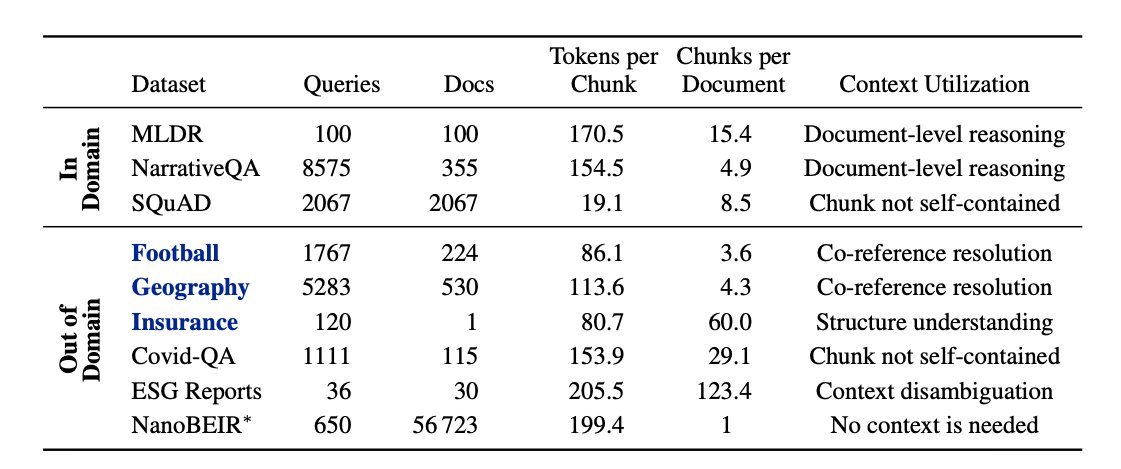
Most practicionners would agree that text embeddings should be "contextual" - ie. they should encode a passage w.r.t. the wider scope of the entire document the passage stems from; "They beat the British" could refer to football or french history without further context...
In ConTEB (arxiv.org/abs/2505.24782), we highlight the standard failure modes of embedding models on retrieval tasks that require context to be properly embedded. We also propose a training strategy that extends standard "late chunking" to teach models to infuse embeddings with just the right amount of contextual knowledge to optimize retrieval.
Super happy to see some new work by @perplexity_ai on contextual embedding models. They eval on ConTEB and use our in-sequence contrastive loss, along with a ton of cool techniques in multiple phases of training. Love the work @bo_wangbo and will read in details, but super happy to see one more stone towards contextual embedding models, in the path already traveled by @hxiao and @jxmnop !
Link to the paper: arxiv.org/abs/2602.11151v1
2
6
37
2,028
Max Conti retweeted

Jan 14
Very proud of this paper, we lead many more experiments since the first release.
I think we made a pretty complete analysis of what is currently possible with the benchmark !
Thanks again to everyone involved !

Two months ago, we released ViDoRe V3 benchmark. Now, the full paper is out! 📄arxiv.org/abs/2601.08620
Here is a recap of the benchmark along with a comprehensive breakdown of our findings on multimodal RAG. 🧵 (1/N)

2
5
81
Max Conti retweeted
31 Dec 2025
In our EMNLP 2025 Oral paper with @mlpc123, we propose an extension to Late Chunking and demonstrate how we can embed contextual information within passage embeddings... and why it's often very useful to improve document retrieval! (9/15)
arxiv.org/abs/2505.24782
1
2
3
132
Max Conti retweeted
5 Nov 2025
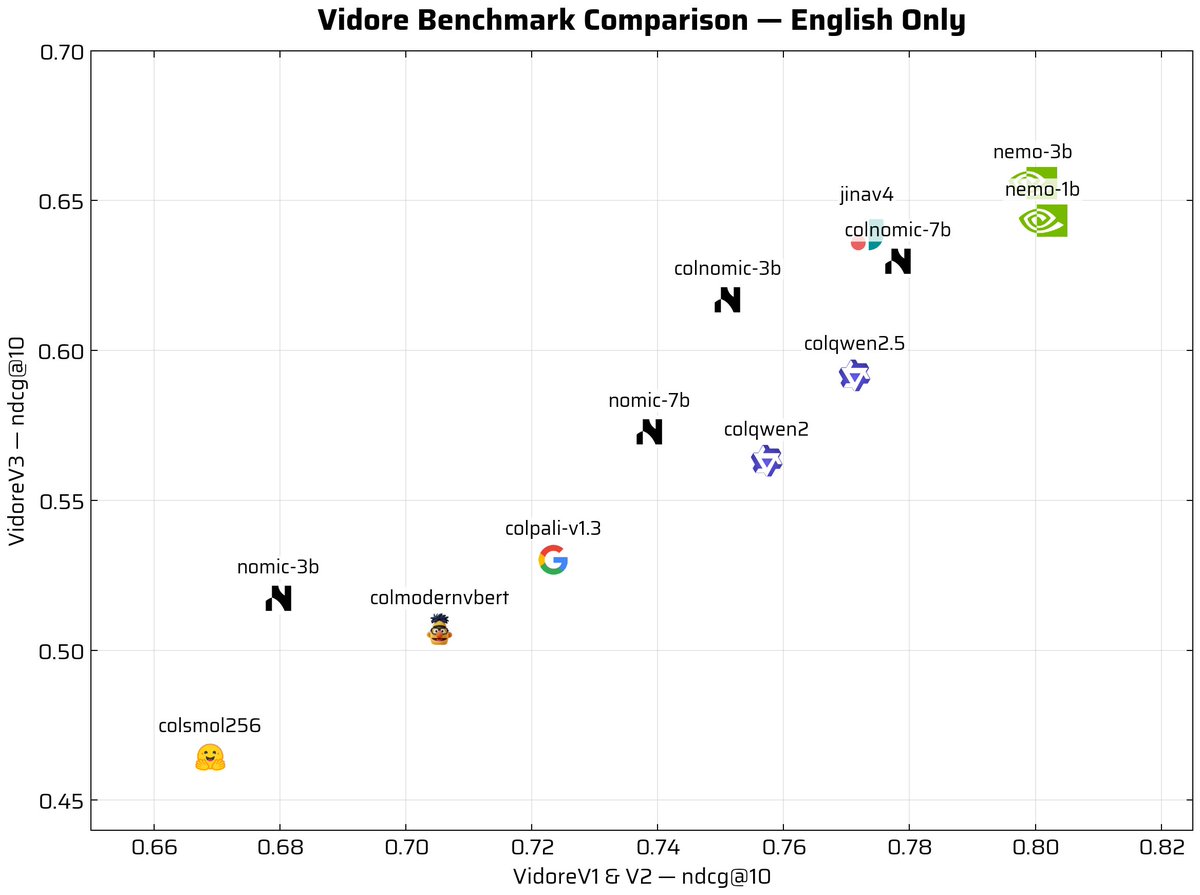
And happy to see our dear ModernVBERT competing with models much larger on it!
1
2
4
85
So happy for you that this project finally sees the day, more than a simple extension of the previous versions! Congrats for the hard work @MaceQuent1 @antonio_loison 🥳
5 Nov 2025
📢 ViDoRe V3, our new multimodal retrieval benchmark for enterprise use cases, is finally here!
It focuses on real-world applied RAG scenarios using high-quality human-verified data. huggingface.co/blog/QuentinJ…
🧵(1/N)

1
71
I'll be in Suzhou next week to present this project as an Oral at #EMNLP2025! 🥳
Let me know if you're there and wanna get in touch, or if you know anyone who'd be interested :)
Looking forward! 🙌🇨🇳
x.com/mlpc123/status/1929568…

🕺Super happy to release our latest work with @ManuelFaysse: in our paper "Context Is Gold to Find the Gold Passage", we share all our findings on how to train embedding models to meaningfully include doc-wide context into chunks - leading to convincing results! 🧑🍳 🧵1/N
2
96
Super excited to finally release this 🕺
What a fun project that was with these guys, s/o to them for all the great work!!
x.com/pteiletche/status/1974…
3 Oct 2025

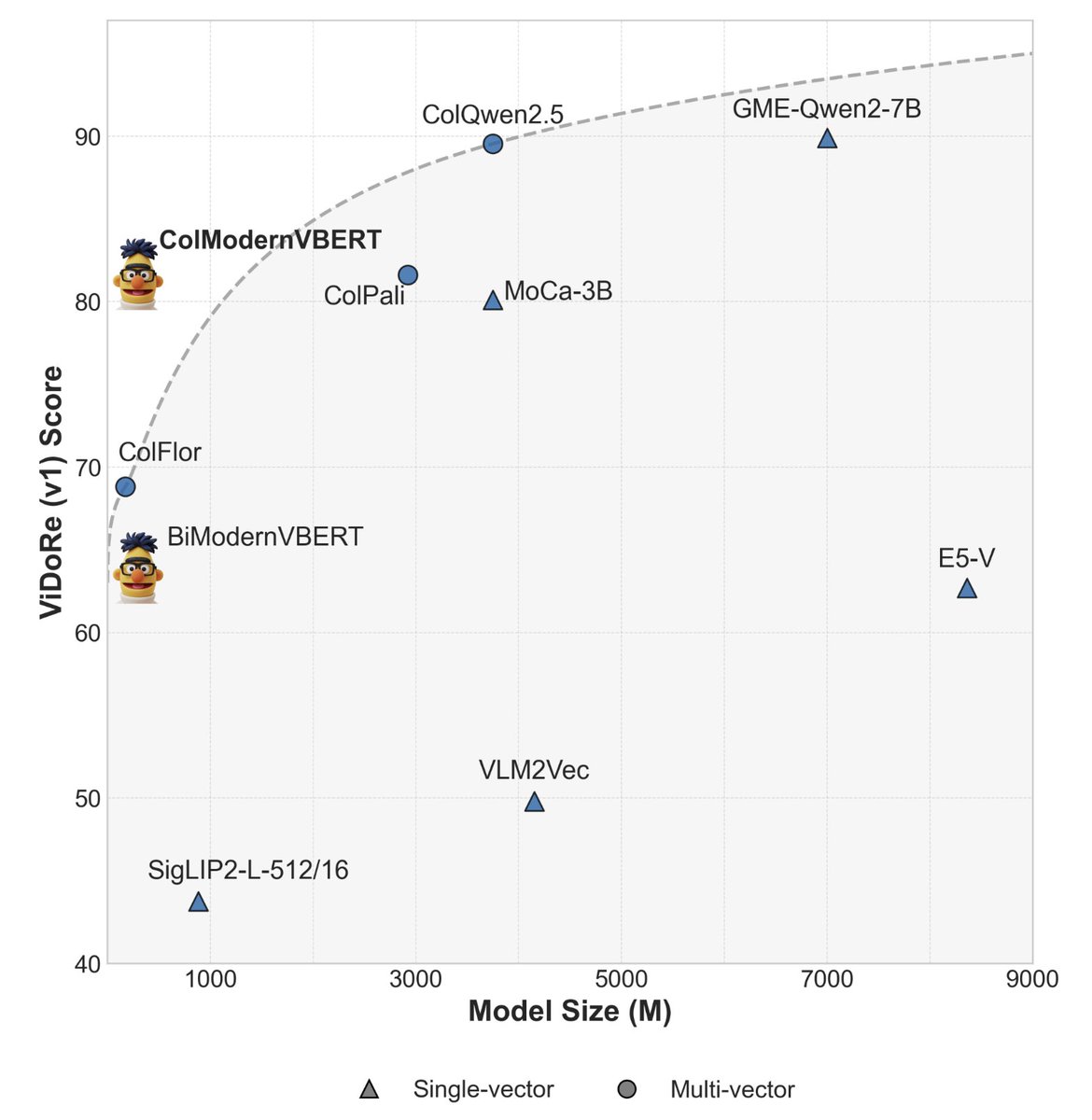
Introducing ModernVBERT: a vision-language encoder that matches the performance of models 10× its size on visual document retrieval tasks! 👁️
Read more in the thread👇 (1/N)
1
3
96
Besides our main results, it was also really interesting to look at some understudied training dynamics in more details
Our findings suggest that we've been using visual encoders far below their potential, and I think we can expect a lot of improvements building on top of this!
1
1
47
Looking forward to what @ManuelFaysse @pteiletche and @antonio_loison will be cooking next, and to the next one with @MaceQuent1 😉🤝
2
53
Max Conti retweeted
2 Jul 2025
🚨Should We Still Pretrain Encoders with Masked Language Modeling? We have recently seen massively trained causal decoders take the lead in embedding benchmarks, surpassing encoders w/ bidirectional attention. We revisit whether Bert-style encoders are a thing of the past? (1/N)

ALT Llama and Bert battling it out to determine what the best pretraining objective is - MLM or CLM ?
7
36
297
37,481
Max Conti retweeted
26 Jun 2025
Dear Reviewer #2, the placeholder URL "hf.co / <anonymous_url>" does lead to a non-existent page as you so correctly note as the main paper weakness, but don't fret, you have everything zipped in the uploaded materials a few pixels down
1
1
6
455