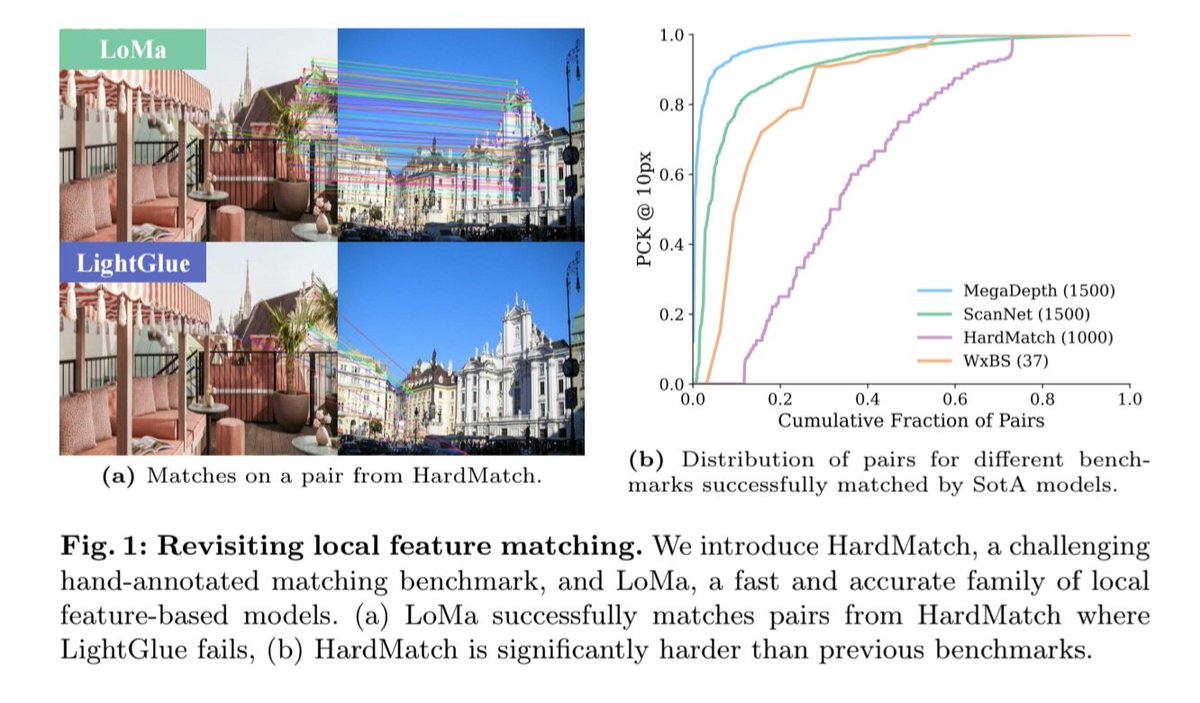
What if we could evolve AI models like organisms in nature, letting them compete, mate, and combine their strengths to produce ever-fitter offspring?
Excited to share our new work: “Competition and Attraction Improve Model Fusion” presented at GECCO’25🦎 where it was a runner-up for best paper!
Paper:
arxiv.org/abs/2508.16204
Code:
github.com/SakanaAI/natural_…
Summary of Paper
At Sakana AI, we draw inspiration from nature’s evolutionary processes to build the foundation of future AI systems. Nature doesn’t create one single, monolithic organism; it fosters a diverse ecosystem of specialized individuals that compete, cooperate, and combine their traits to adapt and thrive. We believe AI development can follow a similar path.
What if instead of building one giant monolithic AI, we could evolve a whole ecosystem of specialized models that collaborate and combine their skills? Like a school of fish 🐟, where collective intelligence emerges from the group.
This new paper builds on our previous research on model merging, which follows such an evolutionary path. We started by using evolution to find the best “recipes” to merge existing models (our Nature Machine Intelligence paper:
nature.com/articles/s42256-0…). Then, we explored how to maintain diversity to acquire new skills in LLMs (our ICLR 2025 paper:
openreview.net/forum?id=Kvdh…). Now, we're combining these ideas into a full evolutionary system.
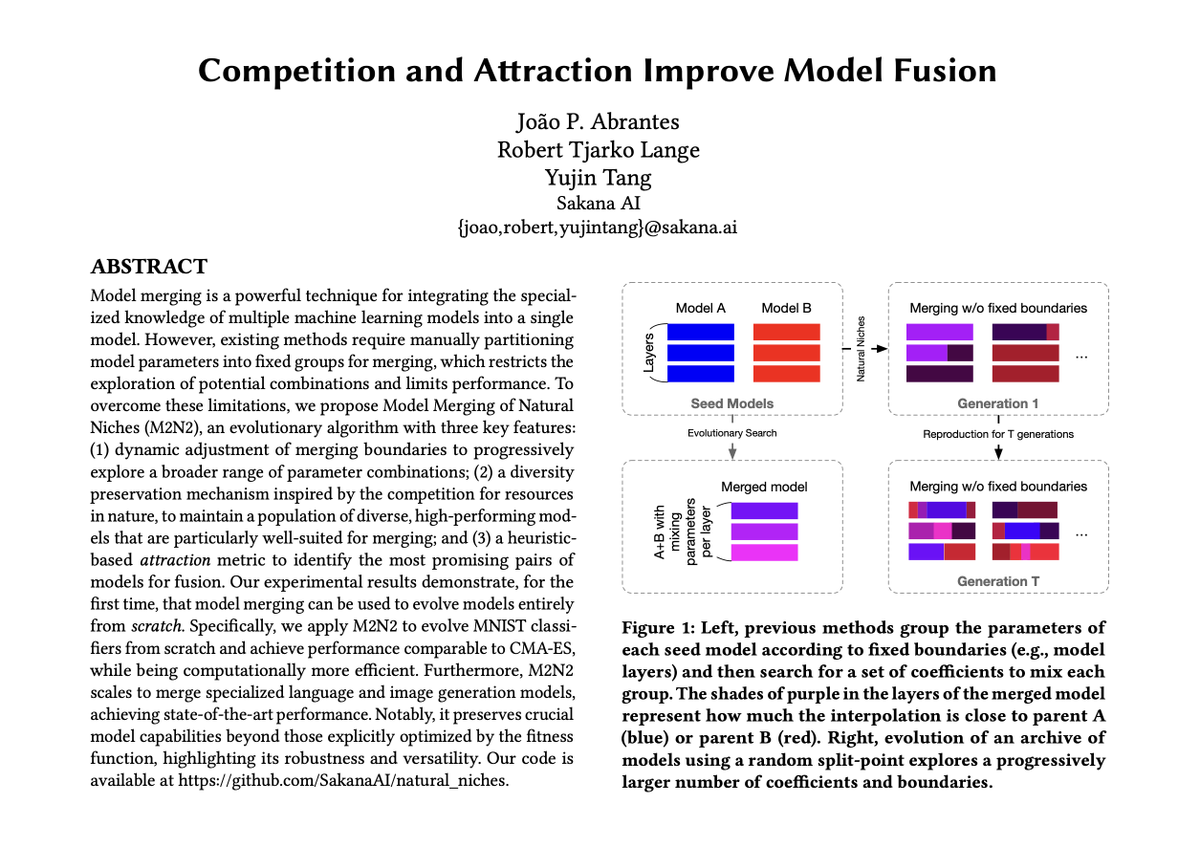
A key limitation remained in earlier work: model merging required manually defining how models should be partitioned (e.g., by fixed layer or blocks) before they could be combined. What if we could let evolution figure that out too?
Our new paper proposes M2N2 (Model Merging of Natural Niches), a more fluid method, which overcomes this with three key, nature-inspired ideas:
1/ Evolving Merging Boundaries 🌿: Instead of merging models using pre-defined, static boundaries (e.g. fixed layers), M2N2 dynamically evolves the “split-points” for merging. This allows for a far more flexible and powerful exploration of parameter combinations, like swapping variable-length segments of DNA rather than entire chromosomes.
2/ Diversity through Competition 🐠: To ensure we have a rich pool of models to merge, M2N2 makes them compete for limited resources (i.e., data points in a training set). This forces models to specialize and find their own “niche,” creating a population of diverse, high-performing specialists that are perfect for merging.
3/ Attraction and Mate Selection 💏: Merging models can be computationally expensive. M2N2 introduces an “attraction” heuristic that intelligently pairs models for fusion based on their complementary strengths—choosing partners that perform well where the other is weak. This makes the evolutionary search much more efficient.
Does it work?
The results are fascinating: This is the first time model merging has been used to evolve models entirely from scratch, outperforming other evolutionary algorithms. In one experiment, starting with random networks, M2N2 evolved an MNIST classifier that achieves performance comparable to CMA-ES, but is far more computationally efficient.
Does it scale?
We also showed that M2N2 can scale to large, pre-trained models: We used M2N2 to merge a math specialist LLM with an agentic specialist LLM. M2N2 produced a merged model that excelled at both math and web shopping tasks, significantly outperforming other methods. The flexible split-point was crucial here.
Does it work on multimodal models?
When we applied M2N2 to text-to-image models, we merged several models by adapting them only for Japanese prompts. The resulting model not only improved on Japanese but also retained its strong English capabilities—a key advantage over fine-tuning, which can suffer from catastrophic forgetting.
This nature-inspired approach is central to Sakana AI’s mission to find new foundations for AI based on collective intelligence. Rather than scaling monolithic models, we envision a future where ecosystems of diverse, specialized models co-evolve, collaborate, and combine, leading to more adaptive, robust, and creative AI. 🐙
We hope this work sparks more interest in these under-explored ideas!
Published in ACM GECCO’25: Proceedings of the Genetic and Evolutionary Computation Conference. DOI:
doi.org/10.1145/3712256.3726…