
Building the spatial intelligence layer for enterprise with the power of vertical AI agents.
Joined February 2022
- Tweets 529
- Following 757
- Followers 6,226
- Likes 344
105 Photos and videos















The apps model for extended reality (XR) content is not going to work. No download, everything contextual. Driven by GenUI, enhanced by AI agents and most importantly developed from an open source library you can expand limitlessly.
- Omnia plan for 2025 onwards.
5
1,061
Most smart glasses demos show someone reading instructions off a screen.
That's not what we built.
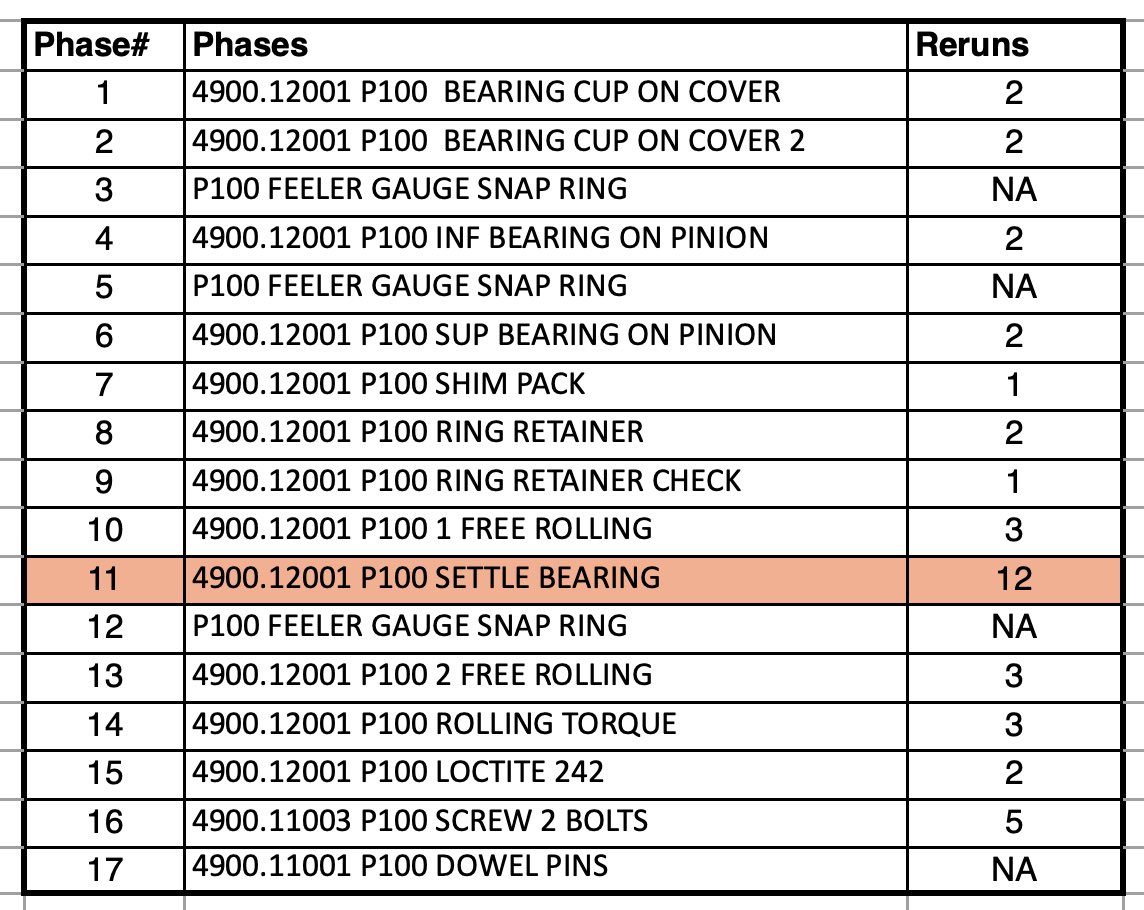
At Comer Industries (Rockford IL), we analyzed 1,025 measurement records across 13 assembly stations.
The Settle Bearing step alone was failing 85.7% of the time. One unit needed 12 consecutive reruns on a single step with zero guidance on what to change between attempts.
76% of all failures had a measured value of exactly zero. The machine ran, captured nothing, logged a defect. Not a bad part. Not a broken tool. The worker initiated the cycle before a physical prerequisite was met — because nothing stopped them.
Here's what we built:
OmniaAgent connects Rokid smart glasses to the legacy OEM software running on the station. The machine completes a press cycle → glasses HUD advances automatically. Worker confirms a step by voice → station software advances in sync.
On top of that: a CV model trained on footage from Comer's own equipment, their own parts, their own assembly line. Not a generic model. One that knows what a correctly seated bearing cup looks like on this fixture before this press descends. It checks before the cycle runs. It blocks the invalid cycle before the machine fires.
The result: 71.9% of failures are directly addressable. $2.3M in projected annual savings — grounded in their actual production data, not estimates.
One station. Path to 100.
This is what enterprise AI on the factory floor actually looks like — agents integrated into legacy OEM software, CV models trained on the client's own equipment, error rates as the scoreboard.
#SmartGlasses #ManufacturingAI #ComputerVision #EnterpriseAI #AIAgents #Industry40

1
1
118
What would an openclaw built agent for enterprise look like on smart glasses? Openclaw nemoclaw.
Built on a real catalogue-backed knowledge base Google Sheet source of truth, with OmniaClaw as a customized OpenClaw UI layer—what you can do today still bumps into documented OpenClaw limits (tool host, local bridge wiring, channel UX). Demo shows supervisor → operator dispatch → voice → sheet anyway.
3
1
109
OmniaClaw on actual glasses. Three demos.
1/ Machine instructions — custom JSON, mock coffee machine. Swap the JSON, swap the machine. Carrier unit, Trane chiller, PTO shaft — same runtime.
2/ Service log — worker speaks, row writes to sheet. No form. No tablet.
3/ Full operator flow on glass — voice, full-screen messages, supervisor path closing in real time.
Next layer: custom CV models on your equipment. The JSON tells the worker what to do. The vision model watches if they did it.
Custom demos available — manufacturing, HVAC, field service.
50
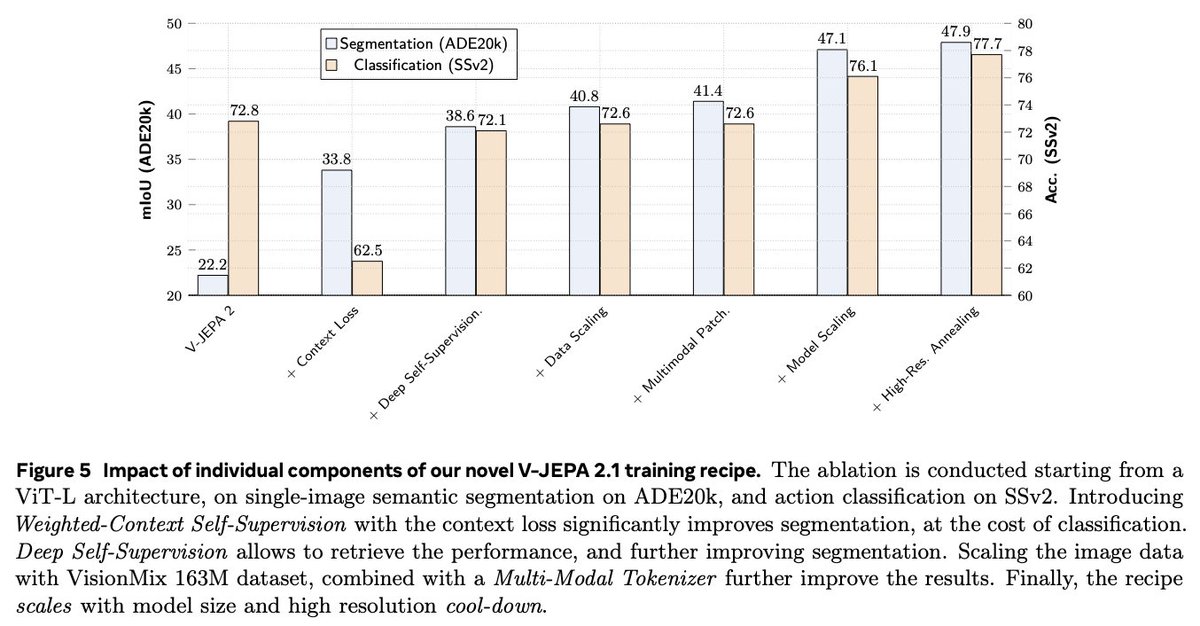
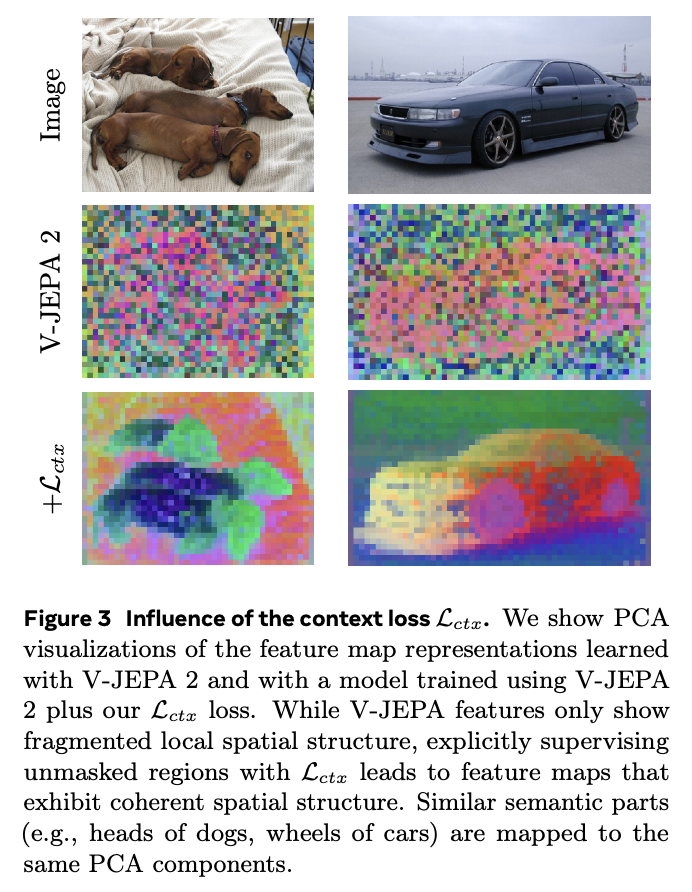
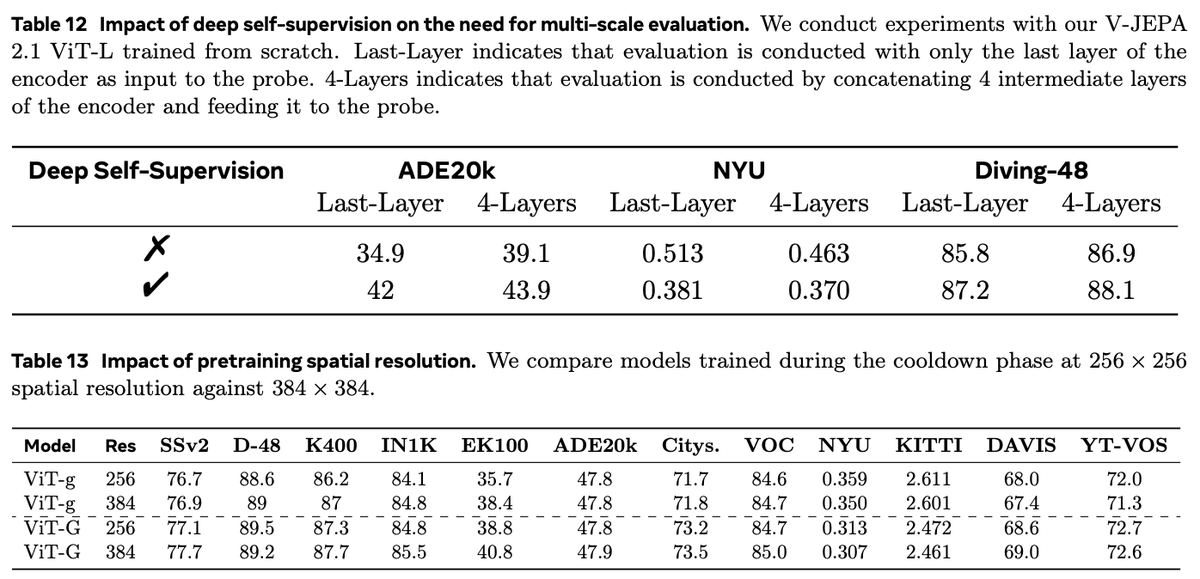
V-JEPA 2.1 (Meta FAIR) is a video JEPA that learns dense representations from pixels: a predictive objective in latent space (not “generate every frame”), with deep self-supervision and a unified image video encoder—so the model sees fine spatial structure and how it evolves over time.
For us (smart glasses): that’s the right kind of world model for egocentric wear—anticipation, depth-aware AR, stable perception under head motion, and a path to distilled on-device variants. Thread on what that means in practice ↓
10
1
85
If you’re pitching “AI glasses,” ask whether your stack learns a compact predictive model of the scene. V-JEPA 2.1 is a strong citation for why JEPA-style video world models belong in the architecture, notas an optional add-on.
arxiv.org/abs/2603.14482 · Meta overview: ai.meta.com/vjepa/ · Code: github.com/facebookresearch/…
56
We built a UI that reads your body.
Omnia's GenUI uses EMG wristband data to classify physiological intent in real time and render only what you need at that moment. it's called BB-UAII a policy engine that maps body state to display config.
The preview video is based on Rokid hardware (open SDK, real display).
The Ray-Ban Meta mockups in the deck show where we're going — but Meta's current SDK doesn't support dynamic overlay rendering yet, so we're clear about that.
This isn't a novel idea, Google Research (Leviathan et al., 2025) proved LLMs can generate full UIs on the fly but it's applied to Web apps. CHI '26 is asking what it means for HCI.
@tambo_ai is building the React primitive.
We're asking what it means when the hardware is on your face and the signal comes from your muscles.
Enterprise applications are the obvious first vertical: factory floors, operating rooms, logistics — anywhere cognitive load is the bottleneck.
The interface is not configured. it is learned.
Building demo on @Hi_CYBERSIGHT and considering @goEverySight as well.

6
125
The Open-Ended Architecture
Omnia GenUI is input-agnostic by design. The intent classifier sits behind a normalized signal interface that accepts any physiological input source. Today that's:
Apple Watch → iPhone → Zenith via HealthKit (HR, HRV, SpO₂, workout state)
Garmin devices via the Zenith's native ANT /Bluetooth bridge (power, cadence, pace)
Neural Band (EMG) via direct BLE to the companion app (muscular activation onset, amplitude envelope, sustained contraction flag — sampled at 20Hz)
Standard BLE sensors (heart-rate straps, power meters) via the Zenith's direct sensor pairing
The architecture treats all of these as competing or complementary streams feeding a single classifier. The Neural Band has the lowest latency and highest signal specificity (intent before conscious effort). HealthKit has the richest longitudinal data (HRV baselines, historical session data for the "model gets smarter" flywheel).
The Zenith then renders whatever display config the policy engine outputs — it has no opinion on what the source was.
62
The @Hi_CYBERSIGHT Zenith is a strong prototype target for Omnia GenUI. It's a 39g binocular waveguide HUD with adjustable brightness from 10–1500 nits, IP54 protection, up to 8 hours battery, and crucially — it syncs with iPhone, Android, Apple Watch, and Garmin devices to pull real-time sensor data including power, heart rate, and pace via Bluetooth CYBERSIGHT. The display architecture is already built to accept a streaming data feed and render it in the FOV. What Omnia adds is the intelligence layer that decides what to render.
The Zenith's phone-mediated connection to Apple Watch opens a clean data pipeline. Here's how Omnia taps it:
1. HealthKit as the data bus Common readable types include heart rate, HRV (heartRateVariabilitySDNN), SpO₂, and active workouts. Themomentum These are the exact signals Omnia's intent classifier needs. The iOS companion app requests granular HealthKit permissions per data type, then runs a persistent background query during an active workout session.
2. Near-real-time streaming via HKAnchoredObjectQuery To get data in near-real time, you declare an HKWorkoutSession to tell the Watch it's in active monitoring mode, then start an HKAnchoredObjectQuery — this triggers its updateHandler every time HealthKit receives a new sample Apple Developer, rather than polling on a fixed schedule. For heart rate specifically, this gives updates every few seconds during a workout. This feeds Omnia's intent classifier at a cadence appropriate for state transitions (low → moderate → high intent) without over-polling.
3. HRV as the deeper signal Beyond raw HR, Omnia queries HKQuantityTypeIdentifier.heartRateVariabilitySDNN — the RMSSD-derived HRV score Apple Watch exposes. This is what the BB-UAII policy engine uses to distinguish sustained high effort from momentary spike, which is the difference between showing a full directive or letting the display settle back to whisper mode.
4. Important constraint to be honest about You cannot access real-time heartbeat data directly; higher-frequency heart rate samples are only available within HealthKit for samples collected during Workouts and ECG sessions. Researchandcare Raw PPG is not exposed. This means Omnia's Apple Watch pipeline is latency-bounded by Apple's sensor-to-HealthKit write cycle — practically 3–5 seconds for HR, longer for HRV.
That's fine for display density decisions (which operate on 5–15 second state windows) but rules out sub-second haptic/audio sync without a dedicated wristband like the Neural Band.
100
"The recent proliferation of powerful LLMs has enabled the generation of UI code directly from unstructured natural language prompts. Our approach differs by tasking the LLM to generate entire, interactive, and data-driven web applications from a single prompt, effectively acting as an autonomous web developer."
44