
programmer, optimist. work: @turbopuffer
Joined November 2019
- Tweets 1,542
- Following 270
- Followers 2,029
- Likes 4,564
269 Photos and videos



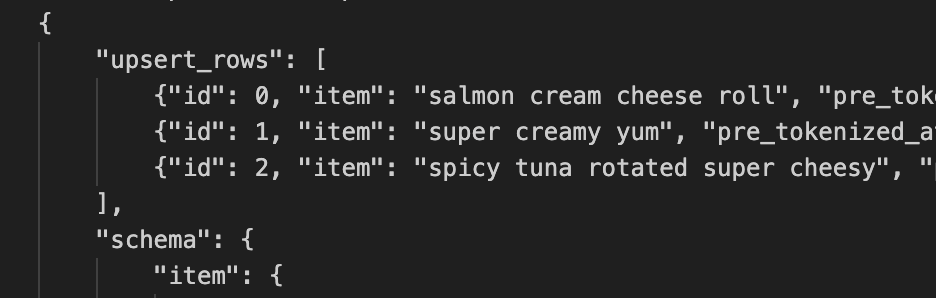






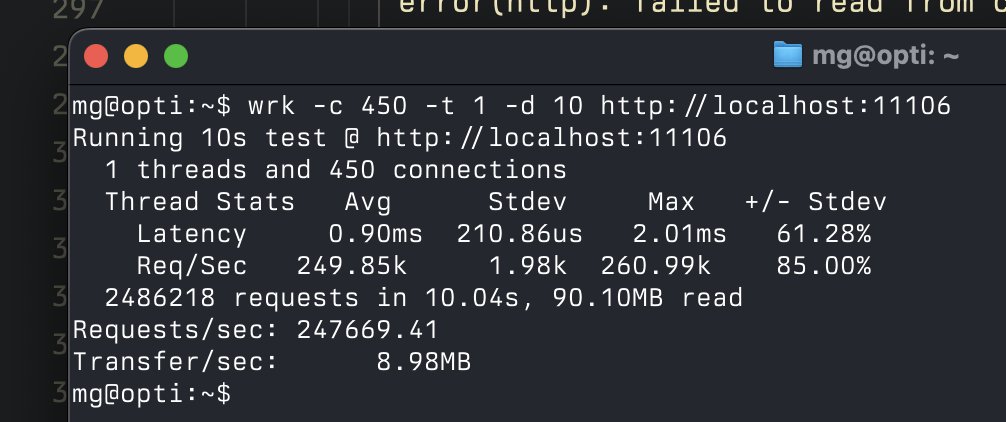
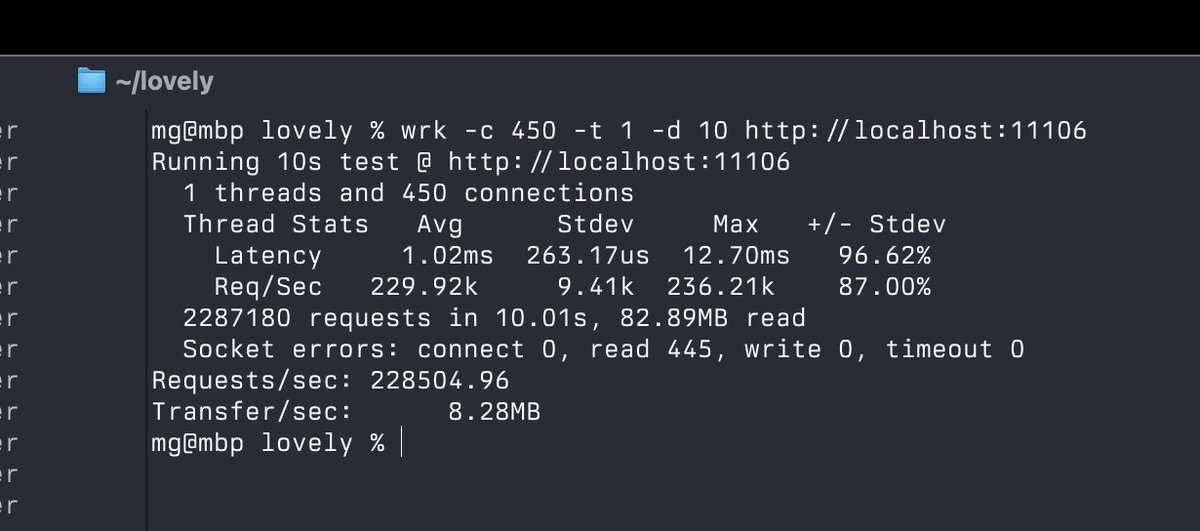

excited to get this out there in the hopes that other folks can benefit from our work here! a lot goes into making a good tokenizer
also wanna make sure I thank the tantivy folks, we've built our earlier tokenizers (everything before word_v4) atop their lovely open sourced work
Jun 2

so @morgallant has optimized FTS tokenization throughput to 423 MiB/s and open-sourced it (github.com/turbopuffer/alyze)
I keep telling him that it would be really high agency to get to DRAM bandwidth (~100 GiB/s), and he keeps getting annoyed at me and making it faster

2
1
11
1,523

May 11
fangirling over being on dash 8 for the first time in a while — i think my first ever flight was on a dash 8!!!
1
1
6
647
morgan gallant retweeted

Apr 27
BM25 efficiently scores text, but relevance often depends on more than text (recency, popularity, PageRank)
we score non-text attributes as clauses in the same MAXSCORE plan that evaluates BM25 → better first-stage relevance, still scales to 100M
tpuf.link/rank-by-attr
10
114
16,631
hoping to write a blog post on this eventually, it's a fascinating topic.. so many different possible approaches, each with their own tradeoffs. for v1, as is always the case at tpuf, we've optimized for simplicity
Mar 9

new in tpuf: regex indexes
regex and glob filters can now use a trigram index to avoid full-table scans
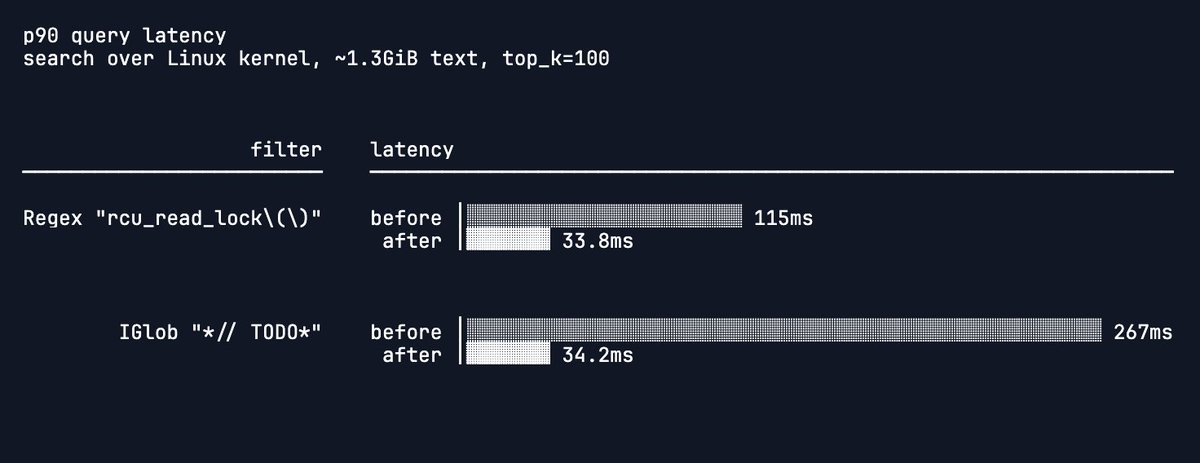
ALT A chart showing p90 query latency performance gains for regex and glob filters after the introduction of a trigram regex index on turbopuffer. Latency improved from 115 milliseconds to 33.8 milliseconds for a representative regex filter and from 267 milliseconds to 34.2 milliseconds for a representative globbing filter. The chart suggests that while these kinds of filters already worked, now they puff!
1
1
7
881
Jan 26
btw hiring for a systems eng. role at @turbopuffer soon on the text team, you’d work closely w/ @jpountz and I on billion-scale {storage,ranking,query eval}. DMs open!
9
20
215
37,306
Jan 14
joint work with @jpountz, covers some of the storage work behind the ftsv2 launch!
Jan 14
for FTS v2, we redesigned our inverted index structure
• tighter compression
• less KV overhead
• better MAXSCORE interaction
up to 10x smaller indexes → up to 20x faster text search!
tpuf.link/fts-index
1
6
2,190
still in awe of the talent density on the @turbopuffer team… truly such an honour and a privilege to get to work with these folks every day
7
3
99
8,721
10 Dec 2025
I really hope that the continued success of Zig will help convince more systems programmers that treating memory allocations as infallible is a terrible idea for PLs, and that OS-level memory overcommits in Linux server environments is similarly terrible!
1
7
1,275
4 Dec 2025
joint work with @jpountz and @nikhilbenesch; excited to start rolling this out more broadly! insane amount of progress on FTS recently :)
4 Dec 2025
FTS v2: up to 20x faster full-text search
turbopuffer is now on par with Tantivy and Lucene for many queries, more to come
v2 now in beta. 2 PRs away from all query plans being implemented. will be enabled in prod for all, shortly.
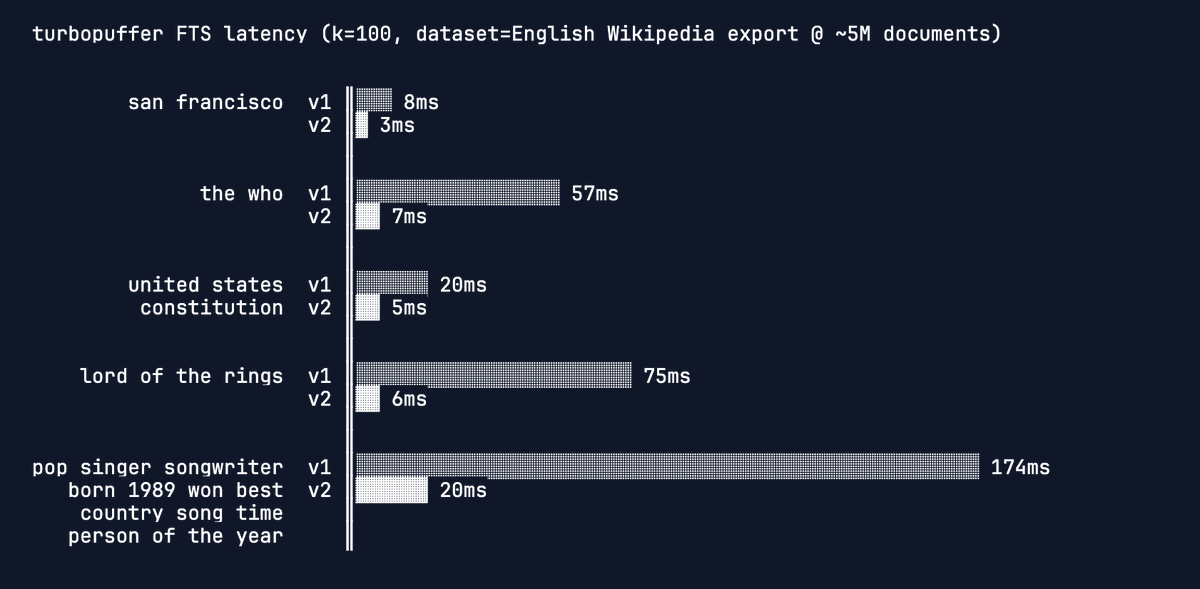
ALT Horizontal bar chart comparing turbopuffer FTS v1 vs v2 latencies for five queries on English Wikipedia, v2 much faster (3–20ms) vs v1 (8–174ms).
1
16
10,480
morgan gallant retweeted

21 Nov 2025
Something that's great with Lucene is how you can run luceneutil benchmarks on a PR to assess the performance impact. So I built something similar for turbopuffer (off the Tantivy benchmark!). Here, baseline is what runs in production now, contender is what will get deployed soon
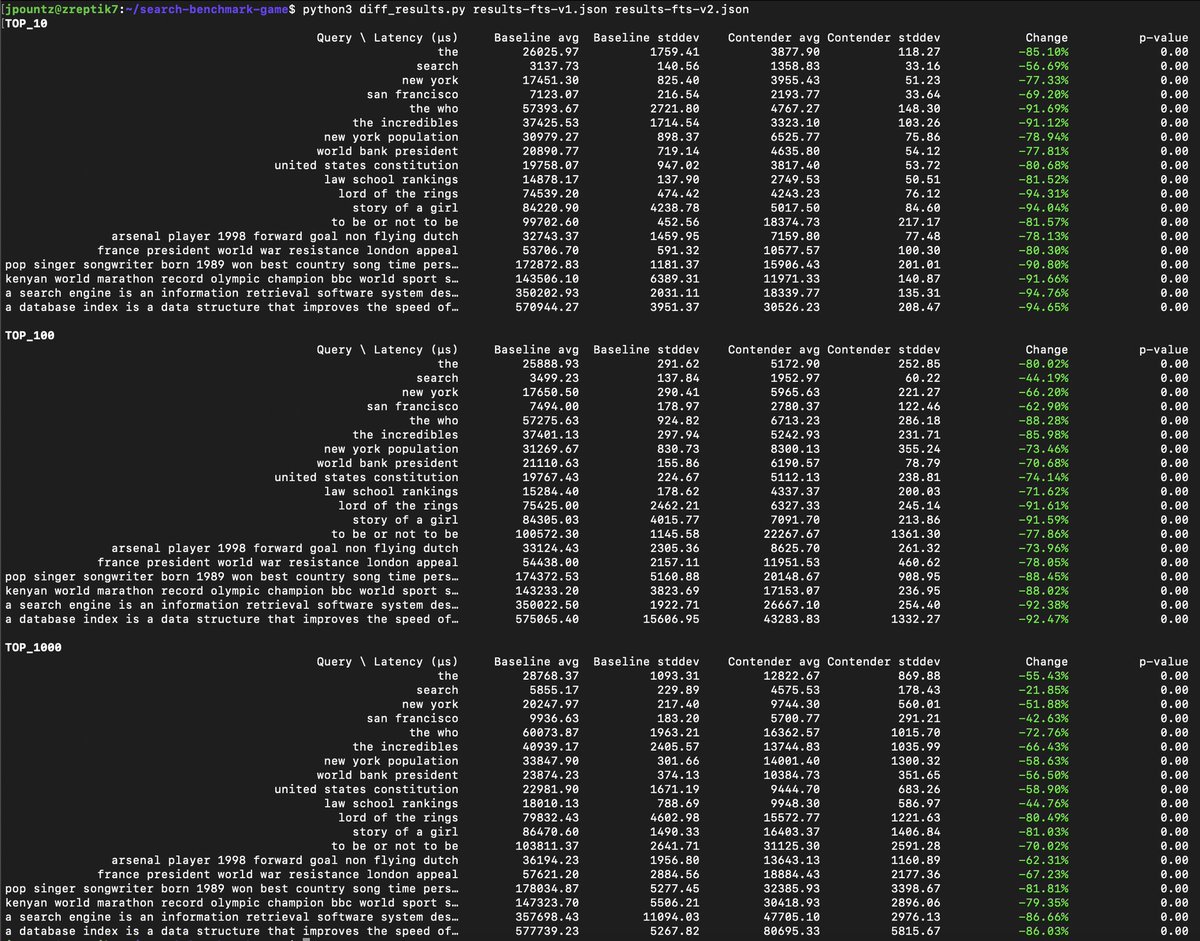
2
32
9,251
11 Nov 2025
hand-rolled a fully uax#29-compliant tokenizer today, brain is a little fried but it was lowkey pretty fun
2
1
4
870
9 Nov 2025
one of my favourite ways to deploy to @Railway! build the binary locally, package it up in a light alpine image and ship it off
1
1
8
1,242
24 Oct 2025
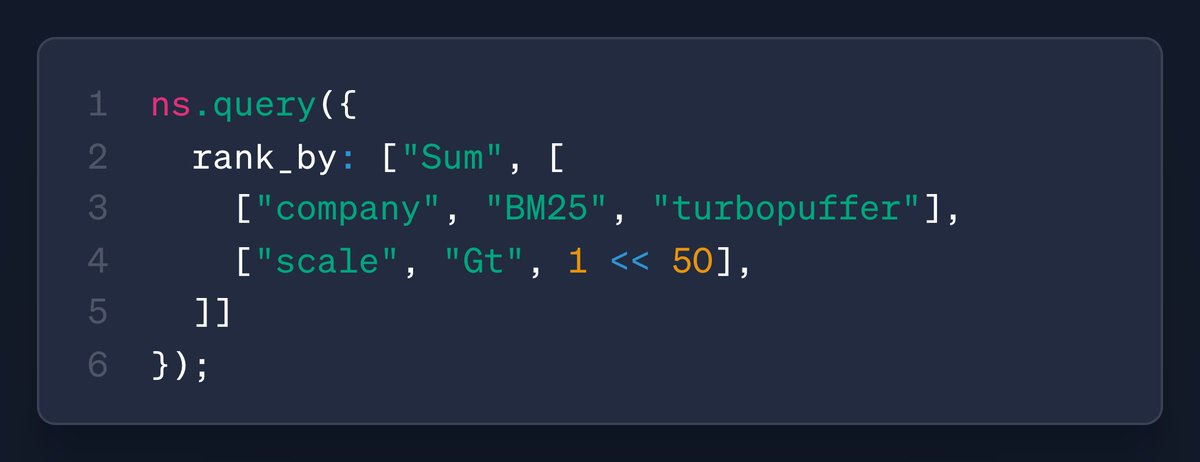
ContainsAllTokens (shipped a while back) uses posting lists to evaluate filters, this is the opposite (filters as postings)
24 Oct 2025
new: rank by filter! boost scores when docs match a condition (e.g. scale > 1pib). plugs straight into rank_by, and works alongside full-text search
1
1
3
647
5 Oct 2025
starting to learn a bit more about unicode and its intraticies. wrote a zig program to parse out property tables.. tried to do it at comptime, succeeded, but unfortunately made compilation times unreasonable. so instead, had to embed .txt in binary and parse it on the fly (sigh)
1
6
478