
Mec chill qui aime la tech 💻 et les trains 🚆 • Étudiant ingénieur informatique @insadelyon 🎓 • En stage IA 🤖 • Aime les animaux 🌱 • Fork : @mtcbx_v2
Joined July 2013
- Tweets 28,721
- Following 456
- Followers 8,496
- Likes 15,989
2,694 Photos and videos










Pinned Tweet

15 Sep 2025
📱 iOS 26 sera disponible ce soir en version publique, alors voici les principales nouveautés de cette mise à jour qui va métamorphoser votre iPhone ! 🧵
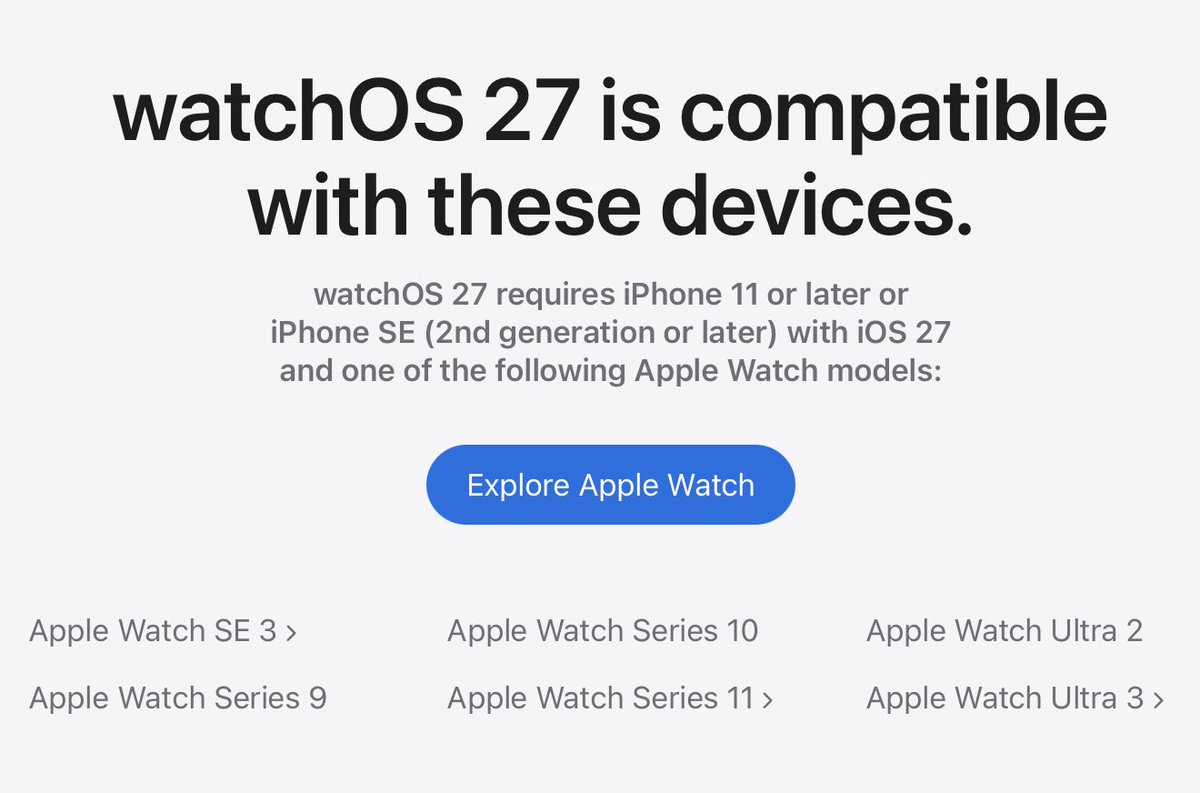
(La liste des iPhone compatibles est à la fin de ce thread.)

37
201
2,167
858,891
10h
Le RN a récemment voté contre l'interdiction du cadmium dans ce qu'on mange, ça me rappelle quand ils ont voté contre l'interdiction des pfas dans les objets du quotidien (après avoir eu un rdv avec des lobbyistes de chez Tefal, bizarrement), c'est assez drôle de parler 24/24 d'insécurité quand ils nous mettent eux-mêmes en danger 🤡
1
14
1,268
Jun 13
Je m'en lasse pas 😩

2
1
31
7,237
Jun 13
Je me demande comment ça se passe sur iOS 27 si une app demande beaucoup de RAM (ou plusieurs apps, ou même une app qui charge un modèle en local par exemple) étant donné que les modèles de fondation sont constamment chargés dans la RAM.
Est-ce que l'OS retire temporairement les modèles de la RAM ou bien l'OS limite artificiellement la RAM dispo pour les apps (ce qui reviendrait à brider la RAM réellement utilisable pour les dev) ?
12
39
8,722
Jun 13
Bon du coup update :
Le modèle AFM 3 Core (le plus léger, à 3B) est effectivement dans la RAM en permanence, il est considéré comme faisant partie de la mémoire système, une partie de la RAM utilisée par le système (isolée de manière virtuelle puisque la RAM est unifiée), et donc les apps ont bien moins de RAM disponible (évidemment ça a toujours été le cas, il y a toujours eu une partie mémoire système, mais pas à une telle proportion), à priori ça ne devrait pas vraiment affecter les perfs puisque les iPhone récents ont bien plus de RAM que nécessaire, sauf peut-être pour le chargement de modèles tiers dans des apps comme Locally AI (le modèle d'Apple ne se décharge pas donc forcément ça limite la RAM qu'on peut allouer à un modèle tiers)
Le modèle AFM 3 Core Advanced est bien plus gros que le précédent, bien trop pour être chargé entièrement dans la RAM (c'est un modèle 20B), donc le modèle reste en mémoire flash (le stockage), mais comme c'est une sorte de MoE (revisitée par Apple, avec une décision par prompt et non une décision par token, sinon trop lent), on charge uniquement les experts nécessaires à chaque prompt dans la RAM (entre 1B et 4B), mais pour éviter une trop forte latence il y a toujours un minimum d'experts "globaux" chargés en RAM en plus d'AFM 3 Core, ce qui doit faire pas mal de RAM bouffée d'office par les modèles de fondation donc (même si ça dépend de comment ils ont quantizé tout ça, mais je trouve aucune info là-dessus)
1
12
897
Jun 13
Allez ça faisait longtemps les photos dans le train (je me suis régalé avec La Vie comme d'hab)
20
1,297
Jun 13
Le gouvernement américain qui ordonne la suspension immédiate de l'accès à Claude Fable/Mythos 5 pour des raisons de sécurité nationale, c'est du jamais vu 💀
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
5
1
44
6,792
Jun 12
J'ai besoin d'un gymbro à Lyon je vais déposer une offre sur Indeed
5
1
13
2,837
Jun 10
Pour celles et ceux qui veulent voir les différences entre les icônes des OS 26 et les icônes des OS 27 d'Apple : basicappleguy.com/basicapple…
2
18
1,368
Jun 10
C'est facile de se vanter de faire du local quand le modèle prend une journée entière pour sa génération (et qu'il laisse l'ombre en plus) 💀

18
4
343
141,653
Jun 10
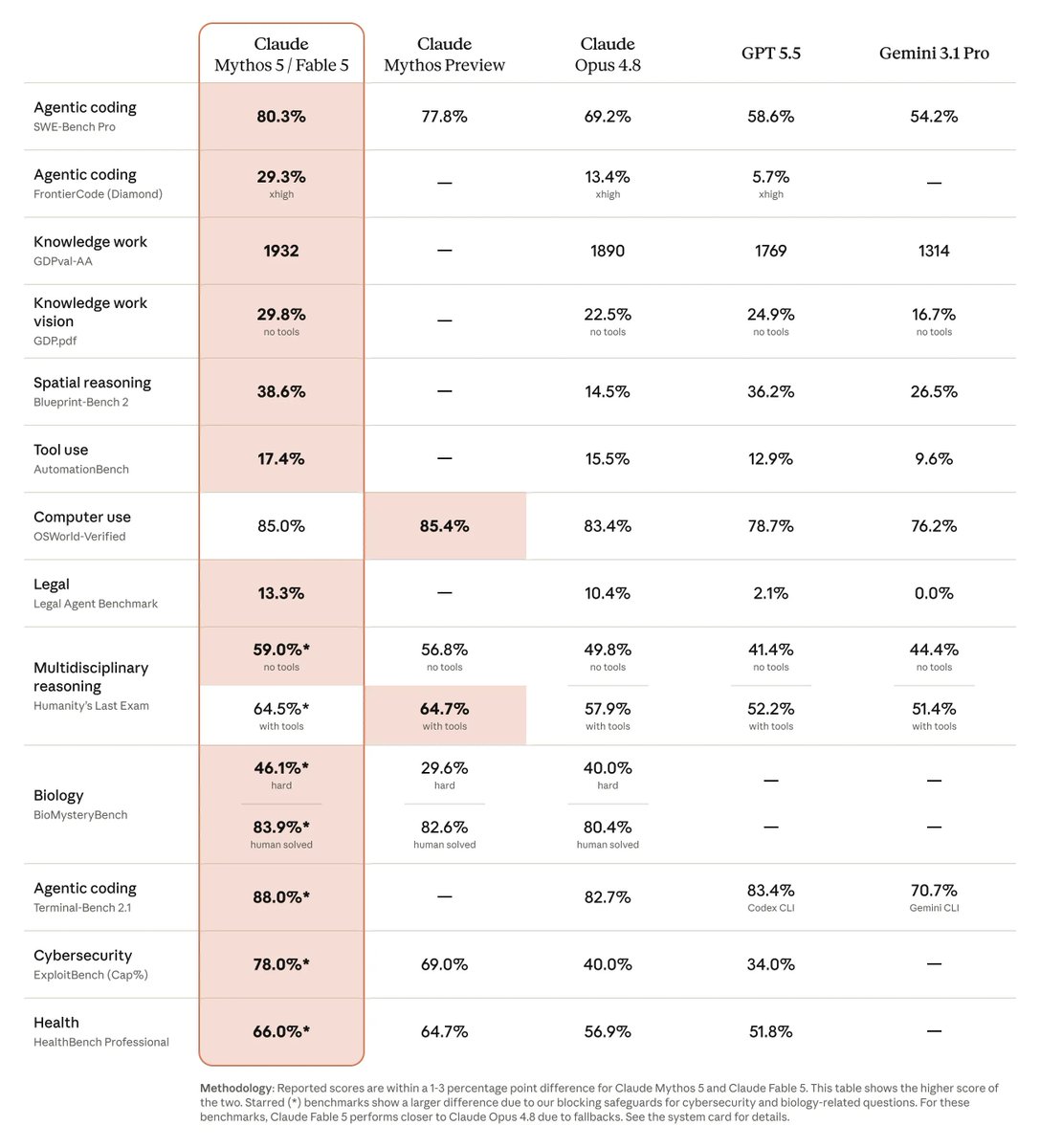
🧠 Anthropic a dévoilé Claude Fable 5 pour le grand public, qui ÉCRASE la concurrence !
C'est le même modèle que Mythos (ce fameux modèle "trop dangereux" pour être rendu public), mais avec des limitations de sécurité qui ne l'autorisent pas à faire n'importe quoi.
4
37
3,641
Mathieu :) retweeted

Apple VS UE
« Laissez les gens choisir » « j’achète ce que je veux », « ce n’est pas une commission non élue qui décide pour moi » etc
Le problème, c’est qu’une majorité boirait du poison ou sauterait d’une falaise pour 2 € de réduction…
30
5
80
9,408

Jun 9
Trop parlé d'Apple ces dernières 24 heures maintenant parlons de mon t-shirt
4
1
55
2,649
Jun 9
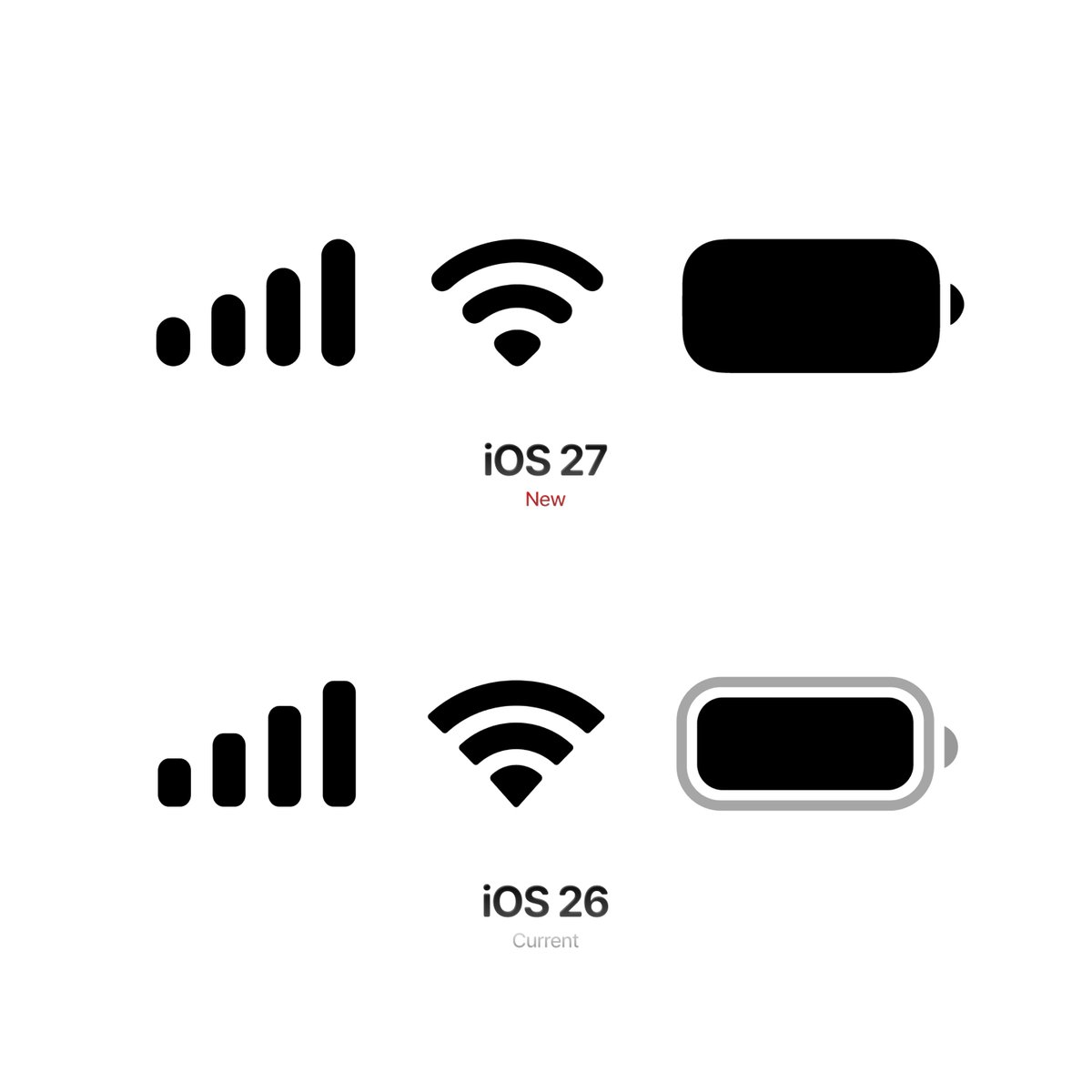
Ça ressemble tellement à Android
(c'est pas une critique)

5
43
8,551