
656 Photos and videos















Emmanuel T Odeke retweeted

8 Jan 2020
This is tragic! I know at least 2 people who perished on this flight!
RIP professor Mojgan Daneshmand who got me very excited about electrical circuits in 2013 and in school for a while!
RIP to all the victims!
I wish peace, solace to their families, communities and countries!
8 Jan 2020

Two University of Alberta professors, a married couple with two daughters, are among the 27 Edmontonians killed in the Ukrainian passenger crash. More here: cbc.ca/1.5418751 #YEG

6
2
28

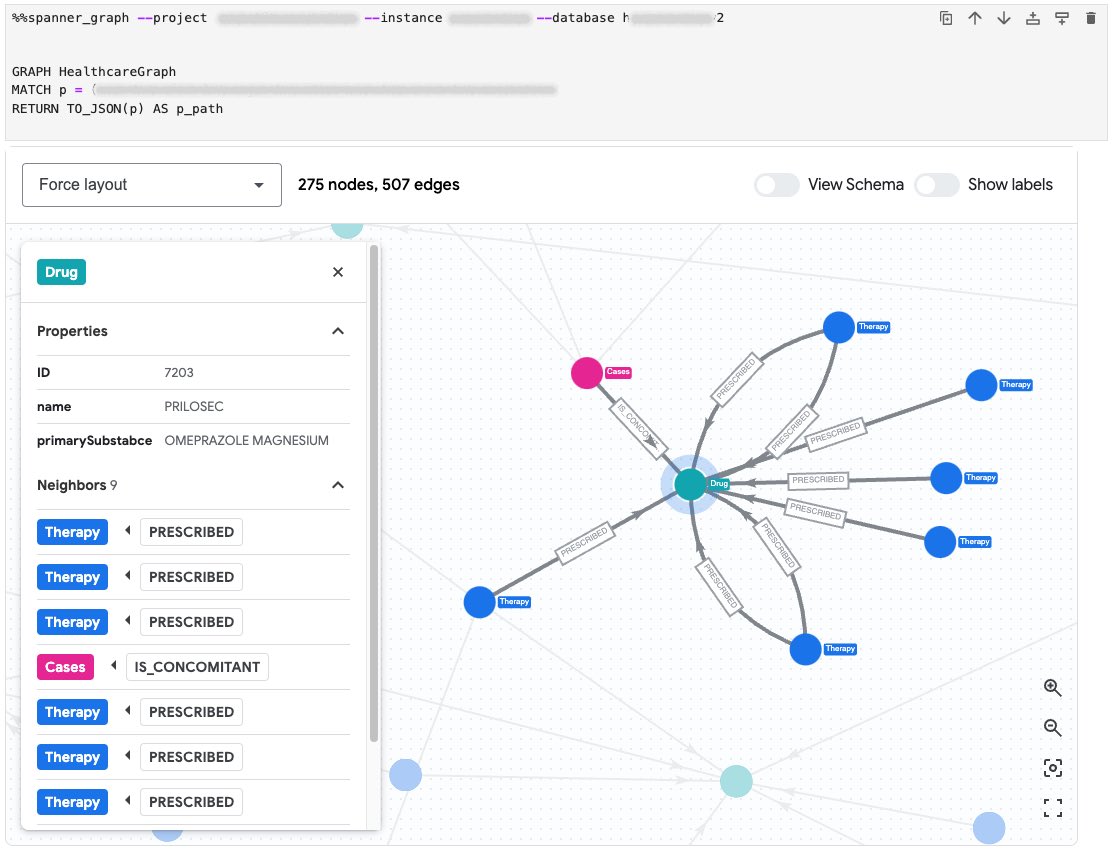
Why financial services & technology companies should choose Google Cloud Spanner as their database:
* Vector search
* 99.999% availability
* Graph
* Indefinite horizontal scalability
* Observability
* Statistics & aggregation
* many integrations
etc
Read spanner.orijtech.com/finserv…

2
7
646
Emmanuel T Odeke retweeted

5 Jun 2015
never care about what people think about you...unless...they actually care about you
27
219
1,012
Emmanuel T Odeke retweeted

18 Dec 2024
🤝 We’re thrilled to expand our partnership with @Temenos! Our custody solution, Taurus-PROTECT, is now fully integrated with Temenos Core Banking, making us the first fully integrated digital asset custody platform within Temenos’ ecosystem.
Read more: eu1.hubs.ly/H0ftmnB0

1
3
6
1,697
Emmanuel T Odeke retweeted
8 Oct 2024
We often hear about HSM and MPC in the context of digital asset custody. But what do they mean, and what should financial institutions know about these technologies?
Jean-Philippe Aumasson, Taurus’ CSO, explains in this video.
1
4
868
Emmanuel T Odeke retweeted

24 Dec 2024
14 Deep Lines about Psychology and Life:
1.

55
1,529
16,753
2,024,305
Emmanuel T Odeke retweeted

21 Dec 2024
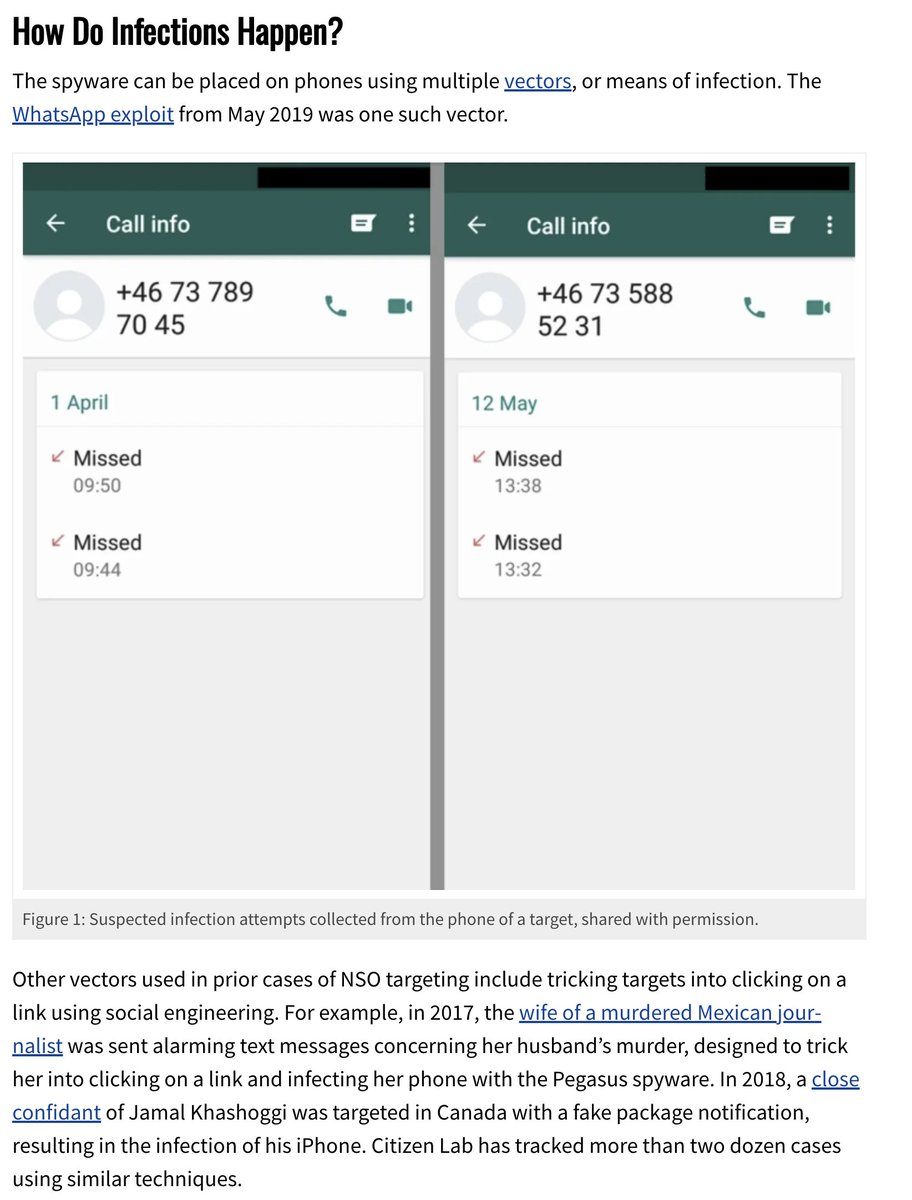
7/ The victims in the 2019 hack had been targeted with a simple missed video call exploit.
No action required, and once-infected, the call log would typically be deleted.
We @citizenlab volunteered help investigate the target list and try find journalists, dissidents, and human rights defenders.
We found a lot.
And plenty of unexpected pockets of repression. Like the targeting dissident members of the clergy in Togo.
citizenlab.ca/2020/08/nothin…



2
122
399
28,029
Emmanuel T Odeke retweeted

20 Dec 2024
youtube.com/watch?v=9Nw_DMpm…
For me, this passes the Turing Test. I genuinely can’t tell if it’s generated by artificial intelligence. If so, it’s an astonishing showcase for what AI can do. Either way, it’s an excellent showcase for my new book, The Genetic Book of the Dead.
82
105
838
167,216
Emmanuel T Odeke retweeted
21 Dec 2024
3/ Today, the court decided that enough was enough with NSO's gambits & efforts to hide source code.
Judge Hamilton granted @WhatsApp's motion for summary judgement against the #Pegasus spyware maker.
The judge finds NSO's hacking violated the federal Computer Fraud & Abuse Act (#CFAA), California state anti-fraud law #CDFA, and was a breach of contract.
What happens next? The trial proceeds only on the issue of resolving damages stemming from NSO's hacking.
Order: storage.courtlistener.com/re…

3
180
653
42,423
Emmanuel T Odeke retweeted
21 Dec 2024
2/ In 2019, 1,400 @WhatsApp users were targeted with #Pegasus.
WhatsApp did the right thing & sued NSO Group.
NSO has spent 5 years trying to claim that they are above the law.
And engaged in all sorts of maneuvering.
With this order, the music stopped and NSO is now without a chair.


7
186
741
48,870





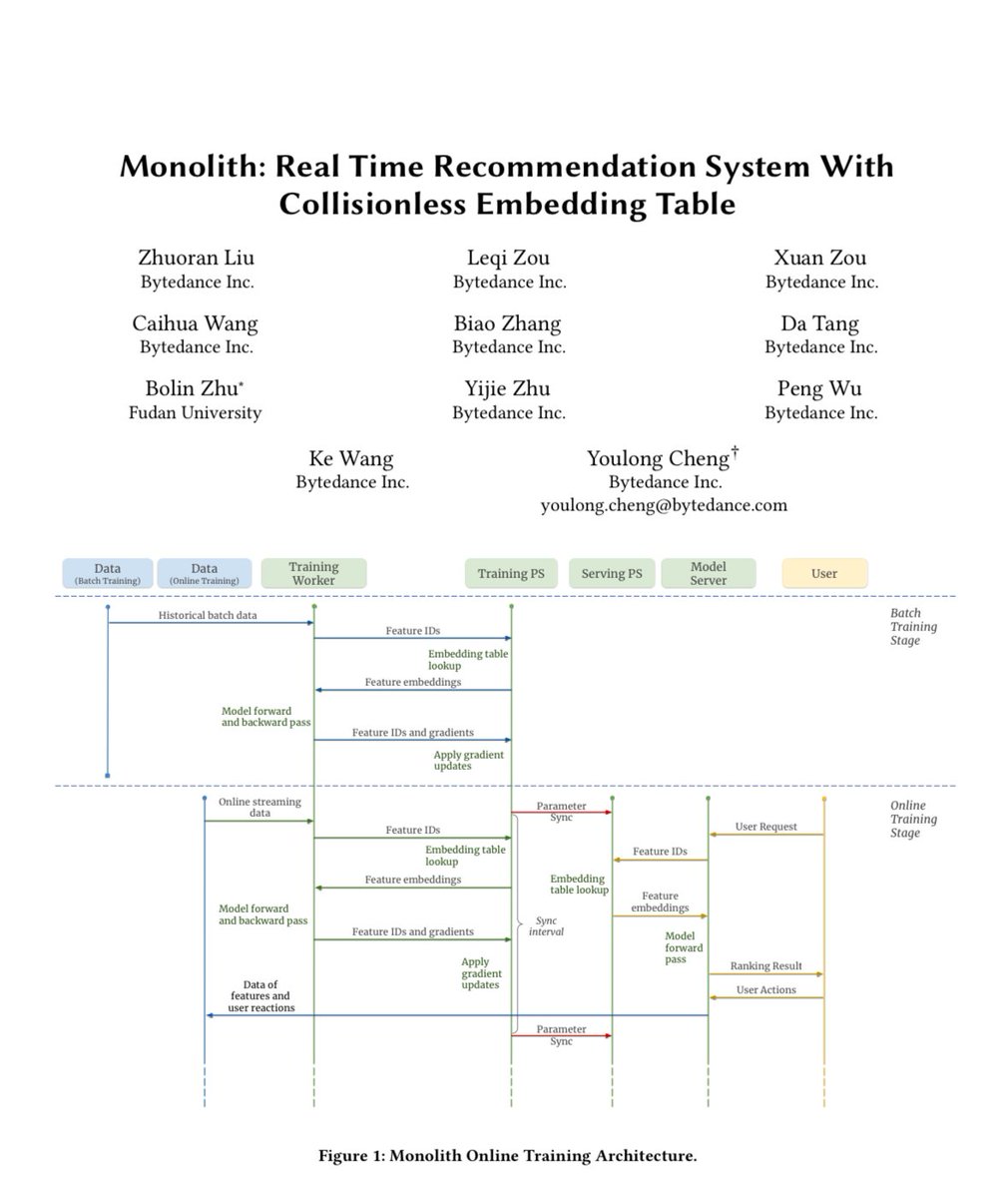
Tiktok's Monolith paper is a must read.
It shows that you don't need a social graph to make an addictive product if you nail real-time recommendations that update AS each user scrolls.
Very few great applied CS papers exist and even fewer that made a 1B user product!
66
923
9,535
790,553
Emmanuel T Odeke retweeted

19 Oct 2024
Scalability! But at what cost?
This paper is an absolute classic because it explores the underappreciated tradeoffs of distributing systems.
It asks about the COST of distributed systems--the Configuration that Outscales a Single Thread. The question is, how many cores does a big distributed system need to outperform some moderately-optimized single-threaded code running on your laptop?
As it turns out, scalability often comes with an extremely high COST. The authors examine several graph processing systems--including some big names like Spark--and find that they need dozens to hundreds of cores to outperform a single-threaded program.
Why is this the case? It's not because these distributed systems are badly designed, but because distributing computation is inherently inefficient for many problems.
Fundamentally, a distributed system cannot rely on all processors sharing state, at least not efficiently. This is a big issue! In graph algorithms, it means servers need to expensively exchange data and eliminates a wide swathe of algorithms and optimizations that rely on shared state. In distributed databases, it means expensive coordination is required to distribute transactions to ensure participating servers have consistent views of data.
Does this mean we shouldn't build scalable systems? Of course not! Many problems are well beyond the capability of a single server, no matter how optimized. But it does mean we should be mindful of the efficiency costs of scaling.
As an aside, I think this kind of thinking is why Postgres is so popular, despite not being distributed. A large Postgres server can handle a vast amount of traffic (especially with read replicas, which can be cheaply maintained). You need a huge company or incredibly heavy workload to outscale that single server, and when you do, the alternatives come with huge tradeoffs!

12
184
1,096
97,496
Emmanuel T Odeke retweeted

21 Oct 2024
CVE-2024-9143 (openssl-library.org/news/sec…) was disclosed recently, which was found by OSS-Fuzz-Gen! This is a pretty proud example of our team showing the promise of leveraging LLMs enable more fuzzing coverage.
23
123
46,741

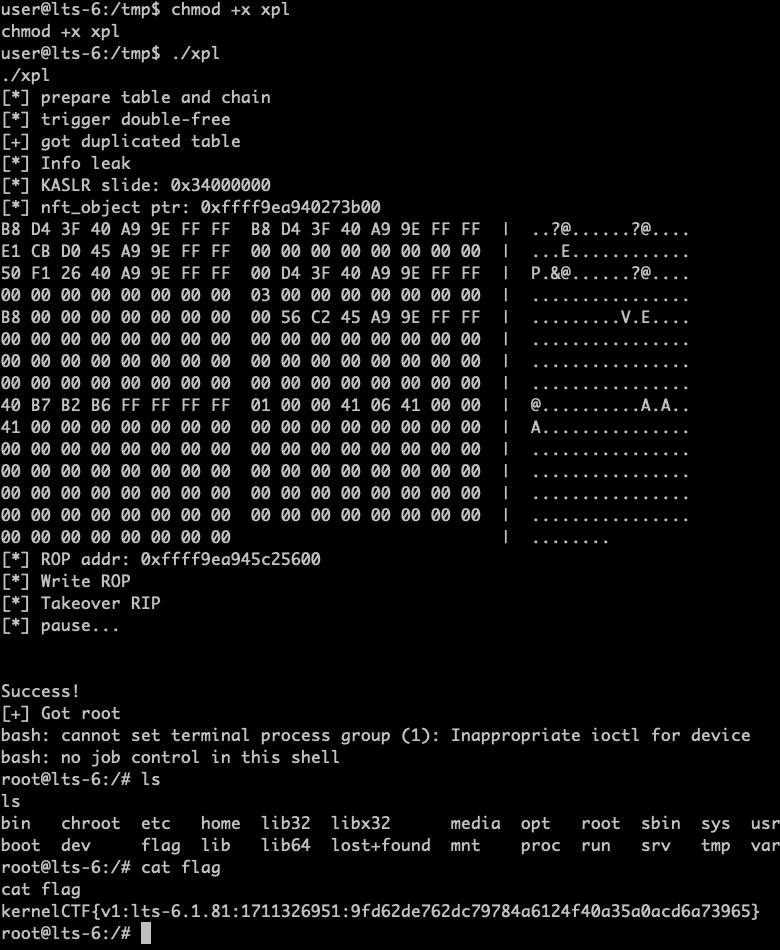
Earlier this year, I used a 1day to exploit the kernelCTF VRP LTS instance. I then used the same bug to write a universal exploit that worked against up-to-date mainstream distros for approximately 2 months.
osec.io/blog/2024-11-25-netf…

3
111
428
51,993

After 25.3 million autonomous miles driven, @Waymo vehicles have an 88% reduction in property damage claims and a 92% reduction in bodily injury claims compared to human drivers per mile driven. 🚖


Our mission is to be the world's most trusted driver and a new study by @SwissRe validates the exceptional safety record of the Waymo Driver. Learn more: waymo.com/blog/2024/12/new-s…
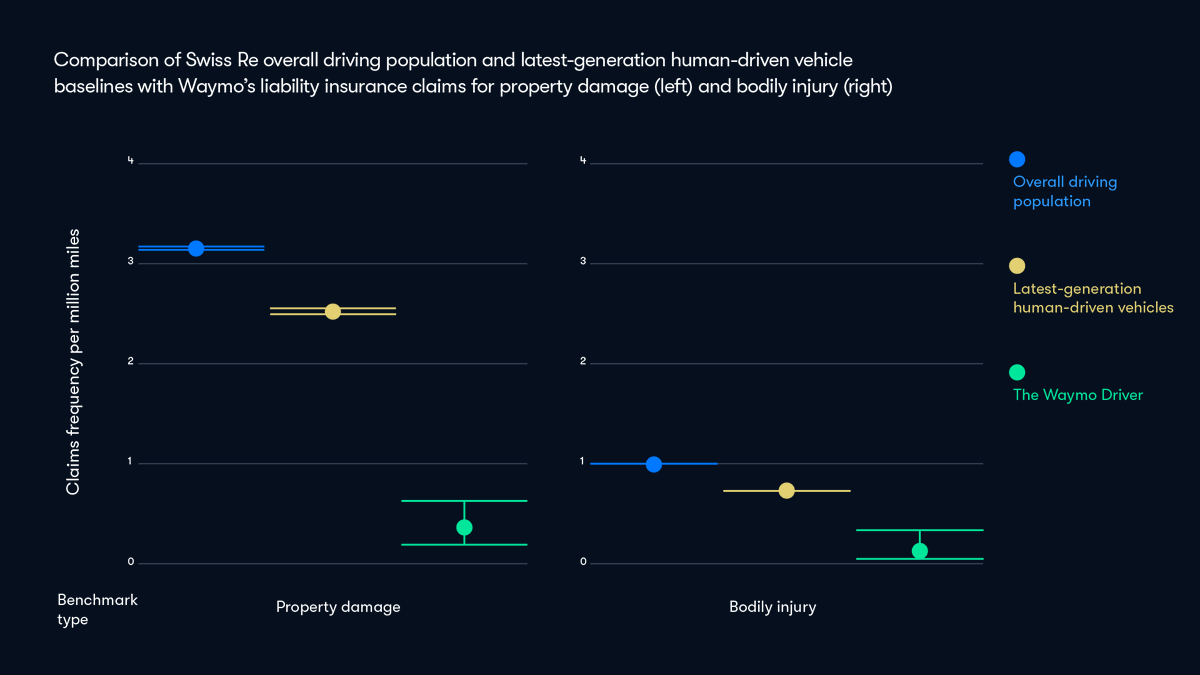
ALT Comparison chart of Swiss Re overall driving population and latest-generation human-driven vehicle baselines with Waymo's liability insurance claims for property damage (left) and bodily injury (right)
94
623
4,583
754,178

Emmanuel T Odeke retweeted

24 Apr 2024
The rise of Go is phenomenal. It is definitively a mainstream programming language. I am a long-time fan of Go... and even I is surprised by the uptake.
#golang
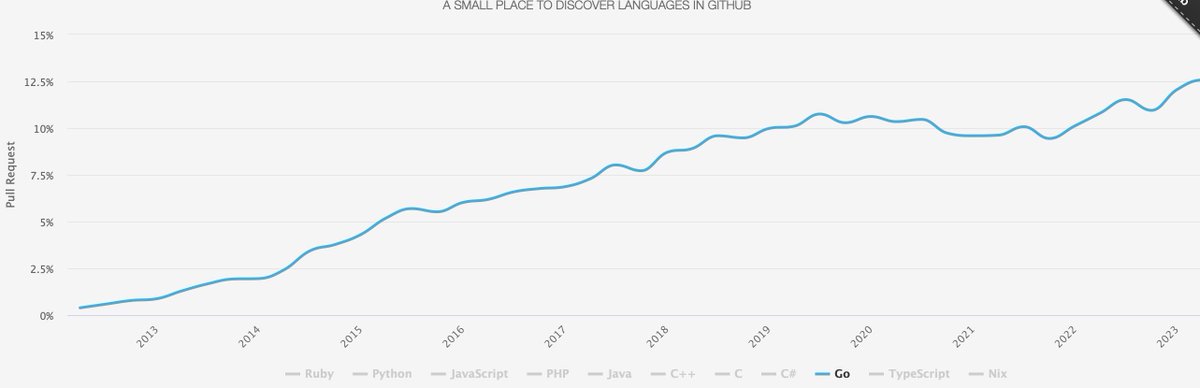
24 Apr 2024

Top 10 languages on GitHub by number of 'pull requests'.
The apparent fall of JavaScript is related to the rise of TypeScript.
Python represents a steady 20% of all pull requests.
PHP and Ruby are trending down.
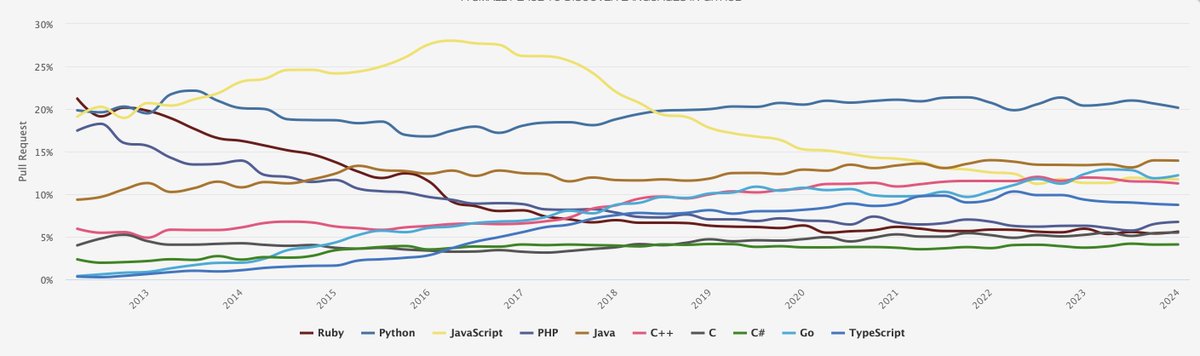
9
14
129
23,524

“Go Protobuf: The new Opaque API” by Michael Stapelberg — go.dev/blog/protobuf-opaque
#golang
3
50
267
26,769
Emmanuel T Odeke retweeted

16 Dec 2024
It's definitely been a journey. Really excited for what is coming in the next few months 🚀
16 Dec 2024

🎉 Happy 2nd Birthday to the Quicksilver Protocol! 🎂
Two years ago today, Quicksilver was born with a mission to revolutionize liquid staking and interoperability in the Cosmos ecosystem. 🚀
Fast forward to today: we now support 11 amazing chains including $ATOM, $OSMO, $TIA, $REGEN, $STARS, $SOMM, $JUNO, $BLD, $SAGA, $DYDX, and $ARCH! 🌌
Thank you to our community, contributors, and partners who’ve made this journey possible. 🙌
So… where should Quicksilver go next? Drop your chain suggestions below! 👇
Here’s to another year of innovation, growth, and expanding the multi-chain future. 🛠️✨
#Quicksilver #LiquidStaking #Cosmos #Interchain #HappyBirthday

ALT Birthday cake covered in candles and the number 2.
3
8
1,044