
Tweets on Technology and Art. Views my own @munhitsu@fosstodon.org
Joined September 2007
- Tweets 4,878
- Following 1,584
- Followers 648
- Likes 3,428
868 Photos and videos








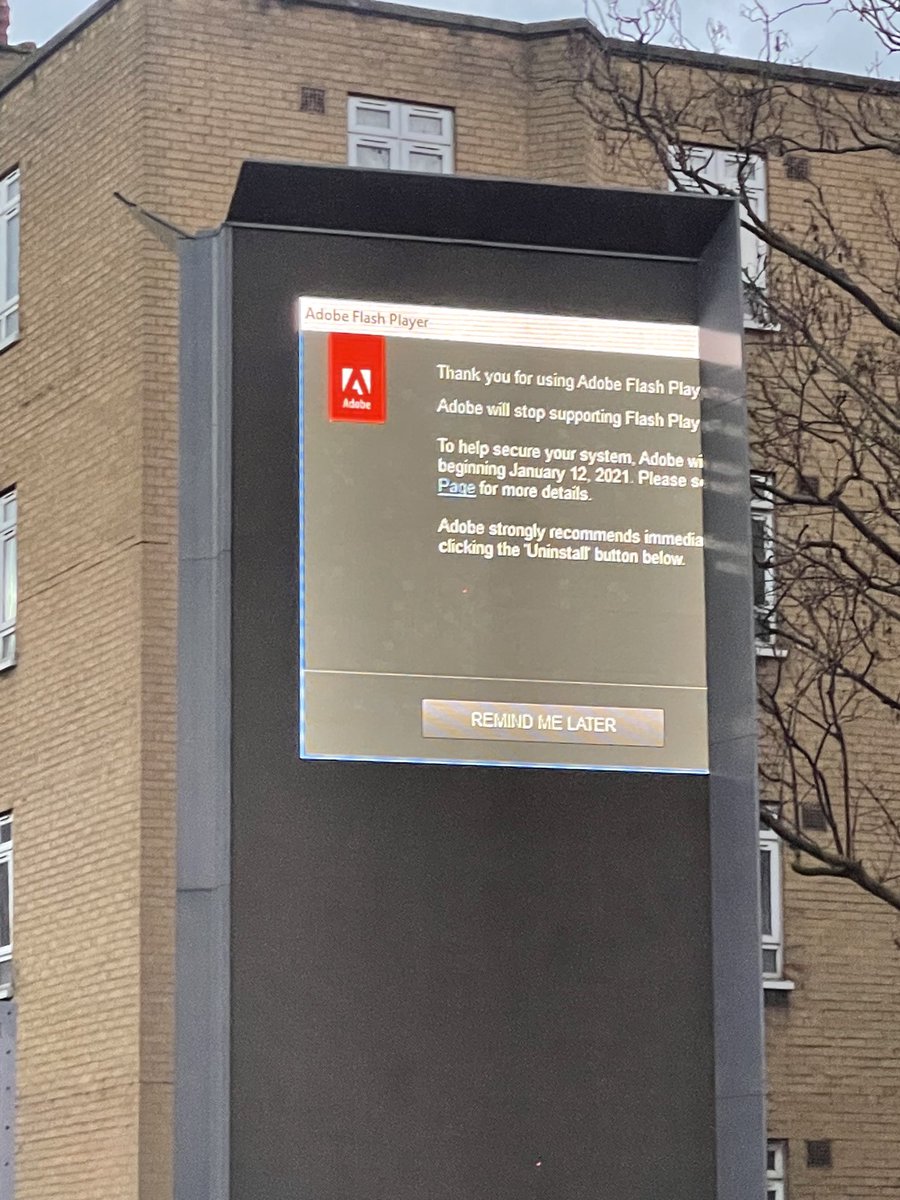



19 Nov 2024
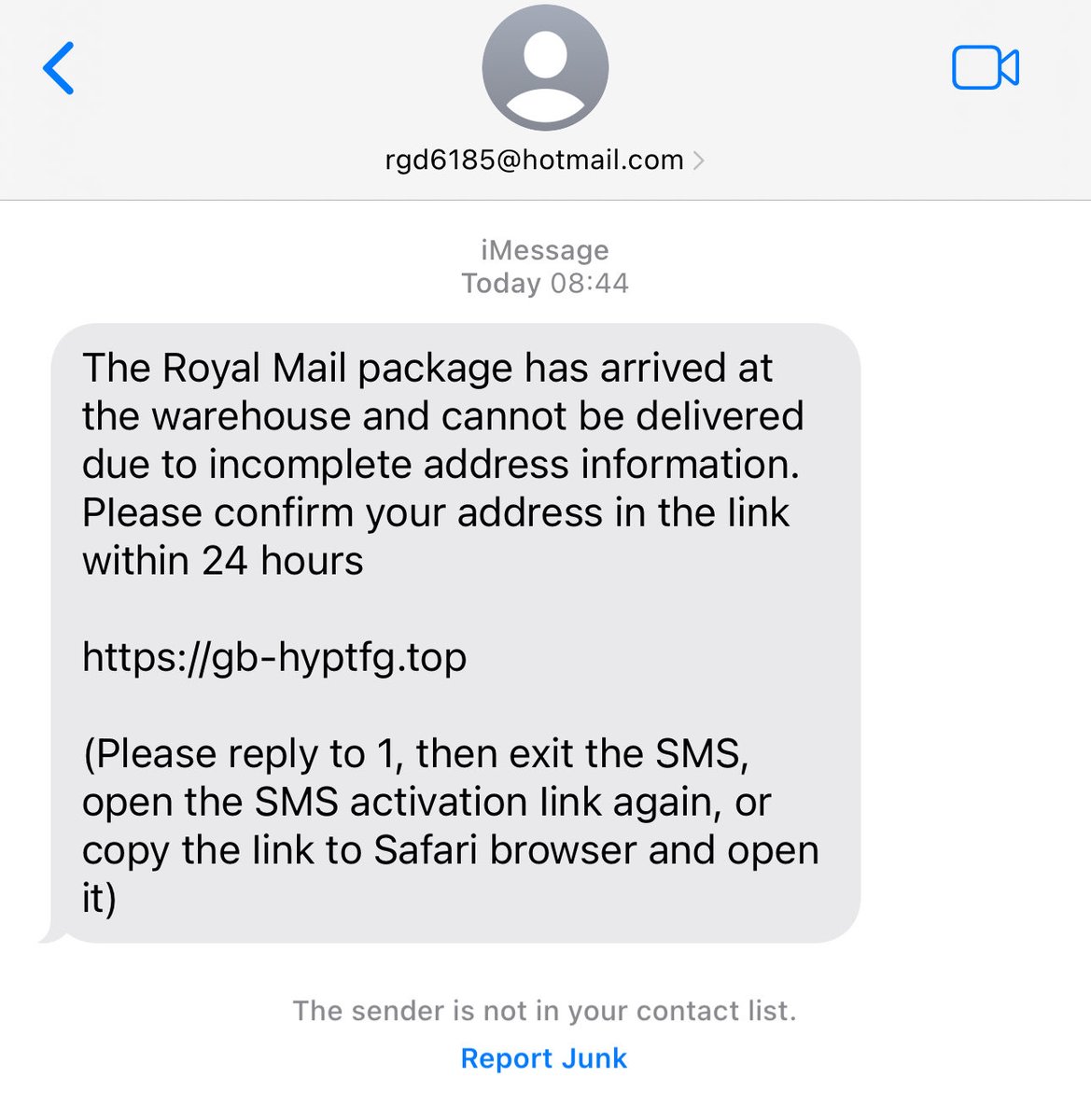
I loved gevent. It was bringing all the benefits of event loop I needed and leaving me with a straightforward API on monkey patched threads. I never could understand why it was treated as an ugly child
18 Nov 2024

“I'm now convinced that async/await is, in fact, a bad abstraction for most languages, and we should be aiming for something better instead and that I believe to be thread.”
lucumr.pocoo.org/2024/11/18/…
1
92
25 Sep 2024
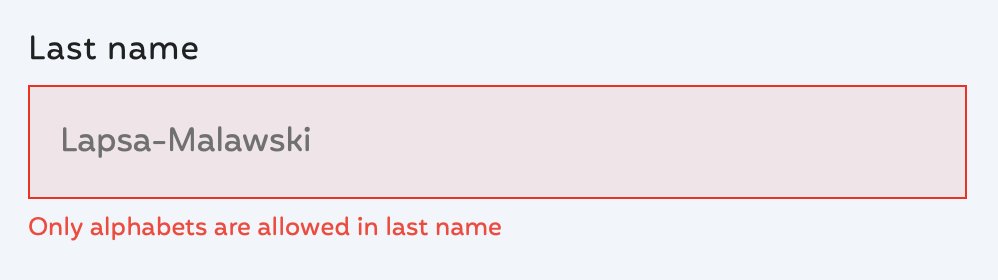
Nice, I might be eventually able to use letter “m” in passwords for some, ancient services. But then again if they are already ancient, will their CISO actually care about the new NIST guidance?
mastodon.social/@LukaszOlejn…
33
Lapsa-Malawski retweeted

22 Sep 2024
Explains why I found myself forced to not just block Musk, but also mute the terms “Elon”, “Musk”, “Elonmusk” to get a Twitter experience where I wouldn’t have every second tweet of his on my timeline.
Case study worthy on how you degrade a social network long-term
29
71
835
115,675
Lapsa-Malawski retweeted

29 Jul 2024
As Apple Intelligence is rolling out to our beta users today, we are proud to present a technical report on our Foundation Language Models that power these features on devices and cloud: machinelearning.apple.com/re…. 🧵
13
184
699
161,150
22 Jun 2024
Long awaited - standardised way to run web app in lambda github.com/awslabs/aws-lambd…
39
20 Jun 2024
We live in the future; it's just not distributed evenly: hakaimagazine.com/videos-vis…
35
29 May 2024
Next time you estimate development think about leaky pipelines: hiandrewquinn.github.io/til-…
43
Lapsa-Malawski retweeted

25 May 2024
Convolutional Neural Networks in action
113
1,611
11,388
918,139
Lapsa-Malawski retweeted

22 May 2024
Yann LeCun says he is working to develop an entirely new generation of AI systems that he hopes will power machines with human-level intelligence. It could take up to 10 years to achieve, he tells the @FT in an interview on.ft.com/3KbShLF

11
58
219
549,955
13 May 2024
honestly, Word, we have enough CPU to keep the table of contents updating automatically
53
1 May 2024
I’ve just been just told by the staff at Pret A Manger that there is no water in espresso 🙈
1
1
128
Lapsa-Malawski retweeted

30 Apr 2024
How to be as "smart" as Auto-Regressive LLMs:
- memorize lots of problem statements together with recipes on how to solve them.
- to solve a new problem, retrieve the recipe whose problem statement superficially matches the new problem.
- apply the recipe blindly and declare victory.
- do not use basic logic.
- do not use common sense to check your solution.
- do not use a mental model of the situation as a sanity check.
- do not simulate the scenario in your mind using your world model.
- when someone tells you your solution is wrong, reply "I'm sorry, you are right" and apply another irrelevant recipe.
Knowledge accumulation is not a substitute for actual understanding.
30 Apr 2024

There’s an art to distilling these to the absolute minimal necessary text. The human brain can’t comprehend how stupid these things are without practice.

200
515
3,228
799,532
Lapsa-Malawski retweeted

21 Apr 2024
At this point I feel like we understand pretty well what's going on with LLMs:
- Outputs are roughly equivalent to kernel smoothing over positional embeddings (arxiv.org/pdf/1908.11775.pdf)
- The learned computation model is *probably* bounded by RASP-L (arxiv.org/pdf/2310.16028.pdf)
- LLMs learn structure primarily from human generated content (text, images) which is far more structured and predictable than the universe.
- LLaMa3 shows us that the higher quality the annotations on the human generated content, the better the LLMs do (10million messages is a lot!)
- Multi-turn labeling is currently very expensive and so likely driving the costs of the models.
- Right now we're likely bottlenecked not on CPU, or size of data, but number and quality of annotations.
So tl;dr. Great at predicting what a human would do or say by averaging in distribution data in the corpus. No emergent generality. Currently bottlenecked by high quality annotated data.
@hausdorff_space did I miss anything?
52
146
1,043
301,680