
Joined May 2025
- Tweets 10,265
- Following 1,067
- Followers 1,516
- Likes 20,490
579 Photos and videos












Pinned Tweet

Jan 23
GM CT
Happy Fridayyyy
@GameXLabsGMX $250 campaign is still ongoing.
Use the GameXdex to swap your tokens and stand a chance to win🔥
For those who don't know how to use the Dex, here's a quick step-by-step guide👇
3
2
6
246
🍄Musty.dev retweeted

Jun 10
It’s World Cup season, and Spenda is turning football passion into real cash! 💵 ⚽️
💰Prize pool: ₦3,000,000 (₦100k for 30 winners)
✅ Predict the TWO finalists The country that will lift the trophy
To participate:
- Follow us @myspenda
- RT this post 🔁
- Comment your prediction (2 finalists winner)
PS: Prediction ends 15th July ⏳

2,127
1,226
1,660
52,454
🍄Musty.dev retweeted

Jun 9
12
12
31
1,293

Gold has held value for thousands of years.
The interesting question is, what happens when it becomes usable on-chain without being sold?
That's the thesis behind STRATO, and it's one of the reasons I've been paying attention to the Community ICO.
Worth digging into before the auction closes.

There's $30 trillion in gold, but most of it sits idle. STRATO makes it money again by letting you:
⎔ Borrow against it
⎔ Earn yield from it
⎔ Spend it as needed
More from @kjameslubin
91
12
136
4,115
🍄Musty.dev retweeted

May 30
🚨 GIVEAWAY ALERT 🚨
10,000 Naira each for 3 lucky winners! 💰
Think you know football? ⚽
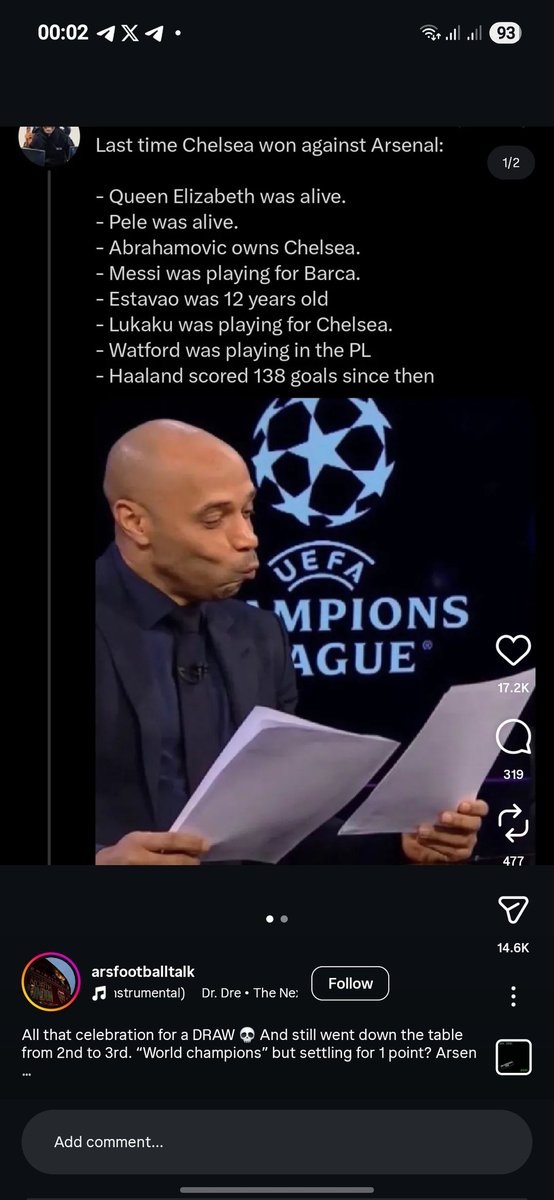
Predict the correct score of today’s UEFA Champions League clash:
🔵 PSG 🆚 🔴 Arsenal
To qualify:
->> Retweet this post
->> Tag a friend
->> Drop your score prediction in the comments
The winners will be those who correctly predict the final score.
Good luck everyone! 🍀
#PSGvsArsenal #UCLFinal #Giveaway

May 30

1st game don cut keh 😭
164
92
145
6,142
🍄Musty.dev retweeted
May 25
Congratulations to the $5k giveaway winners 💥
@musty_dev24 @Cryptdoctor_
@TherealAnointex @OOlajesu42068
Y’all should do well to send me a DM so I can assign your reward>>>
Stay active for more giveaways 🥳
May 18
Giveaway Giveaway Giveaway 🚨
$5K PropFirm Acc for 3 LUCKY Winners
Follow these instructions to participate;
-> Join Tg; t.me/WAXTRADINGARENA
-> Join Discord; discord.gg/BdgYFn7BWU
-> Retweet and tag 1 friend
Drop Proofs in the comments, winners will be selected soon.
GoodLuck 🥳

9
6
19
437
Been deep in @CosmicSignature the past few days and honestly think it deserves more attention.
It’s a procedural on-chain art protocol on Arbitrum and the Mainnet is already live. A few things actually stood out to me:
➠ 7% of every cycle’s ETH gets forwarded on-chain to Protocol Guild at finalization. Not a pledge. Hardcoded into the protocol.
➠ Zero ETH goes to the team.
➠ Two of the biggest allocation tracks (25% 8%) are won by timing, not spend. A small participant with patience can beat a whale.
➠ The NFTs are generated from real three-body problem simulations. Newtonian gravity, 100k candidate orbits per NFT. No AI, no diffusion models.
The founder co-authored the Impala SQL paper at Cloudera back in 2015 and launched Random Walk NFT on immutable Arbitrum contracts in 2021.
Still running today. No exploits. No rug.
Same design philosophy here.
Also interesting: ~50% of the reserve compounds into the next cycle, so the protocol builds over time instead of resetting from scratch.
cosmicsignature.com

103
21
162
7,078
🍄Musty.dev retweeted
May 18
Giveaway Giveaway Giveaway 🚨
$5K PropFirm Acc for 3 LUCKY Winners
Follow these instructions to participate;
-> Join Tg; t.me/WAXTRADINGARENA
-> Join Discord; discord.gg/BdgYFn7BWU
-> Retweet and tag 1 friend
Drop Proofs in the comments, winners will be selected soon.
GoodLuck 🥳
54
65
106
4,495
🍄Musty.dev retweeted
May 17
Listen up…
This Strategy printed me over $5k last month and I’m beginning to spot that same pattern in the market again 💰.
I should have charged for this, but I’m feeling generous today.
Here’s My Google Drive link to watch a Complete 20 videos Course on Crypto Futures & Forex Trading.
From Beginner level to Advanced Professional level:
drive.google.com/drive/folde…
If you’re serious about becoming PROFITABLE in trading, this is for you, IT’s FREE!!!
and if you think I deserve accolades👇:
📌Give me a follow ; @CryptofxOG
📌Like & Retweet my pinned tweet so more people can benefit too.
Happy Learning ❤️
#GodcanTeachaMan

114
136
670
28,833
🍄Musty.dev retweeted

May 16
Congratulations @musty_dev24, you won my giveaway for the game we played yesterday, kindly forward your account details to my dm.
More giveaways to come from me, stay active on my page and turn on post Notif🔔
May 15

Let’s play a game guys,
If anyone can guess the name of the song I’m listening to from the dynamic island in the image.
I’ll be buying dinner for the person. Let’s have it 👇

31
4
59
1,000
🍄Musty.dev retweeted
Apr 3
giveaway 🥳🥳🥳
since it’s easter Friday, I’ll be giving out 100 people to 100k
Retweet and tag a friend
Goodluck 🥳


52
31
74
3,872
🍄Musty.dev retweeted

Mar 25
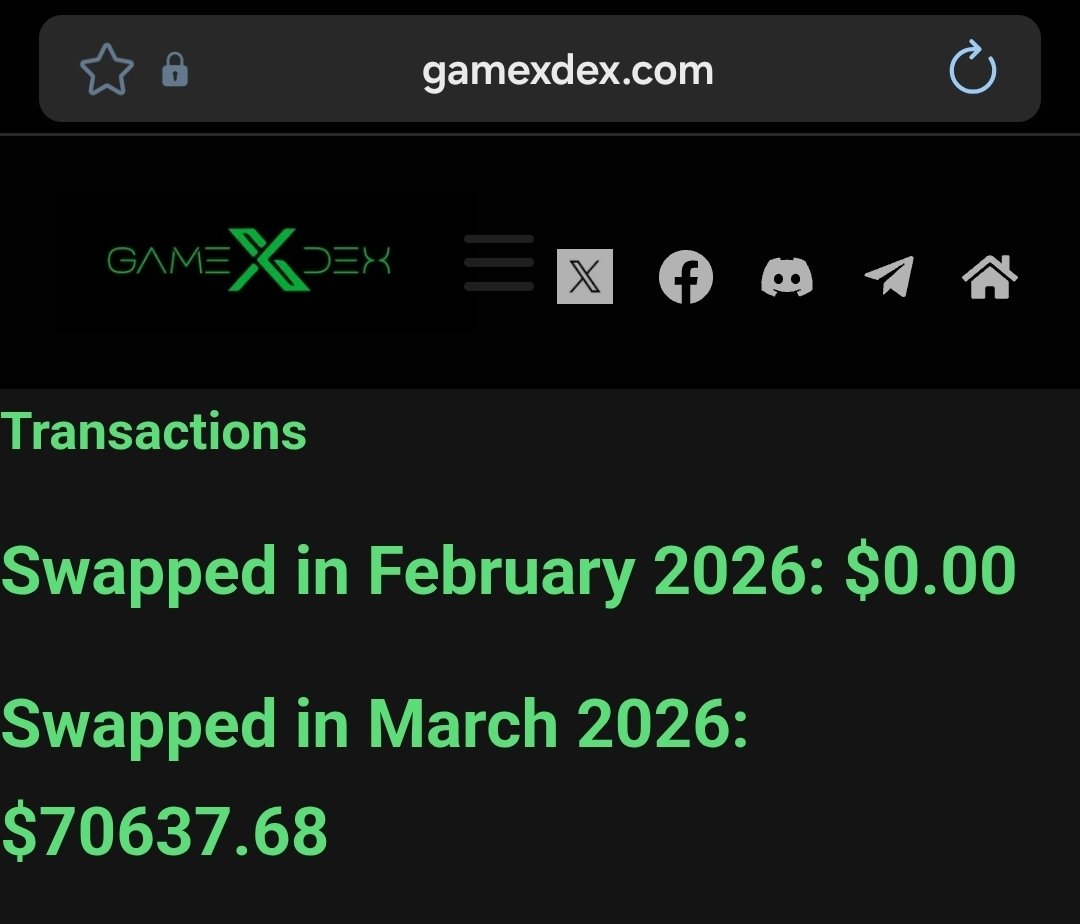
We have broken the $70,000 mark on the DEX for March.
Dont fade your bags, GameXdex is one of the cheapest DEXs in the world.
If you not using our DEX, you are definitely fading your bag.
5
3
19
301
🍄Musty.dev retweeted
Mar 25
Just under $70k swapped on gamexdex.com
Shout out to all of you GameXers, we appreciate your support.
Onwards and upwards 🚀

10
5
29
422
🍄Musty.dev retweeted
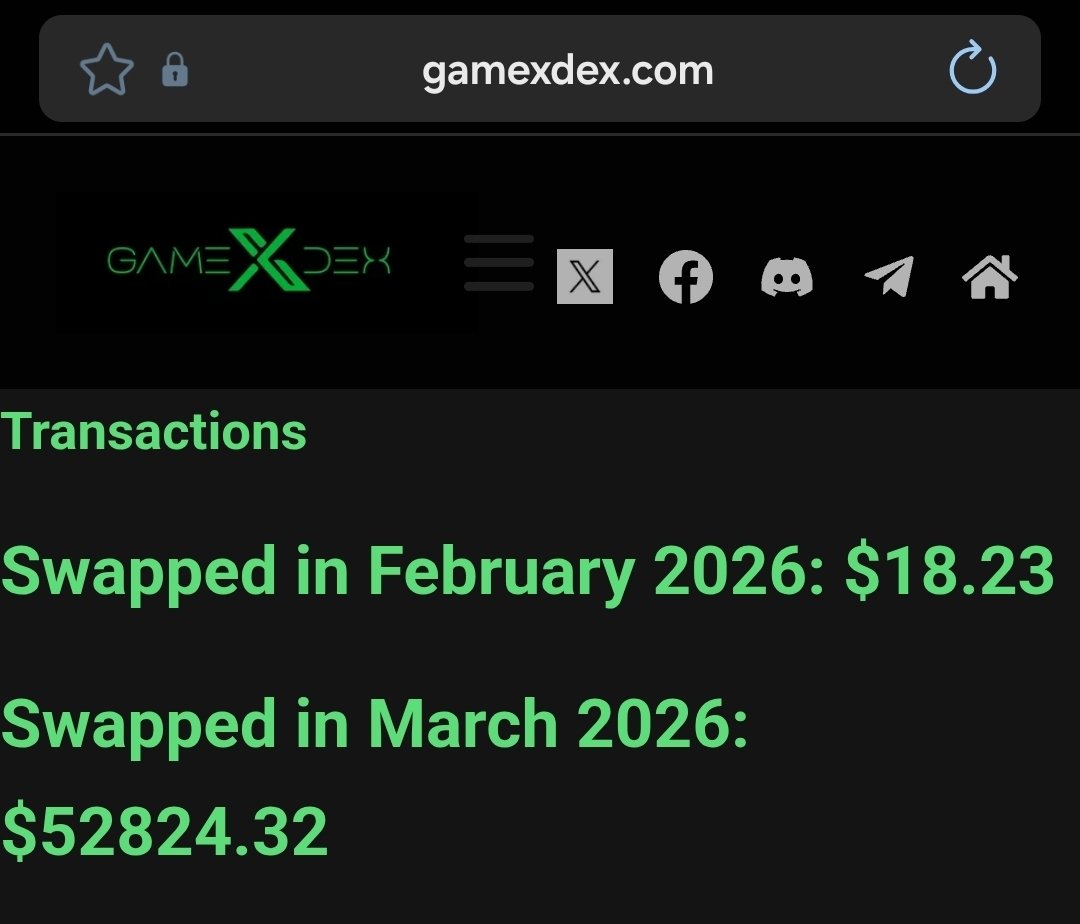
Mar 24
We have just surpassed $50,000 worth of swaps on our DEX for the month of March.
11
4
32
425
🍄Musty.dev retweeted
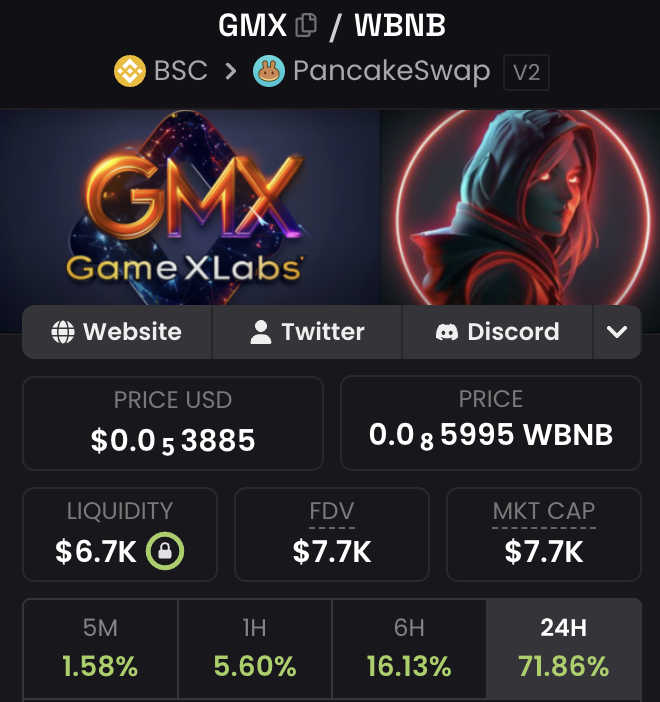
Mar 25
Good morning GameXers,
The $GameXT token continues to grow
71% in 24 hours
6
6
24
324
🍄Musty.dev retweeted
Mar 10
Good morning GameXers 👋
Testing on Deadly Strike Force continues.
The game is looking awesome so far.
Make sure you have turned on notifications for the latest updates.
Longer game trailer below 👇
40
22
78
1,126
🍄Musty.dev retweeted
Mar 21
Hello GameXers,
Here is a short video on how to use the DEX.
17
12
57
803
🍄Musty.dev retweeted
Mar 18
Hello everyone,
Join us this Friday at 7pm UTC for AMA with
@Eni447
Please like, share and lock in.
4 x $6 for your Blue Checkmarks up for grabs.

15
5
37
516
🍄Musty.dev retweeted
Mar 17
🚨 ANNOUNCEMENT 🚨
Good Morning GameXers,
We have partnered with @Mav_Genesis (GMDx), so check out the post below in thread.
X Space on Saturday 28th March 7pm WAT.
We also sponsored funds towards the prize pool for the game nights.
Stay locked in GameXers.
17
7
27
408
🍄Musty.dev retweeted

Mar 15
Most people think AI hallucinates because the models are flawed,That’s not the real problem.The real problem is where the AI retrieves its information from.
Right now, most AI applications are built on top of vector databases.
Here’s how that works:
You ask a question →
The AI searches for similar pieces of text →
Then it tries to assemble an answer from that context.
But there’s a massive flaw in that system.
Vector databases retrieve similarity, not understanding.
So the AI doesn’t actually know what something is or how things are related.
It just finds text that looks close enough.
That’s why you sometimes see strange responses like:
• confusing Apple the company with apple the fruit
• mixing up people with similar names
• pulling outdated information as if it’s still current
The AI isn’t necessarily wrong.
It’s just guessing based on similarity,and as AI agents become more autonomous, this weakness becomes a much bigger problem.
Because agents don’t just answer questions:
They make decisions.
They execute actions.
They interact with systems.
If their memory layer is flawed, the entire AI stack becomes unreliable.
That’s where HydraDB comes in. Instead of relying purely on similarity search, HydraDB introduces something different:
ontology-driven context graphs.
Rather than storing information as loose chunks of text @hydra_db maps:
• entities
• relationships
• timelines
• dependencies
So the AI doesn’t just retrieve similar information,It understands how things are connected. Think of it like this:
Traditional AI stack
AI Model
↓
Vector Database
↓
“Closest guess” context
@hydra_db stack
AI Model
↓
HydraDB Context Graph
↓
Structured relationships real memory
In other words:
@hydra_db turns AI retrieval from guesswork into structured understanding.
And as AI agents become more powerful, this layer might become one of the most important pieces of the stack.Because AI doesn’t just need more data,It needs better context.
If AI is the brain,HydraDB might become its memory layer.

9
4
44
10,509
🍄Musty.dev retweeted
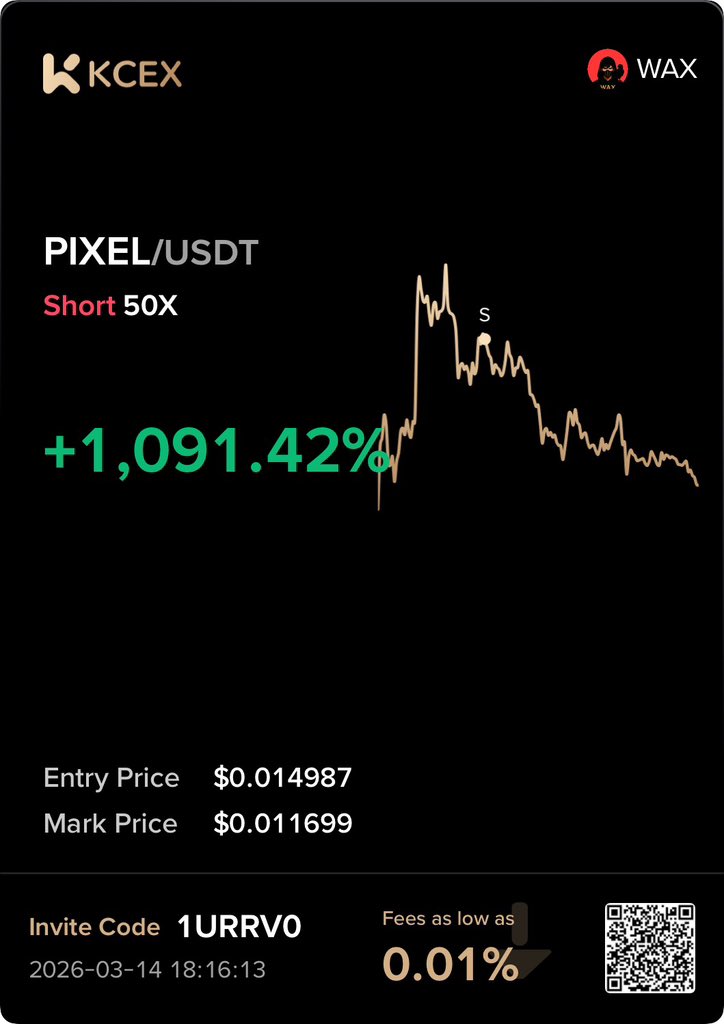
Mar 14
1% better everyday ❤️
told y’all I was gonna share my highlights for the weeK, so here you go
these are the trades we took this week and their results
ATK/USDT — W
ZEC/USDT — W
MMT/USDT — W
PIXEL/USDT — W
FIL/USDT — W
OP/USDT — W
BCH/USDT — limit order (not triggered yet)
no SL recorded this week, bless God for that and Jsyk all trade was shared for free…
Link to the community in the comments.
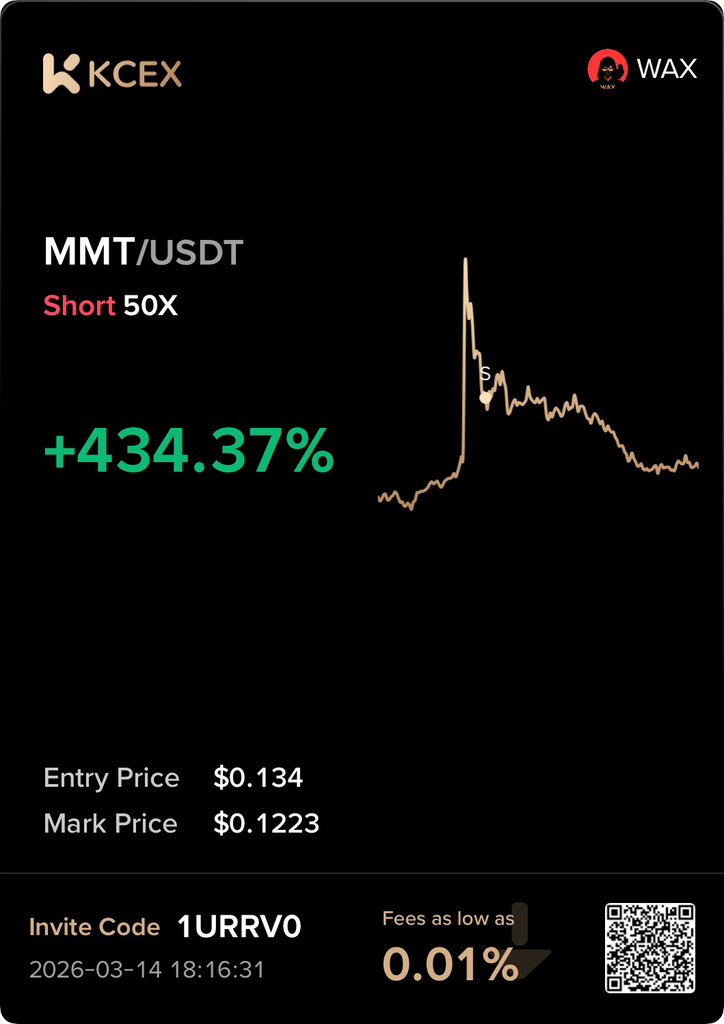
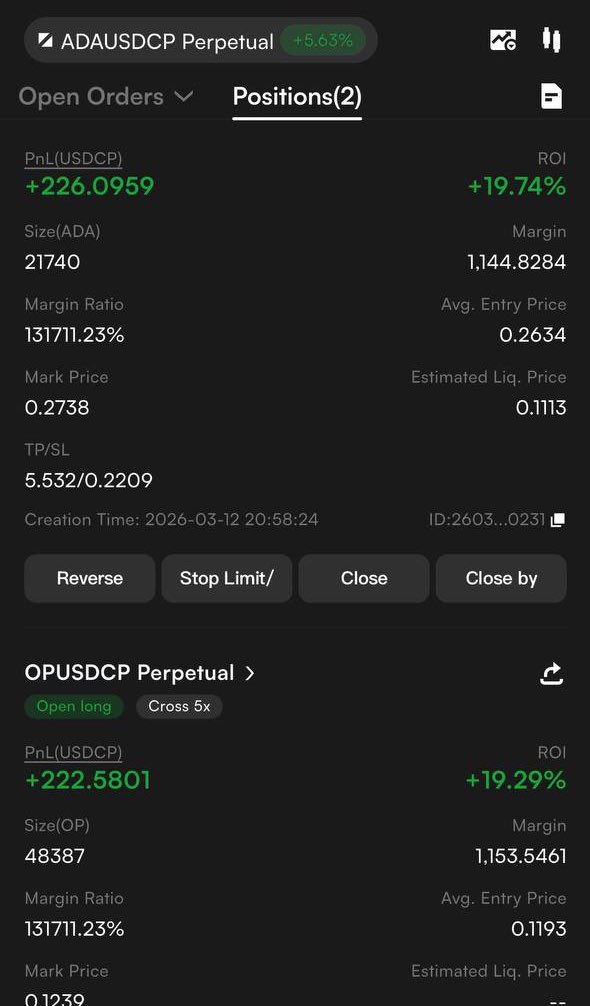

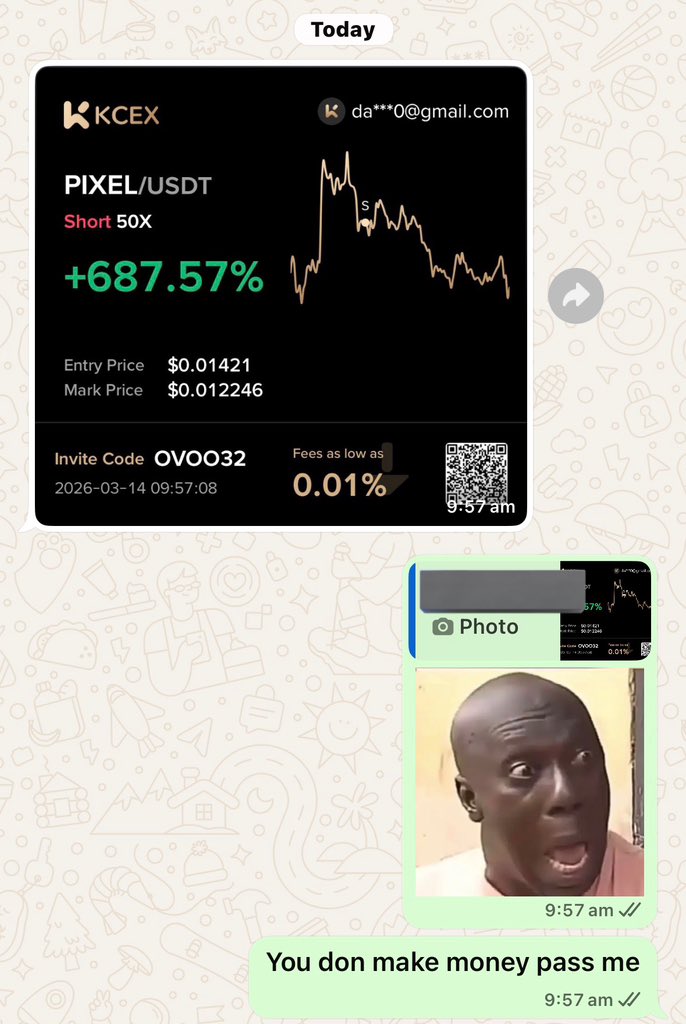
Mar 14
Another banger signal 🥳
No noise, work rate chock, I bless God for this successful one again.
Sharing my highlights for the week soon
who else took the trade on the group?
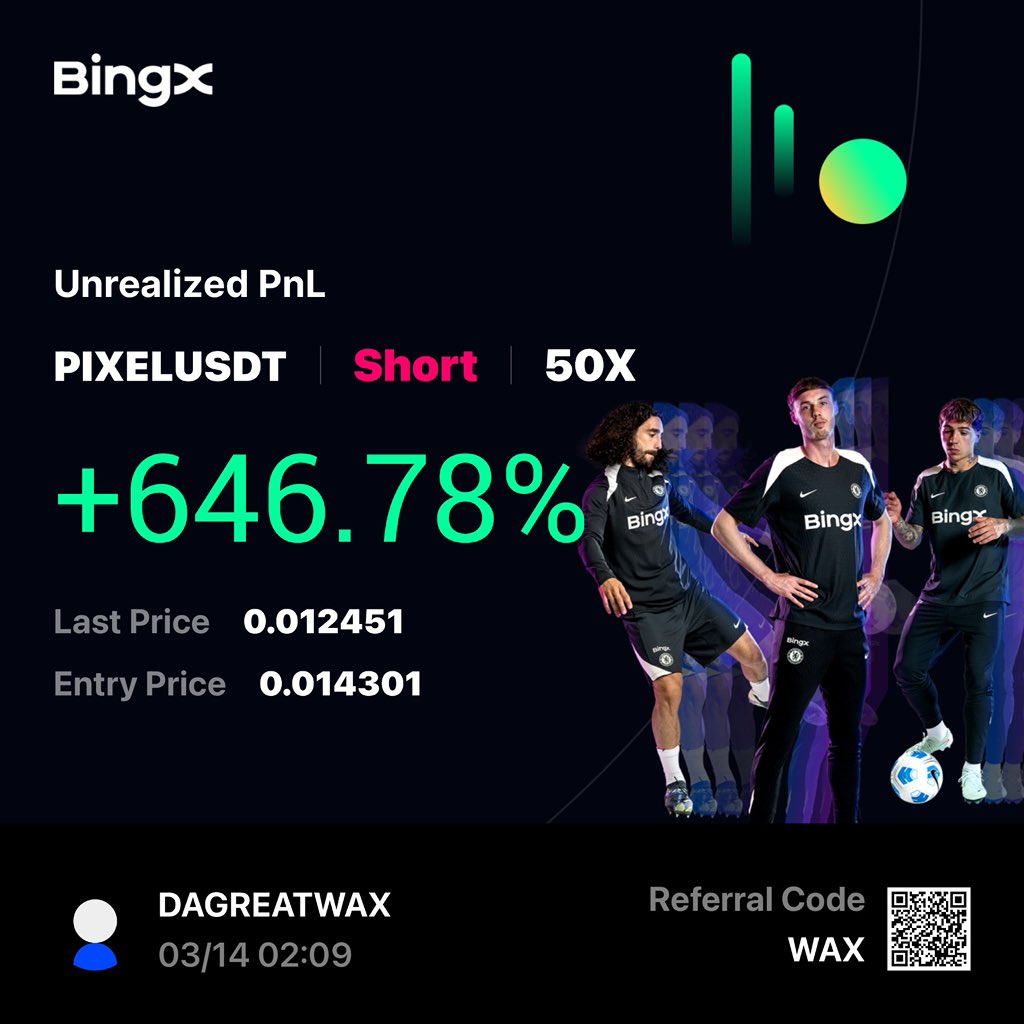
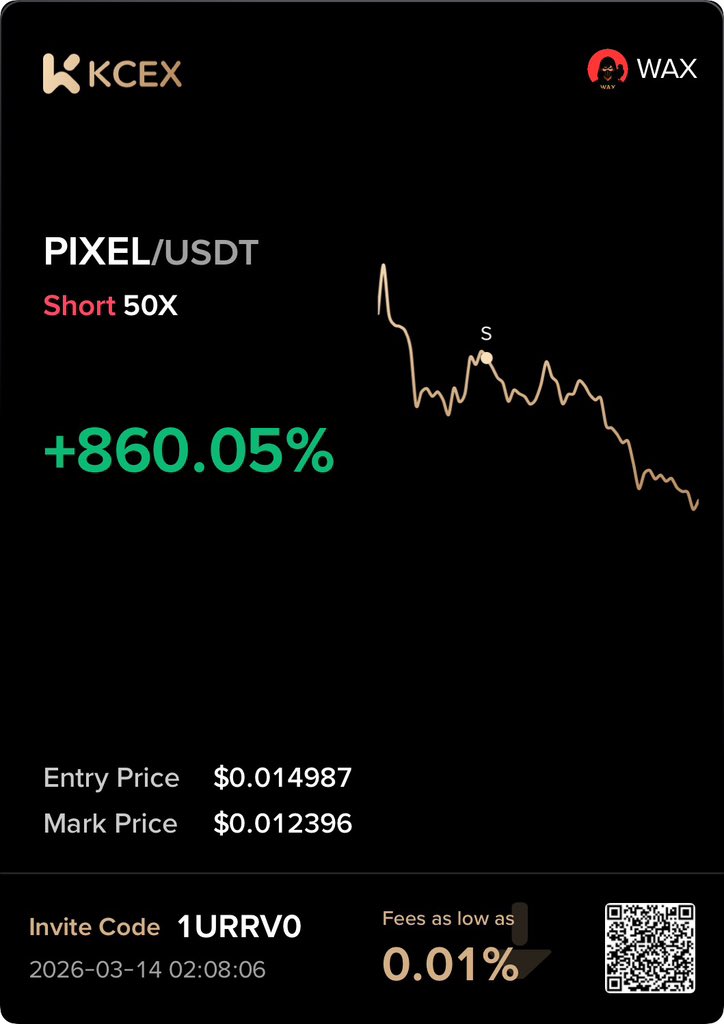

15
7
33
909