
76 Photos and videos




github.com/dropbox/gemlite/t…
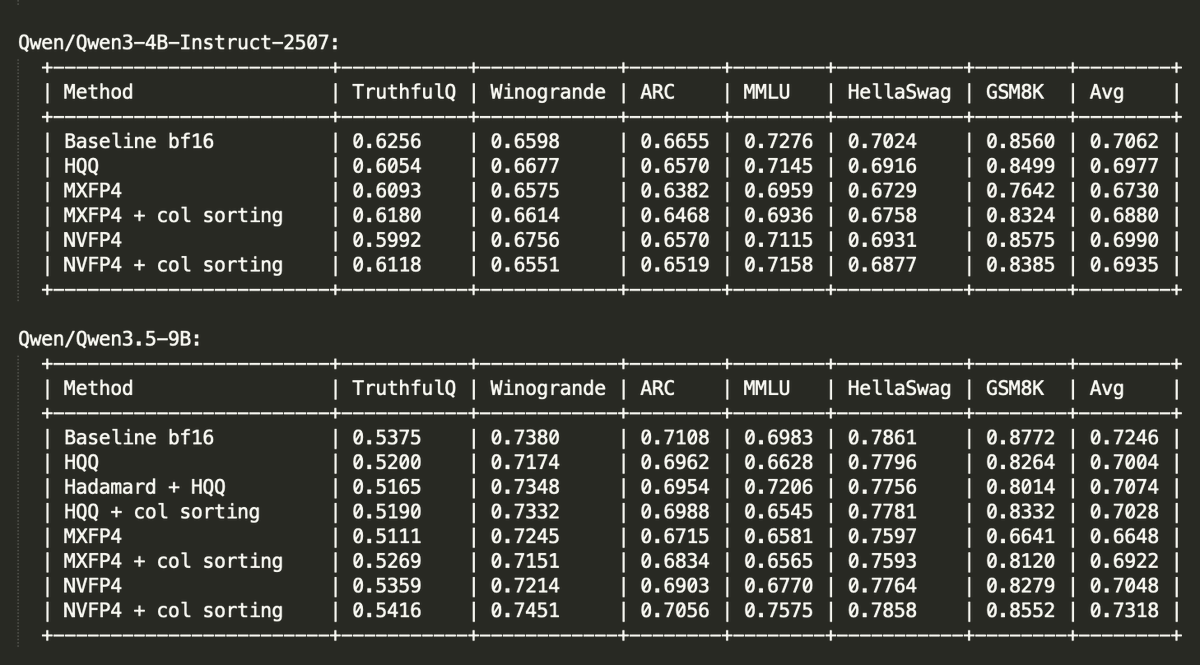
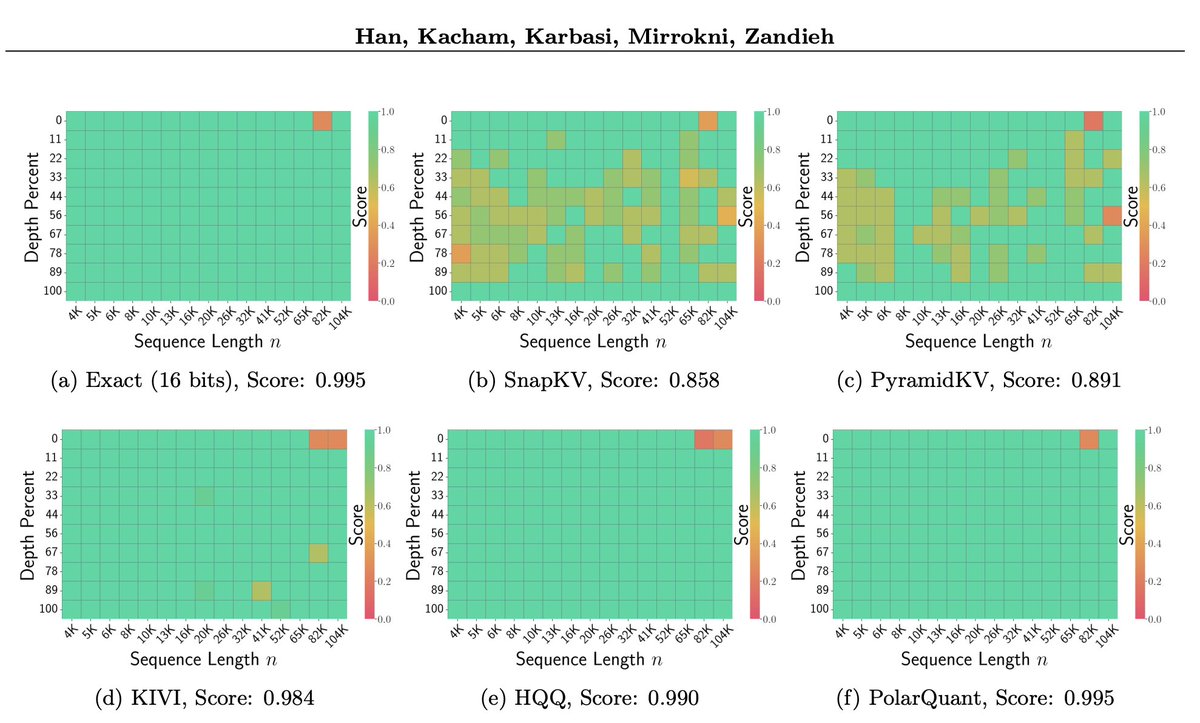
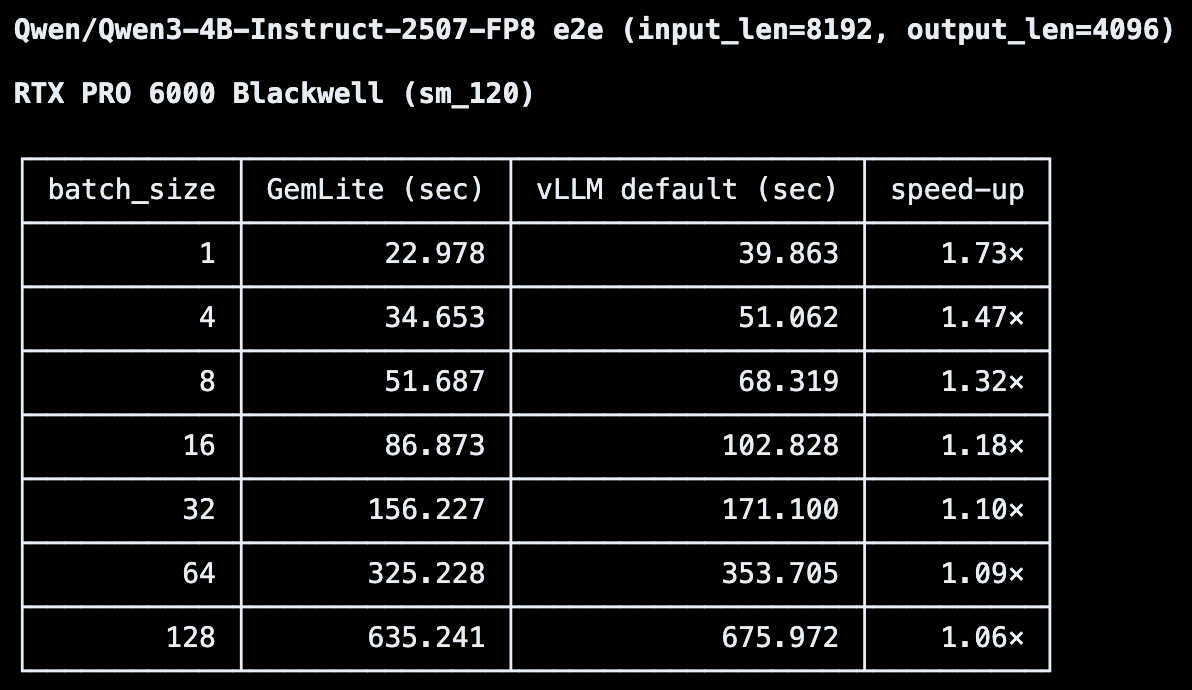
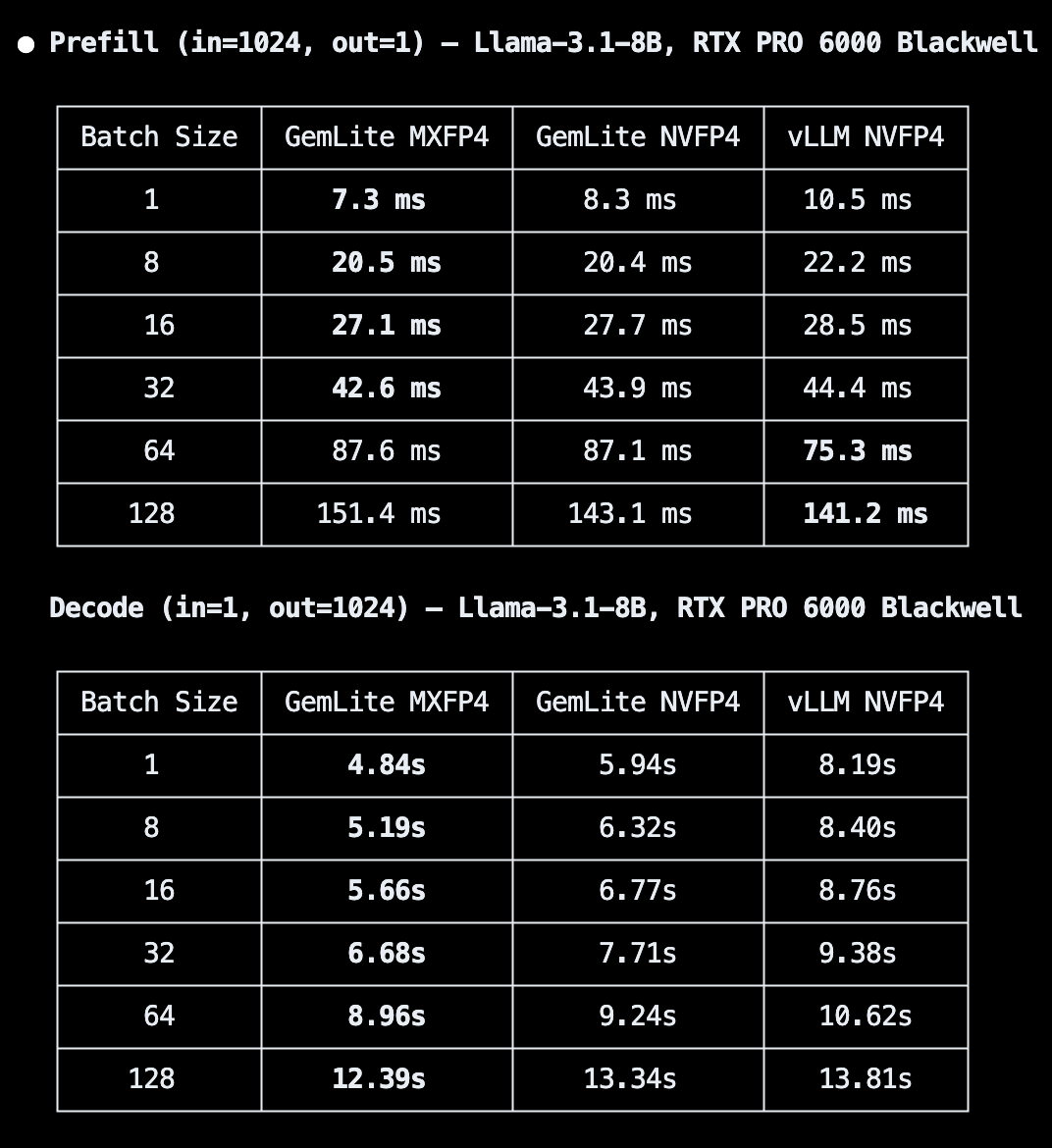
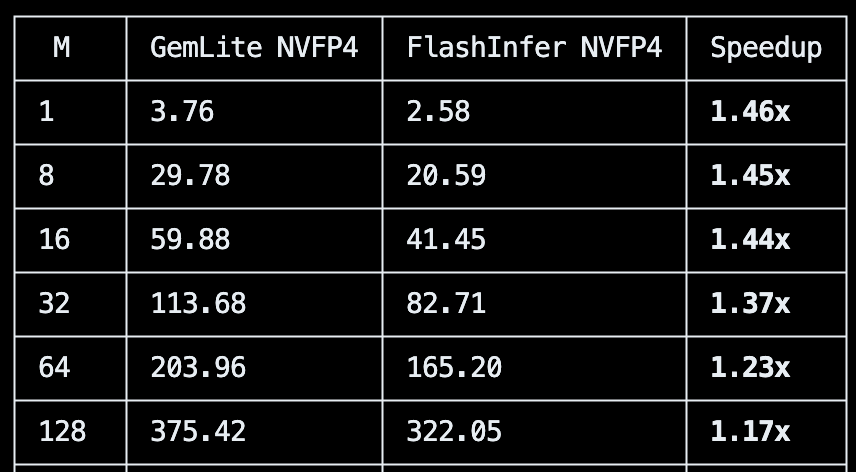
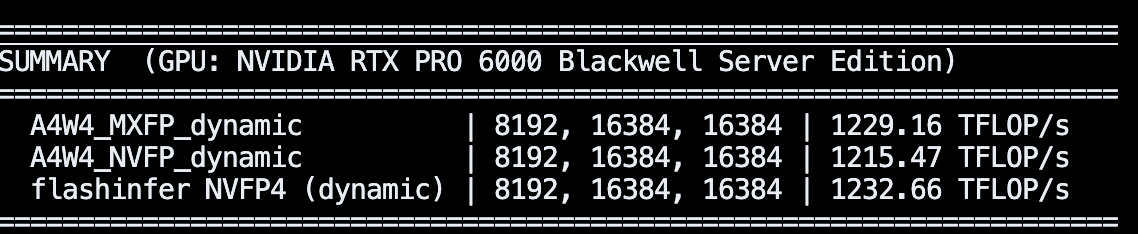
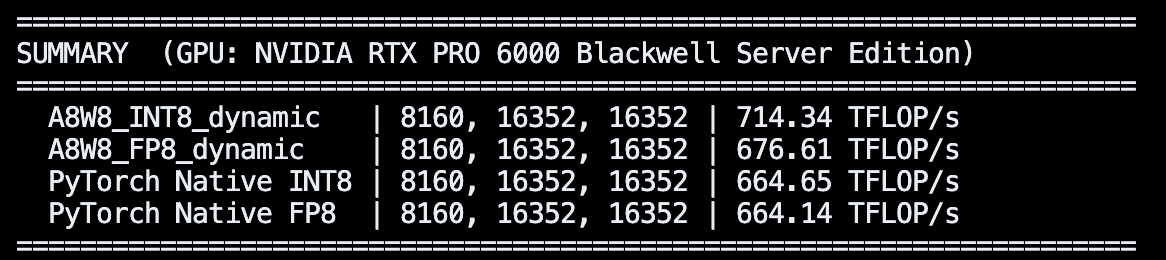
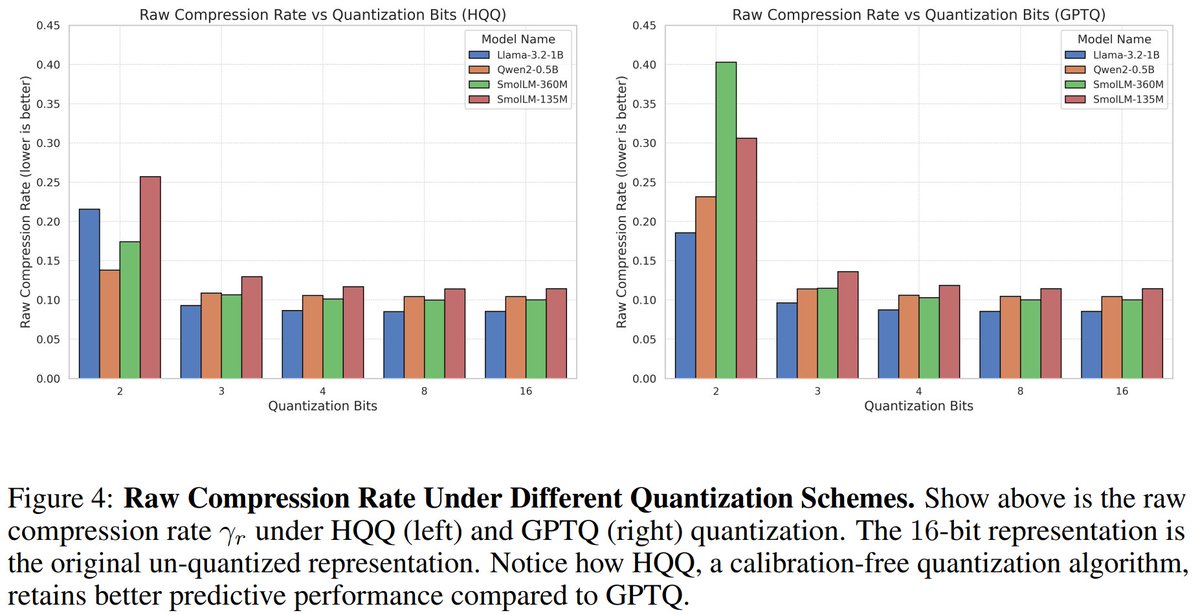
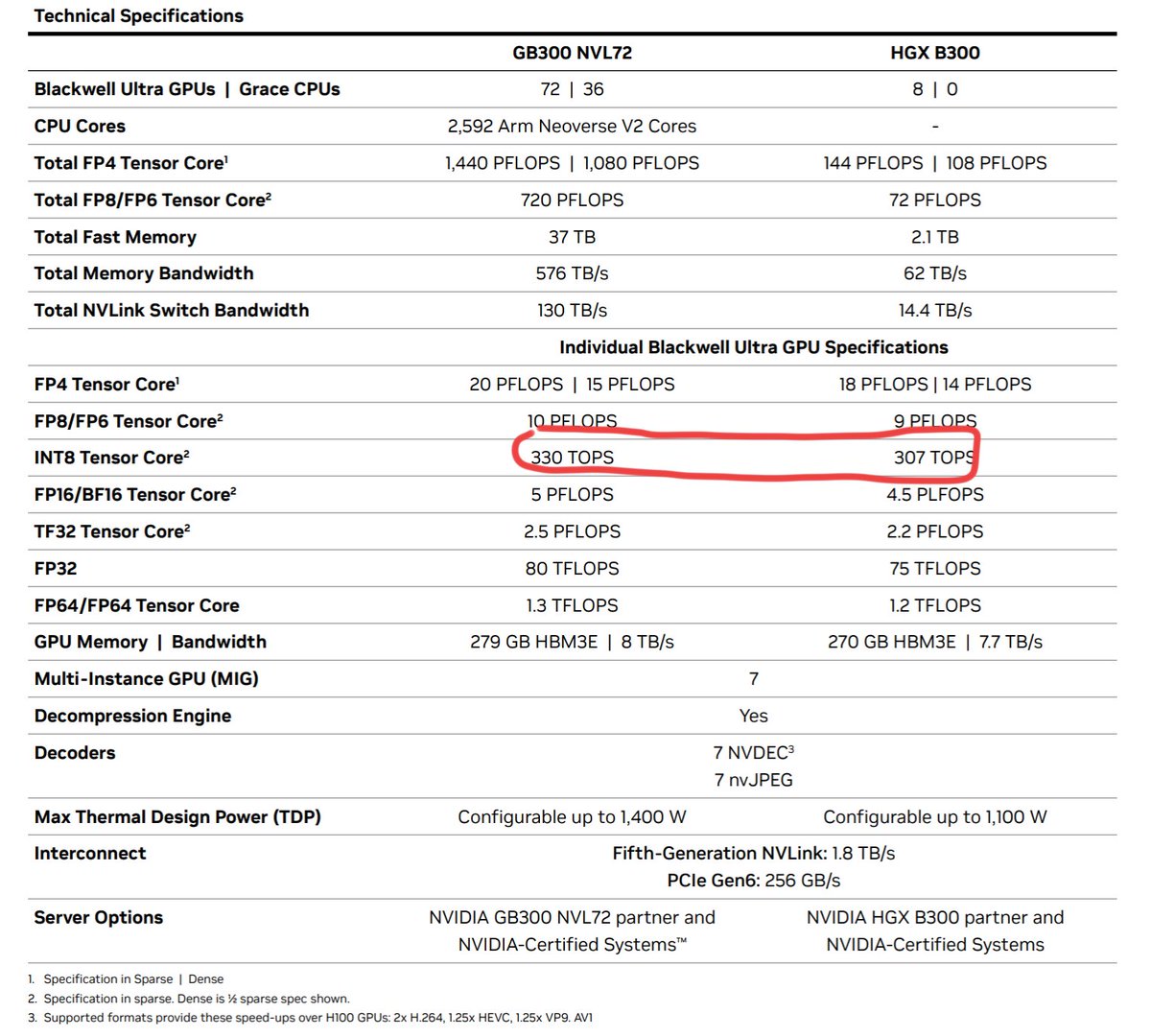
You can now easily load various pre-quantized models (block FP8, NVFP4, AWQ/GPTQ/HQQ, certain GGUFs) via a vLLM plugin! You can also run on-the-fly quant as well, easy to use: 1 or 2 flags to enable!
1
5
19
1,927
Some great on-device multi-vector work at Dropbox, check it out!
Apr 16

Open sourcing something fun from @Dropbox: Witchcraft.
It's a local search engine built in Rust with no API keys or vector DB required.
Think: ColBERT / late interaction style retrieval, but packaged to run locally (perfect for coding agents).
Let's dive in👇
2
255
🫡

Our next kernel competition is now open for submissions! A $1.1M cash prize competition sponsored by AMD on optimizing DeepSeek-R1-0528, GPT-OSS-120B on MI355X
Registration: luma.com/cqq4mojz
4
449