
World models hardware acceleration, @worldjen_ai father
Joined November 2025
- Tweets 50
- Following 13
- Followers 191
- Likes 39
17 Photos and videos










Jun 2
Generative Media TLV #2 meetup is live! 🚀
In collaboration with @nebiusai, we’re bringing together the Israeli generative media research community once again!
Featuring - talks will be recorded:
Decart Optimization Stack
Orian Leitersdorf | Chief Scientist & Co-Founder @DecartAI
BADAS-2.0 - Nexar Driving World Model
@ronigoldshmidt | Senior AI researcher @getnexar
Beyond Text: Continuous Control in Generative Models
@OPatashnik | Assistant Professor @TelAvivUni
Multimodal Generative Agents At Scale
Aviad Dahan | AI Researcher @ ZyG
🗓️ June 15
📍Nebius offices Tel Aviv
1
1
4
274
MoonMath.ai retweeted
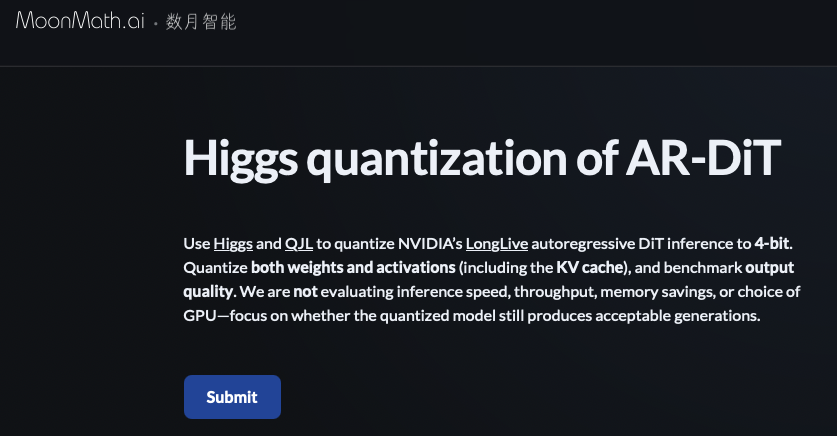
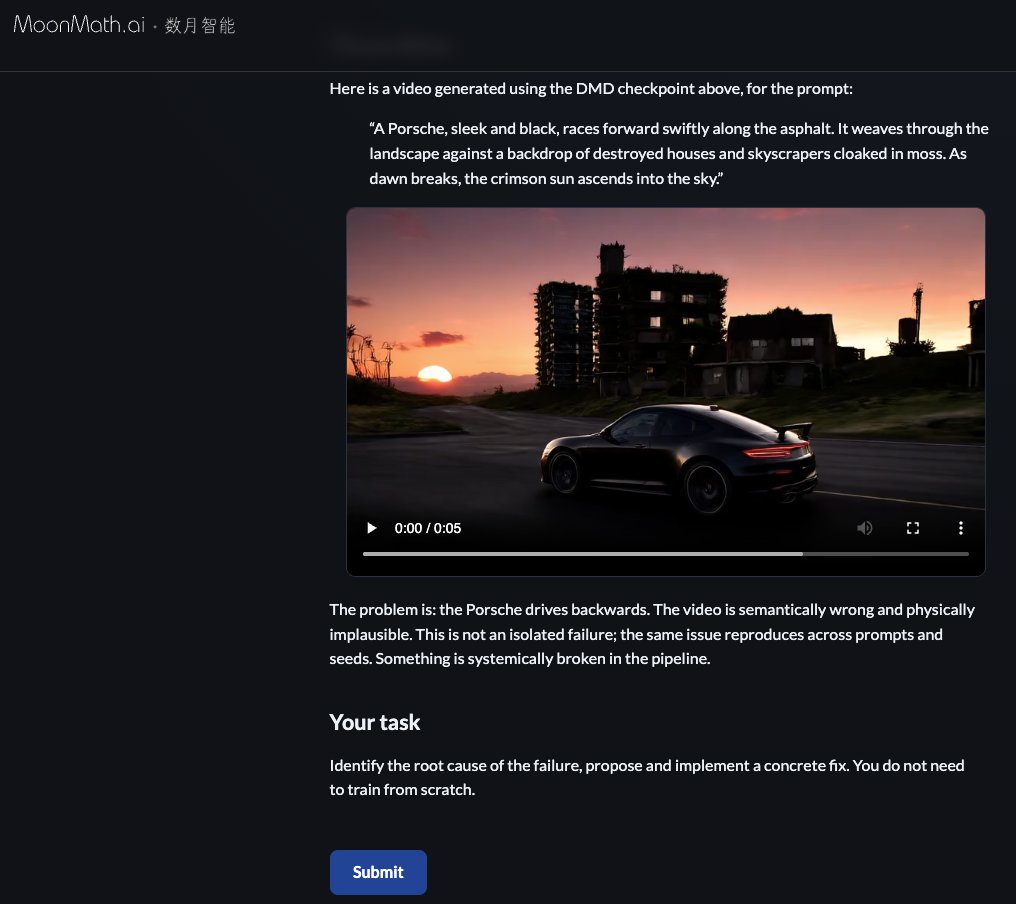
Our most popular section on the website is Challenges.
It's how we hire:
Solve a challenge → get a job offer 💪
A few examples below. More coming soon.
Claude won’t help..

2
9
597
MoonMath.ai retweeted
I just published new research on Video Evals 🤓
We introduce a new scoring system called WorldJen.
This work came from a practical need: when we optimize kernels for video models, we may affect output quality. But video quality loss is hard to quantify. How do we measure degradation or prove an optimization is lossless?
We couldn’t find an existing method we were satisfied with. Human evals are expensive and slow. Current benchmarks are saturated, limited in dimensions, and often miss the specific quality regressions we care about.
Then we spoke with friends at generative media labs and learned they share the same pain. While inference, training, and RL get massive engineering investment, evals are still left behind. So we set out to fix this.
You can skip the paper and just ask your favorite coding agent to install WorldJen and start evaluating videos or models, free. But I strongly recommend checking out the project page: you can score any video in the playground across 11 dimensions, see our kernel-optimization use case in action, and explore examples and insights from the study. We open sourced everything so you can reproduce.
Please share feedback and most importantly, help us find the edge cases where the system breaks. Thank you 🙏
1
1
6
649
May 6
🚨 New Paper 🚨
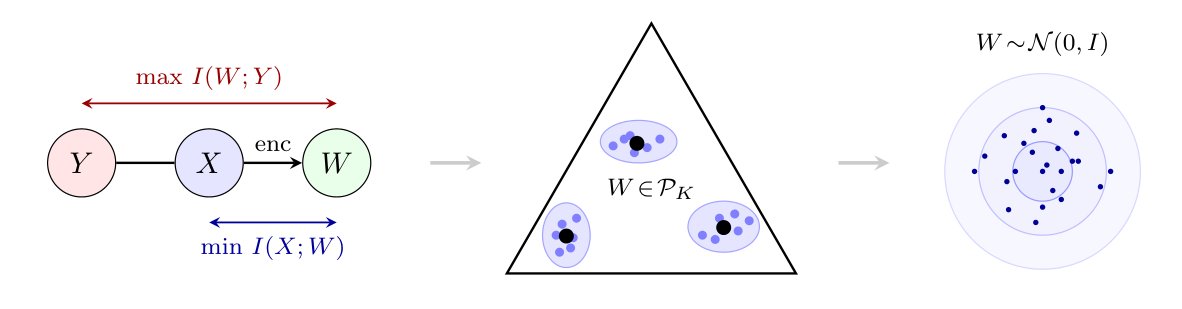
Why Self-Supervised Encoders Want to Be Normal:
Understanding Joint Embedding Predictive Architecture: Soft Clustering on the Predictive Manifold
abstract: Self-supervised learning has achieved remarkable empirical success in learning robust representations without explicit labels, most recently demonstrated within the framework of Joint-Embedding Predictive Architectures (JEPA).
However, a fundamental question remains: what analytical principles drive these encoders toward specific distributional states? In this paper, we demonstrate that the preference for normal distributions in self-supervised encoders is a direct consequence of the Information Bottleneck (IB) principle. By recasting the IB objective as a rate-distortion problem over the predictive manifold, we provide a theoretical basis for why optimal, target-neutral, latent representations should tend towards isotropic Gaussian states.
Under this framework, we show that latent representations correspond to soft clustering of inputs sharing similar predictive distributions, organized within a natural simplex structure. This perspective unifies a wide range of existing supervised and less-supervised objectives and provides a principled explanation for commonly used regularization schemes. Furthermore, we derive practical loss objectives that approximate this structure and demonstrate their effectiveness on standard benchmarks. Ultimately, our framework offers a geometric lens to understanding representation collapse and it establishes a mathematical system for regularization strategies to be used to ensure high-entropy, informative embeddings in modern self-supervised models.
cc: @ylecun
1
6
986
May 6
🚨New paper 🚨
WorldJen: An end-to-end multi-dimensional benchmark for generative videos,
See theard for details and links👇
Feedback is welcome.

Video AI benchmarks are broken.
VBench requires 6,230 videos per model eval. Scores cluster near the ceiling.
Yes-bias makes every model look good. Rankings don't match what humans prefer.
We built WorldJen to fix this. 🧵
2
164
MoonMath.ai retweeted

Apr 29
We have a problem with video/world models. Let me explain what's wrong, and how does it provides a context to Fal new WMA:
First, the state of open source video diffusion models (VDMs):
The best open source video model is currently LTX-2 and it's ranked ~#40 according to AA. There are in general very few open source models outside of academia.
While with LLMs the gap between open and close has mostly collapsed, with VDMs we are talking, IMHO, at least 1y gap. We need DeepSeek for video to come and save us - because almost no frontier lab is open sourcing their models.
Why this gap between LLMs and genreative media? could be multiple reasons - Data availability (much hard to get internet scale high quality video), training cost (order of magnitude more expensive), HW (give me Vera Rubin), model arch stability, Evals maturity etc..
What does it have to do with Fal? Given these conditions, Fal became a pipe to serve Google Veo3 and other closed source model. This is nice on paper and good for traffic, but Google can also just serve directly. There are not enough open source models for Fal to optimize and run on their GPUs (much higher margin) so they created this product, hopefully this will motivate AI labs to give part of the infrastructure to infra experts like Fal

Announcing World Model Accelerator, fal's new product: fal.ai/wma
We've spent years building the inference layer for generative media. In 2023, we shipped 30 FPS, low-latency, action-controlled diffusion APIs, years before anyone else. Fast forward to today and we've been powering foundational model companies across image, video, real-time speech-to-speech and action-controlled world models.
Now we're opening it up. World Model Accelerator is the system behind it all. Our in-house inference engine hits SOTA performance on Hopper and Blackwell for Diffusion Transformer workloads, both causal and bi-directional. Built on fal Serverless, it scales seamlessly from 1 GPU to 1,000 . This is the same platform that's been running real workloads, at scale, for years.
A new WebRTC gateway optimizes latency between users and GPUs (routing requests to the closest region), built on the same infra that powers our real-time speech workloads. And direct access to the fal Marketplace puts your model in front of enterprises spending hundreds of millions on generative media, with a real co-selling motion behind it. This is the infrastructure layer for world models.
1
6
703


MoonMath.ai retweeted
Apr 13
Some time ago, I had the idea to port NVIDIA Physical AI stack to AMD. The motivation was to improve hardware diversity and enable world models and VLAs to run beyond a single ecosystem.
We started with NVIDIA Cosmos Predict 2.5-2B. Porting wasn’t trivial: these models are deeply optimized for NVIDIA’s stack. We used this as an opportunity to apply our ROCm kernels.
The results were surprising:
Both encode and diffusion run faster on AMD Instinct MI300X vs. NVIDIA H200 (FA3) and we still saw significant headroom for further optimization.
Quality is unchanged across modalities (validated with WorldJen)
To be clear, this is no luck. We have deep experience with diffusion models and AMD GPUs. But this just gives us a good opportunity to get closer to a true hardware-to-hardware comparison, as we work with less software abstractions than usual. Just to give an example, on AMD, memory instructions are async with a hardware queue of ordered pending instructions, enabling concurrent load/store with compute without warp specialization. Bottom line: there are real architectural advantages on AMD, if you take the time to work with the hardware.
Note, we did tradeoff ~20% higher memory usage,
That being said, AMD has more to give to begin with :)
in the coming weeks:
AMD versions of Cosmos Transfer and GR00T, an even faster version of Cosmos Predict, and open-sourcing an attention kernel faster than AITER v3 (which is closed-source for some reason? cc: @AnushElangovan )
12
33
218
36,535
Apr 7
Third project we’ve published with AMD support (see LiteLinear and Bria). Hardware is already competitive

Cosmos-Predict2.5-2B Inference
NVIDIA H200 vs AMD MI300X
moonmath.ai/posts/cosmos-amd…

1
5
500
MoonMath.ai retweeted
WJ is VLM-based evaluation for video models.
Research (paper soon): moonmath.ai/posts/introducin…
SDK/CLI: moonmath.ai/posts/speed-and-…

1
1
3
512
Apr 2
High performance benchmarks for video & world models. worldjen.com
*made with @storynote_ai
2
6
678
Apr 1
how long each layer in the transformer forward of LTX-2 takes
Mar 31
The community invested enormous efforts in optimizing attention, but the large `nn.Linear` layers that surround attention? Largely untouched!
Introducing LiteLinear: a drop-in video DiT acceleration that compress nn.Linear layers via calibration-aware low-rank decomposition quantization. Targets both FFN and attention projection linears (Q/K/V/O) without retraining
We are releasing LiteLinear support for both @nvidia Hopper and @AMD Instinct, together with a proof of concept on @Lightricks LTX-2 FFN:
22.5% faster transformer compute
11.5% peak memory reduction
7.6% faster end-to-end inference
Blog: moonmath.ai/posts/litelinear…
Code: github.com/moonmath-ai/LiteL…
4
188
MoonMath.ai retweeted
Mar 31
It’s been a busy month 😅
check out our latest work - LiteLinear
Mar 31
The community invested enormous efforts in optimizing attention, but the large `nn.Linear` layers that surround attention? Largely untouched!
Introducing LiteLinear: a drop-in video DiT acceleration that compress nn.Linear layers via calibration-aware low-rank decomposition quantization. Targets both FFN and attention projection linears (Q/K/V/O) without retraining
We are releasing LiteLinear support for both @nvidia Hopper and @AMD Instinct, together with a proof of concept on @Lightricks LTX-2 FFN:
22.5% faster transformer compute
11.5% peak memory reduction
7.6% faster end-to-end inference
Blog: moonmath.ai/posts/litelinear…
Code: github.com/moonmath-ai/LiteL…
1
6
336
Mar 31
The community invested enormous efforts in optimizing attention, but the large `nn.Linear` layers that surround attention? Largely untouched!
Introducing LiteLinear: a drop-in video DiT acceleration that compress nn.Linear layers via calibration-aware low-rank decomposition quantization. Targets both FFN and attention projection linears (Q/K/V/O) without retraining
We are releasing LiteLinear support for both @nvidia Hopper and @AMD Instinct, together with a proof of concept on @Lightricks LTX-2 FFN:
22.5% faster transformer compute
11.5% peak memory reduction
7.6% faster end-to-end inference
Blog: moonmath.ai/posts/litelinear…
Code: github.com/moonmath-ai/LiteL…
2
7
677
Mar 26
WorldJen is a high-performance benchmarking stack for video models
Today we’re releasing the WJ SDK CLI 🚀
Run fast, reproducible evals to compare checkpoints and rank against other models
Get started:
PyPI: pypi.org/project/worldjen/
Blog: moonmath.ai/posts/speed-and-…
Evaluate LTX2 on your Mac: docs.worldjen.com/tutorial-l…
1
9
1,311
MoonMath.ai retweeted

Mar 25
Making models run fast at inference requires optimizing the entire AI stack.
It was great partnering with MoonMath to take @bria_ai_ 's Fibo to the next level of speed. Unlike standard models, Fibo consists of a Reasoner (VLM) and a Renderer (Flow Matching), requiring both to be optimized at the algorithm, deployment, and kernel levels.
And most importantly it was great to work with @moonmathai
Read more in the new blog post
2
6
23
1,116
MoonMath.ai retweeted
Mar 25
We accelerated Fibo on Hopper, Instinct & DGX Spark (Blackwell)!
Awesome model and awesome team.
1
4
523