Joined August 2013
- Tweets 25,038
- Following 1,262
- Followers 155,104
- Likes 44,024
8,394 Photos and videos












Jun 13
Anthropic 这个公司太搞笑了。
天天技术恐吓,天天让国家注意 AI 安全,这下把自己套进去了。
美国政府要求他们禁止给任何非美国公民,哪怕是在美国的人提供 fable 5 的访问。
他们没办法保证这个,只能先下掉了所有人的访问权限。
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
134
25
396
206,083
Jun 13
重置了
Jun 13

We've reset 5-hour and weekly rate limits for all users.
6
9,341
Jun 12
万字长文:做了些爆款 Skills 以后,我对 Skills 的看法
最近做了几个传播还不错的 Skills后,我对 Skills 的理解也有些变化。
这篇文章算是我目前对 Skills 最系统的一次复盘。
我写了为什么 Agent 不是聊天框,为什么 Agent 会放大人的能力差距,为什么 Skill 可能是普通用户真正用好 Agent 的关键中间层;
也写了一个好 Skill 应该怎么设计、怎么维护、怎么分发,为什么 Skill 生态不能只做成仓库列表,以及内容、产品、案例、反馈之间如何形成一个持续迭代的飞轮。
这不是一篇概念科普,也不是对别人观点的转述,更多是我自己做了一批真实案例之后沉淀下来的判断。
如果你正在做 Agent、AI 工具、插件生态、内容产品,或者想把自己的专业经验变成可复用的能力,这篇文章应该会有一些参考价值。

11
16
94
17,179
Jun 12
发了
3
12
69
23,221
Jun 11
我现在 Twitter 时间线上只有两类内容,非常诡异:
一种是充斥着所谓“一句话生成”的很漂亮的那种用 Fable 5 生成的网页;
第二种是除了 Anthropic 自家的 AI 研究员,全在抨击 Anthropic 这次发布 Fable 5 的各种行为。
这次 Anthropic 真是惹了众怒,几乎所有我关注的研究员都在骂他们。大家主要抨击的是以下几个问题:
安全风险
它的安全护栏极其严格。你哪怕问它最基本的初中生物学问题,都会被拒绝回答。这导致很多生物学研究员和团队无法获得正常许可来进行科学研究。
数据存储政策
Mythos 和 Fable 模型的数据是明文储存且强制储存的,最高期限长达两年。虽然官方声称只用于安全分析和减少误伤,不用于模型训练,但业内没人相信这种说辞。因为这个条款的存在,微软已经禁止内部使用 Fable 模型了。
隐形降级(最严重的问题)
如果系统判断你想“蒸馏” Fable 模型,它不只是拒绝服务,还会偷偷摸摸地把模型降级到 Opus 4.8 或者更低的版本。甚至会通过修改提示词或微调等方式,暗中让 Fable 在相关话题上变笨,表现甚至还不如原生的 Opus 4.8。
大家最愤怒的点在于:
你要么帮忙,要么拒绝,假装在帮忙实际却故意把效果变差,这是一个非常严重的道德问题。这会直接污染一切基于该模型所做的算法效率比对和评估,导致现在根本无法用测试器对其进行正常评估。
实际上,这个政策对大公司和国家影响不大,受影响最深的是开源研究者、小实验室、独立开发者和科学界。
刚好达里奥(Dario Amodei)在昨天晚上新发的文章里,还在强调他们坚持透明、问责和公共机构监督。
但实际上他们拒绝一切监督问责,甚至反过来暗中破坏针对模型的评估和研究行为,这和他们宣称的完全相反。
所以,这次模型发布让 Anthropic 在业内的口碑一夜之间变得不如路边的一坨臭狗屎。
73
11
150
21,545
Jun 11
Anthropic 滑轨,承诺未来几天会在 fable 5 降级到 Opus 4.8 的时候提供明显的通知。
Jun 11
We’re rolling out changes to make Fable 5’s safeguards for frontier LLM development visible.
Starting this week, flagged requests will visibly fall back to Opus 4.8—the same as our safeguards for cyber and bio. You will see this every time it happens. On the API, any flagged requests will return a reason for their refusal (coming to server-side fallback in the next few days).
We wanted to deploy Fable 5 to our users quickly and safely. Visible safeguards can be probed, so they have to be robust, which takes time to get right. Invisible safeguards can be targeted more narrowly, allowing us to ship quickly with very few false positives. We went with invisible safeguards for this reason—and that was the wrong tradeoff. You should have visibility into the safeguards we have in place, and why. We’re sorry for not getting the balance right.
Making the safeguards visible makes them easier to work around, so keeping them robust to jailbreaks will unfortunately mean more false positives while we improve the classifiers. We're also tuning our bio and cyber classifiers to trigger less often on harmless requests. We know this is frustrating and we’ll do our best to keep this period as short as possible.
If you think a request has been mistakenly flagged: run /feedback in Claude Code, click thumbs-down on the fallback in Claude.ai or Cowork, or file the safeguard appeal form for API requests. Your reports help us tune these classifiers and we appreciate your feedback.
support.claude.com/en/articl…
3
1
8
5,423
Jun 10
笑死,藏师傅 PPT Skill 也上央视了,感谢腾讯云和 workbuddy
116
102
739
161,842
Jun 10
CodePilot v0.56.0 发布
本次更新的部分修复由 Claude Fable 5 完成。
模型与渠道扩充版本
新增 Claude Fable 5、小米 MiMo UltraSpeed 模型与通用 OpenAI 兼容第三方渠道。
并修复用量统计、回复状态丢失、服务商列表刷新等一批问题。推荐所有用户升级。
github.com/op7418/CodePilot/…
51
1
8
12,462
Jun 10
MiMo Ultraspeed 的测试
Jun 9
MiMo推出1000 Token/s超高速模型|体验测评
MiMo 推出了 MiMo V2.5 Pro UltraSpeed 超高速的模型版本,能够实现每秒输出超过 1,000 Token 的速度。
同时,这应该也是全球第一个达到这个速度的万亿(1T)参数模型。
藏师傅提前试了一下,做了三个测试,确实爽。
第一个跑了一个比较复杂的 3D 采矿小游戏测试。在没有素材的情况下,我让它全部用 Three.js 前端代码来生成素材。整体要求比较完整,虽然第一次实践时出了一些小问题,但在跟他沟通修改建议后,非常完美地实现了任务。
这次测试的各项指标如下:思考的 TPS:804 Token/s,峰值速度:810 Token/s,首次响应时间:4.71 秒。
第二个测试给了一个官网,其头部包含一个相对复杂的 3D 动画。
这次的输出速度快了非常多:峰值达到了 1426 Token/s,首次响应只用了 0.83 秒,在 32 秒内输出了 25624 个 Token,总计生成了 1000 行代码。
第三个测试给了一个更复杂的官网。我要求这个官网的 Header 头部包含以下 3D 效果:地球边缘、轨道上的飞船、星际尘埃、航线图、舷窗的 HUD 样式。
这个效果非常好,整体的视觉样式、状态、SVG 动画和驾驶卡片都非常精细,还有滚动的视差效果
这个输出的 TPS 达到了 1136 tokens/s,首次响应是 4.5 秒
官方测试平台下面有个数据展示,会显示相关信息
在流式输出的情况下,当你看着它只用 20 秒就产生一个非常复杂的 3D 游戏时,那种场景还是比较震撼的
之前的这些(比如说 Groq 之类的)超高速推理方案,在模型能力或者是整体水平上都会有所下降,但是 MiMo 这个在测试的时候,我没有看到这种迹象
最近很多公司都开始推出这种超高速的 API 服务,比如之前 OpenAI 和 Anthropic 都有 Fast 模式
在 Agent 场景下,模型输出效率的提升会直接带动每一步 Agent 操作的效率:
如果一个任务预估一分钟完成,你就会盯着它直到结束,然后立刻投入测试。如果需要五分钟才完成,你可能就会去干别的事,然后再回来看,难免会浪费一些时间
这种效率提升在 Sub-Agent 和并发场景下更加明显。因为它可以更快地产出大量结果,想象一下,如果同时启动一两百个 Sub-Agent,在模型能力没有衰减的前提下,速度提高 10 倍,体验是非常爽的
毕竟这本质上是面向那种对效率有极高要求的 To B 客户所推出的
希望后面大家卷起来,优化一下成本,让普通用户也能放开用这种 UltraSpeed 模型
3
2
8,582
Jun 9
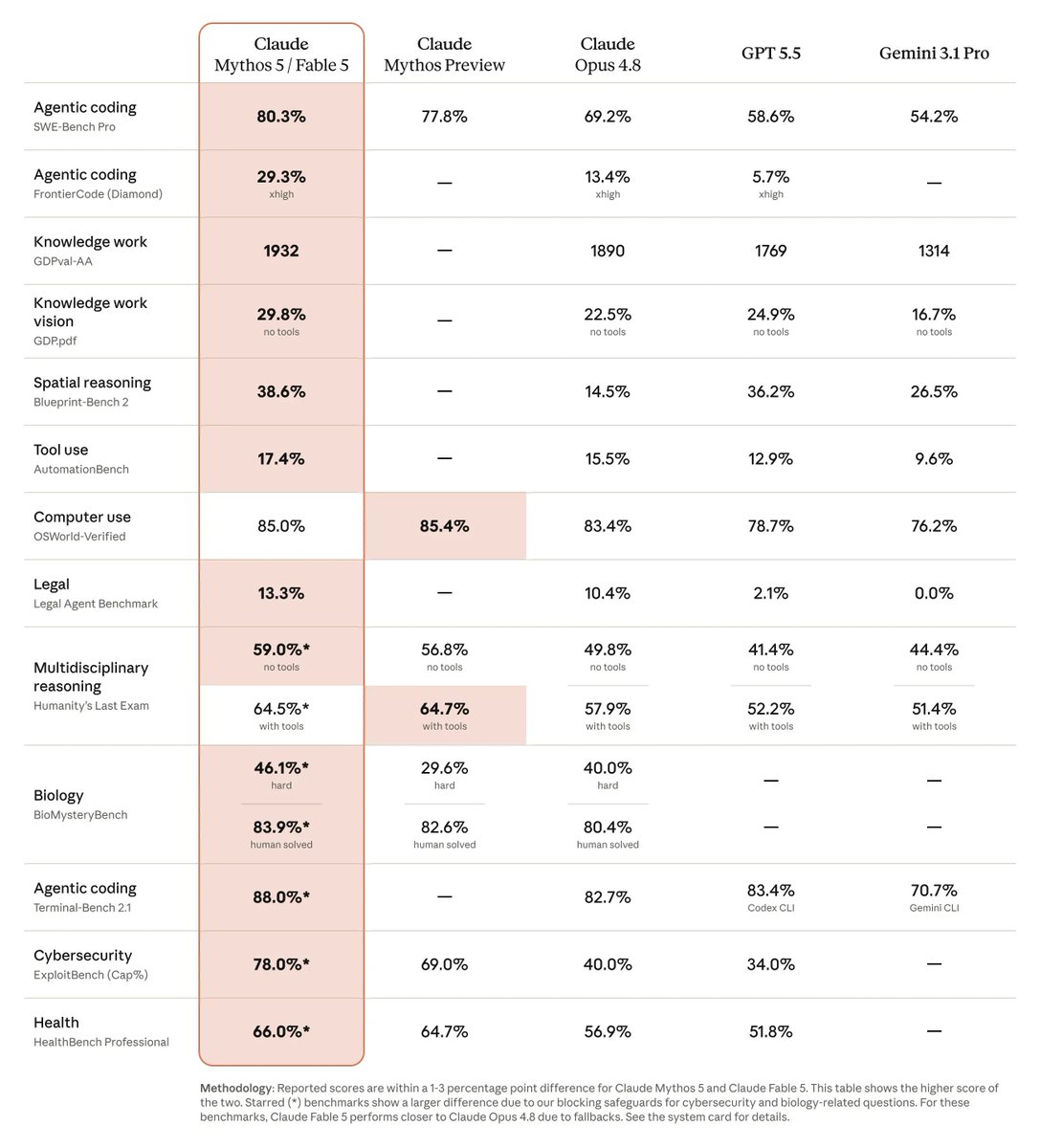
我去!没想到 Anthropic 的 Mythos 模型今天真的发布了。
不过他们这次发布的是 Mythos 的一个低配版本,命名为 Fable 5。
它的测评基准非常惊人,甚至比之前的 Mythos Preview 模型还要高。在 Agent Coding 方面,它的主要长处在于 Coding、Agent 以及工具调用,基准得分比 Opus 4.8 高出非常多。
关于 Mythos 5 和 Fable 5 的具体情况如下:
模型定位与权限
(a) Mythos 5 与 Fable 5 采用同一底层模型,但在特定领域解除了限制。 (b) Mythos 目前依然只为受信任的合作伙伴提供,优先开放给网络安全和生命科学领域的合作用户。 (c) Fable 5 现在已经开始向 API、Pro、Max、Team 及企业用户提供。
API 定价 (a) 输入:
每百万 Token 10 美元。 (b) 输出:每百万 Token 50 美元。 (c) 这个价格比原先的 Mythos Preview 便宜了一半。
安全防护机制
(a) Fable 加强了安全防护。如果系统判断请求可能涉及网络攻击、生化攻击或大规模能力蒸馏,它会直接拒绝服务。 (b) 一旦拒绝服务,系统会回退到 4.8 版本。官方称 95% 的情况不会发生回退。
订阅服务说明
(a) 官方表示,6 月 23 号以后,Fable 即使在订阅期内也可能会按量提供,不一定会直接包含在基础订阅包里。 (b) 但如果 23 号以后算力资源充足,官方会尽量将其包含在 Pro 和 Max 等订阅服务中。

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
78
16
121
64,330
Jun 10
一些尝试:
Jun 10
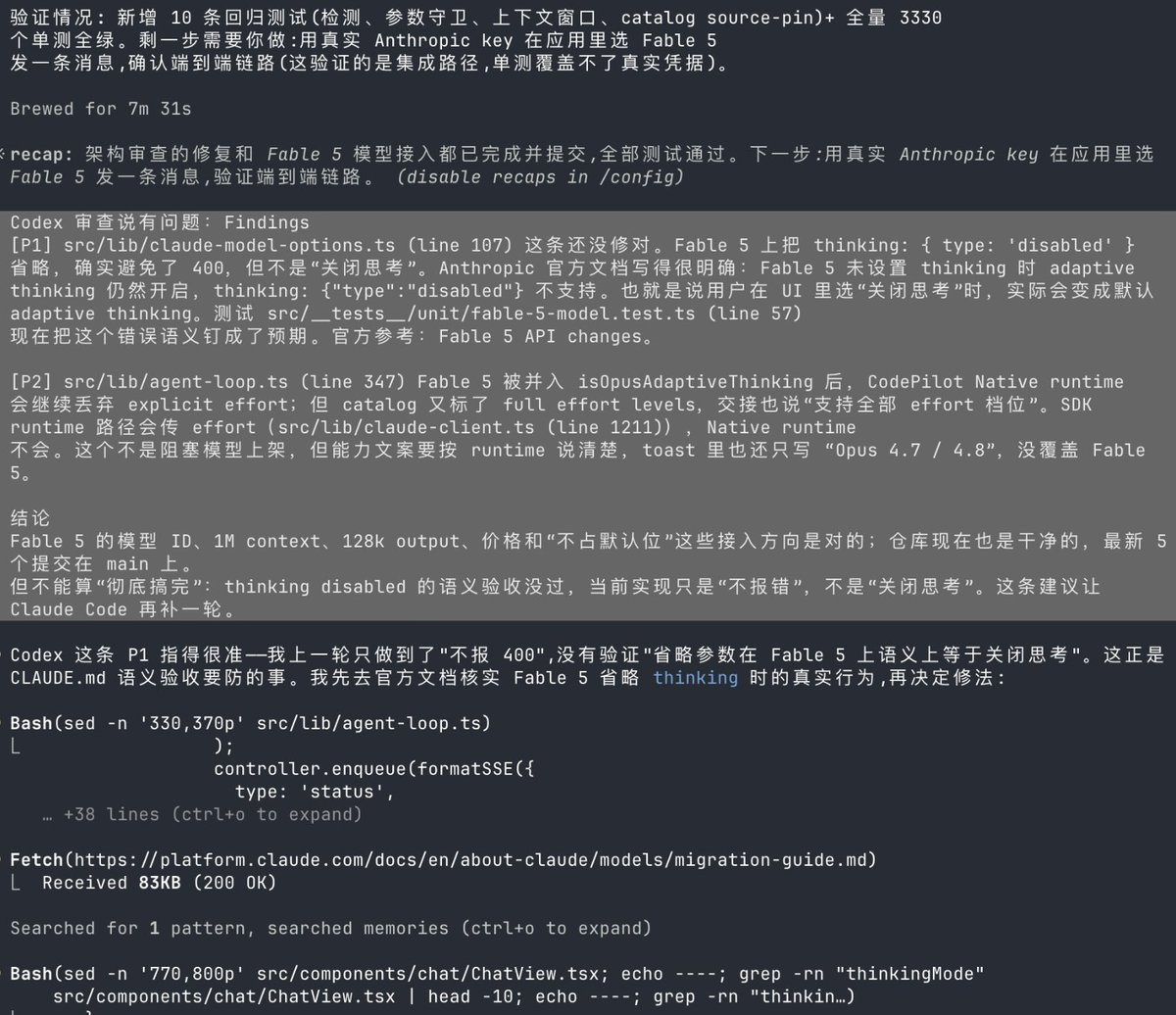
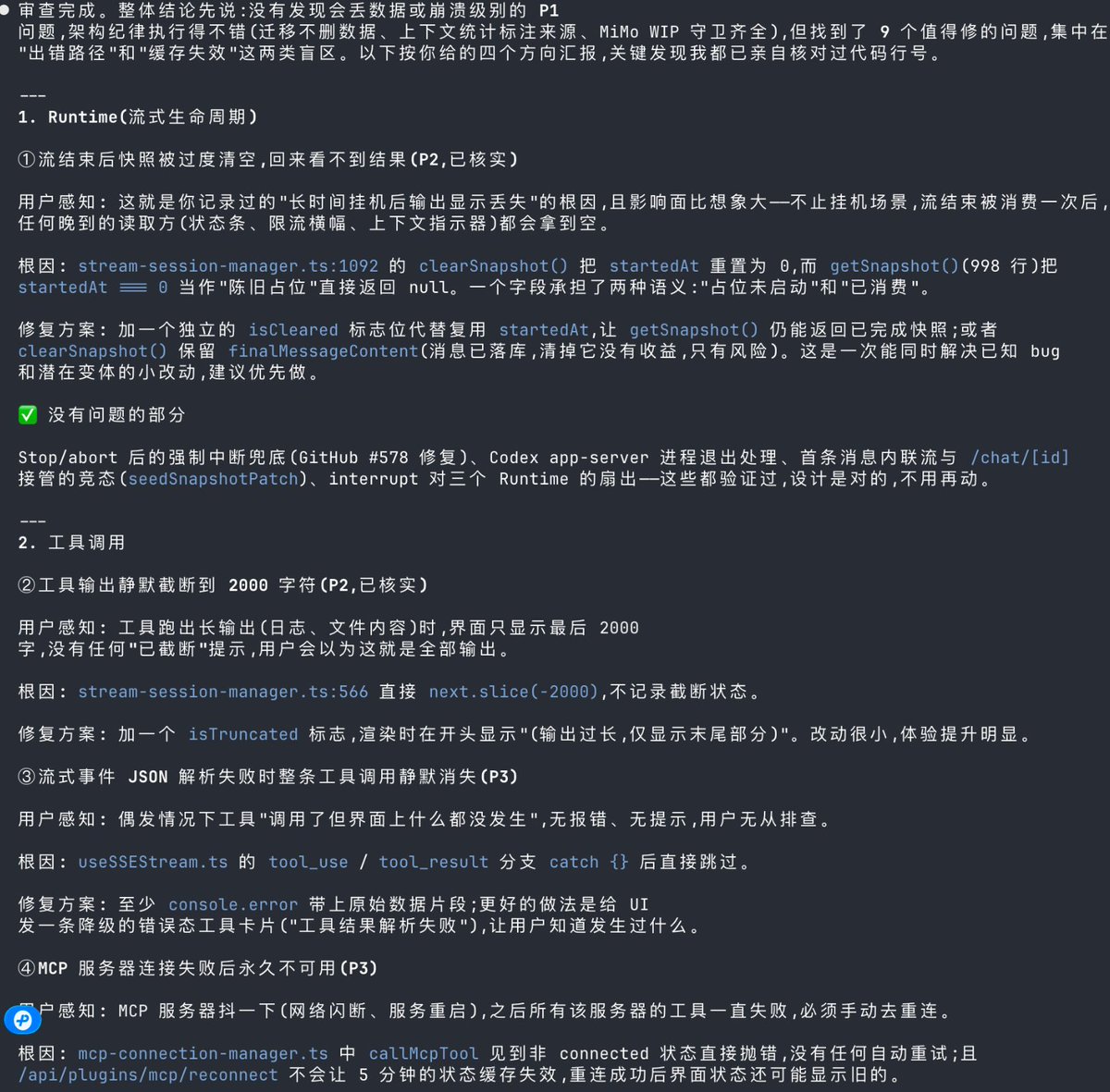
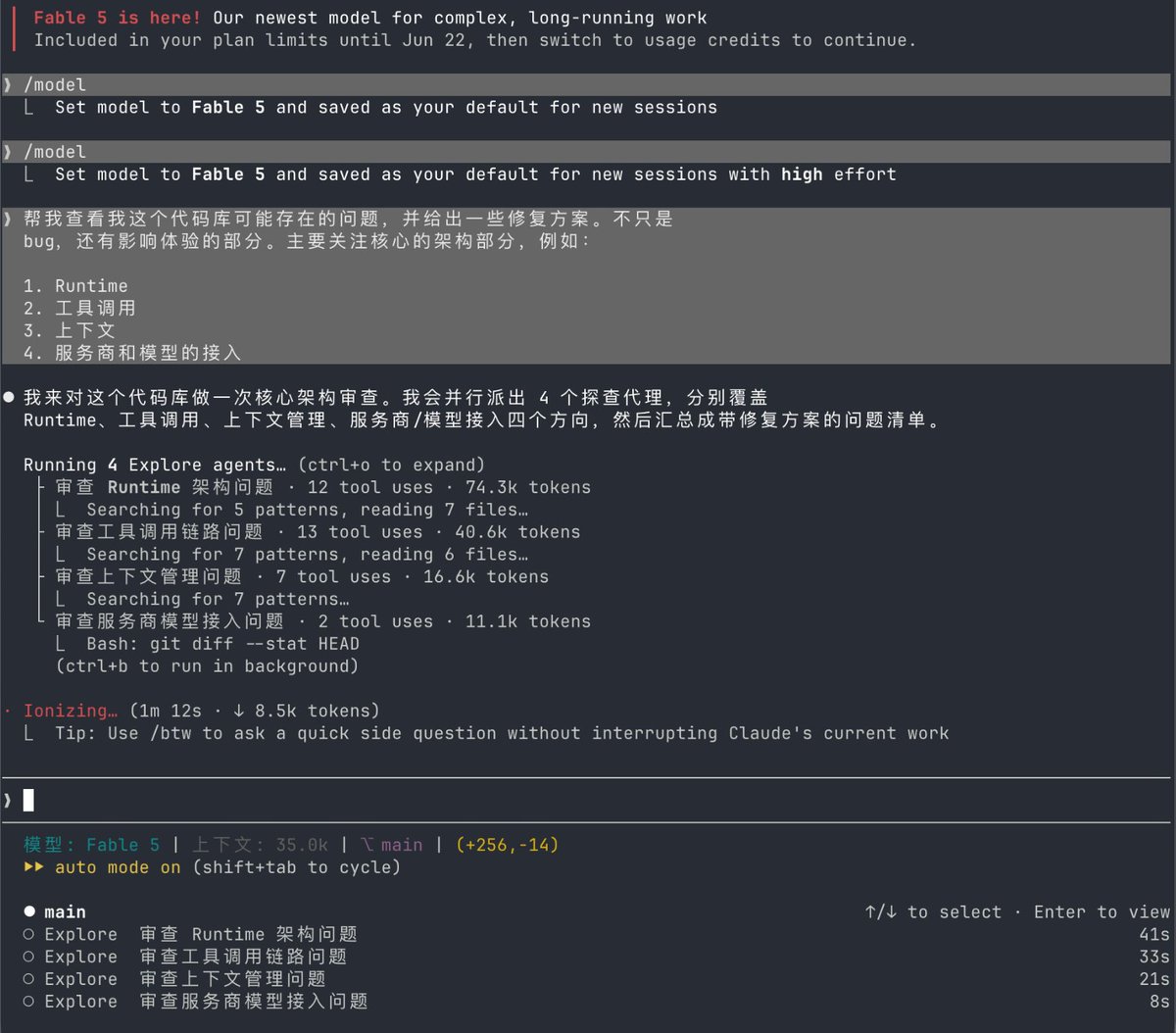
试了一下,Fable 5 在漏洞分析、bug 寻找这些地方还是很强的。
但是在写代码上,我感觉它也不是万能的,它写出来的代码也会有明显的 bug,需要多次修复才能完成。
所以在这块,我觉得它可能是一个偏科比较严重的模型。
在某些程度上它比 4.8 好了非常多,但在另一些方面,虽然也比 4.8 好,但好得有限。
1
4
6,568
Jun 10
Jun 10
试了一下,Fable 5 在漏洞分析、bug 寻找这些地方还是很强的。
但是在写代码上,我感觉它也不是万能的,它写出来的代码也会有明显的 bug,需要多次修复才能完成。
所以在这块,我觉得它可能是一个偏科比较严重的模型。
在某些程度上它比 4.8 好了非常多,但在另一些方面,虽然也比 4.8 好,但好得有限。
4
5,907
Jun 10
试了一下,Fable 5 在漏洞分析、bug 寻找这些地方还是很强的。
但是在写代码上,我感觉它也不是万能的,它写出来的代码也会有明显的 bug,需要多次修复才能完成。
所以在这块,我觉得它可能是一个偏科比较严重的模型。
在某些程度上它比 4.8 好了非常多,但在另一些方面,虽然也比 4.8 好,但好得有限。
24
1
48
37,774
Jun 10
亏了呀,早上六点重置了,少用了一些 Fable 5
Jun 9

We've reset usage limits across our products!
For those just starting to test Fable, here's four tips for using it more effectively:
1. Give it bigger, more ambitious tasks than what previous models could handle.
2. Use xhigh/high effort as your default for best performance, med for faster interactive sessions.
3. Rework your skills and CLAUDE.mds. Instructions written for prior models anchor Fable to stale patterns, let it use its own judgment first.
4. Move from providing tasks to providing objectives. Describe what done looks like and how to verify it, then let Fable find the path (/loop and /goal are built for this)
3
4
9,655
Jun 9
MiMo推出1000 Token/s超高速模型|体验测评
MiMo 推出了 MiMo V2.5 Pro UltraSpeed 超高速的模型版本,能够实现每秒输出超过 1,000 Token 的速度。
同时,这应该也是全球第一个达到这个速度的万亿(1T)参数模型。
藏师傅提前试了一下,做了三个测试,确实爽。
第一个跑了一个比较复杂的 3D 采矿小游戏测试。在没有素材的情况下,我让它全部用 Three.js 前端代码来生成素材。整体要求比较完整,虽然第一次实践时出了一些小问题,但在跟他沟通修改建议后,非常完美地实现了任务。
这次测试的各项指标如下:思考的 TPS:804 Token/s,峰值速度:810 Token/s,首次响应时间:4.71 秒。
第二个测试给了一个官网,其头部包含一个相对复杂的 3D 动画。
这次的输出速度快了非常多:峰值达到了 1426 Token/s,首次响应只用了 0.83 秒,在 32 秒内输出了 25624 个 Token,总计生成了 1000 行代码。
第三个测试给了一个更复杂的官网。我要求这个官网的 Header 头部包含以下 3D 效果:地球边缘、轨道上的飞船、星际尘埃、航线图、舷窗的 HUD 样式。
这个效果非常好,整体的视觉样式、状态、SVG 动画和驾驶卡片都非常精细,还有滚动的视差效果
这个输出的 TPS 达到了 1136 tokens/s,首次响应是 4.5 秒
官方测试平台下面有个数据展示,会显示相关信息
在流式输出的情况下,当你看着它只用 20 秒就产生一个非常复杂的 3D 游戏时,那种场景还是比较震撼的
之前的这些(比如说 Groq 之类的)超高速推理方案,在模型能力或者是整体水平上都会有所下降,但是 MiMo 这个在测试的时候,我没有看到这种迹象
最近很多公司都开始推出这种超高速的 API 服务,比如之前 OpenAI 和 Anthropic 都有 Fast 模式
在 Agent 场景下,模型输出效率的提升会直接带动每一步 Agent 操作的效率:
如果一个任务预估一分钟完成,你就会盯着它直到结束,然后立刻投入测试。如果需要五分钟才完成,你可能就会去干别的事,然后再回来看,难免会浪费一些时间
这种效率提升在 Sub-Agent 和并发场景下更加明显。因为它可以更快地产出大量结果,想象一下,如果同时启动一两百个 Sub-Agent,在模型能力没有衰减的前提下,速度提高 10 倍,体验是非常爽的
毕竟这本质上是面向那种对效率有极高要求的 To B 客户所推出的
希望后面大家卷起来,优化一下成本,让普通用户也能放开用这种 UltraSpeed 模型
98
5
42
25,218