
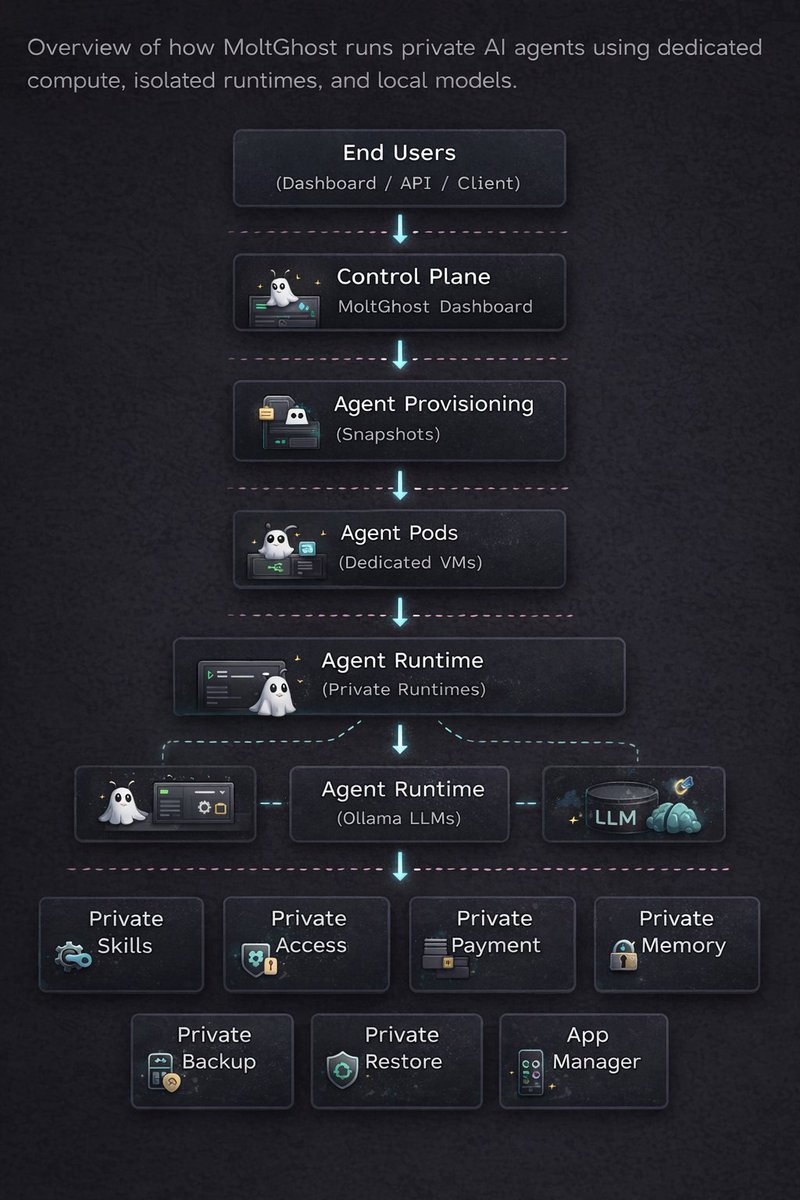
Private AI Agent Infrastructure. CA : GtAHbD7JD7xQJW9ai1fxdxKG65cKsbuCTukTNjRkpump || t.me/moltghost / github.com/Moltghost
Joined February 2026
- Tweets 81
- Following 30
- Followers 268
- Likes 205
22 Photos and videos




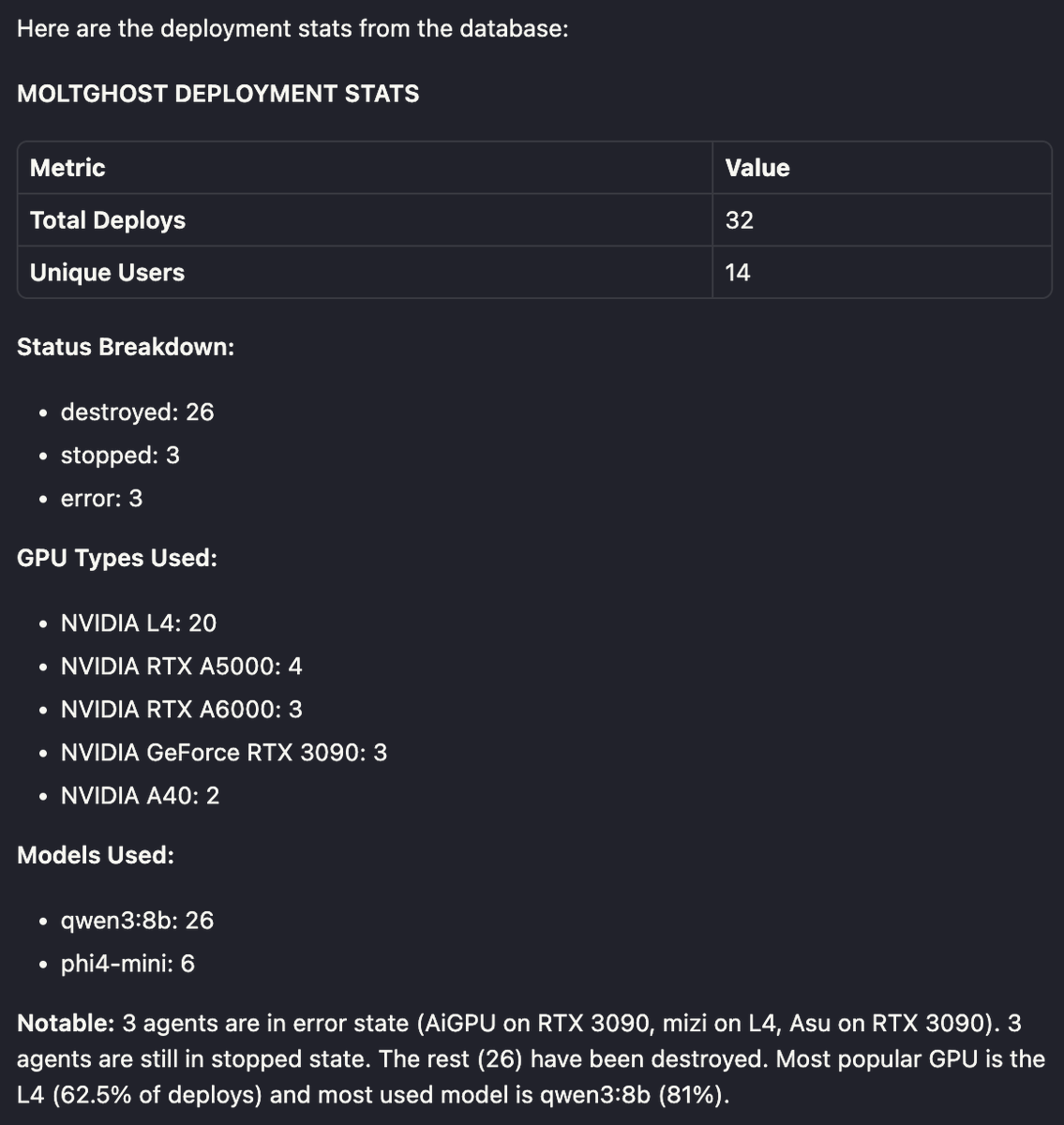


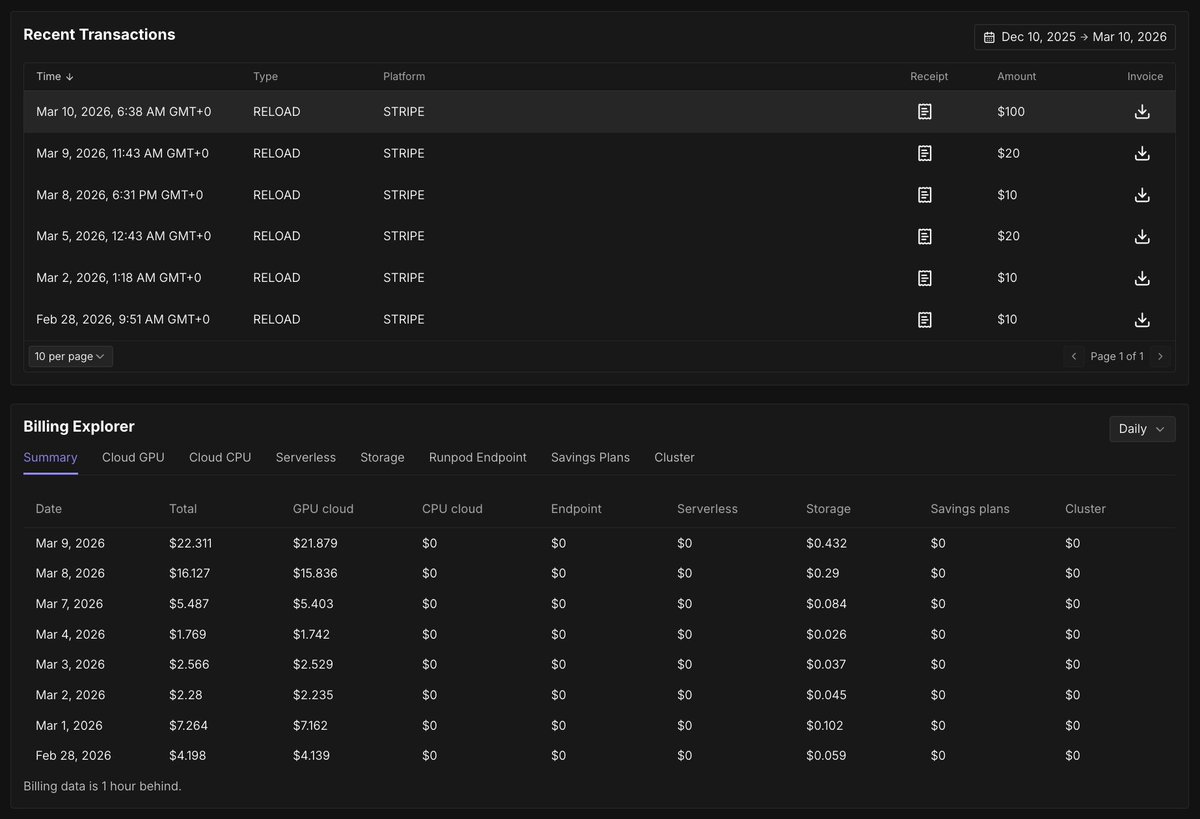
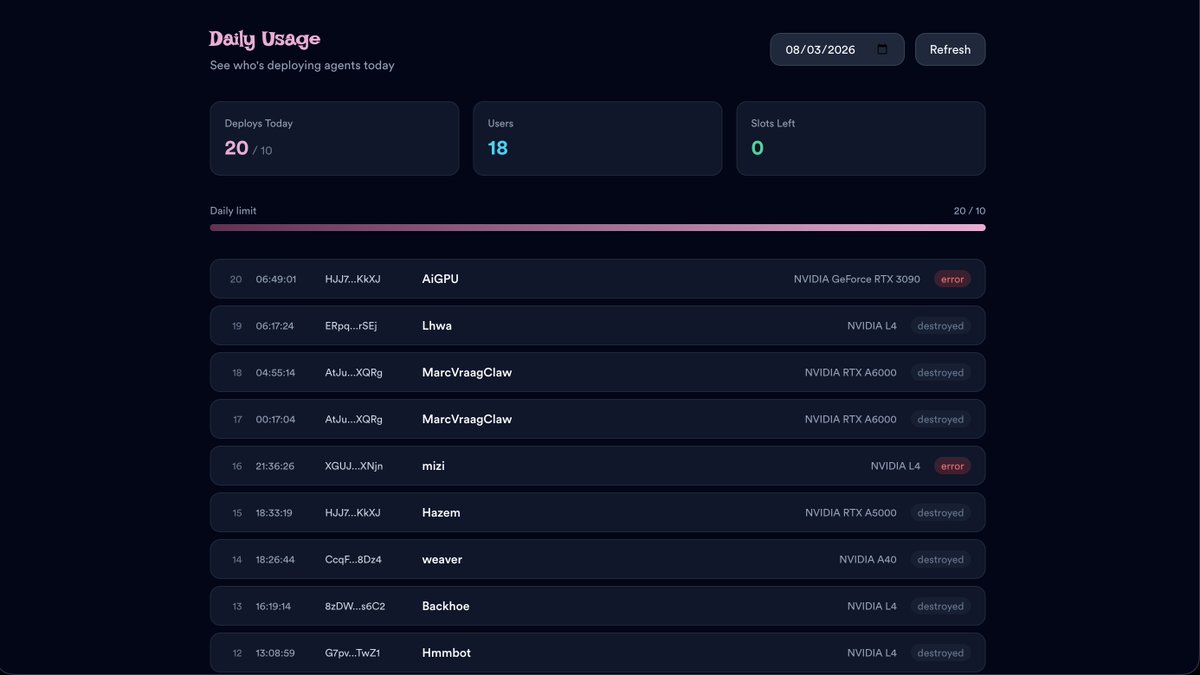

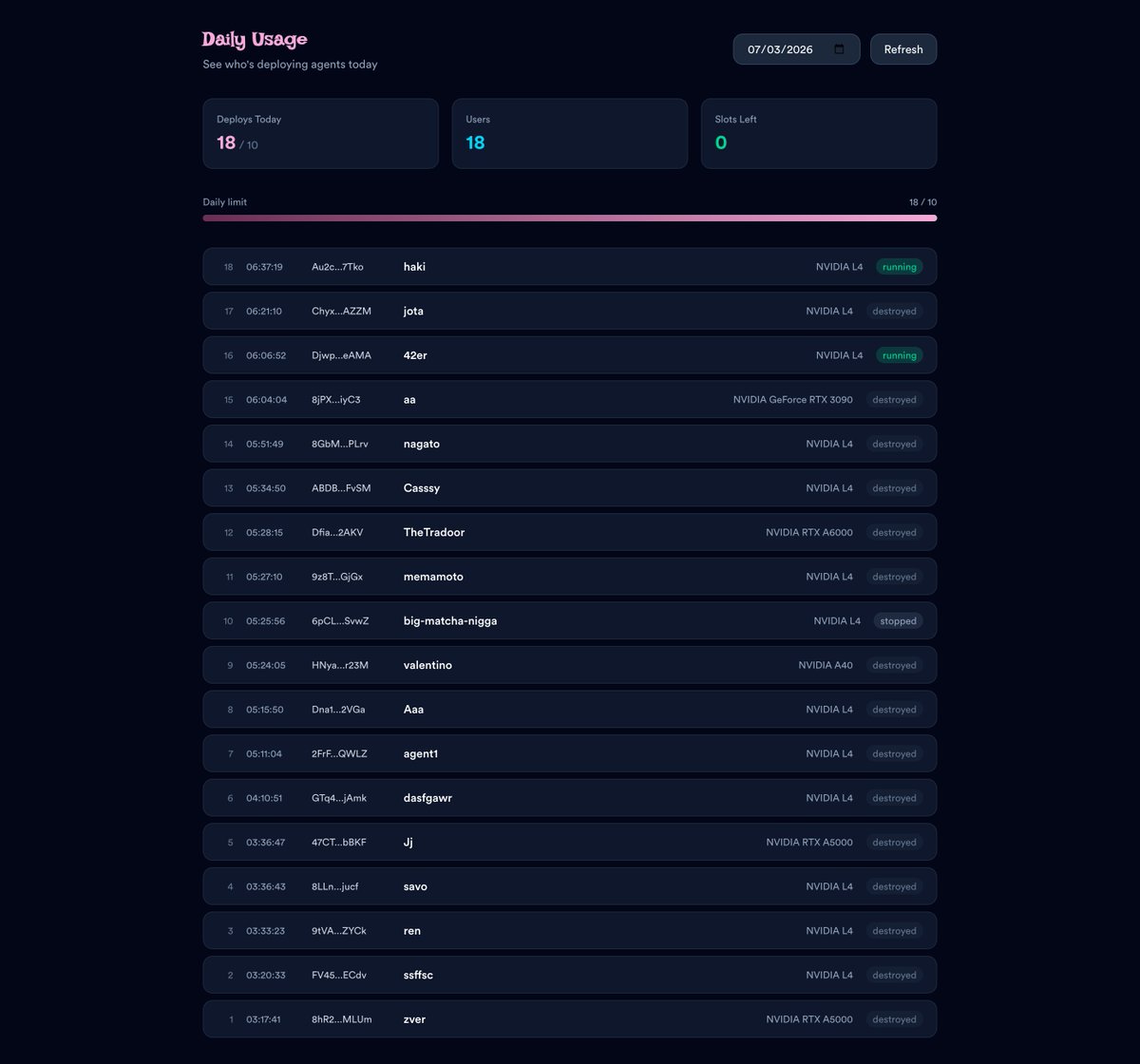



Pinned Tweet

Mar 25
👻 Moltghost — Last Update
Self-hosted infra with AES-256 encrypted DB. zero-knowledge: your wallet, your key.
deploy AI agents via @ollama on @runpod @nvidia GPUs with your own API key.
model → GPU → deploy → live agent URL.
built with OpenClaw 🦀
app.moltghost.io
8
4
13
930
Moltghost retweeted

Apr 2
My self-sovereign / local / private / secure LLM setup, April 2026
vitalik.eth.limo/general/202…
694
668
5,102
1,330,684
Mar 26
Filesystem Privacy & Security: The Forgotten Layer in AI Agent Deployment
Why Filesystem Matters
When we talk about AI security, the conversation usually gravitates toward prompt injection, model poisoning, or API key leaks. Rarely does anyone talk about the filesystem — the layer where your model weights sit, where your agent writes logs, and where secrets live between reboots.
Readmore:
medium.com/@moltghost/filesy…
2
3
441
Mar 25
Your AI agent runs as root. It can cat /tmp/startup.sh and see every secret you passed in.
Filesystem security isn't optional — it's the difference between "isolated agent" and "open backdoor."
Mount only what's needed. Read-only by default. Delete secrets after exec.
We're building a fully private AI agent stack — 20 layers of security & privacy from inference to runtime defense. This is Layer 4: Filesystem.
1
1
7
556
Mar 25
Gm, deep in code audits, patching things up.
Keep building, keep sipping ☕
3
9
416
Mar 24
🔍 I just audited MoltGhost's own infrastructure against the privacy standard we laid out in our "Self-Hosting Your AI Agent Gateway" article.
Honest score: ~60% private.
Here's what's already running on our own server:
✅ Express gateway — every request routed locally
✅ WebSocket server — real-time agent status, zero third-party relay
✅ Winston logger — logs stay on disk, never shipped externally
✅ JWT auth middleware — tokens verified server-side
✅ Ownership isolation — users can only touch their own deployments
But here's where we're exposed:
❌ Database sits on Neon — a SaaS PostgreSQL. That means every wallet address, email, agent name, deployment config, and tunnel token lives on someone else's infrastructure. We preach "the gateway sees everything" — and right now, so does Neon.
What's coming next:
1/ Killing the SaaS database entirely. Migrating to self-hosted PostgreSQL. Drizzle ORM makes this a 2-file driver swap — same schema, same queries, same migrations. Zero data leaves our infra.
2/ Zero-knowledge user encryption. This is the big one. Your Solana wallet becomes your encryption key. You sign a message → we hash the signature into an AES-256 key → your data gets encrypted IN YOUR BROWSER before it ever touches our server. Backend stores nothing but ciphertext.
What the database looks like after this:
email → "aes256:8f2j3k9x..."
wallet → "aes256:m9x2p1q7..."
agentName → "aes256:w3e8r2t5..."
Not us. Not a hacker. Not a subpoena. Nobody reads your data without YOUR wallet signing for it.
We're building infrastructure where even the operator is blind to user data. Self-hosted runtime zero-knowledge encryption = privacy that isn't just a feature — it's the architecture.
More coming soon. 👻
5
2
13
475
Mar 23
Most people focus on inference for private AI.
But memory is where things actually stay.
Every chat, file, and tool output becomes part of the agent’s long-term context.
That’s why in MoltGhost next phase, we’re pushing:
- per-agent memory isolation
- local vector storage
- local embedding models
- optional ephemeral memory
Each agent has its own “brain”
no shared storage, no external indexing
So memory isn’t just stored — it’s contained.
Inference is where data flows
Memory is where it lives
MoltGhost is built to control both
2
3
11
415
Mar 23
I just published Self-Hosting Your AI Agent Gateway: Why ‘Running Locally’ Is Not Enough medium.com/p/self-hosting-yo…
1
9
351
Mar 23
So instead of sending all that inference data outside your infra,
we run it like this:
OpenClaw → Qwen 3B → fully local
In this demo, every prompt, system message, file context, and tool output stays inside the machine.
No external inference endpoint
No fallback to cloud
No data leaving your runtime
This is what controlling the inference layer actually looks like.
2
6
16
434
Mar 23
Inference is the most critical layer in OpenClaw.
It’s not just “chat” — it’s the execution core.
Every prompt, system message, file context, and tool output is sent into the model at this stage.
If your inference endpoint points to external APIs, you’re not running a private agent — you’re streaming your entire runtime outside your infra.
Even worse, some setups silently fallback to cloud providers or break tool calling when using “OpenAI-compatible” endpoints.
Fully private means:
OpenClaw → local inference (Ollama / vLLM) → local GPU
No external calls
No fallback providers
No hidden routing
If you don’t control inference, you don’t control anything.
2
2
6
303
Mar 22
your AI agent shouldn’t leak your data
- prompts
- memory
- workflows
if it’s not private, it’s not yours
2
9
323
Mar 22
MoltGhost Dexscreener just got an update.
We’ve added GitHub and Docs so everyone can easily explore what we’re building and follow our progress.
Check it out.
dexscreener.com/solana/4gznd…
9
2
13
757
Mar 22
For now, we've disabled the free launch on the website.
We're actively developing the new app manager at moltghost-app-manager.vercel… your private way to deploy OpenClaw easily & securely.
1
8
713
Mar 22
We sincerely apologize for the lack of updates over the past few days.
Due to unexpected natural disaster conditions in our working area, our operations were temporarily disrupted. Thankfully, the situation has now been resolved and everything is back on track.
We are now fully ready to resume work as usual.
Starting today, we will begin rolling out several updates , stay tuned.
Thank you for your patience and continued support $MOLTG
3
8
470
Mar 15
Just dropped - moltghost-builder
A lightweight VPS service that builds custom HuggingFace LLM Docker images on demand — pulls the model via Ollama, builds, pushes to Docker Hub, and fires a callback when done.
github.com/Moltghost/moltgho…
#nodejs #docker #llm #huggingface
3
8
24
1,218
Moltghost retweeted
Mar 15
GM $MOLTG
Still building MoltGhost.
We’re currently working on several things behind the scenes. Our focus remains on improving the infrastructure and overall experience for running private AI agents on dedicated machines.
More updates soon. 👻
4
11
19
1,122
Mar 14
Just shipped Llama 3.1 8B on MoltGhost 🦙
3 models now available:
• Qwen 3 8B — all-rounder
• Phi-4 Mini — fast & light
• Llama 3.1 8B — strong reasoning
One-click deploy. Dedicated GPU. No shared infra.
8
9
27
1,187
Mar 13
Behind the scenes, our dev team is still building MoltGhost.
Starting with the MoltGhost UI — some parts are coded manually, while others use AI to move faster.
But not everything should be generated by AI.
Honestly, we’re getting a bit bored with the generic AI-generated UI everywhere, so we’re taking the time to build it the way we actually designed it.
Thanks for the patience
1
7
22
913
Mar 13
This is exactly why we’re building MoltGhost.
Local AI agents alone aren’t enough. You need private runtime, isolated compute, and wallet-native infrastructure to prevent access pattern leakage.
Privacy for AI agents has to be full-stack.
Mar 8

Crypto privacy is needed if you want to make API calls without compromising the information of your access patterns.
eg. even with a local AI agent, you can learn a lot about what someone is doing if you see all of their search engine calls
first-order solution to that is to make those calls through mixnet
but then (or in fact, even without the mixnet) the providers will get DoSed, and they will demand an anti-DoS mechanism, and realistically payment per call
by default that will be credit card or some corposlop "yeah we'll get to the privacy later" stablecoin thing
so we need crypto privacy
But yes, for privacy you have to think full stack. Local AI agent layer is very important.
It is like longevity: if there are 10 things damaging your body, curing one of them increases your longevity by 11%, curing two by 25%, and curing three by 42% (1 / (1 - 0.3) minus 100% base). Risks from data leakage are similar, and so mitigations similarly compound super-additively.
4
10
28
1,957