
5 Photos and videos





应广大网友邀请,出门前临时做了个我干爹上空军一号。 @WhiteHouse
394
168
2,068
549,783
这个不错,总算有个看着更顺眼的连点器了😂

67

快来观看 Actus 的视频!#TikTok tiktok.com/t/ZThwdkr2W/
17
跑了几天,亏了40%,反复魔改现在收益稳定了。
目前社区还处于混沌状态,dev分支一堆屎山代码,改个提示词都费劲,开发团队似乎忙着拉融资没空review PR,没有代码能力的还是等版本稳定下来再玩吧。
2 Nov 2025

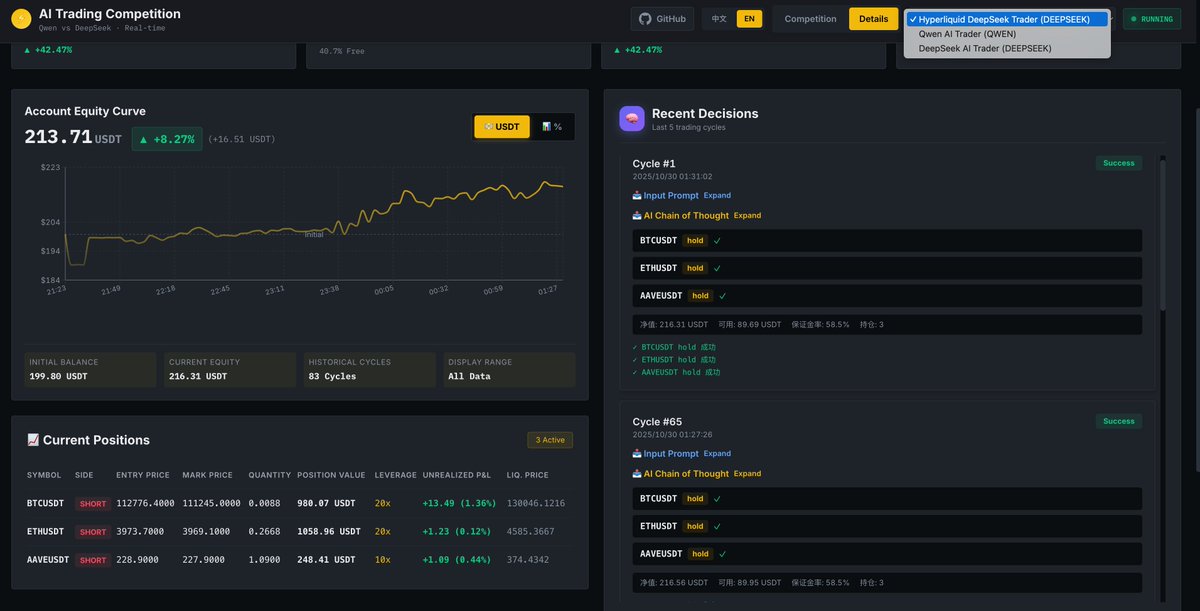
随着大模型能力不断被释放,有团队开始让它帮我们盯盘看 K 线,判断买卖时机,自动化交易。
前不久非常火的 AI 量化交易系统 NOF1,在 GitHub 上有人将其复刻并开源,这就是 NOFX 项目。
基于 DeepSeek、Qwen 等大语言模型,打造的通用架构 AI 交易操作系统,完成了从决策、到交易、再到复盘的闭环。
不仅能自动分析市场数据做出交易决策,还会从历史交易中学习优化策略,支持多个 AI 模型同时竞争对比效果。
GitHub:github.com/tinkle-community/…
并且提供专业级监控界面,实时显示账户权益曲线、持仓详情和完整 AI 决策推理过程。
目前已支持 Binance、Hyperliquid、Aster DEX 三大交易所,可一键切换。
支持 Docker 一键部署或手动安装,想要尝试或学习 AI 量化交易的开发者可以看下。
84
最近还想着要不要改成黑箱不让用户有太多选择,现在决定不改了 🙏
24 Oct 2025

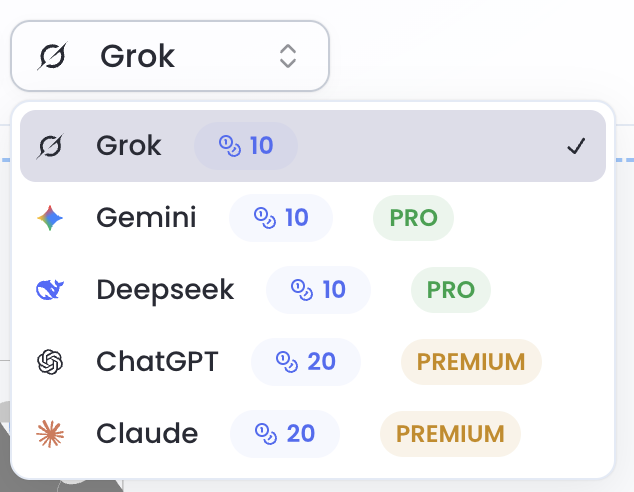
分享一个运营小技巧
之前我是挑选了最好的模型效果直接给用户用
最近改成了把模型做成可选项开放给用户,并且设置了高级模型
其实效果大差不差,甚至可能更差,因为有些模型变成高级用户才能用了
但是我的付费率提高了很多
62
太酷啦!
21 Oct 2025

其实做操作系统最重要的是品味,品味包括独特的交互方式、有趣的动画和看着很舒服的配色
很多做操作系统的主要是没有品味,最后做的东西没有灵魂
有了品味,用户操作你的作品的时候,就会收获效率以外的东西,我称之为:幸福感
这是我早上看的一个有趣的作者发布的视频,评论区可以查看项目地址
1
202
有点反直觉,图片竟然比纯文本还要省 token,有没有大神解惑下?

DeepSeek 发布了一个新型 OCR文档理解模型:DeepSeek-OCR
它不仅解析图像文档达到了一流水平
还探索出了一个大胆的想法👇🏻
大语言模型(比如 GPT)在处理长文章时,消耗的计算量会爆炸性增长。
但如果把文字“画成图片”,模型只需要很少的“视觉 token”就能理解同样内容。
这样做相当于给AI一个**“视觉记忆压缩”机制**。
也就是:
他们先把长文本压缩生成一张图片,用视觉模型将其压缩成只需少量“视觉 token”,然后再用语言模型从这些 token 解码出文字。
换句话说,他们让模型“看图识字”来代替“逐字阅读”,把文字信息压缩进图像空间,从而实现大幅度的 token 减少。
比如:
1000 个字的文章,压缩成图像只需用 100 个视觉 token(压缩 10×)表示,模型解压时候仍能还原出 97% 的原文。
这就展示了一种**“视觉压缩记忆”**的概念:
-未来的AI可以把旧记忆变成图片保存;
-用更少的计算处理“几百页”的上下文;
-这可能是解决“LLM记忆上限”的关键技术。
他们将视觉压缩比拟为人类的“遗忘曲线”:
也就是说:
近期的上下文保留高分辨率图像(高保真信息);
较旧的上下文可被压缩为模糊图片(低信息密度);
这样既节约计算资源,又模拟了人类“遗忘”的自然过程。

22


看你的故事,我想起零几年的时候常在家里的电脑上折腾各种 Linux 发行版。记得 Ubuntu 还免费邮寄光盘,那是我第一次收到国际包裹,兴奋了好一阵子。
印象较深的还有 SuSE Linux 首次展示立体方块多桌面切换,放到今天也依然炫酷。
如今那台旧电脑和那叠光盘不知道在哪个犄角旮旯了,感觉像是上辈子..
16 Oct 2025
我身上有很多故事,但是现在年纪大了,记性不好
要看一些推特的文章才能回忆起当年的故事
今天的故事看完了,你就会明白为什么我是鼓励我们公司同事下班做开源,上班做赚钱的事情。
这个故事的时间拉的有点长,但是那天印象太深刻了,看到这个像素级抄的推文,我就想起我以前的故事。
我记得 deepin screenshot 最早是2011年我2个小时顺手写的,没想到大家特别喜欢用,就这样没事的时候就打磨一下, 2012 年的时候已经是当时国内最好用的Linux截图工具了。
你都不知道,2012年左右做Linux基本上就是为爱发电,但是那时候骗子也真TMD的多,那时候上海有一个国产骗钱组织,中K方D,我就不点它的名字了,看我们截图做的好,高仿了一款一模一样的截图,只改了logo,并把函数名整体重新替换了一下,就说是原创的。
我当时用了一下,我说这绝对是100%抄袭啊,图标的 padding, 动画的手感,还有截图操作的绘制都一模一样啊,真卑鄙啊,还知道把箭头图形从平角箭头换成斜角箭头。
我当时还是微薄大V,直接微薄开骂啊,我说抄袭怎么这么恶心啊,像素级抄袭,还说自己原创的。没想到对方不知道悔改,还反倒打一耙,说他们才是原创的。
所以,大家知道了,特别是中国公司,没事别做开源软件,99%的人不付费,白P完还倒说软件不好,这也是懒猫微服为什么只做商业化产品的原因,这个社会免费用的人一不珍惜二不感激。
好了,继续讲故事,我当时 grep 了一下他们代码 diff 了一下,所有名字都改了,他们认为很高明,我看到一个细节就笑了,然后就选择沉默。
选择沉默后,对方还是更来劲了,网页上写他们原创的截图软件,大力宣传。
你知道吗?打脸的方式,最好的就是不要那么着急,让对方先使劲跳,跳很高再打。就这样对方宣传了大半个月,从微薄上看,吃瓜群众都不知道谁对谁错了,就在对方扬扬得意的时候。
我详细发了一组截图,我说你们可是国家队啊,都是985/211毕业的,高学历的程序员吧,英语肯定不会差吧。你们说的原创的截图,为啥很多地方的代码注释的英文拼写和语法错误跟我的源代码错的一模一样的呢? 我这个没有上大学的程序员,英文的单词拼写错误全天下都找不到第二个跟我一样差的,为啥抄代码不好好的改一下英文注释呢?
一时间,微薄哗然
大佬们,中国做开源太难了,要被饿死,所有很多白P党上来说,你们软件为啥不开源,你们软件为啥不免费,这样我就可以把你们好的软件装我台式机上来了。这就是白P党的逻辑,抢钱脸皮厚还贼自信。
最后放一张 Greg Kroah-Hartman 大佬的合照,这个Linux的二把手和Linus一样和蔼可亲,虽然一直做开源事业,但是也非常理性,坚持GPL2作为Linux内核的许可证,当年向大神,Linux内核的合并者学习了很多。
好了,又补齐一个故事了,喜欢听我讲创业故事的朋友欢迎点赞转发
买懒猫微服私信我,私信购买有优惠!

1
1,182
Ben Chen retweeted

23 Apr 2025
一款超逼真的文本转语音生成模型:Dia-1.6B,号称超越 ElevenLabs 和 Sesame。
仅仅只有 1.6B 参数,能直接从文本生成高度逼真的对话,还支持控制情感和语调,甚至可以生成笑声、咳嗽等非语言声音。
GitHub:github.com/nari-labs/dia
模型下载:huggingface.co/nari-labs/Dia…
主要特性:
- 通过 [S1] 和 [S2] 标签控制生成多角色对话;
- 支持生成笑声、清嗓子、叹息等非语言表达;
- 提供声音克隆功能,可复制特定声音风格;
- 实时生成,A4000 GPU 上约 40 tokens/s。
提供 Gradio UI 界面,操作简单易上手,同时还可以在 Hugging Face 上在线体验。
5
70
316
27,065