
Joined April 2008
- Tweets 17,213
- Following 889
- Followers 2,517
- Likes 7,299
492 Photos and videos
















May 21
Not dead…just demoted to opera chorus


85
Apr 17
Absolutely cannot let this happen
Apr 16

Destroying a library brings the dark ages.
38
Mar 18
Indeed. And take that a step further in learning more deeply exactly how these applications were. In addition to RAG, LLMs use training data with RLHF for ground truth. The problem here is that often the human feedback comes from developers and not human factors practitioners.
Mar 18

"Grounding" Doesn't Mean What You Think It Means 🗺️
Words matter, especially when they're quietly reshaping how an entire industry thinks.
"Grounding" comes from "ground truth," rooted in statistics and originally cartography, where it literally meant going outside to verify that your map matched reality.
In some AI models, "ground truth" is the objectively correct real-world data, like sensor readings or medical records, used to anchor the model to reality. Not documents. Not web pages. Reality.
The core problem with LLMs is that there's no ground truth signal during training or generation. The model isn't checking its answer against the facts; it's only predicting the next most likely word.
What Microsoft, a company I deeply respect admire, calls "grounding" is actually RAG (Retrieval-Augmented Generation): retrieving web documents to supplement a response. Useful! But web text is written by humans, about reality, not reality itself. Those documents can be wrong, biased, SEO-manipulated, or outdated.
RAG is better-informed guessing. True "grounding" is fundamentally a different thing.
The uncomfortable part: Microsoft's own AI Guide features a quote from me where, after significant pushback on their "grounding" framing during a long interview, I said: "RAG does help the LLM ground its response in information from the web, but it's worth remembering that not everything online is true." The caveat got published. The correction didn't & the term has escaped into GEO AIO E-I-E-I-O gauntlet.
I've since watched real people repeat versions of Microsoft's definition & treat it as fact. And I don't blame them. They're trying to keep up with all of these changes.
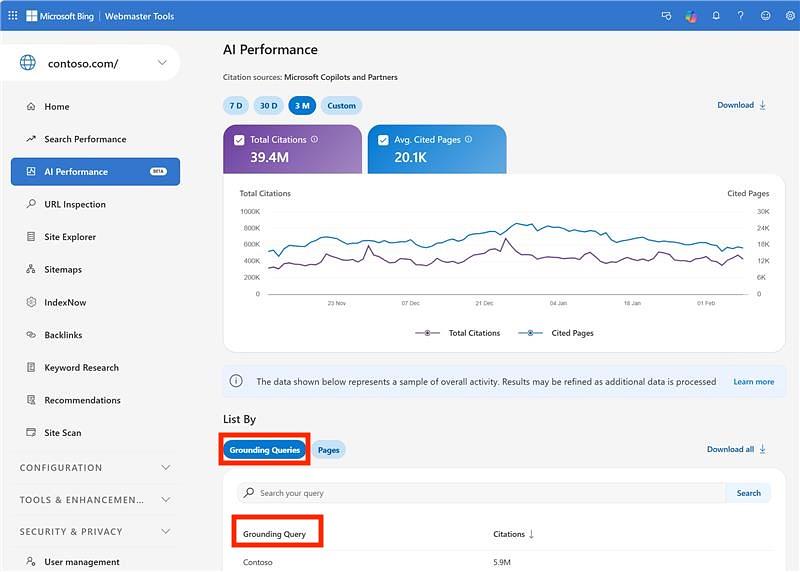
Microsoft's new "Grounding Queries" metric in Bing Webmaster Tools makes this even more confusing. Those aren't user queries. They're background searches AI quietly generates when a user submits a prompt.
For example, when you ask "should I bring an umbrella in Seattle?" the AI might internally generate "Seattle weather today" to inform its response.
Calling those "grounding queries" buries an already-misused term one layer deeper.
I raised this concern with Microsoft & suggested alternatives like "Retrieval Queries" or "AI Queries," which I feel would be more accurate and less confusing but to no avail.
The real irony? Microsoft employs SO many world-class AI researchers. They know the difference. By rebranding RAG and synthetic AI queries as "grounding," a precise technical term has now become a marketing buzzword.
SEOs are now optimizing for a word we don't have a shared definition of. And when AI researchers hear you use "grounding" this way, it'll erode your credibility.
As AI continues to reshape industries, it's more important than ever for us to understand these nuances. By learning the true meaning behind AI terms & tech we can communicate more effectively, make better decisions & drive real results.
19 Days until the next Actionable AI For Marketers Course 🎓


1
49
Mar 12
And there are humans, enterprise information architects, that are qualified to do so with both technical and behavioral expertise. Cross discipline education and cooperation is our path to more humane AI.
Mar 12

The bottleneck of current AI is simple: the techniques we use are still predicated on pattern memorization and retrieval, and thus they need *someone* to tell them which patterns to memorize (training data, RL envs...)
That role cannot yet be played by AI in a truly open-ended and autonomous way. We can't yet remove the humans in the loop. In that sense, current AI is still purely a reflection of human cognition (both in terms of which tasks/goals it pursues and the patterns it uses to solve them). It isn't yet its own thing.
1
1
60
Mar 6
Note to us all: Google is not our friend. Never has been. Never will be. It is a publicly traded company whose mission is to make money for stockholders through search dominance.
Mar 6

Google is gaslighting the entire SEO industry about JavaScript.
I have the receipts.
This week Google removed the "Design for accessibility" section from their official JavaScript SEO documentation. Their reason? JavaScript rendering is "no longer a barrier" for Google Search.
I nearly choked on my coffee.
I manage SEO across hundreds of properties. I see what actually happens when Google tries to render JavaScript sites. Every single day. This is the fifth update to the same document since December 2025, part of a systematic campaign to replace broad cautions with specific technical guidance
Here is what I see that Google apparently does not.
Content behind tabs, accordions, and "load more" buttons? Completely invisible. Google does not click. Google does not scroll. Google does not interact. That content simply does not exist for them.
Structured data injected via JavaScript? Random. Google's own documentation on developers.google.com admits that JS-generated Product markup makes shopping crawls less frequent and less reliable. I see it break constantly.
Images loaded through JavaScript? Good luck getting those indexed. Lazy-loaded images behind interaction events are a black hole. Internal links rendered via JavaScript? Onely proved Google needs 9x more time to crawl JS pages than plain HTML. Nine times. Their experiment showed 313 hours for JS versus 36 hours for HTML to reach the same depth. A 2024 counterpoint study by Vercel/MERJ found most pages rendered within minutes.
And here is the part nobody is talking about.
AI crawlers cannot render JavaScript at all. GPTBot, ClaudeBot, PerplexityBot. They see raw HTML only. Onely's 2025 research estimated about 70% of modern websites may be completely invisible to AI search because of JavaScript dependencies.
So Google removes the warning. Developers lean harder into client-side rendering. And what happens?
Sites become more dependent on Google's proprietary rendering pipeline while going completely dark for every competing search and AI system.
Convenient timing.
Google is not telling you JavaScript is fine because it is fine. Google is telling you JavaScript is fine because it benefits Google.
Server-side rendering is not optional. It never was. Do not let a documentation update convince you otherwise.
Sources:
1. Barry Schwartz, "Loading Content With JavaScript Does Not Make It Harder For Google Search" Mar 5, 2026
2. Google Developers, JavaScript SEO Basics (the removed section)
3. Google Developers, Structured Data with JavaScript (the shopping crawl admission)
4. Vercel "How Google handles JavaScript throughout the indexing process" Jul 20224
3
196
Mar 4
Indeed.

40
Feb 23
Word. It is not a substitute it is a tool.
Feb 21
The best way to use AI is an interface to information that lets you deepen and improve your own knowledge and mental models. The worst way to use AI is as a crutch to outsource and forsake your own cognition
32
Feb 19
Partial credit as they are also learning as they go
Feb 19

Why do LLMs suck so much?
It's not because they are as stupid as you think.
It's because they are balancing quality with... speed.
It's been bothering me for such a long time:
Google is so focused and has made so much progress on separating out quality content from low-quality content on the SERP, but its AI properties seem so far behind. Why don't they utilize those quality systems they already have more?!
And it's so simple, and I feel like such a putz for not seeing this clearer sooner...
It's because they are prioritizing speed. (h/t Matt G. Southern & @sejournal's coverage of Google's Jeff Dean's recent interview)
They will figure this out. Other LLMs will also figure out the balance between quality and speed as the tech evolves.
What's the upshot?
If you are trying to hack for LLM visibility, you are basically betting on LLMs NOT figuring out how to keep the speed while increasing quality.
I have never placed a bet in my life, but that seems like a stupid bet!
1
67
Marianne Sweeny retweeted

Feb 18
If you're a researcher in academia using Keras 3 (PhD student, postdoc, professor...) and you want to train on TPUs, you could receive compute awards from Google for your research. Google is running a new academic grant program, separate from the TPU research cloud.
You can contact me with a few words about your research and I can refer you -- francois.chollet@gmail.com
22
103
1,018
78,932
Jan 9
First, John, Barry and others are not subject matter experts for Gemini and generative search. They offer stellar guidance on what SEO should focus on.
Second, it is NOT POSSIBLE to optimize for generative search, AIO or any other neural component of online information retrieva.
Jan 9

This one caught my eye.
Check out the transcript below to see Danny Sullivan from Google's perspective on "chunking content" - one of the most popular techniques currently believed to improve discoverability in AI search.
In the past year or so, I've seen many different interpretations and approaches for how to "chunk" content, and in many cases - yes, some of them can and do work well for AI search visibility. For now, at least.
But in this case, I'm reading between the lines a bit...
When you start to hear Googlers commenting on popular, widespread SEO/AEO tactics (and talking to their engineering teams about those tactics), my 'SEO spidey senses' start to go off.
We've seen this pattern so many times before, and it's why I spent last year giving multiple presentations about the 'cycle of SEO' (link in comments):
SEO/AEOs discover an effective tactic for driving traffic/visibility that is more focused on optimizing for machines, rather than humans ➡️
SEO/AEOs share this tip with the masses, lots of tools are built to automate and scale these tactics ➡️
Google identifies widespread use of this tactic and determines it's not great for their users ➡️
Google develops systems/policies to demote or penalize these tactics either algorithmically or through updated spam policies (this part can take a while to get right) ➡️
The tactic no longer works, and misusing/abusing it can lead to major setbacks in performance.
It will be interesting to see how this one pans out because we haven't had any clear examples yet of AI search-specific tactics being demoted in the way many SEO approaches have been over the years with algorithm updates, penalties, etc. But as AI search is evolving, it would make sense that Google would have to update its own systems accordingly.
Now, I'm not saying "don't chunk your content." As always, I would recommend only adjusting your content in ways that are *also helpful and valuable for your readers,* not just blindly following what a tool (or an LLM, lol) told you to do.
I've also heard a lot of noise about "writing for machines, not humans" in the past year. I would be very careful to follow that advice, as it is literally the exact opposite of the guidance Google provides in all of its documentation.
Like it or not, Google is still here, and your performance on Google has a massive impact on your overall performance in Search - yes, including AI Search.
1
1
71
Jan 6
Maybe add some information scientists, content strategists, user experience professionals, information architects and search optimization professionals? This entries that the human users protected by these standards have a voice as well.
41
10 Dec 2025
Yes, it certainly can be of the client has ranking content for contextually similar topics. Next SEO ships it’s focused to user engagement on the site. What the site ranks for and where is an indication of the strength of content for that query.
10 Dec 2025

Long-Tail Is The FUTURE (for Both SEO and AI SEO) open.substack.com/pub/annsma…
1
42
12 Nov 2025
Interesting. Question: what do they mean by "original research?"
For some reason, this reminds me of the joke about an interview where one applicant answered the question:" What is 2 2?" with "What do you want it to be?"
12 Nov 2025


35
Marianne Sweeny retweeted

13 Oct 2025
The #1 Skill to Master AI Isn't What You Think (Hint: It's Not Prompt Engineering).
1/16
You know that frustrating feeling when you ask an AI a question and it gives you a useless answer?
You tweak the prompt, add more detail... and it's still not quite right.
What if the problem isn't the prompt? What if the key to unlocking your AI's true power is your mindset? 🤯
A thread. 🧵
2/16
For years, the AI race has been about one thing: building bigger, "smarter" models that crush static benchmarks like MMLU and GSM8K.
The goal has been to create an AI that can ace any test on its own.
But this has a huge blind spot.
3/16
This approach creates AIs that are brilliant test-takers but terrible collaborators.
It's like training a student to get a perfect SAT score but never teaching them how to work on a team project.
They have the knowledge, but they don't know how to be helpful.
4/16
But a fascinating new paper by Christoph Riedl and Ben Weidmann just flipped this entire idea on its head.
They analyzed 667 people working with AI models (GPT-4o and Llama-3.1-8B) and didn't just look at the AI's score.
They measured something new.
5/16
They measured Human-AI Synergy.
In simple terms: How much smarter does the AI make the human?
They calculated an "AI Boost" for every single person—the exact performance uplift they got from collaborating with the AI.
And that's when things got really weird.
6/16
They found that some people got a HUGE boost from AI, while others got very little.
And it wasn't just about how "smart" the person was. In fact, they proved that your individual problem-solving ability is a completely separate skill from your ability to collaborate with an AI.
So what's the secret sauce that separates the master collaborators from everyone else?
7/16
The secret is a psychological concept called Theory of Mind (ToM).
It's your ability to think about what another agent (person, or in this case, an AI) knows, believes, wants, and intends.
It's basically your capacity for "mind-reading."
(And yes, they actually measured this.)
8/16
The results were stunning.
A person's Theory of Mind score was a massive predictor of their success when working with an AI.
But it had ZERO correlation with their success when working alone.
It's a pure collaboration skill.
9/16
So what does "Theory of Mind" look like when talking to an AI?
It's not about writing hyper-complex, 1,000-word prompts.
It's about the small, social cues you use:
Providing context ("Explain this like I'm 15")
Stating your intent ("My goal is to write a blog post")
Seeking confirmation ("Is my approach correct?")
Challenging the AI ("I think you might be wrong about that")
10/16
Think of it like this:
People who treated the AI like a vending machine (input command → get output) got mediocre results.
People who treated the AI like a brilliant, but slightly clueless, intern got AMAZING results.
They managed the AI, they didn't just command it.
11/16
But here's the part that really blew my mind.
ToM isn't just a fixed trait. The researchers found that moment-to-moment fluctuations matter.
When a user showed more perspective-taking within a single conversation, the quality of the AI's response went up immediately.
Your effort to "mind-read" the AI directly improves its output in real-time.
12/16
So, how can YOU use this?
Stop obsessing over the "perfect prompt."
Start thinking like a manager. Your new mental model for AI interaction shouldn't be "Command → Execute."
It should be "Dialogue → Co-create."
13/16
Here's a simple experiment to try this week. Next time you use an AI, don't just ask a question. Instead:
State your knowledge level: "I'm a total beginner at this..."
Ask it to explain its reasoning: "Can you walk me through your steps?"
Give it a role: "Act as a skeptical editor and critique this paragraph."
Watch what happens.
14/16
This research is so much bigger than just getting better answers from ChatGPT.
It's a roadmap for how humans can effectively partner with new forms of non-human intelligence. It shows that social-cognitive skills are becoming more, not less, valuable in a world filled with AI.
15/16
The future of AI isn't just building a better brain.
It's building a better partner.
And the most important part of any partnership is the effort to understand.
16/16
This is truly game-changing work. If you're fascinated by this, go read the full paper "Quantifying Human-AI Synergy."
All credit to the authors for this incredible insight: Christoph Riedl (@criedl on X) and Ben Weidmann.

9
37
159
9,071

1 Jul 2025
"I don't have specific information about someone named <name> in my knowledge base. This could be because he's not a widely known public figure, or because information about him became available after my knowledge cutoff."
Scraping the Web is how LLM continue to learn.
59
26 Jun 2025
Brilliant reminders for us all…
26 Jun 2025

💥 #SEO some history about Large Language Models and Google.
✅ They are not NEW. The first one credited as the origin point for where we are today was created in 1966. Early models were called Markov Chains.
✅ Google BERT in 2018 was a breakthrough in how language could be read and processed by machine learning algorithms (what we call AI now - incorrectly). It made it faster and reduced resource needs. It could disambiguate a word from a sentence and read forward and backward.
It was NOT used in the Search Results, but was used to help process documents.
✅ BERT is the foundation for ChatGPT and all the other models that have come out since. It set off the arms race.
✅ BERT is a Large Language Model. SEOs have been working with the principles of LLMs in Search for some time, they just did not know it for the most part. (Some did)
✅ GEO is not a thing because you are NOT optimizing the Trillion Token Trained LLM, you are using SEO because ALL LLMs use a Search Engine to bring back the documents (RAG) to help ground the Hallucinatory Summarization Engines (HSEs), otherwise they would often write nonsense.
(Still do but not as often or as badly)
✅ If you are writing for the LLM "Chunking," that is what you would do for Natural Language Processing in Google, and how they pulled Featured Snippets and Passages.
This is more than 7 years old.
It is also just about proper page construction like using headers correctly.
✅ "Fan Out" is NOT NEW and just a function of the machine learning, NLP, and LLMs. Google has also utilized it in the SERPs for features such as "People Also Ask" since 2015.
✅ Using entities and related entities? This was a thing when Google moved from the Bag of Words to Natural Language Understanding (Circa 21011) then even more so when they moved to Natural Language Processing and Large Language Models.
Did you know the final sort order in Google Search Results is created by the Neural Matching Algorithm released in 2018? It is not an LLM, but it is AI.
✅ Are you using special HTML, like bullets and paragraphs, to better define your content? This is what you did for Featured Snippets and Passages.
...and that is just the start of the list...
There is no GEO. You are just catching up to what Google has been doing behind the scenes for more than a decade now, mostly since 2018.
AI Overviews and AI Mode just made you aware of it.
Please stop trying to change the name of the industry based on your sudden awareness of Machine Learning, Natural Language Processing, and Large Language Models, which have been gradually added to Search over the course of 13 years, with much of this development occurring in the last 7 years.
GEO is SEO, and it is not a new concept; it may involve a shift in focus or an additional emphasis on these aspects, but they are not new.
Oh, and if you're looking to increase your knowledge about LLMs, start with machine learning articles about BERT, which is how this AI revolution began.
1
1
78
Marianne Sweeny retweeted

30 May 2025
When a service dog sits in front of you on a plane.. 😅
937
6,743
90,475
4,287,184
30 May 2025
It pains me when I see SEOs who do not understand how today's search landscape works.
SERPS have been personalized for some time using the vast amount of data Google has collected.
AI Overviews are dynamically rendered using prediction.
Current methods are degrading rapidly.
1
1
57
21 May 2025
Indeed and they are. To which I would add; If this is news to you then you've been playing catchup ball for quite some time.
63