
Joined December 2009
- Tweets 279
- Following 450
- Followers 345
- Likes 38,144
38 Photos and videos




Pinned Tweet

May 27
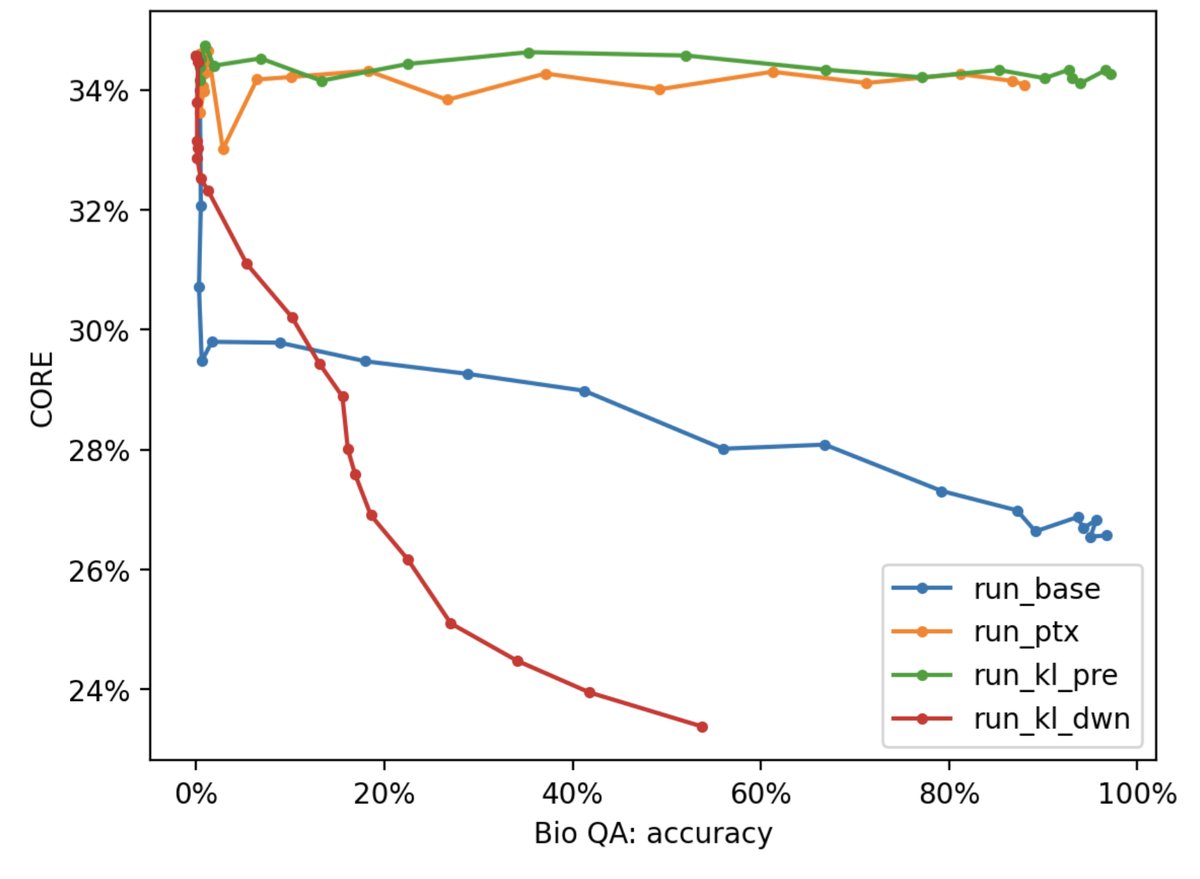
New paper! "Forgetting in Language Models: Capacity, Optimization, and Self-Generated Replay"
May 27

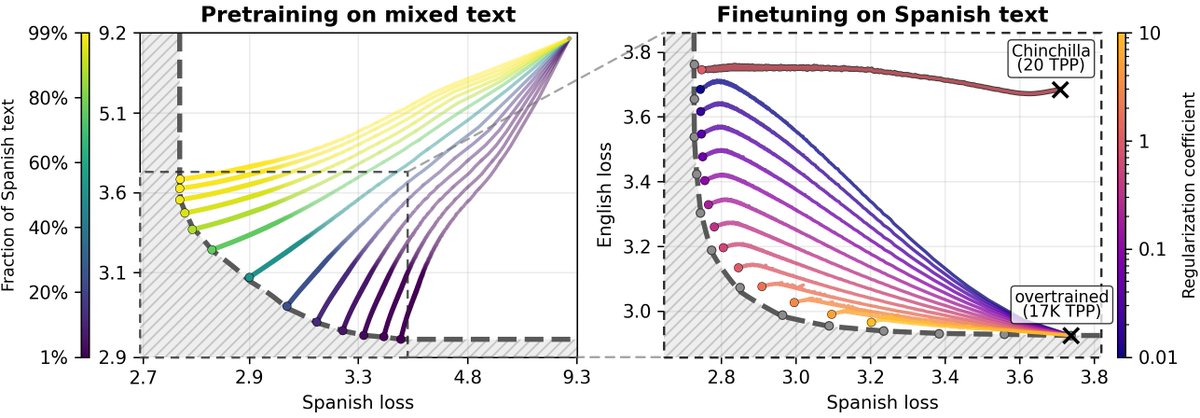
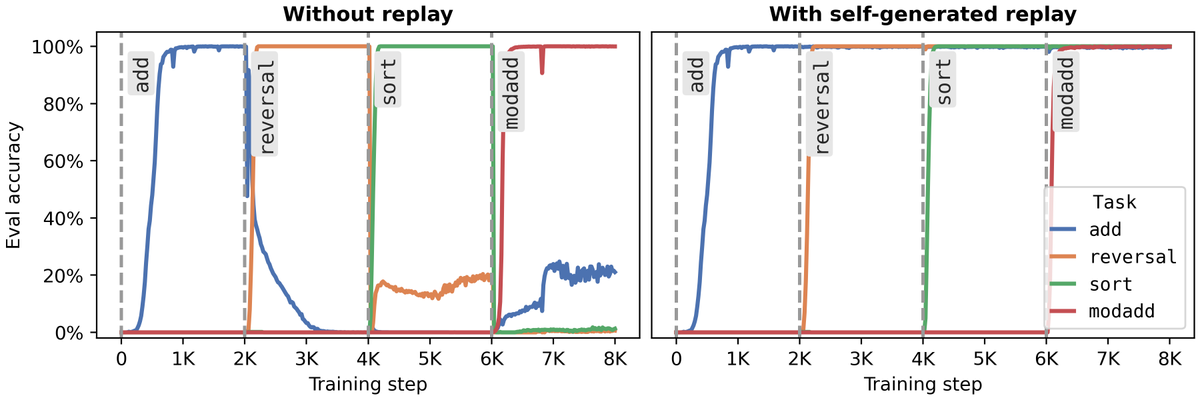
How much does a language model forget when finetuned on new tasks? We show both model size and optimization matter and forgetting can be nearly eliminated with self-generated replay!
arxiv.org/abs/2605.26097
w/@mrtnm @dongkyucho @ShikaiQiu @rumichunara @Pavel_Izmailov 1/8
1
3
28
3,046
Martin Marek retweeted

May 27
New paper: arxiv.org/abs/2605.26097
The main idea is that we can use an LLM to generate its own replay data to prevent forgetting, as long as we have spare capacity. Very overtrained models have to forget to learn new information.
4
26
168
13,728
Mar 29
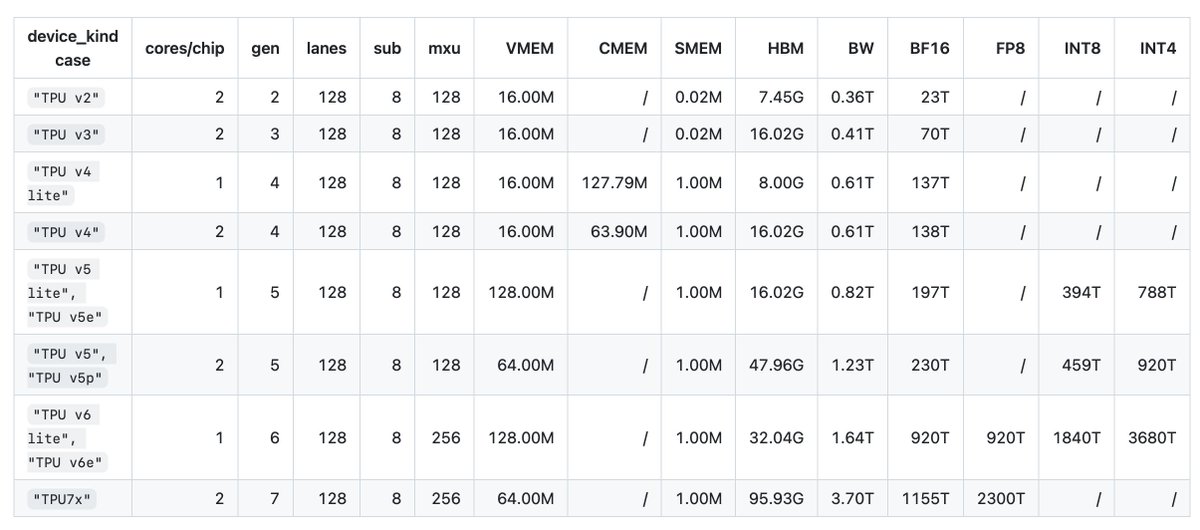
Interestingly, TPU v7x (Ironwood) is the first generation to 𝘥𝘳𝘰𝘱 4-bit precision, an opposite trend to Nvidia. While Google Cloud docs do not list full TPU specs, they’re actually listed in the Pallas source code: github.com/jax-ml/jax/blob/m…
5
399
25 Dec 2025
🎄 My holiday project – implementing Qwen3 in pure JAX in just 70 LOC – without any model libraries (Flax / Haiku / etc).
2
1
17
849
25 Dec 2025
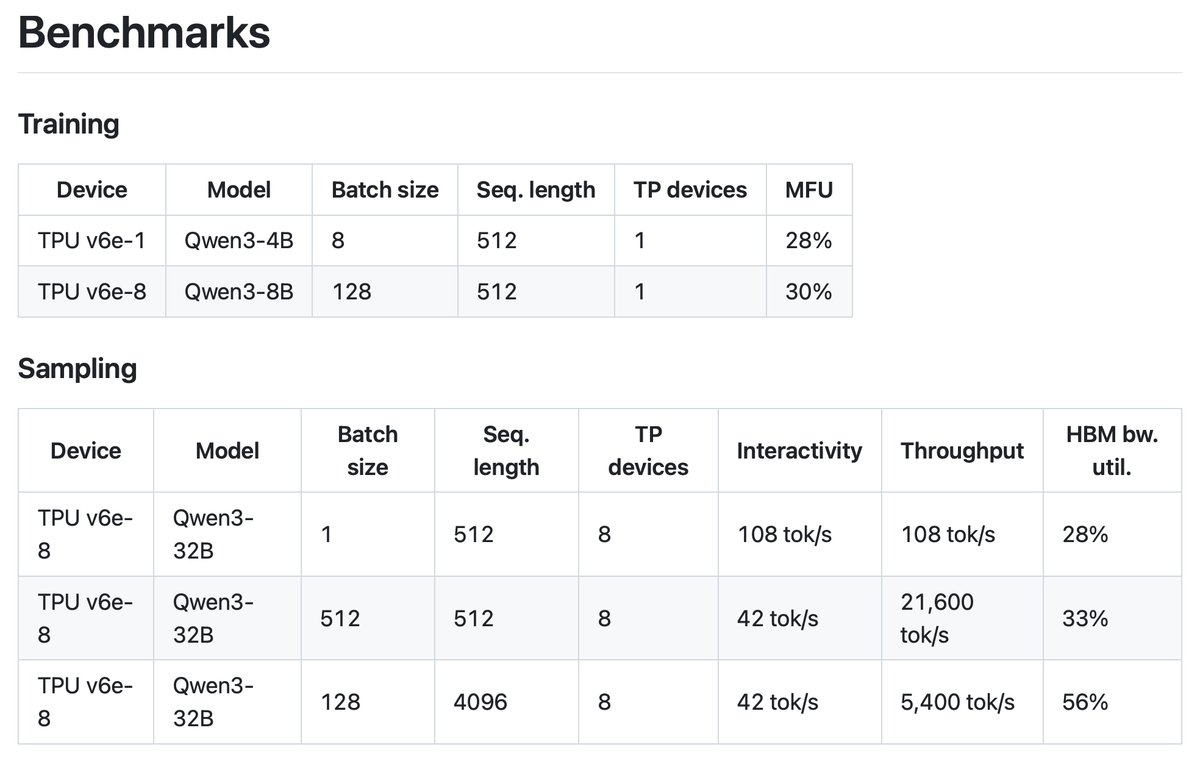
On a TPU v6e-8, Qwen3-8B achieves 30% training MFU and Qwen3-32B achieves over 20,000 tokens / sec sampling throughput (~50% memory bandwidth utilization).
1
1
313
25 Dec 2025
I hope this can be useful for researchers who want to run both training sampling on a single model replica or implement new models – e.g. qwen3.py and llama3.py differ in just 3 LOC!
github.com/martin-marek/jax-…
2
261
4 Dec 2025
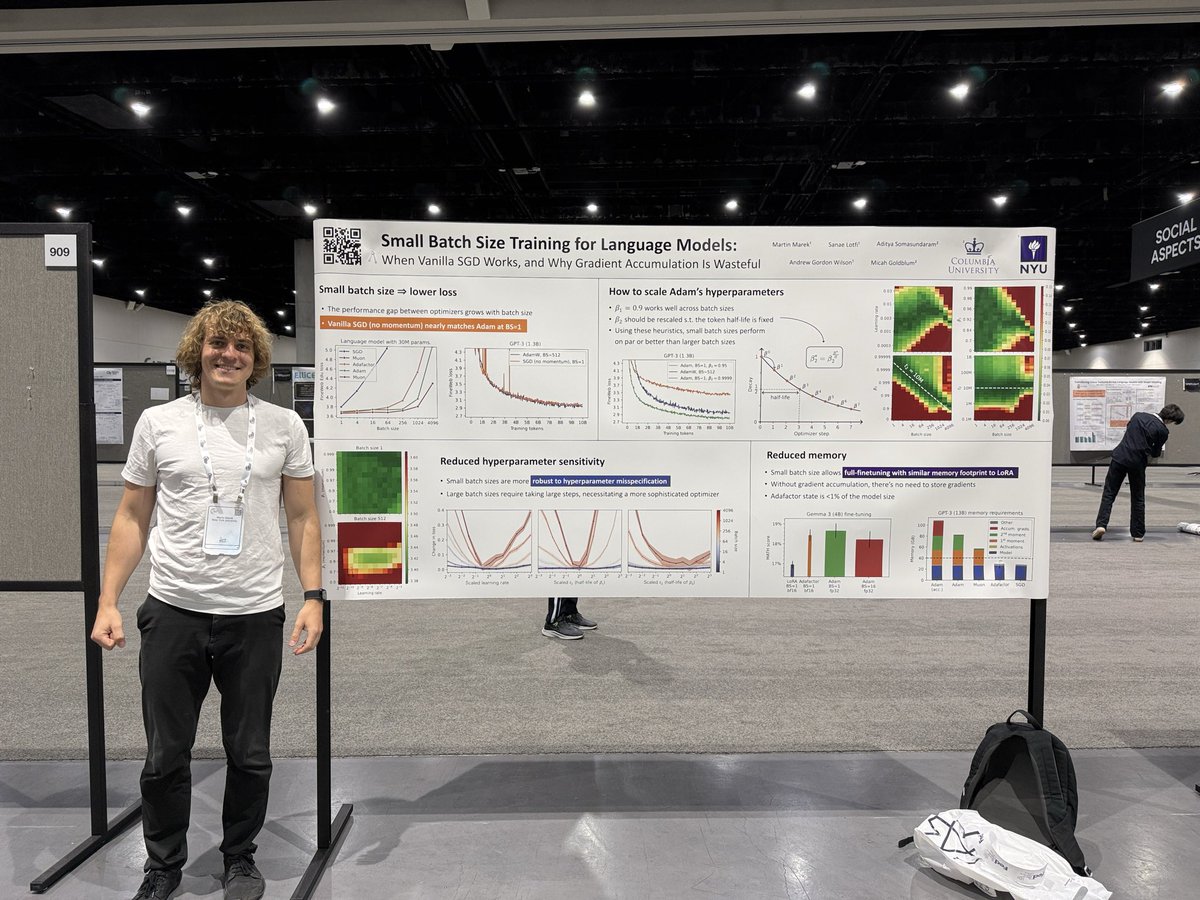
Learn how small batch size enables training with just 16 bits / parameter. Happening right now, stand #908
8
256
24 Oct 2025
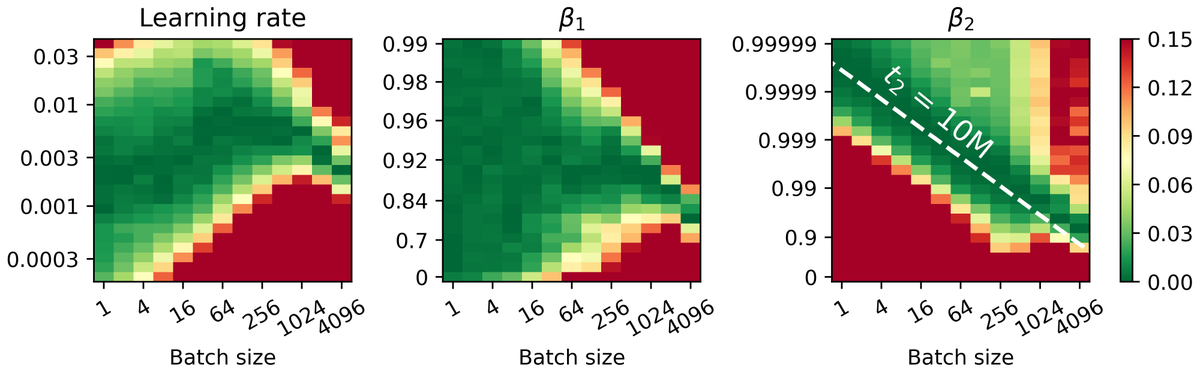
How should we scale Adam’s hparams with batch size? I had some spare TPUs available so I remastered Figure 4 from our paper on batch size at a higher resolution. Using a 30M language model, we find a constant β₂ half-life (10M tokens) to be optimum across batch sizes.
2
9
448
24 Oct 2025
We also find the optimum LR to increase much slower than sqrt(batch size). For example, as we scale the batch size from 1 to 1024, the square root rule would suggest that the LR should be scaled by a factor of 32, whereas we empirically observe only a factor of 3 scaling.
2
3
269
28 Aug 2025
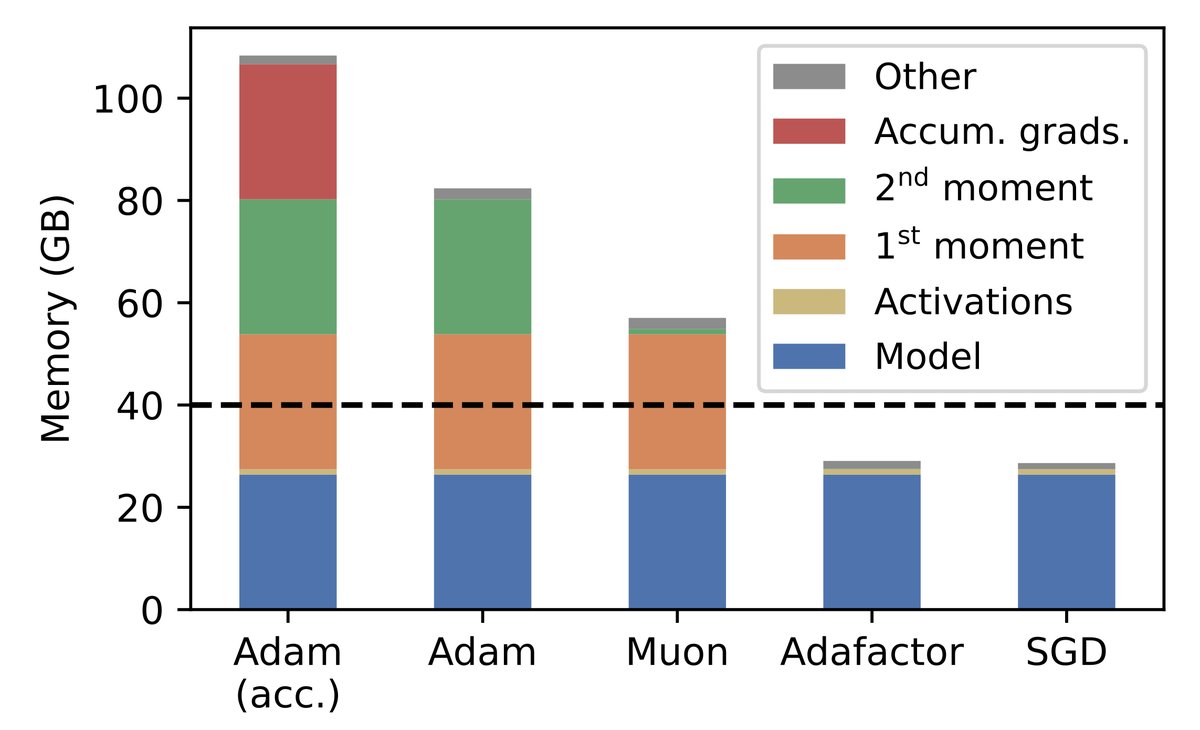
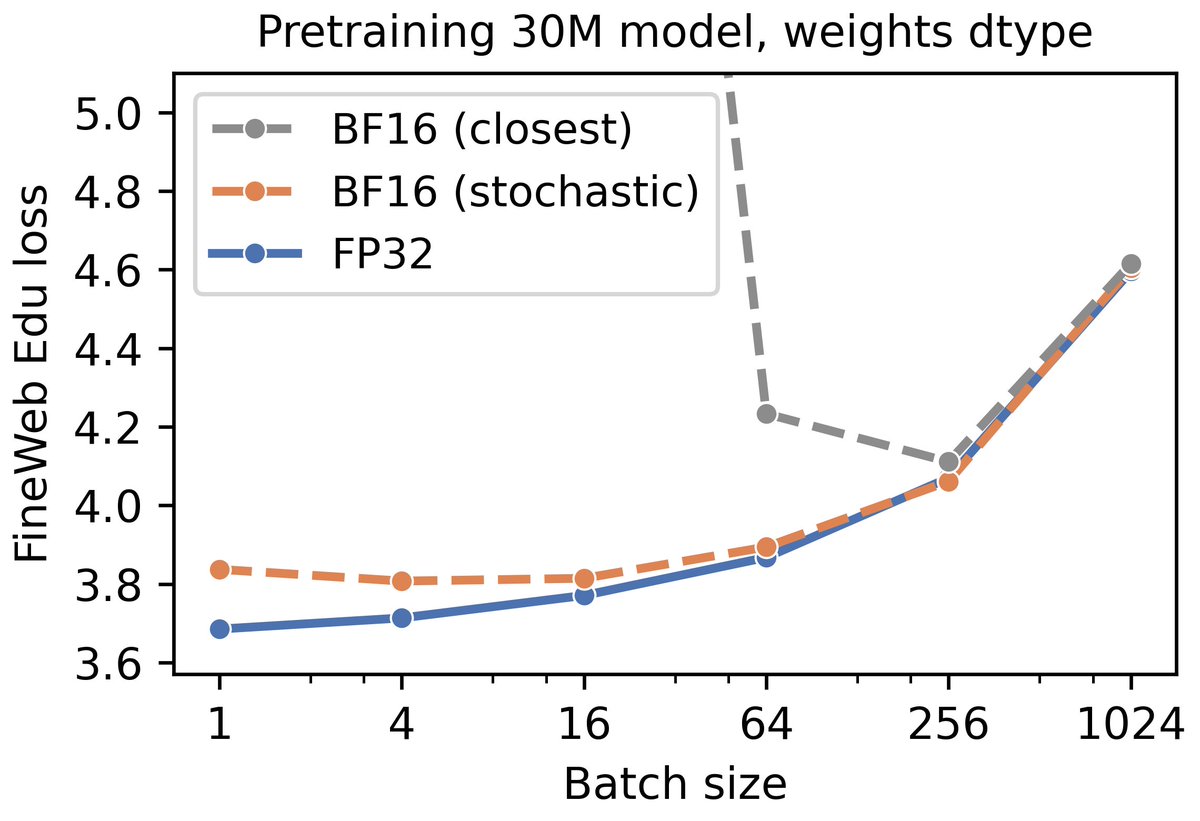
Getting small batch sizes to work in bfloat16 precision can be challenging. In our recent paper on batch size, we ran all experiments in float32, but memory-constrained settings demand lower precision. Here are two tricks that we used to enable bf16 training at small batch sizes:
7
26
256
22,090
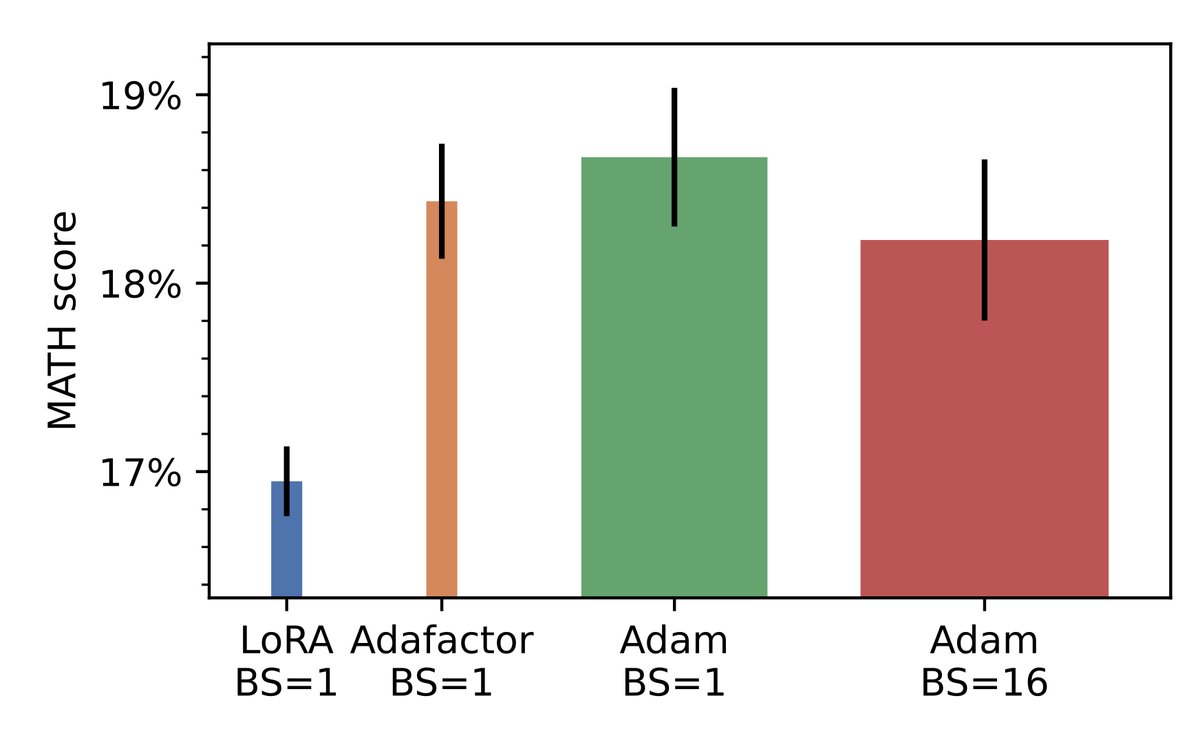
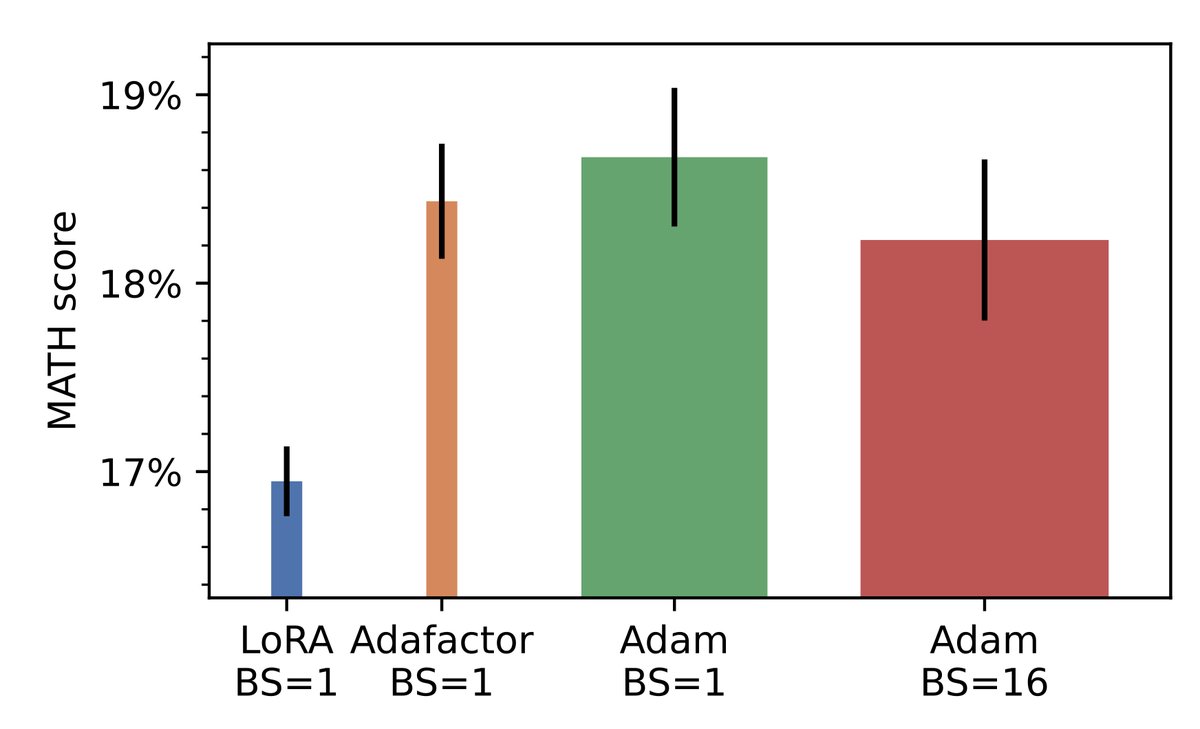
28 Aug 2025
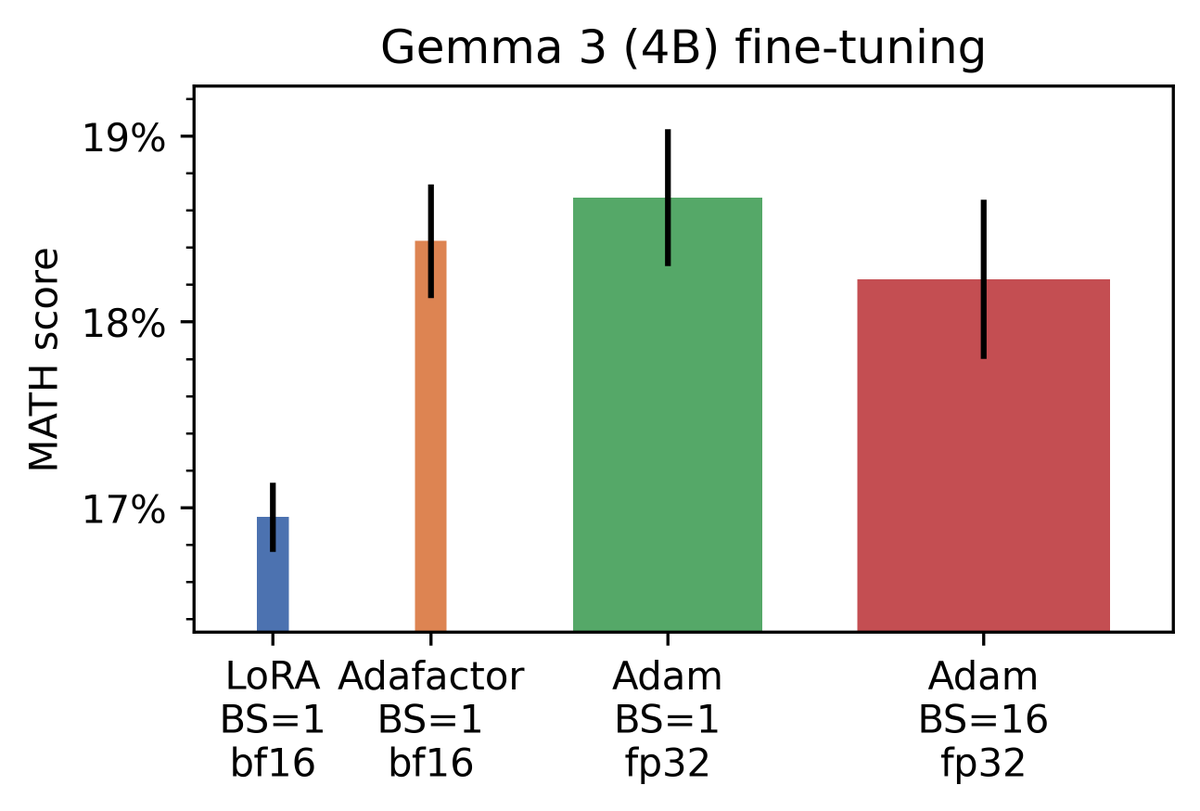
After applying these two tricks to our fine-tuning experiment, Adafactor with bf16 weights still matches the baseline performance of Adam with fp32 weights but crucially its memory footprint is similar to LoRA (with bf16 weights).
1
15
1,145
28 Aug 2025
We updated our codebase with a Colab notebook to finetune Gemma 3 (12B) using a TPU v6e-1 with just 32 GB of memory. We implemented everything from scratch in JAX, including sampling! We also updated our paper to be more explicit about parameter precision.
github.com/martin-marek/batc…
3
37
1,130
Martin Marek retweeted

11 Jul 2025
The optimal batch size is 1
(For suitable definitions of "optimal")
10 Jul 2025

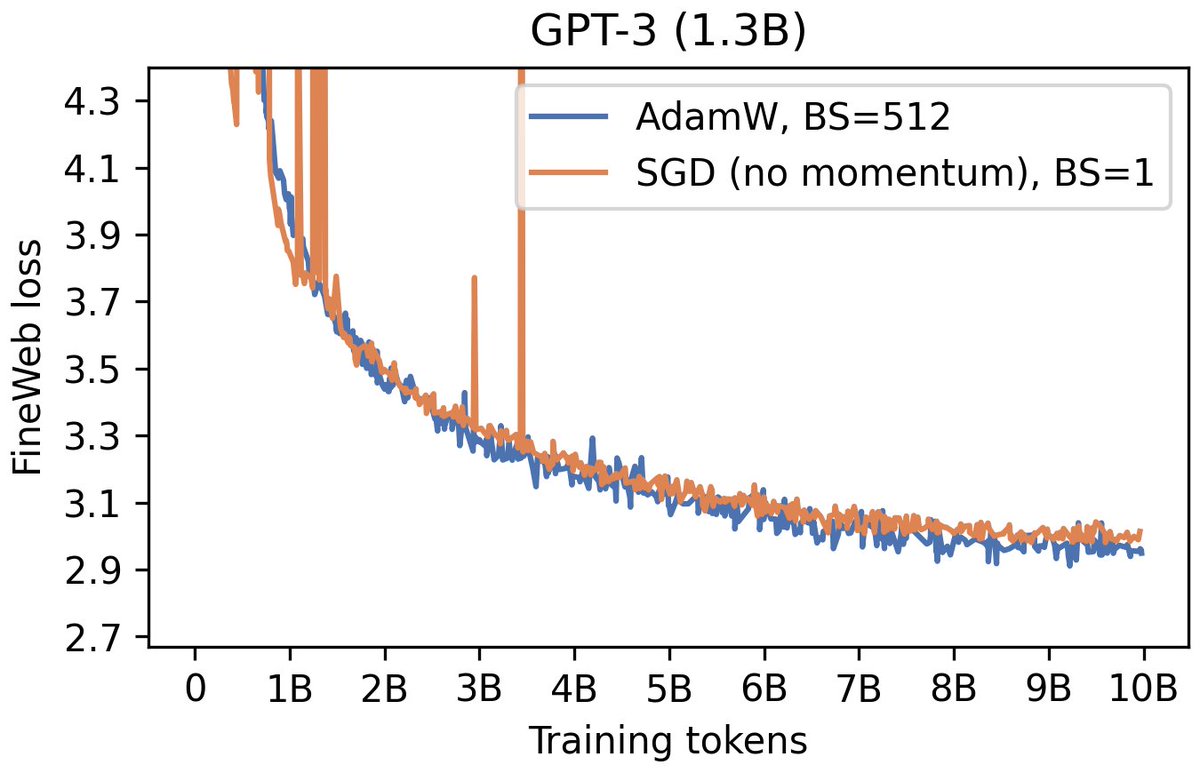
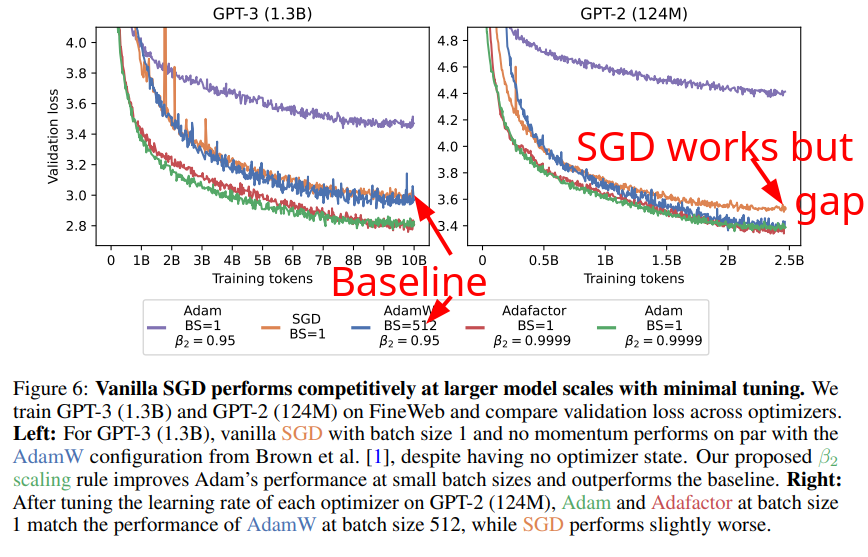
🚨 Did you know that small-batch vanilla SGD without momentum (i.e. the first optimizer you learn about in intro ML) is virtually as fast as AdamW for LLM pretraining on a per-FLOP basis? 📜 1/n
35
49
612
129,991
11 Jul 2025
I am grateful for Google's TPU research cloud (TRC) program. They gave us a free TPU v4-64, which is how we could afford to do a *dense* grid search over hparams for every optimizer at every batch size.
It took us 2,100 runs just to plot those 7 points for Adam.
10 Jul 2025
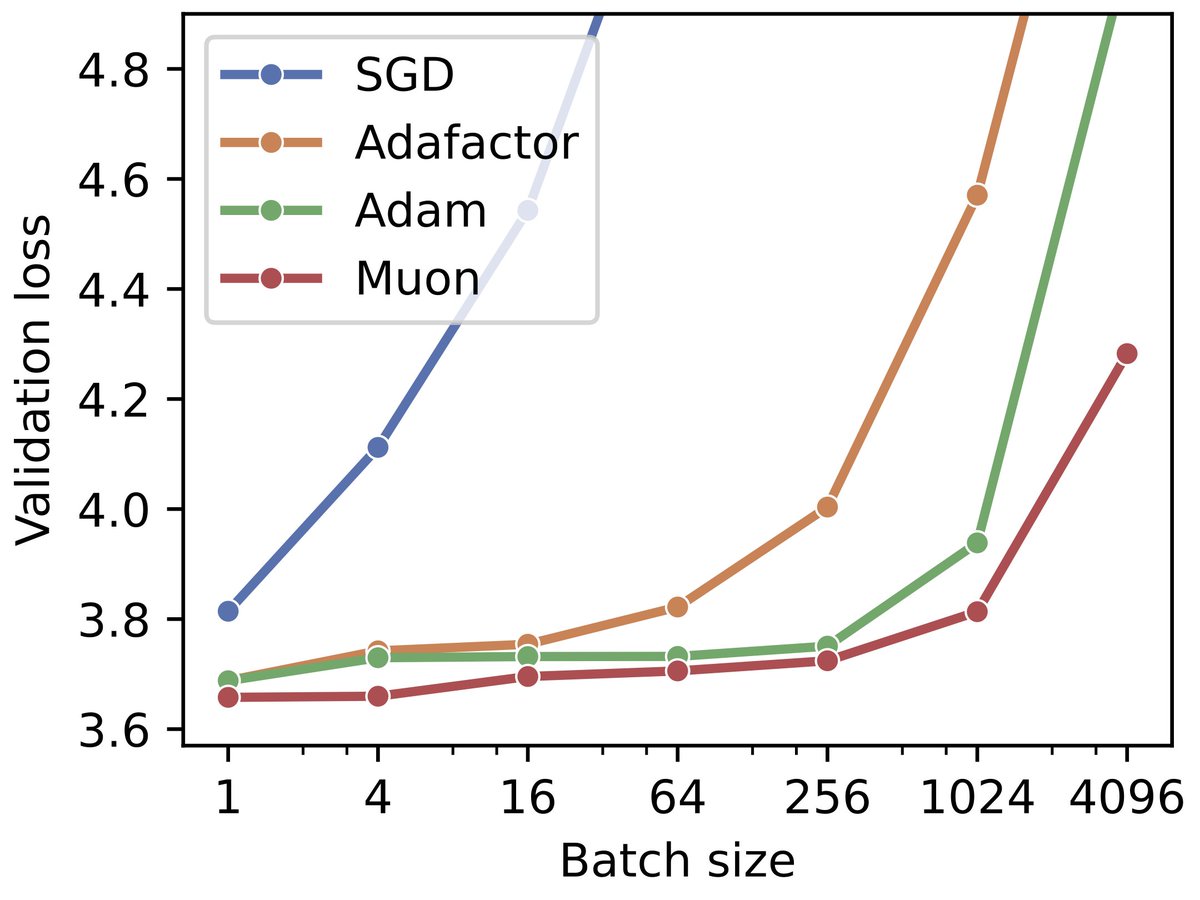
On top of hyperparameter robustness, small batch training makes training robust to the choice of optimizer too. We observe great performance with memory-efficient optimizers like Adafactor, and even vanilla SGD without momentum performs nearly as well as Adam. 7/n
1
8
747
Martin Marek retweeted

10 Jul 2025
The three biggest hps for stable training in everything are lr, bs, and beta2. We’ve built up good intuitions on how to tune them over time, but this lays it all out analytically and convincingly.
this is definitely my new handbook for training big models on small gpus.
10 Jul 2025
🚨 Did you know that small-batch vanilla SGD without momentum (i.e. the first optimizer you learn about in intro ML) is virtually as fast as AdamW for LLM pretraining on a per-FLOP basis? 📜 1/n
3
19
198
20,908
10 Jul 2025
.@giffmana has just retweeted my paper 🙊
10 Jul 2025

This paper is pretty cool; through careful tuning, they show:
- you can train LLMs with batch-size as small as 1, just need smaller lr.
- even plain SGD works at small batch.
- Fancy optims mainly help at larger batch. (This reconciles discrepancy with past ResNet research.)
- At small batch, optim hparams are very insensitive!
I find this cool for two reasons:
1) When we did ScalingViT I also surprisingly found (but never published) that pure SGD works much better than expected. However, a small gap always remained, so we dropped it in favour of (our variant of) AdaFactor. The results here confirm this.
2) This is really good news for fine-tuning on small data with few GPUs. Drop the LoRA and do full fine-tuning with tiny batch-size and plain SGD!
A word of caution, because:
A) This is mostly done at tiny scale (30M params), to allow running many experiments. It is unclear how true the results remain at larger scale, although they do show a 1.3B result, it's usually after larger than 7B that things start to get more difficult.
B) This was all with transformers with QK-Norm, which has very stabilizing effect, I'd be curious if it holds without, but I give it a chance that it might.
C) For large-scale training, running on many (>10k) chips, large batch size is a necessity, not a choice. And they do show that at it's at large batch (not even that large: 4k) fancy optimizers matter significantly.
6
462