
@stanford Professor of Computer Science, @simile_ai co-founder, nationally bestselling author. I build interactive, social, and societal tech.
Joined November 2007
- Tweets 773
- Following 1,886
- Followers 18,856
- Likes 2,800
27 Photos and videos











Natasha is an absolutely stellar designer, elevating everything she touches. Simulation is a blank page for interaction: how do you support people in authoring everything from simple queries to complex simulations, and then make sense of the result?

hey! I recently left Figma and joined @simile_ai as founding designer. I’m stoked to help shape future paradigms for how people interact with simulations. also….we're hiring in NYC & SF 👀 if this sounds like your kind of problem, come build with us!

18
4,378
Michael Bernstein retweeted

hey! I recently left Figma and joined @simile_ai as founding designer. I’m stoked to help shape future paradigms for how people interact with simulations. also….we're hiring in NYC & SF 👀 if this sounds like your kind of problem, come build with us!
26
5
334
42,486
Michael Bernstein retweeted

Jun 2
There’s a lot of existentialism about the role of design in an AI-forward world. And yet there is no one better suited than @natashatenggoro to epitomize what a powerhouse design can be in this new era. Incredibly honored to welcome her to the team 🤩
Since joining Simile, Natasha has uplifted the entire company - crafting a design system that instantly upleveled what customers will experience, building an abundance of prototypes that define the future, not to mention shipping PRs to the core codebase nearly every day.
I’ve always believed that the best work comes from drawing outside the lines. Simile uniquely gives folks the opportunity to do exactly that: building novel products that make cutting-edge research useful and accessible. If you’re interested in drawing outside the lines at the intersection of product and research, reach out 🙂
hey! I recently left Figma and joined @simile_ai as founding designer. I’m stoked to help shape future paradigms for how people interact with simulations. also….we're hiring in NYC & SF 👀 if this sounds like your kind of problem, come build with us!
2
3
54
10,499
Michael Bernstein retweeted

May 15
An Econ PhD student at the 20th ranked program who is working on stuff they are passionate about will have a better job market than one at MIT who's been doing nothing but phd-app-maxxing since undergrad.
People get confused by this because they don't observe *how* successful people came about their insane knowledge bases. It wasn't by relentlessly grinding away at stuff because they had to.
They look at Scott Kominers and say "if i grind and learn as much math as he did, i will be successful." You can't! *You* can't learn as much math as Kominers because he gets energized by configuration results for type ii lattices. You will burn out if you try to do it this way.
You cannot, through grind alone, learn more about the economics of cities than Glaeser, or about how to maximize a value function than Acemoglu.
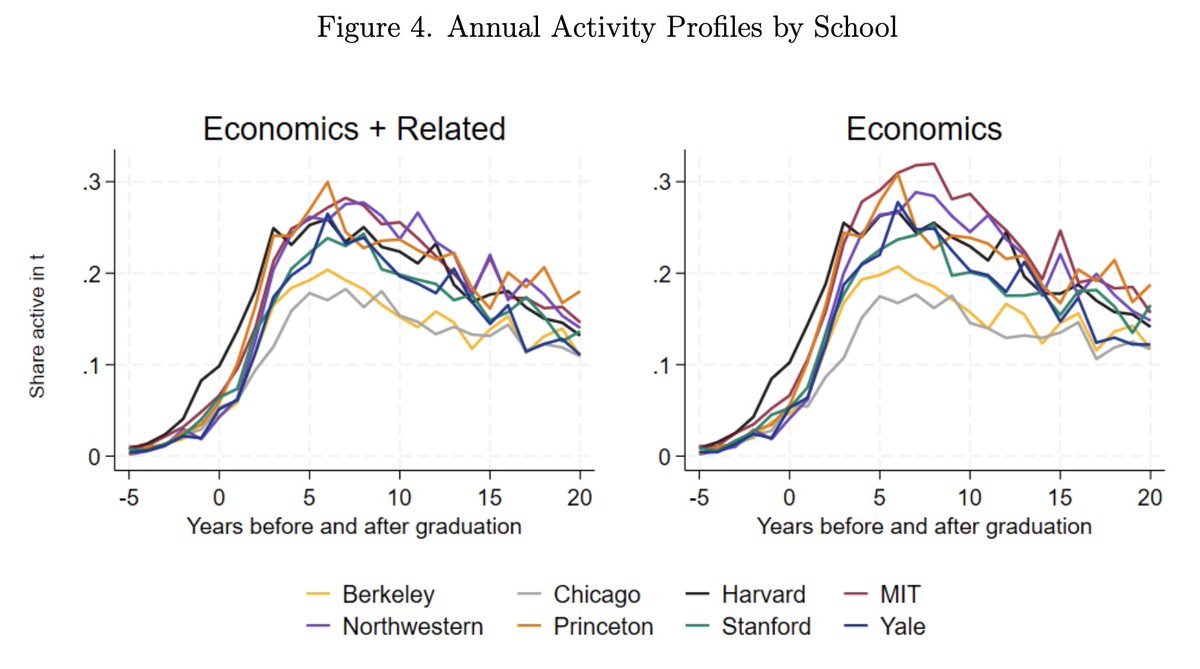
Research careers are long. Most people give up and stop working on research (graph is share of elite PhD graduates with at least one publication in year X after graduation).
If you're starting a PhD, you're presumably doing it to have a successful 40-year research career. The number one factor in whether that happens is not which program you get into, it's whether you find a research angle that energizes you enough to push through the endless barriers an academic career throws in your path.
This is why a lot of the received wisdom around PhD applications is wrong. If you're 100% consumed by the predoc rat race already, it's going to be a long, hard road ahead.
Obv you still have to do admissions, you should study a lot for the GRE, sigh it seems like taking real analysis is probably worth it.
But spending time on the things that energize you about economics is a no-brainer, whether it's policy, or blogging, or whatever, you gotta do the things that light your fire and make you want to be on this road.
32
191
1,601
347,731
Michael Bernstein retweeted

May 5
Honored to lead this merged institute with a new vision and excited to have @drfeifei and John Hennessy advise me.
May 5

Big news! @Stanford is merging @StanfordHAI & Stanford Data Science into a single institute, led by @landay. Continuing under the HAI name, the institute seeks to advance AI & data science for discovery, transform education, and shape AI’s societal impact: news.stanford.edu/stories/20…

6
5
62
10,542
Michael Bernstein retweeted

May 1
It was standing room only at the kick-off for our research series on continual learning. Thank you to @NikzadAfshin (@across_ai ) @sarahookr (@adaption_ai) and @mralbertchun (AI Circle) for hosting!
@oshaikh13 shared his research on human grounding in continual learning. It was so cool to be reminded of the old Apple Knowledge Navigator and how close we are to it and yet how far we still are :) how much easier some questions have gotten and how some remain so hard. Omar, you reminded me of my PhD defense where at some point I annoyed Maneesh so much he said: you can't keep saying "depends on the user context" in response to every question 😅
youtu.be/umJsITGzXd0?si=skoY…
Stay tuned for the next meetup next month and check out Omar's research with @msbernst and @Diyi_Yang :
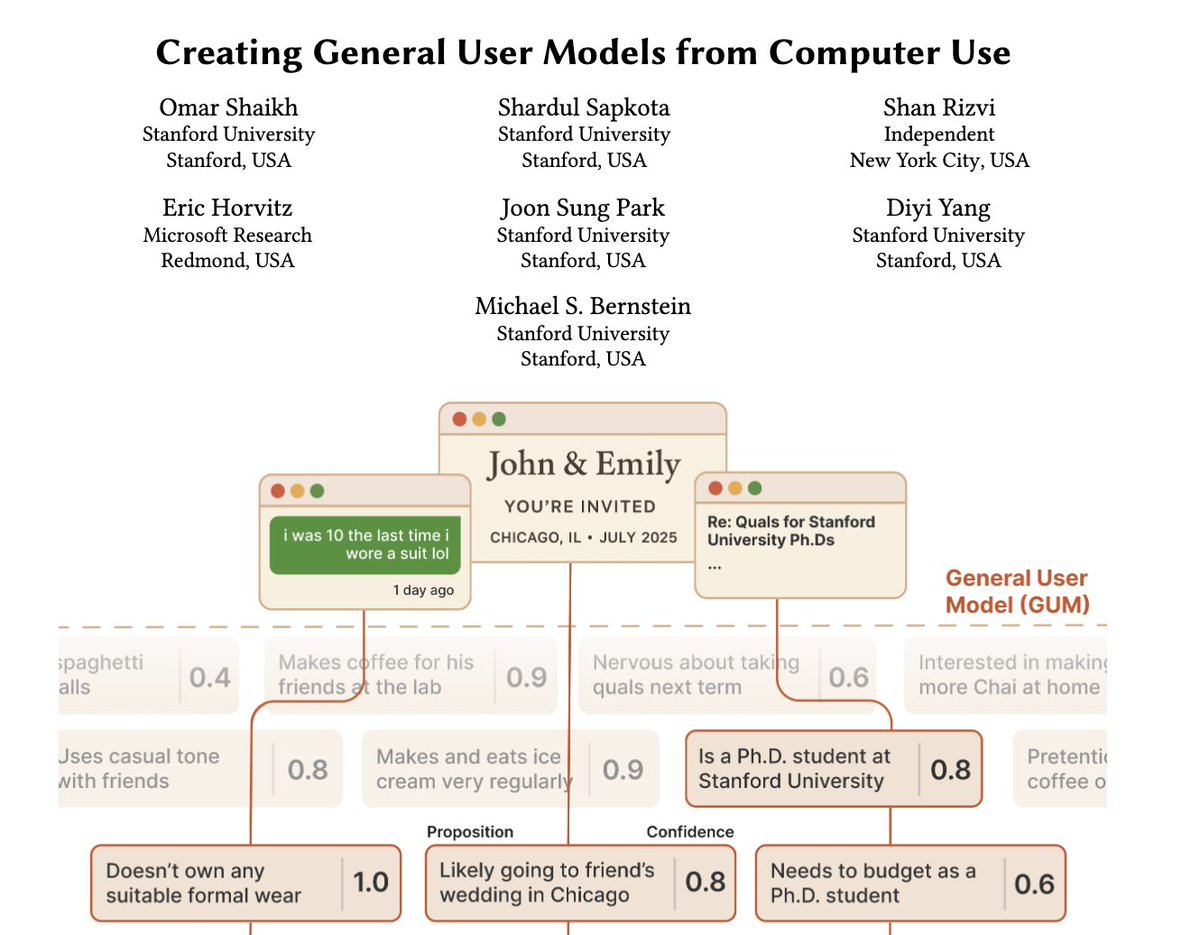
• Creating General User Models from Computer Use (arxiv.org/abs/2505.10831): an architecture for a model that learns about you by observing any interaction with your computer, building confidence-weighted propositions about preferences and intent.
• Learning Next Action Predictors from Human-Computer Interaction (arxiv.org/abs/2603.05923): predicting a user's next action from their full multimodal interaction history (screenshots, clicks, sensor data) rather than just typed prompts.



2
5
30
9,223
Michael Bernstein retweeted

Apr 21
🎉 Thrilled to have two papers accepted to ACL 2026 main!
1. Graph-based models match LLMs on close-ended human simulation tasks with far less compute & greater transparency
2. (oral) How to allocate human samples towards fine-tuning vs post-hoc rectification in simulation


4
19
137
14,518

Apr 21
Research --> product!
Apr 20

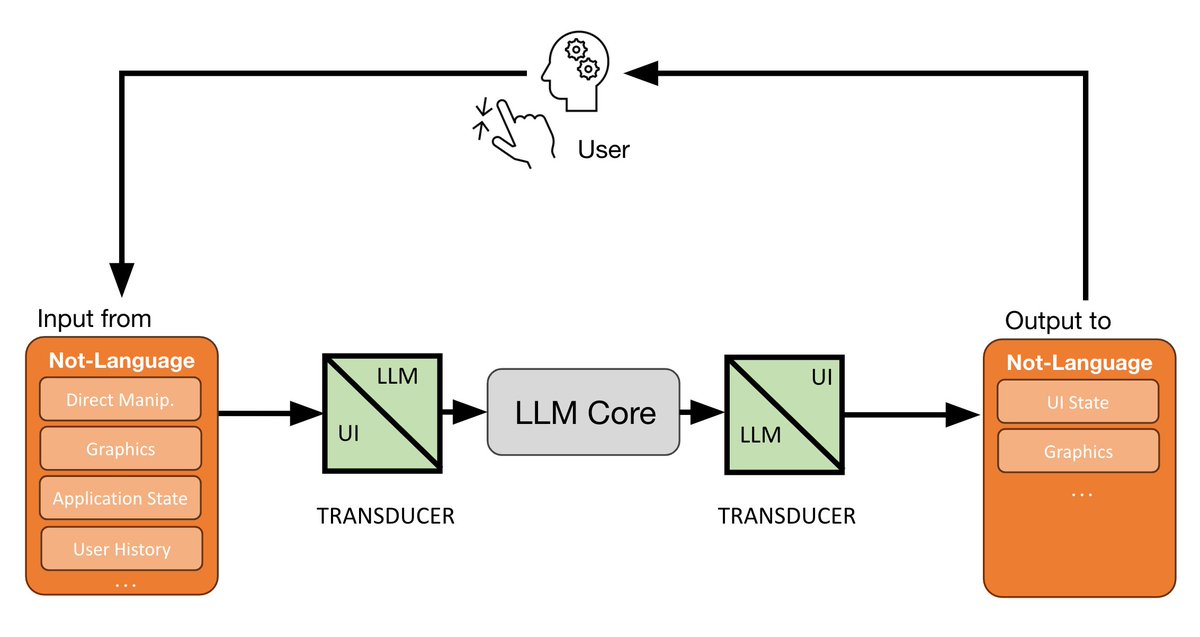
Cool to see Chronicle from @OpenAI 👀This is closely related to what we explored in GUM. Great to see these ideas making it into products!!! arxiv.org/pdf/2505.10831
28
4,768
Michael Bernstein retweeted

Apr 15
This is one of my fav figures in our paper. You can:
1. Identify a user's objective by observing general interaction with their computer.
2. Use it to construct a "just in time" rubric.
3. Sample bunch from model and SCALE TEST TIME COMPUTE ON LITERALLY ANY OPEN-ENDED TASK?!?
Apr 15

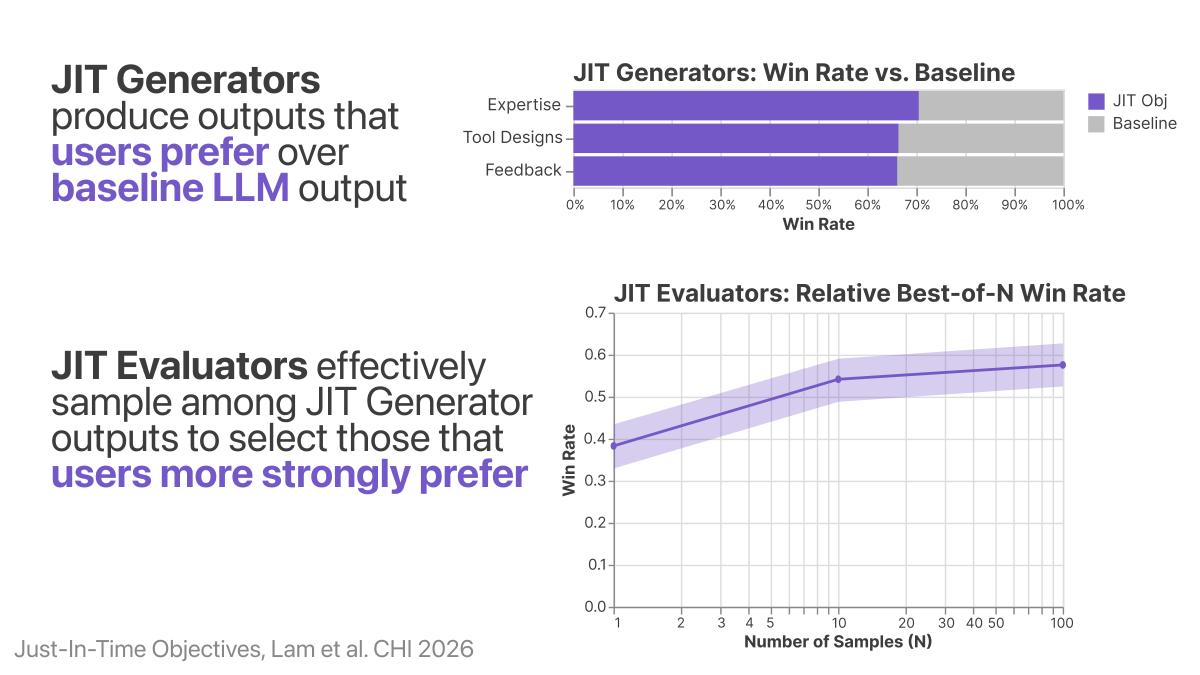
Once you have JIT objectives, you can embed them into various LLM architectures via existing generators and evaluators. Evaluations on N=205 participant-provided inputs show that JIT objectives produce user-preferred outputs, whether generating experts, tools, or feedback.
5
34
9,376
Apr 16
This paper was a fascinating experience where, when we first submitted it, reviewers refused to believe that we could create contentious social media content with LLMs. This time around, they saw it as the main point of novelty.
As time passed, our work got _more_ novel?
Apr 14

2. Mapping the Spiral of Silence: Surveying Unspoken Opinions in Online Communities
w/ @Diyi_Yang @msbernst
We introduce a human–AI pipeline to measure the spiral of silence across political subreddits, revealing how community design shapes when people choose to stay silent online.
Preprint: arxiv.org/abs/2502.00952
1
24
2,936
Apr 16
"Algorithmic feeds are the first at-scale misaligned AIs"
Apr 14
1. Value Alignment of Social Media Ranking Algorithms
w/ @FarnazJ_ @tizianopiccardi @_ziv_e Zach Robertson @sanmikoyejo @msbernst
We present a generalizable method for aligning social media feeds to users’ values, showing with 400 users that value-driven rankings produce meaningfully aligned feeds using their own Twitter data.
Preprint: arxiv.org/abs/2509.14434

11
44
5,371
Apr 16
Best paper honorable mention at CHI — instantly adaptive objectives for LMs as you use your computer
Apr 15
Most of what I actually need help with, I never think to tell a model. But why is it on me to remember?
Our new paper asks: what if AI could proactively specialize to individuals and the tasks they’re carrying out at this very moment? 🧵
3
38
4,515
Michael Bernstein retweeted

Apr 15
Most of what I actually need help with, I never think to tell a model. But why is it on me to remember?
Our new paper asks: what if AI could proactively specialize to individuals and the tasks they’re carrying out at this very moment? 🧵
13
44
261
44,415
Michael Bernstein retweeted

Damn, this was actually very good. Ended up watching the whole hour.

17
752
8,093
1,484,970
Michael Bernstein retweeted

MIT postdoc opportunity! We're hiring a human-AI interaction postdoc (HCI ML/RL) to train agents that deepen how people think and collaborate - rewarded by how humans actually build skill together. With @arvindsatya1 @ZanaBucinca, me & more! Apply by May 1 tinyurl.com/4jsr8ee9
3
18
121
13,186
Michael Bernstein retweeted
Mar 17
GitHub: github.com/GeneralUserModels…
For example: here’s @gandhikanishk following the Australia v. Zimbabwe match while monitoring a training run. All annotated with NAPsack!
2
1
15
1,498
Michael Bernstein retweeted
Mar 17
Passive interaction data is super underrated.
Recruit users, observe what they're already doing (and willing to share!), and label those trajectories with a VLM! It's free lunch!!!!
We're releasing an open-source package (NAPsack) to do this, tested on 1.9M screenshots.
🧵

6
30
137
23,365
Michael Bernstein retweeted

Mar 10
We trained our models to solve problems with objective answers. But can we build models that solve problems where success is subjective, messy, and human? The latter is even more impactful imo.
Agree with Percy: simulation is the next frontier for AI.
Mar 10

I think it’s pretty clear that simulation is the next frontier for AI.
The most impressive feats of AI to date are when we have a clear environment reward, whether it be beating Le Sedol at Go, winning an IMO gold medal, or writing entire apps from scratch. In these cases, the RL algorithm can try different actions, and observe the well-defined consequences in the safety of a docker container.
But what about messy real-world situations involving people? The rewards are unclear, the stakes are high, and you can’t experiment in the real world. But these situations are precisely where the next big opportunity in AI is. To crack this, we need to *simulate* society (“put society into a docker container”). Concretely, this means building a model that can predict what will happen in any given situation (real or hypothetical). If we can do this, we are only limited by our imagination: predict the future, optimize for better outcomes, answer hypothetical (“what if”) questions. Ultimately, this goes beyond making better decisions, but it’s about giving us a better understanding of ourselves and the world.
Simulation is the whole enchilada. And this is exactly the research that @simile_ai is working on. Read more here:
simile.ai/blog/simulation-ne…
6
4
94
16,087
Michael Bernstein retweeted

Mar 10
Current AI is reactive. You prompt, it responds. True proactivity requires predicting what you'll do before you ask.
Our new work done by @oshaikh13 formalizes this as Next Action Prediction (NAP ): given a user's computer use, predict their next action.
We annotated 360K actions across 1 month of continuous computer use from 20 users and open-sourced a pipeline for private-infra labeling. LongNAP combines parametric in-context learning to reason over long interaction traces.
This is one step closer to an assistant that proactively anticipates, not just reactively responds 🚀
Mar 10

What’s the point of a “helpful assistant” if you have to always tell it what to do next?
In a new paper, we introduce a reasoning model that predicts what you’ll do next over long contexts (LongNAP 💤).
We trained it on 1,800 hours of computer use from 20 users.
🧵
8
28
290
52,033
Mar 10
Predict what the user will do next: a task that underlies a huge number of goals. Better assistants, better user models, the next generation of operating system metaphors...
Mar 10
What’s the point of a “helpful assistant” if you have to always tell it what to do next?
In a new paper, we introduce a reasoning model that predicts what you’ll do next over long contexts (LongNAP 💤).
We trained it on 1,800 hours of computer use from 20 users.
🧵
3
20
2,633