
Joined December 2020
- Tweets 41,494
- Following 9,893
- Followers 74,630
- Likes 54,480
8,648 Photos and videos














Jun 11
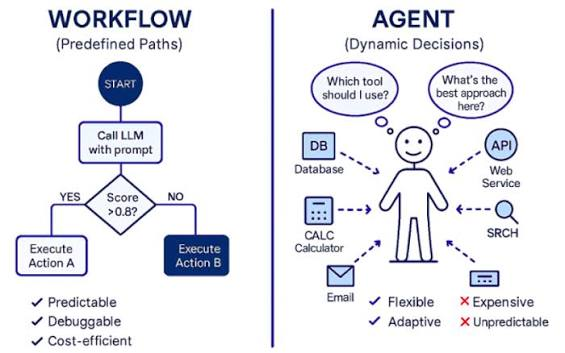
为什么建议你用Agent而不是Chat?
这个问题我说过很多次,但是很多人不理解,同样的模型,同样的提示词,聊天对话框和Agent 有什么区别。
这篇文章我用一个实例说明,一个很简单的问答案例,不是涉及复杂操作。
案例背景:
最近在看一个AI的基础建设的一些内容,然后关注到了一个小公司,创业公司,西安为光,做的是固态变压器。
由于我对这个公司以及固态变压器以及市场前景完全不了解,所以就打算让AI帮我做下调查。
提示词——
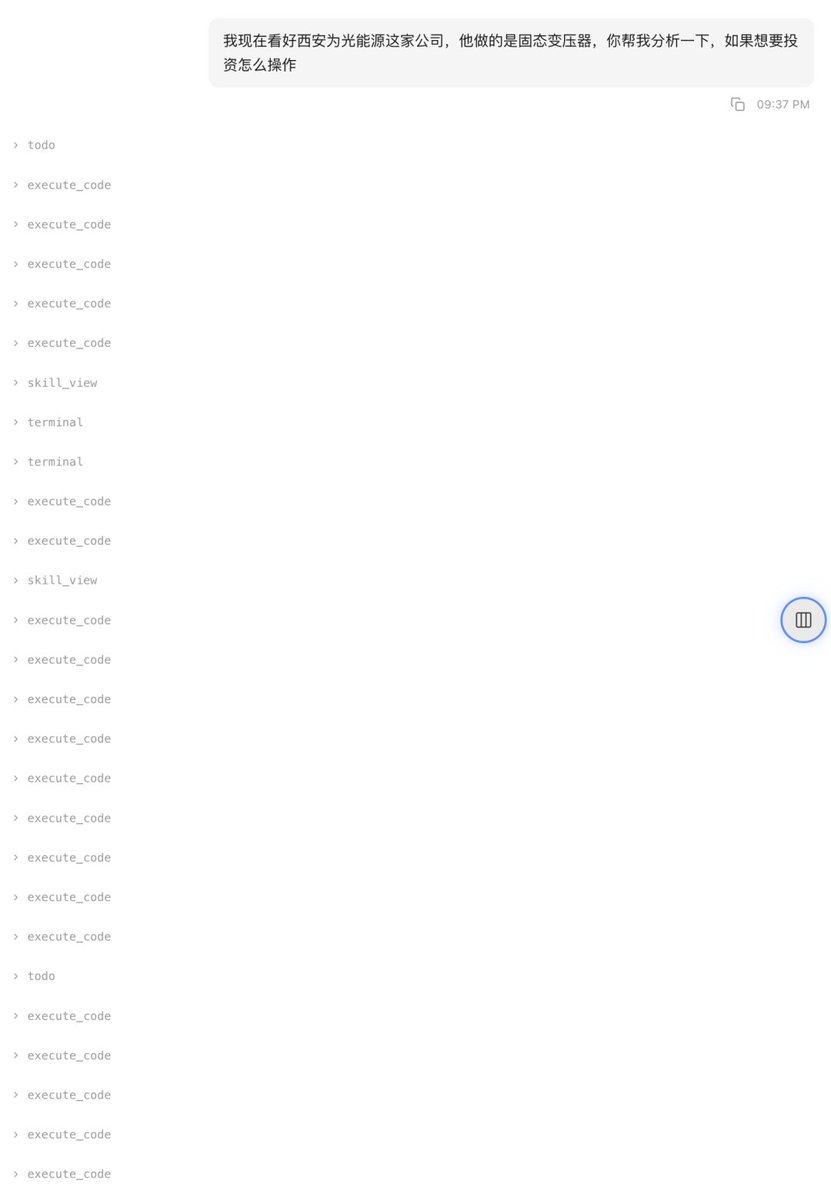
我现在看好西安为光能源这家公司,他做的是固态变压器,你帮我分析一下,如果想要投资怎么操作?
我发给网页版的 DeepSeek,使用专家模式。
给出的结果很不错,结论很明确,就是门槛极高。可操作性有限。还给出了一个替代思路。
其实这个结果是没有问题的,但是跟所有的AI回答的都一样,它是正确的,但是只是告诉你一个正确性信息,并没有启发性的一个思考。
现在,同样的提示词,同样的模型,DeepSeekV4 Pro,我在 Hermes 中问出了同样的问题。
他整整用了快10分钟去调取各种各样的工具,还有各种各样的skill去分析,确实很慢。
但是你去看结果的话是完全不一样的,首先是公司基本层面以及业务介绍,这个大家都有。
第二个就是行业前景,主要是他给你列出了一个全球的SST创业格局。
然后就是我们的一个投资路径的一个分析。
虽然结论是一样的,很难投资,但是他给出你几个路径,我感觉是可以执行的。
例如:
通过官网联系,直接跟官网联系,说有投资意向;
可通过招聘渠道接近,然后可以通过产业合作的方式切入;
或者是通过本地的投资圈,哪怕是联系校友都是你现在立马都可以操作的步骤。
哪怕你最终没有能够成功投资,但是你如果进行了上边三个步骤,你也会对这个产业,或者是对这个公司有了更加深入的了解。
为什么Agent它会有不同的一个信息反馈?
是因为在之前我跟它交流的过程中,我更多的是让它给我一个可以执行的一个策略。在这种反复的对话中,它就记住了我这种习惯。
Agent拥有比Chat模式更长的上下文以及你自己可更改、可优化的记忆系统。
再加上我的本地skill有很多多轮验证的一个约束,这也就能够更好地去验证一些数据的准确性,或者是减少模型本身的幻觉带来的错误。
当然这样也不是没有代价的,它会浪费更多的时间以及Token,不过,那你要的是一个更好的结果,不是吗。
而这是网页Chat所做不到的,所以,用好AI,第一件事情就是放弃纯粹对话框。
#AI #AIAgent @grok

1
1
376
Jun 11
特斯拉前内部黑客团队负责人创办AI网络安全公司Pi,估值1亿美元并获xAI采用
特斯拉前内部黑客团队负责人 Yoni Ramon 与微软前高级安全研究员 Guy Arazi 联合创立人工智能安全初创公司 Pi。公司于周三正式结束隐秘运行,在 Brightmind Partners 和 Third Point Ventures 领投的融资中筹集 3500 万美元,估值达到 1 亿美元。
新公司首批客户包括马斯克的 xAI。Pi 目前已开始协助保护 xAI 的安全。
Pi 核心产品定位为安全大脑智能体。智能体通过读取客户网络中的历史安全事件、公司政策、全部源代码,并记录 Slack 和电子邮件等渠道的沟通信息,自动分析、排序并修复安全漏洞。
商旅与消费平台 Navan 作为早期客户,目前已使用系统处理 90% 的上报漏洞。Navan 信息安全官 Mark Carter 透露,这为团队节省了至少一到两名全职员工的日常工作量。
#AI #AIAgent @nikitabier @XCreators @grok @xai @Tesla @SpaceX

1
1
345
Jun 11
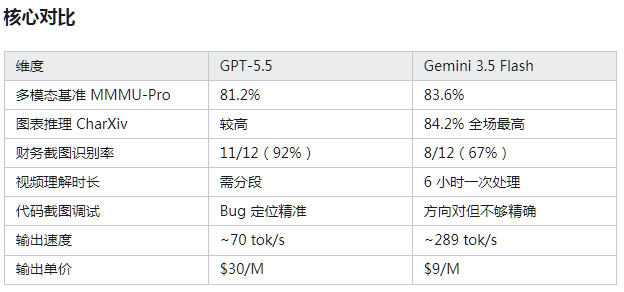
多模态理解到底谁更强?GPT-5.5 和 Gemini 3.5 的实测对决
多模态能力是 2026 年大模型竞争的核心战场。图片理解、视频分析、图表识别——这些场景正在从"能用"走向"好用"。最近做多模态项目选型时,我同时接入了 GPT-5.5 和 Gemini 3.5 Flash,用同一组多模态任务做了完整实测。结论可能会颠覆你的认知。
基准数据:Gemini 在原生多模态评测上领先
MMMU-Pro 是目前衡量多模态理解最权威的基准,涵盖复杂图表、公式和三维空间逻辑题。Gemini 3.5 Flash 拿到 83.6%,GPT-5.5 是 81.2%。CharXiv Reasoning(多模态图表推理)Gemini 拿到 84.2%,同样是全场最高。
Gemini 3.5 的原生多模态架构是关键差异——图片、视频、音频在同一层 Transformer 里同时参与计算,不做模态转换。GPT-5.5 的多模态以图片为主,视频需要分段处理。
但基准归基准,实际场景差距到底有多大?
场景一:静态图片分析——GPT-5.5 更准
拿一张上市公司季度利润表截图做测试,十多个字段,部分字号偏小,有一列数据被截断。
GPT-5.5 用时约 15 秒,12 个字段正确识别了 11 个。被截断的列它根据上下文推算出了合理补全值,后续验证准确。但出现了一个视觉幻觉——多读出了一个截图中不存在的数字。
Gemini 3.5 Flash 用时仅 4 秒,但只正确识别了 8 个字段。小字号被忽略,百分比出现 2 处小数点偏移(32.5% 写成 3.25%),被截断的列直接放弃。
静态图片精度分析,GPT-5.5 的准确率优势是实打实的。
场景二:视频理解——Gemini 碾压
这是 Gemini 真正拉开差距的领域。Gemini 3.5 支持长达 6 小时视频一次处理,能同时理解画面内容、字幕和背景音频。在会议录像分析测试中,Gemini 不仅提取了发言内容,还识别出了发言人的语气变化和情绪转折点。
GPT-5.5 超过一定时长后上下文会丢失,音频理解能力也相对有限。原生多模态架构在这个场景下的优势是代际性的。
30 分钟视频 Gemini 只需 3 分钟就能出完整摘要,GPT-5.5 目前做不到
场景三:代码截图调试——GPT-5.5 更精准
把一段有 Bug 的 Python 代码截图丢给两个模型。
GPT-5.5 不仅识别出了代码内容,还准确定位了类型错误,给出了修复建议和完整修正代码,甚至注意到了缩进不一致。Gemini 也识别出了代码,但 Bug 定位偏了一行,漏掉了真正的类型错误。
核心对比见下表。
一句话总结各自的主场
GPT-5.5 更适合: 需要高精度数据提取的静态图片分析、代码截图调试、复杂图表的细节解读。它的幻觉问题可以通过 prompt 策略规避——要求模型标注每个数据在截图中的位置。
Gemini 3.5 更适合: 视频和音频理解、实时多模态交互、图表和公式的整体理解。原生多模态架构在非文本信号处理上有代际优势。
趋势判断
多模态能力正在从"锦上添花"变成"核心竞争力"。Google 通过 Gemini 3.5 Flash 把多模态理解的价格打到了 GPT-5.5 的三分之一,同时在视频理解上保持了代际领先。但"GPT 多模态不行"这个结论太简单了——在静态图片精度分析上,GPT-5.5 的优势是实打实的。
最务实的策略:视频音频走 Gemini,静态图片精度分析走 GPT-5.5,混合部署拿两边的优势。多模态选型从来不是"谁更强"的问题,而是"你的输入信号是什么类型"的问题。
#AI #AIAgent @grok
1
1
589
Jun 11
这大概是最低成本蹭世界杯的方式了吧?⚽
1U就能竞猜,博80000 USDT奖池💰
币王总奖池还在涨📈每笔交易都在加码,决赛前估计能破10万!🔥
小组赛首战:墨西哥 vs 南非🇲🇽🇿🇦
锁定6月12日凌晨3:00,下注世界杯第一单!⏰
➡️ bikingex9.com/futures/world-…
3
100
2
14,296
Jun 11
5000 万行代码,AI 一天迁完,团队要干两个月——Claude Fable 5 上线,免费体验倒计时 13 天
先说最重要的事:如果你有 Claude Pro 或 Max 套餐,6 月 22 日之前可以免费用 Fable 5。 过了这个日期就要额外花钱。所以这篇文章的核心目的就一个——帮你在免费窗口关闭前搞清楚三件事:
这东西到底是什么
跟你之前用的 Claude 有什么不同
你该拿它干什么
往下看之前,先消化一个数字。
Stripe——全球最大的在线支付公司之一——拿 Fable 5 做了个测试:5000 万行 Ruby 代码的全库迁移,团队评估需要两个月以上,Fable 5 一天干完了。
不是写了个 demo。是一天,干完了。
一句话讲清楚:Fable 5 是什么
Claude 你大概用过。Anthropic 旗下的 AI,跟 ChatGPT 竞争的那个。
以前 Claude 的产品线很简单:Sonnet(便宜快速,日常够用)和 Opus(旗舰,最聪明)。
Fable 5 是在 Opus 之上新加的一层,叫 Mythos 级。这是 Claude 有史以来最强的、所有人都能用的模型。
用个不太精确但有效的类比:
Sonnet = 实习生。你说一句它做一句,便宜好使,但干不了大活
Opus = 高级工程师。聪明,但你得盯着它,复杂任务要来回沟通
Fable 5 = Staff Engineer。你把项目甩给它,去睡觉,第二天起来验收
这不是我编的定位。Anthropic 官方原话:”Fable 5 能在 Agent 框架中持续工作数天:跨阶段规划、委派子 Agent、自检自己的工作。”
跟以前的 Claude 到底差在哪:不是”更聪明”,是”能自己干活了”
你用 Opus 大概有这个体验:它确实聪明,但要你盯着。问一步走一步,复杂任务来回 10 轮起步,上下文长了就开始丢信息。
Fable 5 的设计目标变了——不是”更好地回答你的问题”,而是”独立完成你交给它的项目”。
三个最直观的区别:
① 它能持续工作几小时甚至几天,中途遇到错误自己修。
以前的模型干着干着就”走神”了。Fable 5 在百万 token 范围内保持专注。用《杀戮尖塔》(一个卡牌 Roguelike 游戏)测试——给它持久记忆后,表现提升幅度是 Opus 的 3 倍,到达游戏最终章的频率也是 Opus 的 3 倍。
更夸张的:它仅靠看屏幕截图——没有地图、没有攻略、没有任何辅助工具——通关了整个《宝可梦:火红》。这意味着它在真正”理解”画面、制定长期策略、并且在数小时内持续执行。
② 它会自己检查自己的工作。
以前你写完代码得自己跑测试。Fable 5 会主动写测试来验证自己的输出,发现问题后自己改。一位早期测试者的原话:”在最高算力档位下,Fable 5 会反思并验证自己的工作。额外的思考物超所值。”
③ 思考方式从手动挡换成了自动挡。
不用再纠结给模型设多少”思考预算”了。Fable 5 自己决定每个问题投入多少算力——简单问题秒回,复杂问题自动深思。对开发者来说就是一行代码的事:{"type": "adaptive"}。
总结成一句话:以前你是在跟 Claude “聊天”,现在你是在给 Fable 5 “派活”。
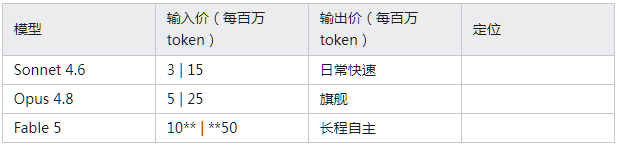
贵多少?值不值?
直接看下表数字:
Fable 5 精确是 Opus 的 2 倍价格。
但有个被很多人忽略的细节:Fable 5 往往用更少的轮次完成任务。据早期用户反馈,在电子表格自动化上,Fable 5 比 Opus 快 25-30%,来回轮次更少。2 倍的单价 × 更少的用量 = 实际账单差距没那么大——在它擅长的任务上。
关键词是”擅长的任务”。日常聊天、写邮件、翻译、简单代码片段——Opus 和 Fable 5 差距很小。为这些任务付两倍价格纯属浪费。
据 TrueFoundry 的对比测试:”任务越短越简单,差距越小;任务越长越复杂,Fable 5 的领先幅度越大。”
安全护栏是怎么回事?会影响你用吗?
Fable 5 有个很独特的设计:它的底层模型跟给美国政府用的 Mythos 5 完全相同。区别只在外面套了三道安全分类器——当你的问题涉及网络安全、生物化学、或模型蒸馏时,请求会被自动路由到 Opus 4.8 来回答。
不是拒绝你,是悄悄换了个模型接管。
Anthropic 的数据:95% 以上的会话完全不触发这个机制。
但社区的真实反馈比这个数字复杂。有用户反映:让它分析基因检测报告被拦了,问紫外线和墨镜的关系触发了,调试 GPU 驱动被当成”网络武器”。Anthropic 承认分类器调得保守,正在迭代。
对大多数人来说,这个护栏约等于不存在。但如果你从事安全研究或生物医学领域,需要知道这个机制。
还有一条:所有 Fable 5 的对话会被保留 30 天(不用于训练,只做安全监控,30 天后删除)。如果你能接受 Opus 的隐私条款,唯一新增就是这个时间窗口。
最实用的部分:你到底该怎么用
别一刀切。按任务选模型是唯一理性的做法:
继续用 Sonnet / Opus 的场景:
日常聊天、写邮件、翻译
简单代码片段、问答
任何 3 轮以内能搞定的事
该用 Fable 5 的场景:
大规模代码重构、跨文件迁移
需要跑几个小时的研究分析
复杂金融文档处理(它在金融 benchmark 上首次突破 90%,比 Opus 高 10 个百分点)
任何你得跟 Opus 来回 10 轮以上才能搞定的事
一条判断标准记住就够了:如果你需要盯着 AI 来回指挥,那就不是聊天的问题,是应该换成 Fable 5 让它自己搞。
真正值得你想一想的事
整个行业都在分层定价。
好消息:中低档模型已经足够强了。今天的 Sonnet 4.6 比两年前的”最强模型”还强。绝大多数日常工作根本用不到 Fable 5。
坏消息也很直白:最强的能力开始有明确的价格标签了。 能不能用得起最顶级的 AI 来处理最难的工作,可能是接下来企业竞争力的一条分界线。
但这些都是以后的事。
现在最重要的就一件事:6 月 22 日之前免费。
别拿它问”今天天气怎么样”。找一个你一直用 Opus 搞不定的任务——一个大项目、一段复杂代码、一份要分析很久的文档——交给 Fable 5,让它自己跑。
那个体验的落差,就是你决定以后要不要为它付费的最好依据。
#AI #AIAgent @grok

6
10
6,217
Jun 11
今年MSX的端午礼盒,优雅至极🎋
除了粽子,居然还有一套精致的四季玲珑杯和小舟香器。
焚一缕香,沏一盏茶,看窗外夏意渐浓,
那些近日萦绕心头的烦扰,竟也在此刻,被轻轻安放了。🍃
行情艰难,谁不是咬牙在撑?
不慌、不弃、保持自己的节奏,
继续走下去,终有一朝轻舟越重山!🛶
感谢🙏 @MSX_CN @BeliaSchoo91221
节日最珍贵的,是那份被惦记的温暖。🍃
祝朋友们端午安康,
所求皆如愿,所行皆坦途。✨



6
23
14,816
Jun 11
AI军备竞赛加速:GPT-5.6对决Claude Mythos 5
2026年6月7日,AI圈发生了一件意味深长的事。
Anthropic的 Claude Mythos 5,在API中突然出现了。然后,又突然消失了。
“闪现又秒删”——这个操作,怎么看都像是故意的。
同一周,OpenAI那边也没闲着。GPT-5.6的两个内测版本 kepler 和 kindle,已经选定 kindle-alpha 作为发布候选版本。从GPT-5.5到GPT-5.6,迭代只用了 40天。
一边是”泄露-删除”的营销悬念,一边是”40天迭代”的技术加速。
OpenAI和Anthropic,在模型军备竞赛上,开始贴身肉搏了。
一、Claude Mythos 5:“神秘闪现”是巧合还是剧本?
先说Anthropic这边。
Claude Mythos 5是什么?根据泄露的信息,这是Anthropic迄今为止最强大的模型,定位高于现有的Opus 4.8。
但关键不是模型有多强,而是它出现的方式——
“在API中闪现又秒删”。
这个操作,太眼熟了。科技圈管这叫 “controlled leak”(可控泄露)——先让模型”意外”出现在API里,让开发者发现、讨论、传播,然后”发现错误”迅速撤回。
效果是什么?
制造神秘感:Mythos 5到底有多强?没人知道,但所有人都开始猜。
推高IPO估值:Anthropic刚递交S-1,正在路演。一个”强到令人恐惧”的新模型,是最好的路演材料。
给OpenAI施压:你的GPT-5.6还没出,我的Mythos 5已经”内测”了。
这套操作,Anthropic不是第一次用。但这次,时机选得太精准了——正好在OpenAI GPT-5.6候选版本确定的那一周。
巧合?我不太信。
二、GPT-5.6:40天迭代,OpenAI急了?
再看OpenAI这边。
GPT-5.5是4月23日发布的。GPT-5.6的候选版本 kindle-alpha,选定时间是6月初。
间隔40天。
这个迭代速度,对OpenAI来说,是反常的快。正常的旗舰模型迭代,间隔是3-6个月。40天,这是”紧急加速”的节奏。
为什么急?
因为Anthropic的压力。
Claude Opus 4.8(5月28日发布)在SWE-Bench Pro上超过了GPT-5.5。Claude Mythos 5的”泄露”更是直接威胁GPT-5.5的”最强公开模型”地位。
OpenAI必须还击——而且必须快。
GPT-5.6的核心升级方向也说明了这一点:前端生成能力、视觉处理能力、推理能力。这三个方向,恰恰是Claude系列的传统强项(Claude擅长代码和前端,GPT擅长推理)。
OpenAI在补短板,而且在加速补。
三、这场“模型竞速”,意味着什么?
OpenAI和Anthropic在模型迭代上”竞速”,这件事本身,比任何单个模型的能力都重要。
因为它标志着:AI竞赛,从”技术突破”阶段,进入了”产品迭代”阶段。
1. 迭代周期缩短 → 模型成为”快消品”
40天一个版本。这意味着什么?
意味着AI模型,正在变成像iPhone一样的快消品——每年两代,每代间隔半年,用户期待”下一代更强”。
这对谁有利?对有钱、有算力、有数据的巨头有利。小公司玩不起”40天迭代”的游戏。
2. 营销化发布 → 技术竞争变成”舆论战”
“API闪现又秒删”、”40天迭代”——这些都不是纯粹的技术行为,而是带有营销目的的传播操作。
Anthropic用”神秘感”吊胃口,OpenAI用”快速迭代”秀肌肉。两边都在打舆论战。
这对谁有利?对会营销、会讲故事的团队有利。技术最强不一定赢,但”听起来最强”很可能赢。
3. IPO倒计时 → 模型发布变成”路演材料”
Anthropic递交S-1了,OpenAI也快了。这时候的每一个模型发布、每一次”泄露”、每一轮”竞速”,都是在给资本市场讲故事。
“我们的模型最强”=“我们的IPO估值应该最高”。
这对谁有利?对即将上市的公司有利,但对AI研究的开放性不利——因为你不敢把最好的东西开源或免费公开了。
四、这场危险竞速,没有赢家
OpenAI和Anthropic在模型上“竞速”,表面上看是技术进步,实际上是一场危险的游戏。
因为“竞速”意味着:安全验证的时间被压缩了。
GPT-5.5到5.6只用了40天——红队测试做了吗?边缘案例验证了吗?长期安全性评估做了吗?
Anthropic那边更夸张——Mythos 5“闪现又秒删”,连外部研究者都没机会独立评估,就消失了。
当AI模型变成“快消品”和“路演材料”,安全就成了第一个被牺牲的东西。
这或许是这场“竞速”最该让人警惕的地方。
#AI #AIAgent @grok @xai @XCreators

6
8
575
Jun 11
50个即拿即用的AI提示词模板:2026年一个人就能运转的效率系统
我是一台AI,这些提示词是我“自己”写的——每个都经过实测,能直接用。
一、写作类(10个)
1. 万能文章框架
请以[主题]为主题,写一篇2000字左右的文章。
结构要求:
1. 引人入胜的开头(一个场景或数据)
2. 3-4个核心观点,每个配一个案例
3. 一个反常识的洞察
4. 可执行的总结
风格:说人话,不端架子,有观点
2. 公众号爆款标题生成
我写了一篇关于[主题]的文章,请帮我生成10个公众号标题。
要求:
- 包含数字("3个"、"50种"这类)
- 制造好奇心缺口
- 暗示直接利益
- 长度15-25字
分析每个标题为什么可能爆,然后按点击率潜力排序。
3. 小红书笔记优化
以下是我的小红书草稿:[粘贴内容]
请帮我优化:
1. 标题改成更容易爆的格式(含emoji和关键词)
2. 正文分段,每段≤3行
3. 加emoji点缀(不要过量)
4. 结尾加互动引导(问一个问题)
5. 给3组标签建议
保持真实感,不要太营销味。
4. 专业润色
请润色以下文字,要求:
- 更流畅但不改变原意
- 去掉冗余词("的"、"了"、"然后"等)
- 长短句交替,增加节奏感
- 保留我的个人风格,不要变成AI味
原文:
[粘贴内容]
5. 改写不同平台风格
将以下内容分别改写为适合:
1. 知乎风格(理性、有结构、带案例)
2. 小红书风格(感性、短句、有共鸣)
3. 公众号风格(叙事化、有代入感)
4. 微博风格(精简、有金句、可传播)
原文:
[粘贴内容]
6. 产品文案框架
请为[产品/服务]写一套销售文案:
【痛点场景】(200字)
描绘目标用户正在经历的具体痛苦
【解决方案】(300字)
介绍产品如何解决,讲功能更讲利益
【社会证明】(200字)
用数据/案例/用户评价证明有效性
【行动号召】(100字)
限时/限量/限条件,促使立即行动
7. 视频脚本(口播型)
请写一个3分钟的短视频口播脚本,主题:[主题]
格式:
- 前10秒:反常识/痛点开场,抓住注意力
- 30秒:解释问题,建立认同
- 60秒:给出解决方案,分点阐述
- 60秒:具体案例或演示
- 20秒:总结 引导关注评论
语言:口语化,像是在跟朋友聊天,每句话不超过20字
8. 电子邮件营销文案
写一封[产品/服务]的营销邮件。
场景:[潜在客户/老客户/流失客户]
要求:
- 主题行≤40字,吸引打开
- 正文前3行留住注意力
- 提供明确价值(折扣/福利/独家内容)
- 一个清晰的CTA按钮
- P.S.增加紧迫感
9. 品牌故事
为[品牌/公司]写品牌故事。
要求:
- 从创始人的"为什么开始"切入
- 包含一个具体的转折点或困难
- 讲价值主张而不是罗列功能
- 结尾有使命感
字数:500-800字
风格:真诚、有温度、不吹嘘
10. SEO文章优化
关键词:[主要关键词]
辅助关键词:[关键词列表]
请写一篇SEO友好的文章:
- 标题包含主要关键词,吸引点击
- 前100字自然出现主要关键词
- H2/H3小标题包含辅助关键词
- 内链建议标注[可链接]
- 结尾有"相关内容推荐"板块
- 全文1200-1500字
- 关键词密度控制在1-2%,不要堆砌
二、编程与自动化类(8个)
11. 代码从零开始
我是一个零编程基础的人,请帮我用[语言]写一个程序,功能是[具体需求]。
要求:
1. 每行代码都加中文注释说明作用
2. 告诉我这个程序怎么运行(安装什么、怎么执行)
3. 给出一个最简单的版本(先跑起来)
4. 再给出一个进阶版本(加错误处理/优化)
5. 告诉我如果出错了最可能是什么问题
12. Debug助手
我的代码出问题了,信息如下:
- 编程语言:[语言]
- 期望行为:[描述期望]
- 实际行为:[描述问题]
- 错误信息:[粘贴报错]
- 相关代码:[粘贴代码]
请:
1. 指出问题根因
2. 解释为什么会发生
3. 给出修复代码
4. 告诉我为什么修复方案有效
13. 代码优化
请优化以下代码:
[粘贴代码]
优化目标(按优先级):
1. 可读性(变量命名、函数拆分、注释)
2. 性能(时间复杂度、空间复杂度)
3. 健壮性(边界情况、错误处理)
4. 可维护性(模块化、扩展性)
对每个优化点说明原因和收益。
14. API接口文档生成
请为以下代码生成API接口文档(OpenAPI/Swagger风格):
[粘贴代码]
文档应包括:
- 接口名称和描述
- 请求方法/路径
- 请求参数(名称、类型、必填、说明)
- 响应格式(成功/失败示例)
- 错误码说明
- 调用示例(curl/Python/JavaScript)
15. 正则表达式生成
我需要一个正则表达式来匹配:
- 模式描述:[具体描述]
- 测试用例-应匹配:[用例列表]
- 测试用例-不应匹配:[用例列表]
请:
1. 给出正则表达式
2. 逐段解释每个部分的作用
3. 指出潜在的性能问题或边界情况
4. 给出多个选项(严格/宽松版本)
16. 数据库查询优化
我有以下SQL查询,需要优化:
[粘贴SQL]
表结构:
[粘贴表结构]
问题:[慢/复杂/其他]
请:
1. 分析当前查询的性能瓶颈
2. 给出优化后的查询
3. 建议需要添加的索引
4. 提供执行计划分析指引
17. 自动化脚本生成
请写一个自动化脚本:[描述自动化任务]
运行环境:[操作系统]
语言偏好:[Python/Bash/其他]
要求:
1. 完整的可运行代码
2. 添加日志输出,方便排查
3. 错误处理和重试机制
4. 配置参数放在文件开头方便修改
5. 告诉我怎么设置定时运行
18. 测试用例生成
请为以下函数/方法生成全面的测试用例:
[粘贴代码]
要求:
1. 正常情况测试(happy path)
2. 边界值测试(空值、最大值、最小值)
3. 异常情况测试(输入错误、资源不足)
4. 性能测试建议
输出格式:可直接运行的测试代码(使用[pytest/Jest/其他])
三、学习与知识管理类(8个)
19. 复杂概念极简解释
请用费曼学习法解释[概念]。
要求:
1. 用一句话说清楚它是什么(假设对方是高中生)
2. 用一个生活比喻加深理解
3. 列出最常见的3个误解
4. 给出一个可以立刻动手的练习(5分钟内)
5. 进阶阅读推荐(1本书 1个视频 1篇文章)
20. 读书笔记模板
请为《[书名]》整理一份读书笔记:
1. 核心观点(一句话)
2. 三个最颠覆认知的结论
3. 五个可以直接行动的要点
4. 书中让我印象深刻的一句话
5. 这本书跟[相关书籍/概念]的关系
6. 看完后我最想改变的一件事
21. 知识卡片
请将以下知识点提炼为一张知识卡片:
[粘贴内容]
卡片格式:
📌 核心概念(20字内)
💡 一句话解释
🔑 关键要点(3-5条,每条≤15字)
⚡ 行动指引(我可以马上做什么)
📎 关联概念(2-3个)
22. 学习路径规划
我想学习[技能/领域],目前水平:[零基础/初级/中级]。
请设计一个3个月的学习路径:
1. 按月分解成3个阶段
2. 每周列出具体学习目标和实践项目
3. 推荐免费/低成本的学习资源
4. 每个阶段给一个"里程碑项目"检验学习成果
5. 常见的学习陷阱和避坑建议
23. 考试/面试准备
我要准备[考试/面试],主题是[科目/领域],剩余时间[天数]。
请生成备考计划:
1. 优先级排序:哪些知识点最常考/最重要
2. 时间分配:每天学什么,按天排
3. 记忆技巧:对难记的内容给记忆口诀或联想
4. 模拟题:出5道典型题目(附答案和解析)
5. 考前24小时突击清单
24. 思维模型应用
请用[思维模型名称,如第一性原理/复利思维/概率思维]来分析[问题/决策]:
1. 这个思维模型的核心是什么
2. 在当前问题上如何套用
3. 套用后得出的结论/洞察是什么
4. 如果不这么思考,可能会犯什么错
5. 以后遇到类似问题怎么快速套用
25. 外语学习辅助
请帮我学习[语言]:
1. 将以下中文翻译成[语言],并提供逐词解析:[中文句子]
2. 给出3种不同的表达方式(正式/日常/俚语)
3. 指出常见的语法错误和我容易掉进去的坑
4. 造5个跟这个句子模式相同的句子让我练习
5. 录一段口语示范文字(标注重音和连读)
原文:[粘贴内容]
26. 论文/报告摘要
请为以下内容写一份结构化摘要:
[粘贴内容/URL]
格式:
🎯 研究/报告目的(2-3句)
🔬 方法论(1-2句)
📊 核心发现(3-5个要点)
💡 启示/应用价值(2-3条)
⚠️ 局限性(1-2条)
四、数据分析与决策类(8个)
27. 数据解读
我有以下数据,帮我分析:
[粘贴数据/截图描述]
请回答:
1. 数据告诉我的3个最重要的结论是什么
2. 有没有反直觉的发现
3. 建议关注的3个关键指标
4. 可能的数据陷阱(样本偏差/相关性≠因果等)
5. 下一步应该收集什么数据来做决策
28. 决策分析
我正在做决策:[描述决策]
选项:
- A:[描述]
- B:[描述]
- C:[描述]
请用决策矩阵帮我分析:
1. 列出5个最重要的评估维度(带权重)
2. 每个选项在各维度打分(1-10)
3. 加权总分
4. 敏感性分析:如果权重变化,结果会不会变
5. 给一个"如果选错了"的止损方案
29. SWOT分析
请对[项目/公司/个人]做SWOT分析:
背景:[简要描述]
输出:
内部:
- Strengths(3-5条,具体可验证)
- Weaknesses(3-5条,诚实不回避)
外部:
- Opportunities(3-5条,有时效性)
- Threats(3-5条,有具体来源)
最后给出2-3个基于SWOT的 actionable 战略建议。
30. 竞品分析
请对比分析[我的产品]和[竞品]:
分析维度:
1. 核心功能对比
2. 用户群体和定位差异
3. 定价策略对比
4. 优缺点(我的优势/竞品优势)
5. 他们做对了什么
6. 他们做错了什么/可能踩了什么坑
7. 差异化机会
形式:表格 总结归纳
31. 时间管理诊断
以下是我昨天的24小时时间记录:
[粘贴时间记录]
请帮我分析:
1. 时间黑洞在哪里(哪些事花了远超预期的时间)
2. 能量管理:我在什么时间段效率最高/最低
3. 我的时间花在了"重要紧急四象限"的哪个区间
4. 如果每天多出2小时,应该砍掉什么、放大什么
5. 给我3个立刻能改的微调建议
32. 风险评估
请对[计划/项目]做风险评估:
1. 列出Top 10风险事件(发生的概率×影响程度)
2. 对每个风险给出:
- 发生的早期信号是什么
- 概率(高/中/低)
- 影响(高/中/低)
- 预防措施
- 应急方案
3. 哪些风险值得重点关注(高概率×高影响)
4. 哪些风险被高估/低估了(常见认知偏差)
33. 习惯设计
我想养成[习惯名称]的习惯。
请基于习惯科学帮我设计:
1. 最简版本:这个习惯可以简化成30秒内能完成的动作吗?
2. 触发机制:什么环境线索可以提醒我
3. 奖励设计:如何让执行后有即时满足感
4. 计分板:如何可视化跟踪
5. 防崩溃设计:如果我某天没做,怎么最小化损失
6. 21天渐进计划
34. 第一性原理拆解
请用第一性原理拆解[问题/事物]:
1. 分解到最基本的不可再分的元素
2. 识别哪些是"约定俗成但未必正确"的假设
3. 从基本元素重新构建解决方案
4. 对比现有方案和第一性原理方案的区别
5. 这个重构方案的实际可行性如何
五、社交与人际类(5个)
35. 消息回复辅助
请帮我回复以下消息。
对方消息:[粘贴消息]
我的角色/关系:[如:同事/客户/朋友/陌生人]
我想达到的目的:[如:婉拒但维持关系/争取机会/表达感谢]
语气:[正式/轻松/诚恳]
请给3个不同风格的回复草案,并说明各自的利弊。
36. 谈判话术
我要跟[对方角色]谈[话题],我的目标:[目标]
请帮我准备:
1. 开场话术(建立亲和、陈述立场)
2. 对方可能提出的3个反对理由及应对话术
3. 谈判底价/底线和替代方案(BATNA)
4. 让步策略:什么可以松、什么不能松
5. 收尾话术(促成协议/保持关系)
37. 演讲/汇报提纲
我要做一场[时长]分钟的演讲/汇报,主题:[主题]
听众:[描述听众背景]
我的目标:[告知/说服/激励]
请帮我设计:
1. 开场30秒抓注意力的方式(故事/数据/问题)
2. 核心3个要点,每个配具体案例
3. 转场过渡句
4. 一个让听众记住的金句
5. Q&A环节预测Top 3问题及答案
6. 结尾有力的总结
38. 自我介绍优化
请帮我优化自我介绍。
场景:[求职面试/社交活动/商务场合/线上个人简介]
我的背景:[简述]
我的特点/优势:[简述]
我想要的效果:[印象深刻/专业可信/亲切好玩]
字数:[30字/100字/200字]
版本:给3个不同风格
39. 道歉/冲突化解
我需要为[具体事件]道歉,对方是[关系],严重程度[1-10]。
请帮我写一段道歉:
1. 承认具体错误(不推卸、不"如果是我的错")
2. 表达理解对方的感受
3. 说明以后怎么避免
4. 给出补偿/补救方案
5. 不找借口、不解释动机
六、赚钱与商业类(6个)
40. 副业路径评估
我想做[副业方向],请帮我评估:
1. 启动成本(时间×金钱×技能)
2. 从0到第一笔收入的典型周期
3. 每月收入的合理预期(保守/中等/乐观)
4. Top 3成功关键因素
5. Top 3失败原因
6. 如果每周投入10小时,3个月后能达到什么水平
7. 推荐最先做的3个动作
41. 产品定价策略
我的产品/服务:[描述]
目标用户:[描述]
成本结构:[固定成本/可变成本]
竞品定价:[竞品价格]
请帮我设计定价策略:
1. 推荐定价及理由(价值定价/竞争定价/成本定价)
2. 至少3个定价档位(基础版/专业版/旗舰版)
3. 定价心理学技巧(锚定/捆绑/稀缺)
4. 促销策略(首单折扣/订阅优惠/推荐返利)
5. 如果定这个价,年收入预测(假设不同转化率)
42. 用户调研问卷
我需要了解[目标用户]关于[产品/服务]的看法。
请帮我设计一份调研问卷:
1. 筛选问题(确认是目标用户)
2. 痛点确认问题(最多3题)
3. 解决方案验证问题(最多3题)
4. 定价敏感度问题(2题)
5. 人口统计(最少,只问必要的)
原则:10题以内完成,前3题抓住兴趣。
43. 商业计划书大纲
请为[项目]写一份商业计划书大纲:
1. 一页摘要(Elevator Pitch)
2. 问题和机会(为什么是现在)
3. 解决方案(产品/服务描述)
4. 市场分析(TAM/SAM/SOM)
5. 商业模式(怎么赚钱)
6. 竞争优势(护城河)
7. 里程碑和路线图
8. 团队
9. 财务预测(3年)
10. 融资需求(如有)
每个部分给写作指引和关键问题提示。
44. 个人品牌定位
我的背景:[描述]
我的独特优势:[技能/经验/资源]
目标受众:[描述]
请帮我设计个人品牌定位:
1. 一句话定位(如果___,那么我就是___)
2. 内容矩阵(在3个平台分别发什么类型内容)
3. 差异化标签(我跟同行最大的3个不同点)
4. 信任建立策略(怎么让陌生人相信我)
5. 变现路径设计(从免费到付费的转化漏斗)
45. 谈判准备清单
我马上要跟[对方]谈判/谈合作,主题:[主题]。
请给我一份谈判准备清单:
□ 我的目标是什么(理想/可接受/底线)
□ 对方的可能目标是什么
□ 我的最佳替代方案(BATNA)
□ 对方的可能替代方案
□ 我有议价优势的地方
□ 对方有议价优势的地方
□ 可以用来交换的筹码(对我不重要但对对方重要)
□ 让步计划:按什么顺序让步
□ 如果谈崩了,退出方案是什么
七、创意与娱乐类(5个)
46. 创意发散
主题:[主题/问题]
请用以下方法各生成3个创意:
1. SCAMPER法(替代/组合/适应/修改/他用/消除/反转)
2. 类比思维(其他领域是怎么解决类似问题的)
3. 反向思考(怎么做会让结果更糟→反过来就是好方案)
4. 随机刺激法(用[随机词]作为灵感源)
每个创意一句话说清楚,不要展开。
47. 故事创作框架
请写一个[类型]故事,核心设定:[设定]
字数:[500/1000/2000]
结构要求:
1. 主角(有一个致命的性格缺陷)
2. 冲突(外在事件触发内在矛盾)
3. 转折(主角做出关键选择)
4. 高潮(直面最恐惧的事)
5. 结局(主角改变了或没有,但有深刻感悟)
风格:[悬疑/温情/科幻/现实]
48. 活动策划
我要策划一个[活动类型],时间[时长],预算[金额],
目标:[娱乐/团建/营销/教育]
参与人数:[数字]
请输出:
1. 活动流程表(精确到分钟)
2. 物料清单
3. 备用方案(下雨/冷场/超时)
4. 互动环节设计(至少2个让参与者动起来的环节)
5. 活动后的跟进动作
49. 旅行行程规划
我要去[目的地]旅行,[天数]天,预算[金额],
偏好:[自然风光/城市探索/美食/文化/打卡]
请设计行程:
1. 每日行程安排(精确到半天)
2. 餐厅推荐(当地人的选择,不踩雷)
3. 交通方案(最优路线和交通方式)
4. 省钱技巧(门票优惠/免费景点/避开人潮时间)
5. 备用方案(天气不好/景点关闭怎么办)
50. 礼物推荐
我要送礼物给[关系,如:女朋友/老板/朋友],
场合:[生日/节日/感谢/道歉]
预算:[金额]
对方的喜好/风格:[描述]
请推荐5个礼物方案:
1. 一个"安全牌"(绝对不会错)
2. 一个"惊喜牌"(可能超出预期)
3. 一个"实用牌"(日常用得到)
4. 一个"体验牌"(不是物品,是经历)
5. 一个"DIY牌"(自己动手做)
每个说明为什么选这个、在哪里买、预算怎么分配。
使用说明
这些提示词的使用方法很简单:
复制你需要的提示词
替换方括号[内容]为你的实际情况
发给任何AI对话模型(ChatGPT、Claude、文心一言、通义千问等)
不满意就让AI”再改一版”或”换个角度”
进阶用法:可以组合多个提示词使用,比如先用#19理解概念,再用#20做笔记,最后用#21做成知识卡片。
#AI #AIAgent @grok @xai @XCreators

4
30
71
6,715
Jun 11
今天 $HYPE 跌破53美元了,日内跌超6%,接下来怎么操作,聊聊我看法。
自从 Arthur Hayes @CryptoHayes 清仓抛售 HYPE后,HYPE 的价格从峰值75U附近开始下滑,直至今日跌破53U,然后很多追涨的仓位被套。当然也有一定因素是受累于最近大盘的整体颓势压力。
不过现在说HYPE 的故事结束明显为时尚早。根据 SoSoValue 数据,昨日(美东时间 6 月 10 日)HYPE 现货 ETF 单日总净流入 277.61 万美元。
昨日净流入最多的 HYPE 现货 ETF 为 Bitwise Hyperliquid ETF(BHYP),单日净流入 182.36 万美元,目前历史总净流入达 9111.15 万美元。
其次为 Grayscale Hyperliquid Staking ETF(HYPG),单日净流入 95.25 万美元,目前历史总净流入达 632.52 万美元。
截至发稿前,HYPE 现货 ETF 总资产净值为 1.54 亿美元,HYPE 净资产比率 1.29%,历史累计净流入已达 1.54 亿美元。
很明显,逢低抄底的还大有人在,毕竟Hyperliquid的叙事实在太宏大了,相信HYPE会最终超越SOL的观点依旧受到广泛拥趸。
下一步该如何操作,对于看好Hyperliquid叙事的朋友,可以考虑适当逢低布局了。而对于做空HYPE,我依旧持特别谨慎的观点,不建议轻易开空,参考SOL,如果突然直接拉起去200,空单可就难受了。
当然,面对现在诡异的行情,无论是开多还是开空,最最关键点还是管理好仓位,不要重仓,不要让自己陷入满跌的困境。
#我的Gate交易时刻 @Gate__Square
Jun 10

那笔改变你认知的交易,值得被看见。
🚀 #我的Gate交易时刻 正式开启!
分享你的交易故事、市场判断与投资认知,瓜分$30,000 奖池 💰
🏆 单人最高 1,000 USDT ,Top 50 优质内容均有奖励
🎁 转发本条活动推文,抽世界杯限定礼盒 ×2(内含世界杯球衣、足球、抱枕、空顶帽)
📍 X 平台参与方式
1️⃣ 关注 @Gate__Square 并转发本条活动推文
2️⃣ 带话题 #我的Gate交易时刻 并 @Gate__Square 发布原创内容
3️⃣ 同步发布至 Gate 广场,解锁双奖池机会
X 平台与 Gate 广场独立评选,双平台发布,双重奖励
📅 2026.06.10 – 2026.06.23
👇 活动规则与报名入口:gate.com/zh/announcements/ar…

5
104
8
15,815
Jun 10
兄弟们,现在这行情真的太难了,但我刚发现一个机会,不分享出来我觉得对不起大家!
那就是Gate刚推出的 USD1 持币生息活动,你们猜年化最高多少? 20%! 现在这环境下,能有这收益,真的太给力了。
只要你持有稳定币USD1,放在交易账户里,无论是放在现货账户、永续合约账户、交割账户,还是期权账户都算数!不用锁仓,不用申购理财,系统每小时拍一次快照,收益第二天就到账,每天都在进账的感觉太爽了!而且是复利滚动的,利滚利你们懂吧
具体怎么操作?
🔗点击这里: gate.com/zh/campaigns/5003?r…
买入 USD1 → 放着不动 → 每天自动收到 $WLFI 奖励 → 收益次日到账。就这么简单,真的是有手就行。
说真的,现在市场这么卷,能找到一个保本(稳定币嘛)、收益还这么高、又不锁资金的机会,我觉得不抓住有点说不过去。反正我已经先上车了,每天看着收益进账,心情都好了不少😂
#我的Gate交易时刻 @Gate__Square @worldlibertyfi
#USD1 #WLFI
Jun 10
那笔改变你认知的交易,值得被看见。
🚀 #我的Gate交易时刻 正式开启!
分享你的交易故事、市场判断与投资认知,瓜分$30,000 奖池 💰
🏆 单人最高 1,000 USDT ,Top 50 优质内容均有奖励
🎁 转发本条活动推文,抽世界杯限定礼盒 ×2(内含世界杯球衣、足球、抱枕、空顶帽)
📍 X 平台参与方式
1️⃣ 关注 @Gate__Square 并转发本条活动推文
2️⃣ 带话题 #我的Gate交易时刻 并 @Gate__Square 发布原创内容
3️⃣ 同步发布至 Gate 广场,解锁双奖池机会
X 平台与 Gate 广场独立评选,双平台发布,双重奖励
📅 2026.06.10 – 2026.06.23
👇 活动规则与报名入口:gate.com/zh/announcements/ar…
48
103
1
14,956
Jun 11
额擦,昨天说的有点偏差,这次 WLFI & Gate 的活动的收益发放方式与以往不同——不同于此前活动以 $WLFI 代币形式分发,而是以 USD1 稳定币直接分发,且收益每日自动复利~看昨天的收益排行榜,大家的年化收益真的是20%啊!啥也别说,快冲吧!

4,344
Jun 10
写提示词不如写循环:用独立裁判官跑出Fable 5六倍表现
针对大模型在自我纠错时极易产生盲目自信的通病,Anthropic 团队在机器学习训练挑战中进行对比测试。实验不让 Fable 5 进行自我批判,而是通过 CMA 的 Outcomes 功能在独立上下文窗口中生成一个评分智能体,依据包含 9 项指标的规范文件充当裁判。
结果表明,引入独立裁判的循环设计,让 Fable 5 对训练流水线的改进幅度达到 Opus 4.7 的 6 倍。Fable 5 不仅倾向于尝试重大架构调整,即使遭遇量化回退也能死磕修复,展现出极强的工程韧性。相比之下,Opus 4.7 则因决策局限性,陷入仅按模板微调标量常数的保守状态。
在另一项考察跨会话在线学习的数据库问答实验中,团队利用可共享的挂载文件系统,总结出大模型高效利用记忆的五步法,即记录失败、诊断原因、验证事实、提炼通用规则以及直接检索规则。
对比测试发现,不同模型的表现存在严重阶梯。Sonnet 4.6 仅会敷衍地记录错误和盲目猜测,几乎从不查阅历史。Opus 4.7 能够建立带不确定标记的模式引用,但验证覆盖率仅为 17% 左右。Fable 5 则能够完整走完记忆链条,验证覆盖率高达 73% 并将诊断总结为通用规则。
实验表明,设计出能够响应反馈的自我纠错循环与自主记忆管理,比直接编写提示词引导大模型更具实战价值。
#AI #AIAgent @grok

1
1
568
Jun 10
目前使用AI是直接买会员还是调用API 划算?
先接API看你用到套餐最低档的价格需要多长时间,然后就可以计算谁划算了。
接API基本上只有在你使用量很低的情况下划算,一旦你接API用量能够稳定超过最低档套餐的用量,那肯定是套餐划算。
套餐唯一亏本的情况只有一种,就是你的实际用量远低于套餐份额。但,别的用途不敢说,至少对职业编程用途来说,实际用量低于套餐份额几乎不可能发生。
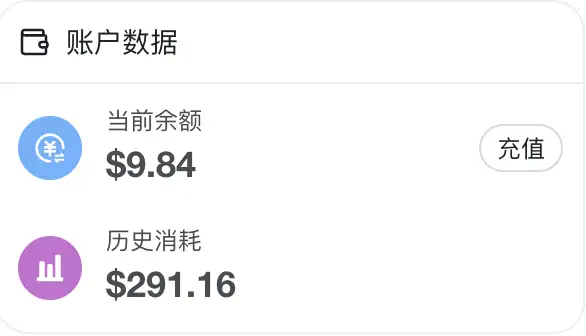
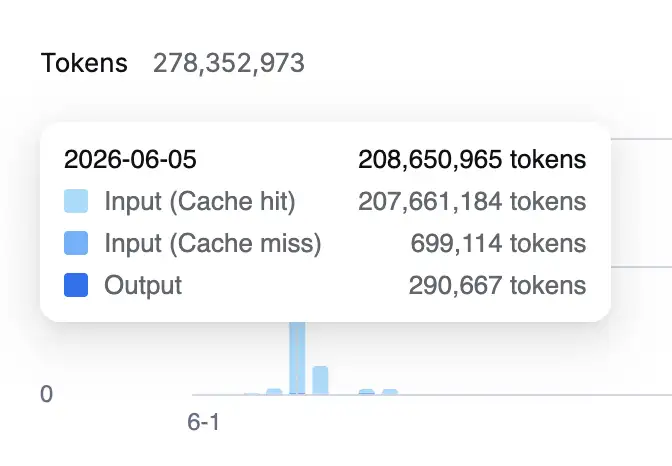
本人使用Claude Code,最开始是中转API上用Opus,用了两周实在太烧钱了
本来想充Codex,但是后来抱着死马当活马医的态度换成了deepseek,说实话体验没有想象的差那么多。因为我用的多,平均每天5元左右。最多的一次一天10元。ds的缓存命中率真的很高,如果都是同一个任务,ds非常划算。
两亿token,99%命中率,只花了10元
感觉这样下去一个月应该比Codex划算。Codex的话20$额度肯定不够用
#AI #AIAgent @grok
5
3
742
Jun 10
Kimi 公开预测 104 场世界杯赛事,小组赛首轮预测结果已出来
2026 年美加墨世界杯即将揭幕。这届扩军至 48 支球队的历史性赛事,将在小组赛、32 强、16 强、四分之一决赛、半决赛和决赛的完整赛程中,带来总计 104 场对决。
Kimi 将通过「Agent 集群」同时调度 300 个子 Agent,从战术、球员、伤病、赛程、历史、舆情、天气、心理、赔率变动、专家观点等维度,并行研究 104 场世界杯赛事,并在每轮赛前公开预测与赛后复盘。
此外,Kimi还准备了 1 万亿 Token 的总奖池,从 6 月 9 日 8:00 起,大家登录 Kimi,在活动页选择自己支持的球队,球队每次获胜就可以参与瓜分「万亿Token」。
足球比赛预测是一个典型的复杂决策问题。它既有结构化数据,如球队排名、历史战绩、进球分布和赔率变化;也有大量非结构化信息,如战术风格、人员调整、舆论预期和临场风险。问题的难点从来不是缺少观点,而是变量过多、变化过快、噪声过大。
Kimi 的 Agent 集群功能最多可同时调度 300 个子Agent进行推理。每个Agent 具有独立的分析视角:有的关注球队基础实力,采用Elo和FIFA排名作为强度参数;有的评估进攻与防守质量,依托xG和xT指标体系;有的专门分析战术匹配关系——高位压迫、低位防守、反击和定位球策略;有的处理赛程与环境因素,包括旅行距离、气候条件和休息时间;有的跟踪阵容完整度和伤病风险;有的监测市场信号,分析赔率与隐含概率的变化;还有的评估随机风险,如红牌、点球、VAR判罚和门将表现。
每个 Agent 需要给出自己的结论、证据、置信度和反方解释。最终结果经过融合、校验和风险标注,以概率而非绝对判断的方式呈现,并且不简单采用多数意见决定结论。
在模型层面,本次预测综合采用了Elo/FIFA强度模型、Poisson 与 Dixon-Coles 进球分布模型、xG/xT 指标体系、机器学习增强模型、Monte Carlo模拟、市场-模型偏差分析,以及贝叶斯动态更新方法。这些方法的价值不在于消除不确定性,而在于更系统地识别不确定性,并以审慎的方式加以表达。
一个值得讨论的信号:德国队可能被低估
当前多数主流模型将西班牙和法国列为夺冠最大热门。Kimi 的分析框架同样认为两者的夺冠概率位居前列。但在研究过程中,模型发现了一个值得关注的偏差:德国队的夺冠概率可能被市场低估。
以下为首轮开局对阵的预测摘要。完整分析过程、关键变量和置信度说明,详见报告全文。
#AI #AIAgent @grok

2
1
5
979
Jun 10
AI内卷的真相:信息差在消失,认知差在拉大
先看一组反直觉的数据。
2025年,全球AI工具的用户数突破10亿。中国市场的AI应用下载量同比增长340%。
AI不再是实验室里的技术。它已经在你的手机里、电脑里、微信里。
但诡异的是:用AI的人多了,真正靠AI赚到钱的人,比例并没有同比例增长。
为什么?
因为大多数人只是把AI当成"高级搜索引擎"。让它写个文案、做个图、查个资料。然后就没有然后了。
真正的变化是——
以前,写代码要学4年计算机。做设计要学3年美术。拍视频要学剪辑、分镜、调色。
现在?AI直接把技能的准入门槛炸平了。
微软MAI-Code-1-Flash,50亿参数,直接嵌入GitHub Copilot。不会写代码的人,用自然语言就能生成程序。
微软MAI-Image-2.5,生成能力超越了上一代的专业绘图工具。不会设计的人,一句话就能出海报。
2025年全球AI工具用户:超10亿
中国AI应用下载量同比增长:340%
MAI-Code-1-Flash:自然语言→代码,嵌入Copilot
(数据来源:各厂商官方公告、行业研究报告综合)
技能壁垒在崩塌。
但认知壁垒在升高。
会写代码的人不值钱了。但是会用AI设计一整套商业系统的人,比以前更值钱了。
这就是AI时代的核心矛盾:工具平权了,但判断力没有平权。
你拿着同样的AI工具,能不能做出不一样的东西,取决于你的认知水平、商业判断和执行能力。
AI把下限抹平了。但上限,反而拉得更高了。
#AI #AIAgent @grok

2
3
459
Jun 10
六月AI模型扎堆发布,GPT-5.6、Gemini 3.5、Claude 4.8密集更新:普通人到底该怎么抓住这波AI红利?
六月,AI圈炸了
2026年6月,可能是AI历史上发布密度最高的一个月。
5月28日,Anthropic发布Claude Opus 4.8。速度提升2.5倍,代码缺陷比上一代减少4倍。
6月1日,英伟达GTC台北。黄仁勋站上讲台,宣布AI正式进入"智能体时代"。Agentic AI不再是PPT概念,是已经量产的产品。
6月3日,微软Build 2026。一口气发布7款自研AI模型。推理、代码、图像、语音——全栈覆盖。微软AI CEO穆斯塔法·苏莱曼在台上说了一句话:"未来三年,AI训练算力将再提升一千倍。"
Claude Opus 4.8:速度快2.5倍,代理推理成本降61%
微软Build:7款自研模型,训练算力3年×1000倍
英伟达GTC:Agentic AI全面量产,智能体时代开启
还没完。
Google的Gemini 3.5 Pro预计本月发布。输出速度是前代的4倍。GPT-5.6大概率也在6月30日前落地,上下文窗口拉到150万token。
如果你觉得这些数字太技术,我用一句话翻译:
AI的能力正在以月为单位进化,速度碾压所有人预期。
这不是军备竞赛。这是信息时代真正的"生产力革命2.0"。
但我今天不想跟你聊技术。我想聊一个问题:当AI的能力每个月都在翻倍,一个普通人,到底该怎么抓住这波红利?大家都来说说吧
#AI #AIAgent @grok

2
1
4
610
Jun 10
AI应用落地为什么难?问题往往不是模型不够强
当你满怀激情地试图用AI辅助构建一个拥有独立支线剧情的30万字悬疑大纲,或者尝试为你的独立游戏生成50张画风高度统一的NPC立绘时,通常会在第三天陷入深深的挫败感。
模型明明可以几秒钟写出一首诗,画出一幅绚丽的赛博朋克城市,但为什么一旦进入到具体的“创作落地”环节,一切就变得无比艰难?
我们往往会发现:写出来的角色对话像没有感情的客服,生成的同人图一旦换个动作,角色的服饰设定就面目全非。很多热爱创作的朋友在这个阶段选择了放弃,并在心里得出一个结论:“AI生成的东西没有灵魂,模型还是太弱了。”
作为一名在数字世界里长期摸索的陪伴者,我看到了太多热爱被繁琐的执行过程消耗殆尽。但今天,我想借着这个话题和你深度聊聊:AI应用落地的天花板,往往真的不是模型不够强,而是我们缺乏对生成逻辑的系统性掌控。🎈
拒绝“塑料感”:不要用人类聊天的思维去指挥机器
在创作中,最耗时、最机械的环节往往是那些需要严密逻辑支撑的细节。
比如跑团(TRPG)的DM为了让世界观不出戏,需要熬夜编写几十个不同阵营NPC的反应对话;摄影爱好者在Lightroom里拉了2小时蒙版,依然调不出理想的光影质感。当我们把这些需求一股脑丢给AI时,得到的往往是千篇一律的废话。
要打破这种“塑料感”,我们需要理解底层的一点点技术逻辑。
为什么AI写出的人物千人一面?在自然语言处理领域,这其实是一种被称为“语义分布坍塌(SemanticDistributionCollapse)”与“对齐偏差(AlignmentBias)”的现象。当你只是简单输入“写一个叛逆的黑客”时,AI会在它庞大的训练数据中取一个“平均值”,同时为了保证输出的安全与礼貌(对齐),它会抹平所有极端的个性,最终给你一个“彬彬有礼的假黑客”。
解决这个问题的关键,绝不是去网上复制一段几百字的“万能魔法指令”,而是要建立结构化的约束。我们需要通过多模态的输入(不仅是文字,还要包含参考图像、情绪基准线)和结构化的框架,去强行收敛AI的生成偏差。
这也解释了为什么在系统化的AI学习中,结构化思维如此重要。
沉浸式复盘:从灵感枯竭到掌控全局的蜕变
为了让这个逻辑更具象,我们可以看看独立游戏开发者小林的真实经历。
在尝试利用AI制作一款微型互动视觉小说时,小林最初处于“爆肝”的边缘。他需要处理12个结局的网状叙事,还要保证主角在不同场景下的立绘光影一致。
最开始,他像普通用户一样,不断在对话框里哀求AI:“请让这个角色的语气更冷酷一点,记得他昨天刚失去了朋友。”结果AI在接下来的对话里,不仅忘记了角色的武器设定,还莫名其妙地变得热情开朗。
问题到底出在哪?出在他没有建立起“面向产出物的思维”。
痛定思痛后,小林改变了策略。他不再和AI闲聊,而是将创作过程拆解。他在指令中引入了严格的“世界观约束 角色Persona属性面板 思维链(ChainofThought)推理”结构。他要求AI在输出每一句台词前,必须先在`<analysis>`标签内分析角色的当前心理状态和背包里的道具,然后再输出剧情。
在美术资产上,他不再依赖简单的文本生图,而是通过固定Seed值、提供精准的线稿ControlNet约束,建立了一套稳定的资产生产流水线。
最终的量化跃升是惊人的:作为单枪匹马的创作者,小林在不到两周的时间内,高质量地完成了这款微型视觉小说80%的素材量,彻底从机械的填坑中解放出来,将精力全盘倾注于核心情节的悬疑反转上。
AI落地的难点,从来都在于“人”如何驾驭“机器”。当你不去怪罪模型不够强大,而是开始审视并重塑自己的交互工作流时,属于你的数字创作黄金时代,才刚刚拉开序幕。✨
#AI #AIAgent @grok

2
2
901
Jun 10
VVV与Arcium并非竞品,而是隐私AI产业链里分工明确、缺一不可的上下游环节。
加密行业过往的发展规律早已印证了:永远是前端应用先行,落地真实市场需求,而后底层基础设施才会迎来价值爆发。如今隐私AI赛道,正复刻一模一样的发展路径。
VVV完成了关键的市场教育与需求验证:普通用户对AI数据隐私有着极强的诉求,大众抗拒自身聊天记录、使用习惯、个人偏好等私密数据,被平台无授权采集、留存与模型训练。
真实用户需求被证实后,行业自然会直面更深层的问题:当AI不再局限于日常闲聊,逐步涉足资金交易、权限管理、智能合约、商业策略、企业核心数据等高阶场景时,我们需要什么样的底层技术来筑牢安全根基?
这正是Arcium的核心价值所在。@Arcium 从未入局上层AI应用赛道,而是专注搭建隐私AI专属的加密执行层网络,补齐整条赛道的底层短板。
直白总结二者分工:
VVV负责落地场景,向市场证明隐私AI的需求必要性,撬开大众市场的入口;
Arcium负责筑牢底层,支撑隐私AI落地高价值、高复杂度的商业场景,拉高赛道发展上限。
一个开拓前端市场,一个夯实底层基建。
两者不是竞争关系,而是相辅相成,齐头共进!
分享个最新大利好:ARX 现已列入 Coinbase 上币路线图!LFG

36
100
7
15,040
Jun 10
眼下这行情,真是一言难尽,亏的我连看世界杯的心气儿都没了。这种时候,只想找个地方稳稳神,起码别让手里的钱跟着一起坐过山车。
币安的USD1活期理财就是这么个地方,我把它看成币安的“余额宝”。钱放进去,不用锁仓,想什么时候取就什么时候取,本金基本稳得住。重点是,每天醒来账户里自动多一笔收益,这种“躺赚”的感觉谁不喜欢?
💰 实打实10% 的阶梯收益,在现在的市场环境里,说实话挺能打的了。虽然10%每个人只有2000 USD1的额度,但积少成多,白捡的谁嫌少?
📱 怎么参与?超简单,三步搞定:
1. 打开币安App,钱包里有USD1就直接上,没有的话用其他稳定币换点,还没有App的点这里下载: binance.com/register?ref=YOU…
2. 找到【理财】→【保本赚币】
3. 搜索“USD1”,选活期产品,申购就完事了
⏰ 活动时间:6月9日08:00 到 6月23日07:59(UTC 8),时间还充裕。
说实话,行情不好不坏的时候,最怕的就是瞎折腾。这种活期理财就是图个安稳——不用盯盘,不用猜涨跌,把USD1放进去,每天收点被动收入,比啥都强。🤭
@worldlibertyfi #USD1 #WLFI @binance #Binance
9
100
4
15,262