
Joined April 2020
- Tweets 56
- Following 71
- Followers 566
- Likes 20
19 Photos and videos














Moment retweeted

I am trying to build the fastest way to query a CSV with SQL. I have it down to 2 clicks.
3
9
1,914
Moment retweeted
I've turned this into a blog post with an interactive visualization: "TurboQuant, or: why are random compression schemes often nearly as good as carefully-designed ones?". Link in reply.

The first time you hear about the JL lemma, it will seem too good to be true. And it is, kind of, I'll explain. The idea is: if you have points in large d-dimensional space, a RANDOM projection to much smaller k-dim subspace will be "nearly optimal" "in the general case." Or, more specifically: with high probability, the pairwise distances between points are preserved, given a couple other requirements around d and k.
So why don't we just use random projections instead of carefully-constructed ones all the time? This is the most common misunderstanding of the JL lemma, and the one thing to really understand about it: in many (most?) datasets that are meaningful to humans, you actually CAN do better with something like maybe PCA. If your dataset is pathological, e.g., the points all lie on a plane even though it's technically in 3 dimensions, then clearly some planes you project onto will be better than others. The JL lemma does not apply to 2 and 3 dimensions, but you can imagine this would be true in large numbers of dimensions too. (See screenshot 1, i hope you like it because i made it myself lol.)
If you know just those facts, you will be pretty well-prepared to answer most questions about its use. Most of the papers Delip mentions do presuppose that you know this. At least when I was a student, I found this to be non-obvious.

2
10
111
16,255
Moment retweeted
replacing a tableau dashboard with markdown files. Drag weather.csv into document → click "query with SQLite" → tell copilot CLI to make the dashboard. 30s end-to-end not including the time opus-4.6 needs to think about it.
1
2
14
1,308
Moment retweeted
Earlier this week we got to the frontpage of HN writing a somewhat negative article about CRDTs, and particularly, Yjs. Today I wrote about what I think the long-term fix is: funding the `react-prosemirror` project. We spend $10k/yr on it. You should too.
x.com/hausdorff_space/status…
1
3
1,144
Moment retweeted
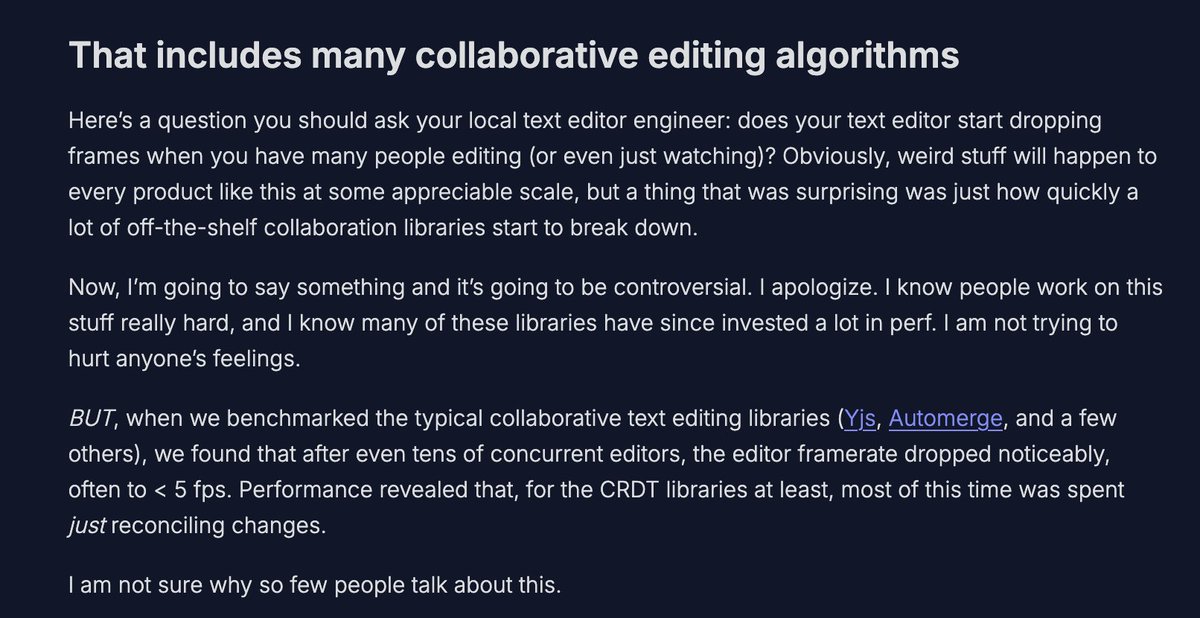
Ok. For the last, like, 15 years, I've constantly been told that CRDTs (and Yjs in particular) solve collaborative text editing. Both the offline and live-collab cases. After an excruciatingly painful evaluation, I argue not only is this completely false, they're generally not appropriate for production-grade editors... at all.
Yeah, I know: everyone uses Yjs, so the problem must be us. Right? That's what I thought too. Well, did you know that on every single collaborative keystroke, Yjs will REPLACE YOUR ENTIRE DOCUMENT? (See this GitHub issue: github.com/yjs/y-prosemirror…) Did you know that this is BY DESIGN? (See this discussion on the ProseMirror boards: discuss.prosemirror.net/t/of…) Did you know that this breaks, like, every editor plugin? (See the ProseMirror author's commentary here: discuss.prosemirror.net/t/of…)
I am not trying to bag on anyone, but to me this kind of mistake belies a fundamental misunderstanding of what text editors need to perform well, in any situation, let alone a collaborative one.
Anyway, learn from my pain. I wrote a somewhat long-form article about all the other challenges we ran into with CRDTs on our blog: moment.dev/blog/lies-i-was-t…
5
9
106
11,948
Moment retweeted
3
13
139
69,753
Moment retweeted
we are in software’s carboniferous era. a giant, verdant, swampy explosion of personalized software that will eventually become the coal deposits of the next era.
1
3
1,103
Moment retweeted

Feb 18
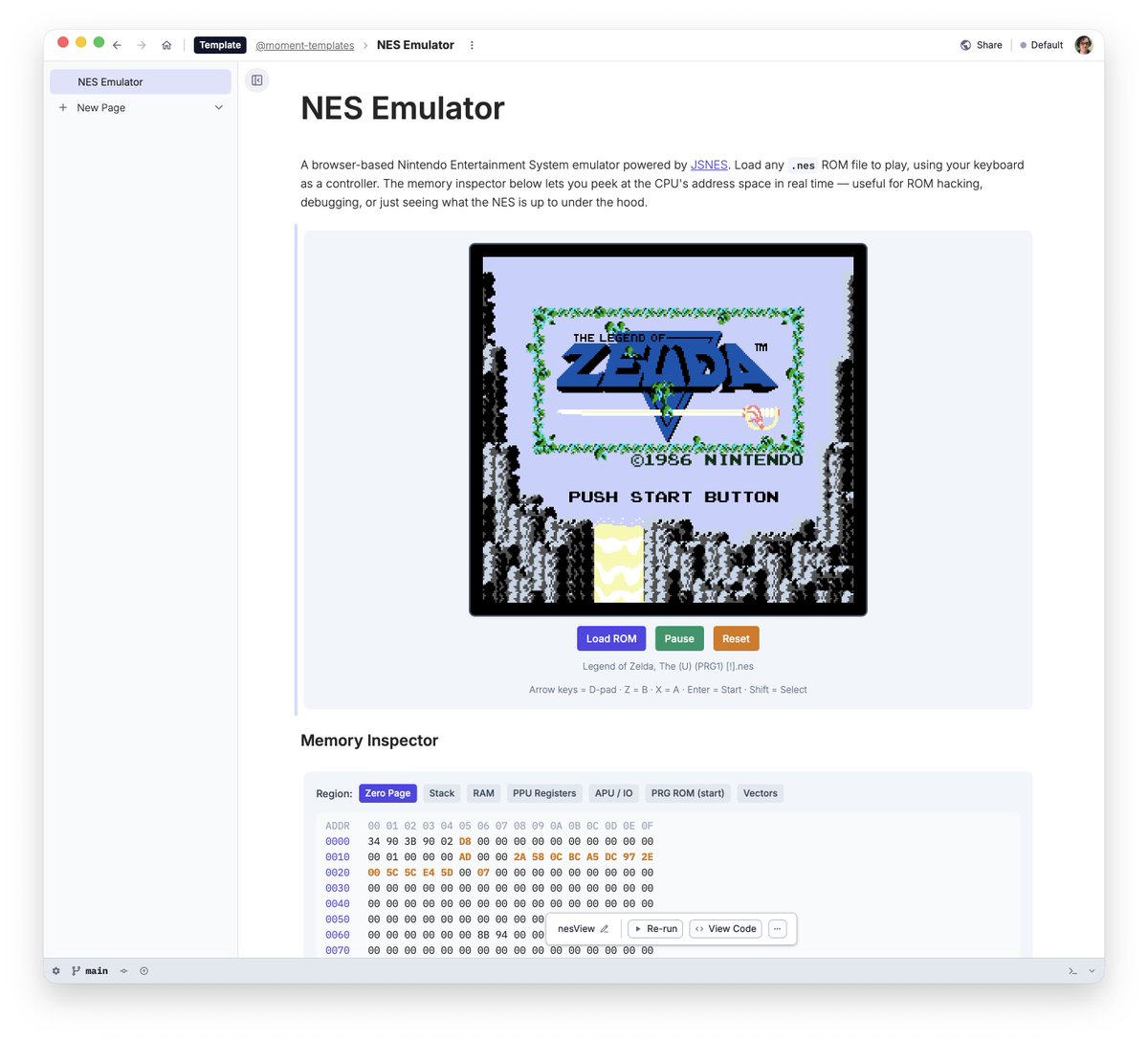
it took me months to have a working nes emulator in browser but claude one shotted it😭
Feb 18

if u are building a markdown-based notion competitor, it is v. important that you are able to vibe up a working NES emulator, which is claude did in this video in about 10 minutes (you can see just the last part here, where the whole thing lights up)
1
1
3
593

Feb 18
if u are building a markdown-based notion competitor, it is v. important that you are able to vibe up a working NES emulator, which is claude did in this video in about 10 minutes (you can see just the last part here, where the whole thing lights up)
2
1
15
7,933
Feb 18
Of course YOU don't have to vibe code it, because I immediately turned it into a template. You can just get it with `New Document`:
1
649
Feb 17
Moment is Google docs, but for markdown, with a git backend.
Feb 5

@southpolesteve was just complaining to me about this
Google docs but for markdown with github/gist backend
10
12
154
20,589
Feb 17
I SHOULD HAVE POSTED THIS BEFORE, I AM SORRY, but elsewhere in that thread are some videos of the sort of thing we are up to recently: x.com/hausdorff_space/status…
I missed this at the time, sorry. Yes, this is what we do @samuelcolvin at @moment_dev. The product is basically a Notion-like workspace (live collab, tables, buttons that do things) but (1) it's also plain-old Markdown files, living in git repositories, on your local disk, and (2) it's programmable (because markdown) and therefore natively amenable to use with `claude`.
Here, for example, are two templates claude pretty much one-shotted. An NES emulator with living memory space visualization:
and a dashboard for our team's live PRs:
5
1,362
Moment retweeted
I missed this at the time, sorry. Yes, this is what we do @samuelcolvin at @moment_dev. The product is basically a Notion-like workspace (live collab, tables, buttons that do things) but (1) it's also plain-old Markdown files, living in git repositories, on your local disk, and (2) it's programmable (because markdown) and therefore natively amenable to use with `claude`.
Here, for example, are two templates claude pretty much one-shotted. An NES emulator with living memory space visualization:
and a dashboard for our team's live PRs:
1
2
7
4,328
Jan 24
🧵 Changelog 0008.
Daily Notes. One of Moment’s most-requested features. The button always shows up in the top left of the docs list. Click it, and it creates a page for today, if one does not exist. The cal shows you which dates have entries. Click to open that date's page!
1
1
401
Jan 24
Beyond all this, many small bugs and fixes. Forward/backwards buttons, fixes to how delete works next to bullet list, fixes for truncation, decoding, and zombie process bugs in the embedded terminal, fixes to filewatching, fixes for image loading, and many others.
1
284