
74 Photos and videos








Pinned Tweet

5 Oct 2025
I closed one chapter a few days ago: my last day at Google. Half a year of incredible research, surrounded by brilliant colleagues, an experience I’ll always treasure and recommend. Big Tech is safe, and safe is good. But when you’re young, too much safety means missing something vital.
What’s missing? The courage to go all in. The thrill of building 0 → 1.
So I packed my life, moved to San Francisco, and went all-in. I walked away from the safest paths, the big tech offer, the academic track, because if I never bet on myself, I’d regret it forever.
And now -- right at a moment in history when AI can change everything -- who could resist betting it all?
This is the next chapter: building the world’s greatest data infrastructure for ASI. This is bigger than me -- it’s a mission.
If you’re curious, want to support, or just want to chat -- DM me. And if I can help you in any way, my DMs are always open.
Let’s accelerate toward ASI together. 🚀
Fun fact: my last day wasn’t in South Bay, but in a SF office I’d never even been to before, because I was rushing to submit my ICLR paper🥲.


134
76
2,527
447,976
What if the biggest problem with frontier model evaluation is the benchmark itself?
Too many benchmarks reduce the frontier model to narrow SWE-style tasks.
AutoLab Benchmark is designed to be broader: real-world engineering research environments, long-horizon execution, and human expert solutions as reference baselines.
Because evaluating real models should look more like evaluating real work.
#autolab #benchmark
2
3
28
2,025
2
527
Thank you for sharing our paper ❤️

AutoLab benchmarks the actual question of 2026 frontier model agents: can they sustain long-horizon closed-loop optimization.
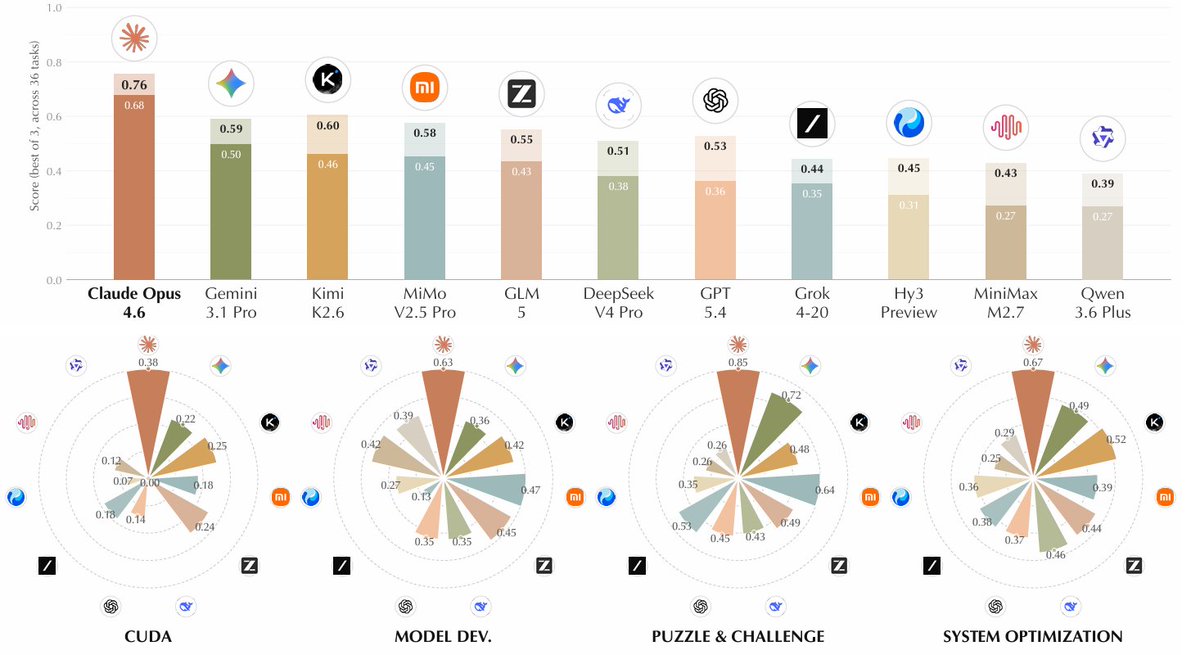
36 expert-curated tasks across system optimization, puzzle/challenge, model development, and CUDA kernel optimization.
The dominant predictor of success is NOT initial-attempt quality, it is persistence in repeatedly benchmarking, editing, incorporating empirical feedback.
Most "agentic AI" demos are competent at the first iteration and incompetent at iteration 50, which is exactly where real engineering work lives.
AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
Paper: arxiv.org/abs/2606.05080
11
2,605
We put out a blog version of AutoLab in March. Today, I am excited to share that our full paper is out!
📖 AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
Since then it's been great to see work in the field building on what we shared, that's a big part of why we went back and did the complete version, with the full experiments.
The question is simple: can a model stay with a hard problem for hours? 36 environments, each a real program that works, but not optimized. The model gets the code, a sandbox, up to 12 hours, and a sealed scorer -- the only way to a better number is better code.
We ran 17 frontier models. 2,544 hours, 8.6 billion tokens. The finding from the blog held up: the strong models weren't the ones with the best first attempt -- they were the ones that kept closing the loop: test, change, test again! Persistence alone wasn't enough. Some models ground on for hours but barely ran the code, and the clock ran out on them. Others gave up with hours left.
We built this benchmark; it might not capture everything. But we hope it fills in a piece of the picture that one-shot scores miss, especially for anyone building agents to do hours of real work!
If you've been building on the blog version, we'd love to see what you found. And if you try your models on it, tell us what breaks.
#AutoLabBench
1
11
31
2,699
Paper: arxiv.org/abs/2606.05080
Site: autolab.moe
Code: github.com/autolabhq/autolab
Any comments welcome!
1
1
8
1,432
Thank you for sharing our work 🫶
AutoLab is definitely my most proud work in this year 🧡

Outstanding paper on long-horizon agents.
(bookmark it)
Similar to humans, how do you make agents persist on a difficult task, and how is that useful?
And which models today work well on this?
This new work, AutoLab, explores this question and how encoding persistence in agents is beneficial for tasks such as auto research and engineering tasks.
Can a model keep improving an artifact for hours, under a strict wall-clock budget, the way real research and engineering actually work?
Results:
AutoLab hands agents 36 expert-curated tasks across system optimization, model development, CUDA kernels, and puzzles, each starting from a correct but deliberately suboptimal baseline.
Across 17 frontier models, the dominant predictor of success was not the quality of the first attempt. It was persistence, repeatedly benchmarking, editing, and folding in empirical feedback.
It appears that Claude-opus-4.6 sustained that loop well. Most of the other models quit early or burned the budget, making almost no progress.
Paper: arxiv.org/abs/2606.05080
Learn to build effective AI agents in our academy: academy.dair.ai/

1
25
4,529
A lot of people have asked whether I’ll be at #ICLR 🇧🇷 this year. Sadly, I won’t make it in person. It has been an unusually busy stretch, and I ended up missing the trip.
Our CoDA is presenting at #ICLR now, and welcome to stop by and chat ☕️.
📅 Sat (today!), Apr 25, 2026, 10:30 AM – 1:00 PM (local time)
🏠 Pavilion 3, P3-#1602
While CoDA is presented in the context of scientific visualization, the core architectural ideas go far beyond that application.
What we really care about is a broader question: how agent systems can decompose complex tasks, collaborate across roles, and iteratively refine outputs until they become genuinely useful.
I’m also excited that the code is now publicly available through Google Research:
👩💻 github.com/google-research/a…
If you are thinking about multi agent systems, self-evolving, or harness, we would be very happy to discuss!
📝 Conf details: iclr.cc/virtual/2026/poster/…
📂 Project page: coda-agent.github.io/CoDA/
6 Oct 2025

With deep research revolutionizing research/data analysis, why are we still stuck in manually crafting data viz?
Meet CoDA (huggingface.co/papers/2510.0…): The ultimate multi-agent LLM powerhouse for auto-generating stunning plots from NL queries! Handles complex data, self-refines for perfection, & smashes baselines by 41.5%🚀
Key Features:
🌟Specialized agents for metadata analysis, planning, code gen/debug, & reflection
🌟Bypasses LLM input length limits w/ metadata focus
🌟Iterative loops for robust, human-like quality checks
🌟SOTA on MatplotBench & Qwen & DA-Code
#DataViz #AgenticAI #MultiAgent

2
6
29
3,850
Thank you for sharing our work!
Exciting direction!
What matters now is being able to measure whether agents are actually contributing to scientific and engineering progress, not just producing fluent outputs.
If research capable AI matters, evaluation has to be open, realistic, and community built.
Apr 11

Agent will take over human science!
2
7
1,313
Since launching #AutoLab, we’ve gotten a lot of inbound from researchers, builders, and friends.
What’s clear is this: the field wants a better standard for evaluating research-capable agents.
Our goal is simple: build a fair, open, transparent benchmark for agents that can operate in real scientific and engineering loops.
This should not be defined behind closed doors.
[Accidentally deleted this earlier, reposting] 😭
#AutoLab #autoresearch
We've been asking ourselves a question: if AI agents can now run hundreds of experiments overnight, how do we know whether they're actually contributing to research — or just generating noise?
That's why we built AutoLab (autolab.moe/blog).
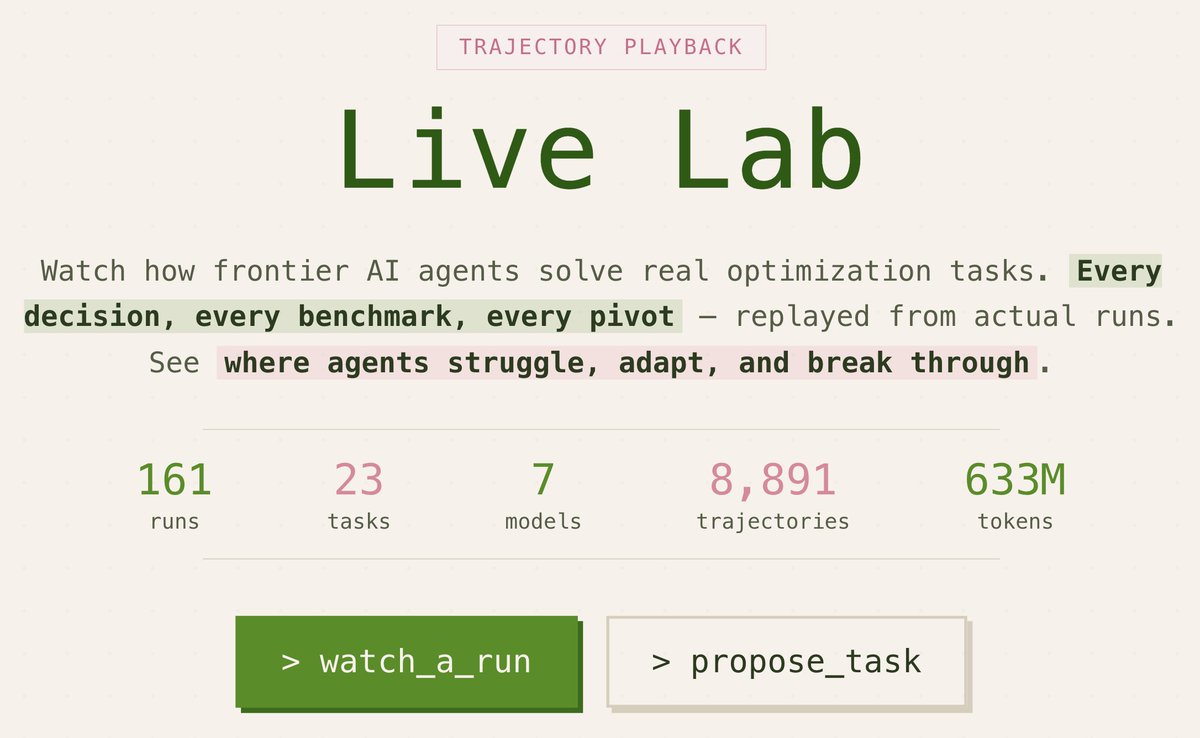
Not another pass/fail benchmark, but an open-source environment where agents face the same loop every researcher knows intimately — propose, test, fail, diagnose, revise, repeat.
23 tasks with no answer keys, just open search spaces and real constraints.
We ran 161 evaluations across 7 frontier models, 633M tokens. Every decision, every pivot, every dead end — all openly available in our Live Lab for anyone to replay and learn from.
What we found wasn't about which model is "smartest." It's about a capability we call closed-loop resilience: when incremental refinement stops working, can the agent recognize it and restructure? On one task, two frontier models hit the same wall. One kept pushing within the existing frame. The other stepped back and redesigned the approach entirely. That moment — knowing when to abandon a frame, not just optimize within it — is what separates real research from sophisticated pattern matching.
We believe this matters beyond benchmarking. If agents are genuinely entering the research loop, we want that transition to be measured transparently, built in the open, and shaped by the community — not locked inside any single lab. The scientist doesn't disappear. The loop gets a new participant. And we want to make sure that participant is understood.
This is a joint effort across @Stanford, @MIT, @UW, @UCSanDiego, @ucsantabarbara, @NotreDame, NUS, @Google, @NVIDIA, @IBMResearch, and @bakelab_hq. But 23 tasks is just the start. If you have an optimization problem you've spent weeks grinding on empirically — with a clear metric and no known optimal solution — it probably belongs here. Contribute a full task, a rough skeleton, or just the idea.
The best benchmarks aren't built by one team. They're built by the people who actually do the work!
Github: github.com/autolabhq/autolab



1
18
2,677
The more concentrated frontier capability becomes, the more important open evaluation becomes.
If powerful agentic systems are going to shape critical work, the field cannot rely only on selective access, internal safeguards, and closed reporting to understand what these systems can actually do.
We need public evaluation surfaces with open tasks, replayable runs, visible failures, and community scrutiny.
That is a big part of why we built AutoLab.
autolab.moe/
Apr 7

Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
anthropic.com/glasswing
10
1,486
Zichen Chen (🐱,💖) retweeted

Apr 4
Awesome benchmark I've come across recently. It highlights how crucial the environment is, echoing my previous points about Interactive environments.
[Accidentally deleted this earlier, reposting] 😭
#AutoLab #autoresearch
We've been asking ourselves a question: if AI agents can now run hundreds of experiments overnight, how do we know whether they're actually contributing to research — or just generating noise?
That's why we built AutoLab (autolab.moe/blog).
Not another pass/fail benchmark, but an open-source environment where agents face the same loop every researcher knows intimately — propose, test, fail, diagnose, revise, repeat.
23 tasks with no answer keys, just open search spaces and real constraints.
We ran 161 evaluations across 7 frontier models, 633M tokens. Every decision, every pivot, every dead end — all openly available in our Live Lab for anyone to replay and learn from.
What we found wasn't about which model is "smartest." It's about a capability we call closed-loop resilience: when incremental refinement stops working, can the agent recognize it and restructure? On one task, two frontier models hit the same wall. One kept pushing within the existing frame. The other stepped back and redesigned the approach entirely. That moment — knowing when to abandon a frame, not just optimize within it — is what separates real research from sophisticated pattern matching.
We believe this matters beyond benchmarking. If agents are genuinely entering the research loop, we want that transition to be measured transparently, built in the open, and shaped by the community — not locked inside any single lab. The scientist doesn't disappear. The loop gets a new participant. And we want to make sure that participant is understood.
This is a joint effort across @Stanford, @MIT, @UW, @UCSanDiego, @ucsantabarbara, @NotreDame, NUS, @Google, @NVIDIA, @IBMResearch, and @bakelab_hq. But 23 tasks is just the start. If you have an optimization problem you've spent weeks grinding on empirically — with a clear metric and no known optimal solution — it probably belongs here. Contribute a full task, a rough skeleton, or just the idea.
The best benchmarks aren't built by one team. They're built by the people who actually do the work!
Github: github.com/autolabhq/autolab
1
4
917
[Accidentally deleted this earlier, reposting] 😭
#AutoLab #autoresearch
We've been asking ourselves a question: if AI agents can now run hundreds of experiments overnight, how do we know whether they're actually contributing to research — or just generating noise?
That's why we built AutoLab (autolab.moe/blog).
Not another pass/fail benchmark, but an open-source environment where agents face the same loop every researcher knows intimately — propose, test, fail, diagnose, revise, repeat.
23 tasks with no answer keys, just open search spaces and real constraints.
We ran 161 evaluations across 7 frontier models, 633M tokens. Every decision, every pivot, every dead end — all openly available in our Live Lab for anyone to replay and learn from.
What we found wasn't about which model is "smartest." It's about a capability we call closed-loop resilience: when incremental refinement stops working, can the agent recognize it and restructure? On one task, two frontier models hit the same wall. One kept pushing within the existing frame. The other stepped back and redesigned the approach entirely. That moment — knowing when to abandon a frame, not just optimize within it — is what separates real research from sophisticated pattern matching.
We believe this matters beyond benchmarking. If agents are genuinely entering the research loop, we want that transition to be measured transparently, built in the open, and shaped by the community — not locked inside any single lab. The scientist doesn't disappear. The loop gets a new participant. And we want to make sure that participant is understood.
This is a joint effort across @Stanford, @MIT, @UW, @UCSanDiego, @ucsantabarbara, @NotreDame, NUS, @Google, @NVIDIA, @IBMResearch, and @bakelab_hq. But 23 tasks is just the start. If you have an optimization problem you've spent weeks grinding on empirically — with a clear metric and no known optimal solution — it probably belongs here. Contribute a full task, a rough skeleton, or just the idea.
The best benchmarks aren't built by one team. They're built by the people who actually do the work!
Github: github.com/autolabhq/autolab
2
14
78
10,439
Honored to be back at #GTC.
On Tuesday night, I’ll be joining “The Last Mile of Personal AI” for a conversation on where personal AI is heading, across both agentic AI and physical AI. Very excited to be invited into this discussion and to share the stage with so many leaders and builders I deeply respect.
We’ll be talking about a question that feels increasingly central: how data, agents, and humans will work together to shape the next era of AI.
If you’ll be at #GTC, come find me. Always excited to meet people building what comes next!
luma.com/1qud1f9o?tk=GOPgGq
4
944
What is beauty?
If everyone feels it differently, why are we trying to score it like math?
Introducing Visual Aesthetic Benchmark (VAB): vab.bakelab.ai/.
For centuries, beauty was judged by humans — artists, critics, experts — through comparison, context, and intuition.
Now AI quietly shapes what the world sees.
So we asked a blunt question:
Can frontier models judge beauty like humans do?
To find out, we chose the hardest path -- commissioning original artworks, inviting domain experts to evaluate them, and constructing controlled comparisons where only aesthetic choices differ.
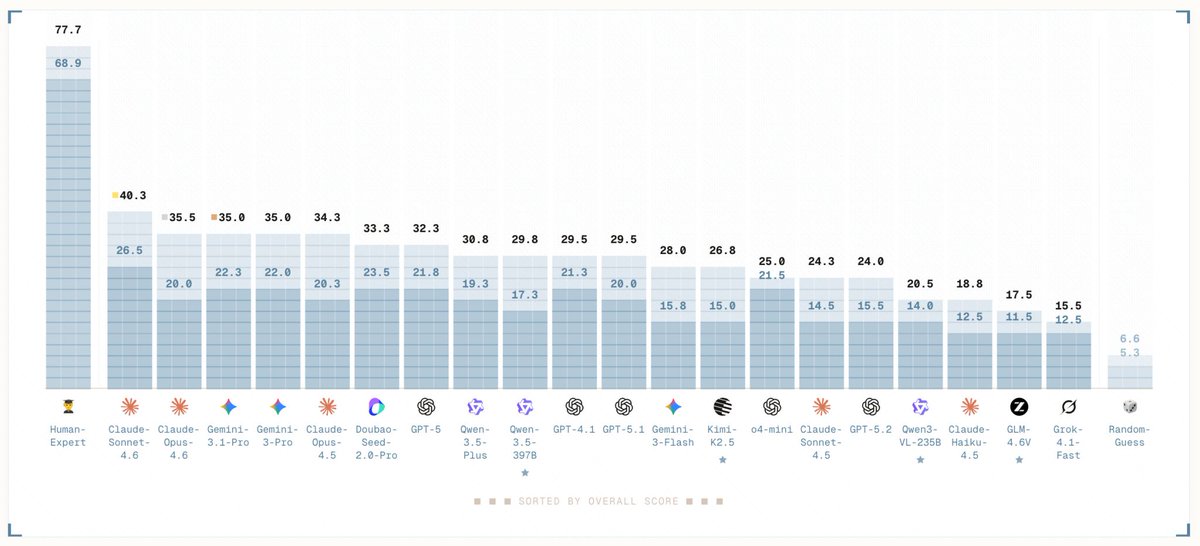
Massive effort:
1,000 artists
100 expert judges
13,000 expert decisions
2,000 hours of creation
24 thematic domains
The result is clear. Humans still lead — by a wide margin.
Best model (Claude-Sonnet-4.6): 26.5%
Human experts: 68.9%
If AI will co-curate our world,
it should be tested on judgment — not just perception.
#benchmark #LLM #AI

4
4
20
1,275