
working on #nlproc at University of Arizona
Joined November 2011
- Tweets 2,749
- Following 167
- Followers 1,306
- Likes 326
89 Photos and videos












Mihai Surdeanu retweeted

12 Dec 2025
The Computer Science Department at U.Arizona is looking to hire multiple tenure-track and multiple teaching faculty this year. If you are searching for a faculty position and like sunshine, consider applying! ☀️🌵 cs.arizona.edu/currently-ope…
2
2
834
Mihai Surdeanu retweeted

4 Sep 2025
Co-authors: @Yminglai @Vikas_NLP_UA @msurd — thank you! See you in Suzhou, Nov 4–9. 🙏 #EMNLP2025 (6/6)
1
1
244
Mihai Surdeanu retweeted

24 Aug 2025
Now that school is starting for lots of folks, it's time for a new release of Speech and Language Processing! Jim and I added all sorts of material for the August 2025 release! With slides to match! Check it out here: web.stanford.edu/~jurafsky/s…
9
69
399
34,913

25 Aug 2025
An important new EMNLP paper coming from our lab, with several nice and cool co-authors :)
22 Aug 2025

Our paper accepted at EMNLP 2025 Main! 🎉 @emnlpmeeting
“How Is LLM Reasoning Distracted by Irrelevant Context? An Analysis Using a Controlled Benchmark”
👉 arxiv.org/abs/2505.18761
📌 We introduce GSM-DC: a controlled benchmark for reasoning under Irrelevant Context (IC).
We systematically vary reasoning depth and IC level via a knowledge DAG to study LLM reasoning behavior under distractions, not just accuracy🧭
👥 Huge thanks to my awesome team:
@_ethan_huang @LiangZhang4825 @msurd @WilliamWangNLP @PanLiangming


7
462
Mihai Surdeanu retweeted

20 Aug 2025
This is actually a really solid context engineering template.
Kudos, @AnthropicAI

63
605
7,896
910,824
Mihai Surdeanu retweeted

25 Apr 2025
Today (4/25, 11am EST)! In our final CS Colloquium of this series, @msurd shares how combining symbolic rules with neural models leads to more explainable information extraction. #NLP #ExplainableAI @KCSciences_UML @uarizona
see details👉 ow.ly/fZL250BGU4M
1
2
358
3 Apr 2025
I am truly humbled to receive this award. It represents everything I stand for. I consider it the apex of my career.
3
29
536
Mihai Surdeanu retweeted

21 Mar 2025
We created SuperBPE🚀, a *superword* tokenizer that includes tokens spanning multiple words.
When pretraining at 8B scale, SuperBPE models consistently outperform the BPE baseline on 30 downstream tasks ( 8% MMLU), while also being 27% more efficient at inference time.🧵

ALT Segmentation of the sentence "By the way, I am a fan of the Milky Way" under BPE and SuperBPE.
93
324
2,773
369,959
16 Feb 2025
Our new paper in Findings of NAACL 2025, with Vlad Negru, @robert_nlp, @CameliaLemnaru, and Rodica Potolea, proposes a new, softer take on Natural Logic, where alignment is generated through text morphing. This yields robust performance cross domain. arxiv.org/abs/2502.09567
5
24
5,296
Mihai Surdeanu retweeted

9 Jan 2025
Using AI-assisted coding to build software prototypes is an important way to quickly explore many ideas and invent new things. In this and future posts, I’d like to share with you some best practices for prototyping simple web apps. This post will focus on one idea: being opinionated about the software stack.
The software stack I personally use changes every few weeks. There are many good alternatives to these choices, and if you pick a preferred software stack and become familiar with its components, you’ll be able to develop more quickly. But as an illustration, here’s my current default:
- Python with FastAPI for building web-hosted APIs: I develop primarily in Python, so that’s a natural choice for me. If you’re a JavaScript/TypeScript developer, you’ll likely make a different choice. I’ve found FastAPI really easy to use and scalable for deploying web services (APIs) hosted in Python.
- Uvicorn to run the backend application server (to execute code and serve web pages) for local testing on my laptop.
- If deploying on the cloud, then either Heroku for small apps or AWS Elastic Beanstalk for larger ones (disclosure: I serve on Amazon’s board of directors): There are many services for deploying jobs, including HuggingFace Spaces, Railway, Google’s Firebase, Vercel, and others. Many of these work fine, and becoming familiar with just 1 or 2 will simplify your development process.
- MongoDB for NoSQL database: While traditional SQL databases are amazing feats of engineering that result in highly efficient and reliable data storage, the need to define the database structure (or schema) slows down prototyping. If you really need speed and ease of implementation, then dumping most of your data into a NoSQL (unstructured or semi-structured) database such as MongoDB lets you write code quickly and sort out later exactly what you want to do with the data. This is sometimes called schema-on-write, as opposed to schema-on-read. Mind you, if an application goes to scaled production, there are many use cases where a more structured SQL database is significantly more reliable and scalable.
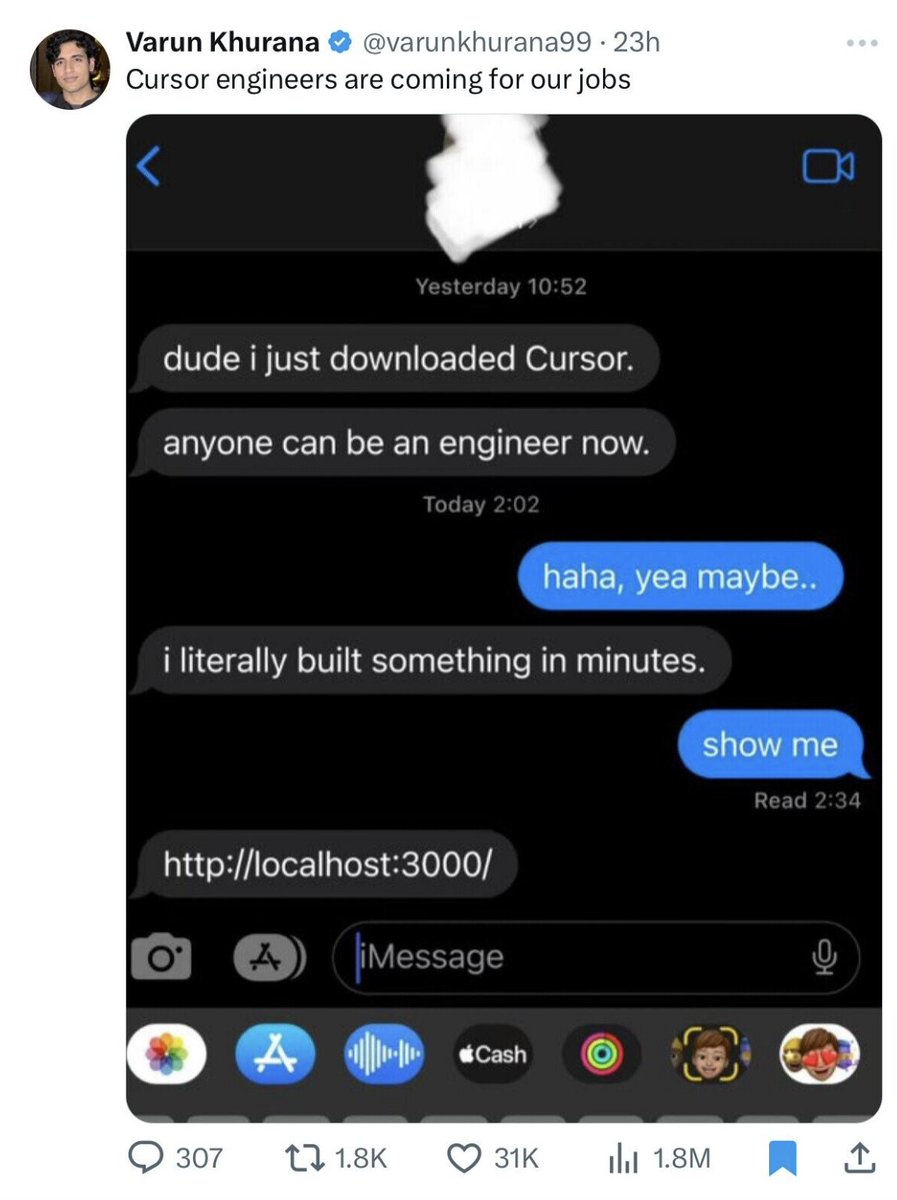
- OpenAI’s o1 and Anthropic’s Claude 3.5 Sonnet for coding assistance, often by prompting directly (when operating at the conceptual/design level). Also occasionally Cursor (when operating at the code level). I hope never to have to code again without AI assistance! Claude 3.5 Sonnet is widely regarded as one of the best coding models. And o1 is incredible at planning and building more complex software modules, but you do have to learn to prompt it differently.
On top of all this, of course, I use many AI tools to manage agentic workflows, data ingestion, retrieval augmented generation, and so on. DeepLearning.AI and our wonderful partners offer courses on many of these tools.
My personal software stack continues to evolve regularly. Components enter or fall out of my default stack every few weeks as I learn new ways to do things. So please don’t feel obliged to use the components I do, but perhaps some of them can be a helpful starting point if you are still deciding what to use. Interestingly, I have found most LLMs not very good at recommending a software stack. I suspect their training sets include too much “hype” on specific choices, so I don’t fully trust them to tell me what to use. And if you can be opinionated and give your LLM directions on the software stack you want it to build on, I think you’ll get better results.
A lot of the software stack is still maturing, and I think many of these components will continue to improve. With my stack, I regularly build prototypes in hours that, without AI assistance, would have taken me days or longer. I hope you, too, will have fun building many prototypes!
[Original text: deeplearning.ai/the-batch/is… ]
118
443
3,048
293,617
Mihai Surdeanu retweeted

6 Jan 2025
🚀 Registration for CLEF 2025 Labs is NOW OPEN! Don’t miss your chance to participate in this year’s CheckThat! Lab, where we tackle some of the most critical challenges in fact-checking and information verification.
🔥 Why Join CheckThat! Lab?
This year, we bring you four cutting-edge tasks designed to advance the boundaries of Natural Language Processing and Multilingual Fact-Checking:
🔍 Task 1: Subjectivity
Detect subjective text and pave the way for a refined fact-checking pipeline.
🌍 Languages: Arabic, English, Bulgarian, German, Italian, and Multilingual
✏️ Task 2: Claims Extraction & Normalization
Simplify and normalize social media claims across 20 languages!
🌍 Languages Include: English, Arabic, Hindi, Spanish, Thai, and more
📊 Task 3: Fact-Checking Numerical Claims
Verify numerical claims.
🌍 Languages: Arabic, English, Spanish
🔬 Task 4: Scientific Web Discourse
Classify online scientific discourse and retrive the mentioned paper from a pool of candidate papers
🌍 Language: English
🎓 Who Should Join?
Researchers, students, and professionals in NLP, AI, and fact-checking eager to make an impact.
👉 Register Now: clef2025-labs-registration.d…
👉 Learn More: checkthat.gitlab.io/
👉 Access Data & Code: gitlab.com/checkthat_lab/cle…
🗓️ Key Dates to Remember:
November 2024: Registration opens
December 2024: Training materials released
April–May 2025: Evaluation cycle

2
2
488
6 Jan 2025
Over the break, I simplified the most common usage of our #nlproc library: clulab.org/processors/basic.…
3
203
Mihai Surdeanu retweeted

17 Dec 2024
and it is like that with any sufficiently challenging NLP task. LLMs are way better than before, but not perfect, and cannot really be improved in an interesting way. frustrating. but we should focus on *other* opportunities they bring, not the old tasks in which we are stuck.
5
3
57
3,156
Mihai Surdeanu retweeted

17 Dec 2024
Announcement #1: our call for papers is up! 🎉
colmweb.org/cfp.html
And excited to announce the COLM 2025 program chairs @yoavartzi @eunsolc @RanjayKrishna and @AdtRaghunathan


1
41
163
23,025
15 Dec 2024
I just finished teaching an introduction to deep learning course based on our textbook. All content (book, slides, code) is available here: clulab.org/gentlenlp/
1
16
670
Mihai Surdeanu retweeted

6 Dec 2024
Check out our new benchmark on Evaluating LMs as Synthetic Data Generators!
Main findings:
- LMs' ability to generate synthetic data varies
- This is not necessarily correlated with problem solving ability
- More data from cheaper models is often better than less from stronger
6 Dec 2024

#NLProc
Just because GPT-4o is 17 times more expensive than GPT-4o-mini, does that mean it generates synthetic data 17 times better?
Introducing the AgoraBench, a benchmark for evaluating data generation capabilities of LMs.

27
132
9,658