
Senior ML engineer and Tech educator •• I Make AI powered solutions •• I speak 🇬🇧🇸🇦🇪🇸 .
Joined October 2022
- Tweets 1,659
- Following 1,544
- Followers 1,696
- Likes 992
98 Photos and videos












Nonso Dev retweeted

Mar 28
Gave a talk earlier today at BitDevs Kaduna ⚡.
Did a deep dive into our @Breez_Tech integration at @evento_so: architecture, trade-offs, and the real-world issues we ran into building it.
Also got to demo Zap-All live 🤭.
Amazing crowd, great questions, peak BitDevs energy all round 💐.
Evento is now open-source too, so feel free to check it out, suggest improvements, or contribute.
Appreciate everyone who came through 🫡.

ALT BitDevs Kaduna Meetup, Mar 28th 2026.
Mar 18

Don’t miss our March BitDevs Meetup!
Join us as Aaliyah Junaid (Software Developer @Evento) breaks down how they integrated Breez SDK to power seamless Bitcoin & Lightning payments ⚡

4
7
22
1,226
Nonso Dev retweeted

30 Dec 2025
Empowering through guidance 🤝
Introducing the Mentorship Team of GDG On Campus, committed to nurturing talent, encouraging collaboration, and shaping future innovators. 🚀
#GDGOnCampus
#MentorshipTeam
#LearnGrowTogether
#TechMentorship
#StudentCommunity
#BuildWithGoogle




1
5
147

Nonso Dev retweeted

9 Dec 2025
In today's episode of programming horror...
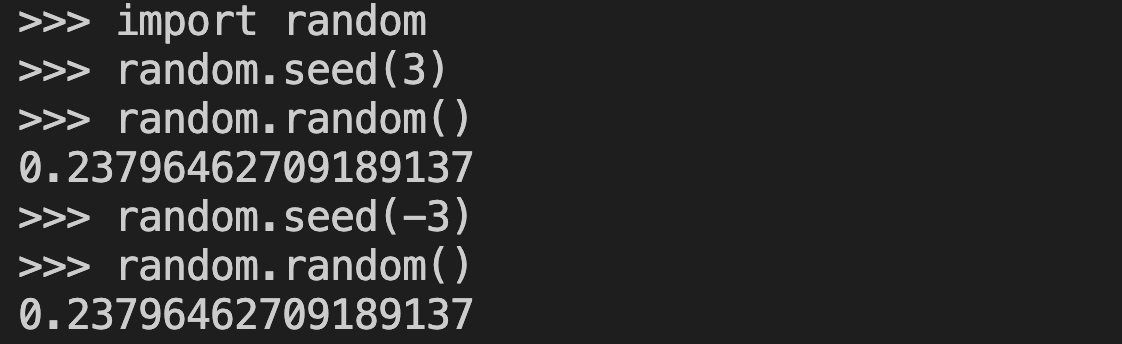
In the Python docs of random.seed() def, we're told
"If a is an int, it is used directly." [1]
But if you seed with 3 or -3, you actually get the exact same rng object, producing the same streams. (TIL). In nanochat I was using the sign as a (what I thought was) clever way to get different rng sequences for train/test splits. Hence gnarly bug because now train=test.
I found the CPython code responsible in cpython/Modules/_randommodule.c [2], where on line 321 we see in a comment:
"This algorithm relies on the number being unsigned. So: if the arg is a PyLong, use its absolute value." followed by
n = PyNumber_Absolute(arg);
which explicitly calls abs() on your seed to make it positive, discarding the sign bit.
But this comment is actually wrong/misleading too. Under the hood, Python calls the Mersenne Twister MT19937 algorithm, which in the general case has 19937 (non-zero) bits state. Python takes your int (or other objects) and "spreads out" that information across these bits. In principle, the sign bit could have been used to augment the state bits. There is nothing about the algorithm that "relies on the number being unsigned". A decision was made to not incorporate the sign bit (which imo was a mistake). One trivial example could have been to map n -> 2*abs(n) int(n < 0).
Finally this leads us to the contract of Python's random, which is also not fully spelled out in the docs. The contract that is mentioned is that:
same seed => same sequence.
But no guarantee is made that different seeds produce different sequences. So in principle, Python makes no promises that e.g. seed(5) and seed(6) are different rng streams. (Though this quite commonly implicitly assumed in many applications.) Indeed, we see that seed(5) and seed(-5) are identical streams. And you should probably not use them to separate your train/test behaviors in machine learning. One of the more amusing programming horror footguns I've encountered recently. We'll see you in the next episode.
[1] docs.python.org/3/library/ra…
[2] github.com/python/cpython/bl…
215
483
7,800
768,773
Of course there is no harm to experimenting, if you have time and a gpu, but here are few tips:
- Use when model is too complex.
- You can actually see the overfitting happening. (This is better because instead of holding on to regularization as default, you can see if the model performs better without regularization and have some sort of baseline to work with)
- A large datset is not available (if the data is relatively small and there is risk for the data to end up being memorized by the complex model, then yes).
- If you do not have enough time nor gpu and you are unsure about the characteristics of the model and data, then yes also.
Hope this helps.

I was reviewing a mentee's Deep learning model today and saw something i had wanted to talk about for a while.
A lot of hobby DL models we create do not get better performance when Regularization is implemented, in fact it decreases training accuracy and overall generalization.
1
115
I was reviewing a mentee's Deep learning model today and saw something i had wanted to talk about for a while.
A lot of hobby DL models we create do not get better performance when Regularization is implemented, in fact it decreases training accuracy and overall generalization.
4
187
Picked up fastai over the last weekend for a gig so I did a little something for y'all to check out.
A pneumonia detector from chest xrays...You could open on colab, run the cells and start testing it out right away and of course, improve it.
Colab link:
colab.research.google.com/dr…
1
98
Nonso Dev retweeted

4 Nov 2025
had a dinner with this guy in korea
heard that he writes code
seems cool

302
447
15,835
645,560
Nonso Dev retweeted

1 Nov 2025
everyone:
- “just use the API”
PewDiePie:
- built a 10x GPU AI Server (8x modded 48GB 4090s, 2x RTX 4000 Ada)
- runs opensourcemodels with vLLM for TP
- vibe-coded his own Chat UI, including RAG, DeepResearch, and TTS
- is fine-tuning his own model
be like PewDiePie
Buy a GPU

493
1,176
22,722
1,453,826
Did a parametric experiment to understand really the reason why dropout reg works so well.
Didn't really document per se as I just wanted to check it out.
I feel like I'd go with the researchers that say this is because of the less reliance on individual nodes there by stabilizing the network, although I won't really say the other findings are really orthogonal so...
I'll do much more research and hopefully document this time so y'all can see.
2
4
102
Nonso Dev retweeted
20 Oct 2025
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...
20 Oct 2025

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
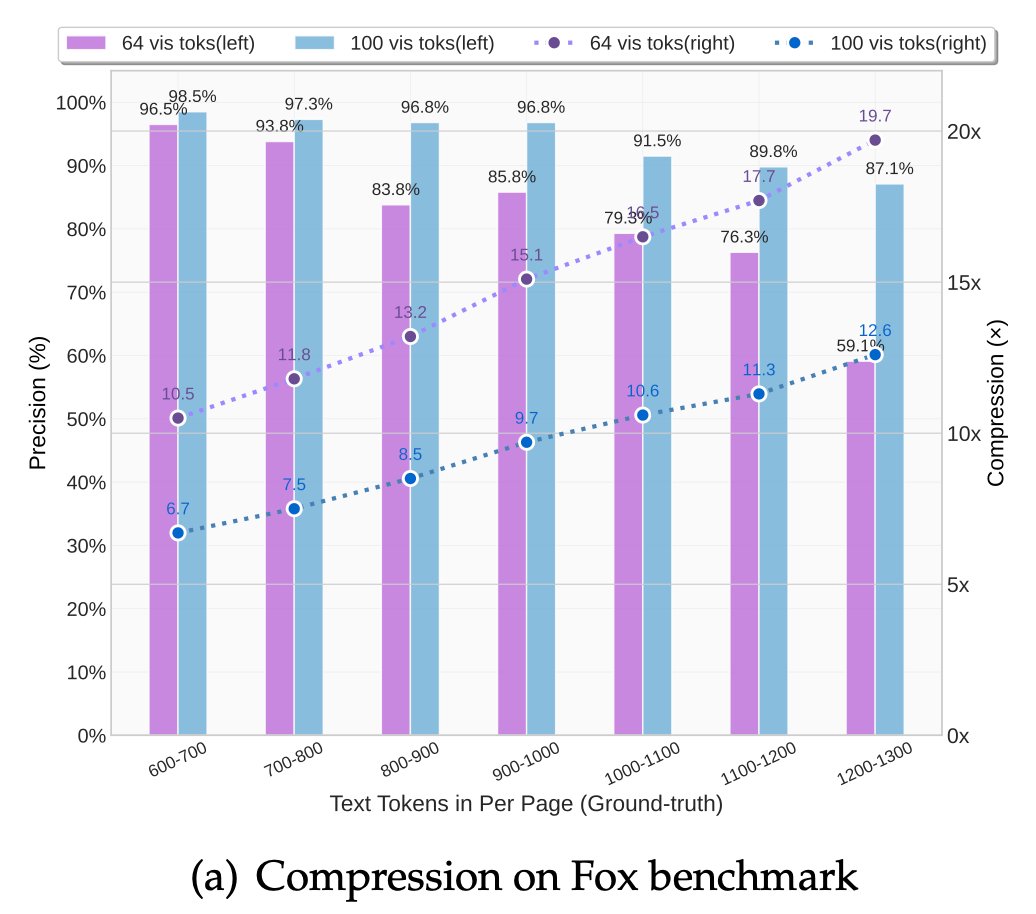
🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×.
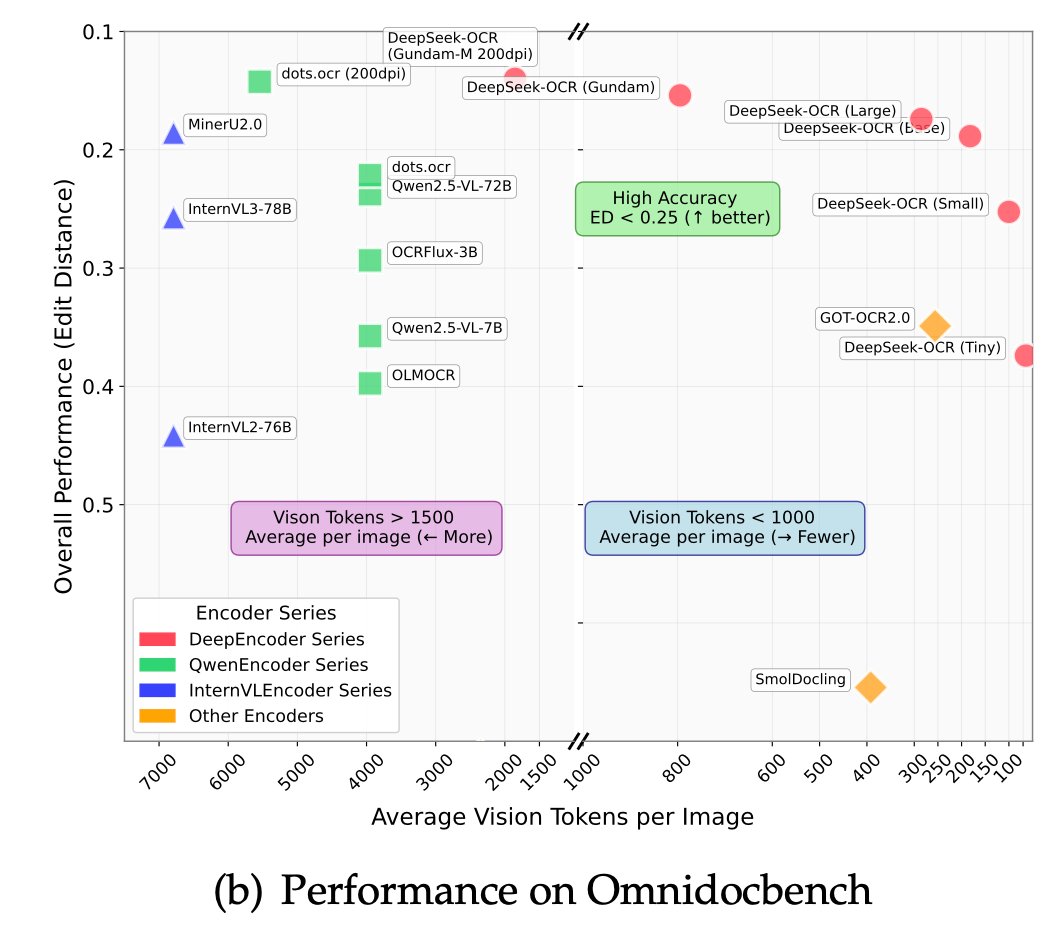
📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens.
🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale.
🔗 github.com/deepseek-ai/DeepS…
#vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning

558
1,558
13,282
3,329,666
Nonso Dev retweeted

15 Oct 2025
An exciting milestone for AI in science: Our C2S-Scale 27B foundation model, built with @Yale and based on Gemma, generated a novel hypothesis about cancer cellular behavior, which scientists experimentally validated in living cells.
With more preclinical and clinical tests, this discovery may reveal a promising new pathway for developing therapies to fight cancer.
537
3,181
21,604
6,864,675
Nonso Dev retweeted

15 Oct 2025
your honor i object, i dont know about harvard but stanford literally releases SOTA courses


14 Oct 2025

Harvard and Stanford students tell me their professors don't understand AI and the courses are outdated.
If elite schools can't keep up, the credential arms race is over. Self-learning is the only way now.
43
119
2,992
516,284
Nonso Dev retweeted

16 Oct 2025
Builders’ Challenge Live: How to Build & Win with AI Agents x.com/i/broadcasts/1lDGLBeze…
13
19
60
2,518