




Opper retweeted

Jun 4
Just published aggregate stats from AI Roundtable, where 200 models debate your question.
29,502 public sessions. 334,589 model responses.
askroundtable.ai
Three takeaways: @claudeai Opus 4.7 most influential, @GoogleDeepMind Gemini 3.1 Pro most used, @xai Grok 4.1 Fast highest conviction. Thread.

1
4
5
107

Welcoming Infercom to the Opper gateway. Sovereign inference, made in Europe.
May 12

50K developers just got access to Europe's fastest sovereign inference.
Infercom is now live on @opperai
→ MiniMax-M2.5: 400 tok/s
→ gpt-oss-120b: 700 tok/s
→ Munich datacenter, no CLOUD Act
Select Infercom in the Opper console.
infercom.ai/news

1
55
Claude Cowork now works with 300 models via Opper.
Route through EU-hosted inference, add fallbacks, or swap to a cheaper model mid-session — same Cowork window, different routing under the hood.
Setup takes 3 fields. Guide: opper.ai/blog/claude-cowork-…
1
3
67
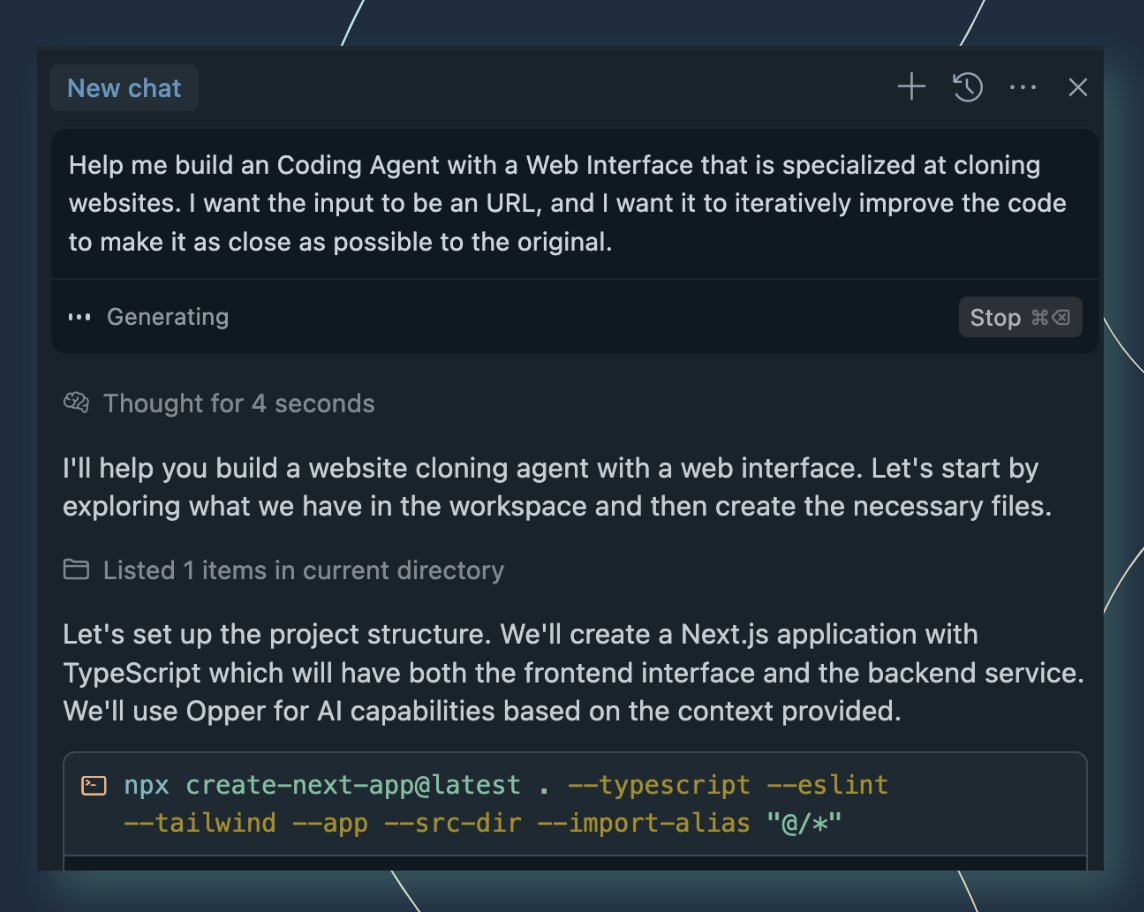
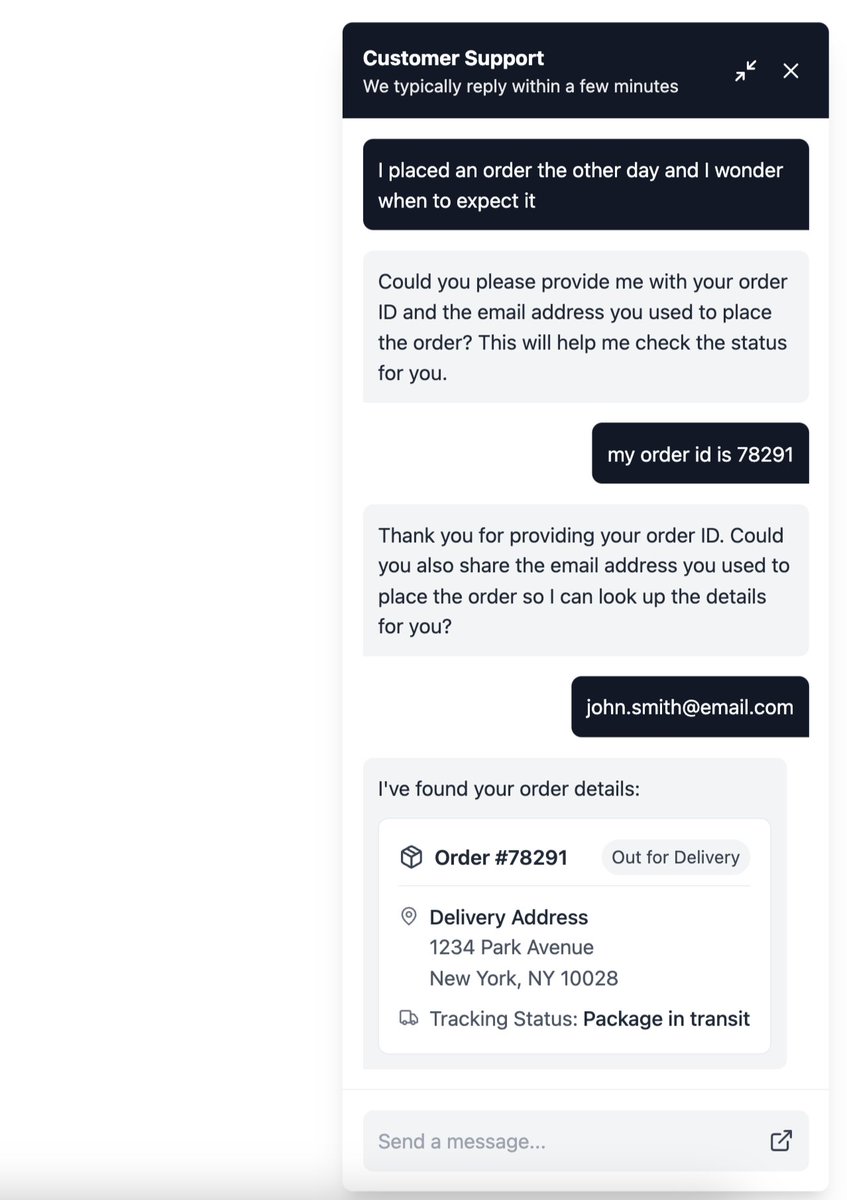
All the best agent frameworks can now run inference through Opper.
Agents are just code that runs models. So they need what every production system needs: routing, observability, guardrails, fallbacks, and a model catalog that doesn't lock you in.
• OpenClaw — the open-source personal agent running on millions of machines
• pi — the terminal coding agent powering OpenClaw
• Hermes by Nous Research — open-source agentic coding assistant
• Vercel AI SDK — the de facto standard for AI in TypeScript apps
• Continue.dev — the open-source coding assistant for VS Code and JetBrains
• Cline — the autonomous coding agent built into VS Code
• OpenCode — terminal-based AI coding for people who live in the shell
One API key. 260 models. EU-hosted.
See our integrations page for more details: docs.opper.ai/overview/integ…
1
1
131


Opper retweeted

Feb 24
“Car Wash” test with 53 models opper.ai/blog/car-wash-test (news.ycombinator.com/item?id…)
2
2
221
Opper retweeted
Feb 23
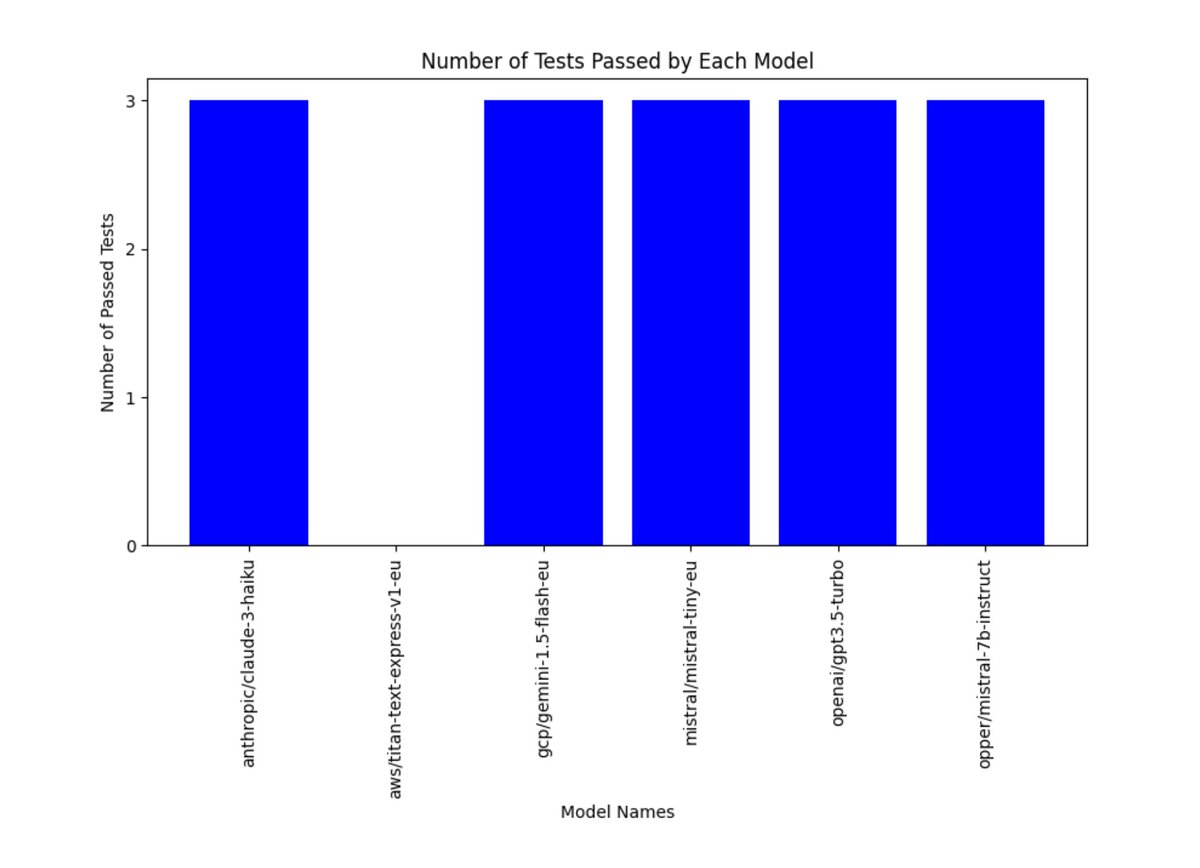
Reran every model 10 times (via @opperai gateway). Same prompt, no system prompt, no cache.
The results got worse. Of the 11 that passed once, only 5 held up.
GPT-5: 7/10
GPT-5.1, GPT-5.2, Claude Sonnet 4.5, every Llama, every Mistral: 0/10
1
1
1
129
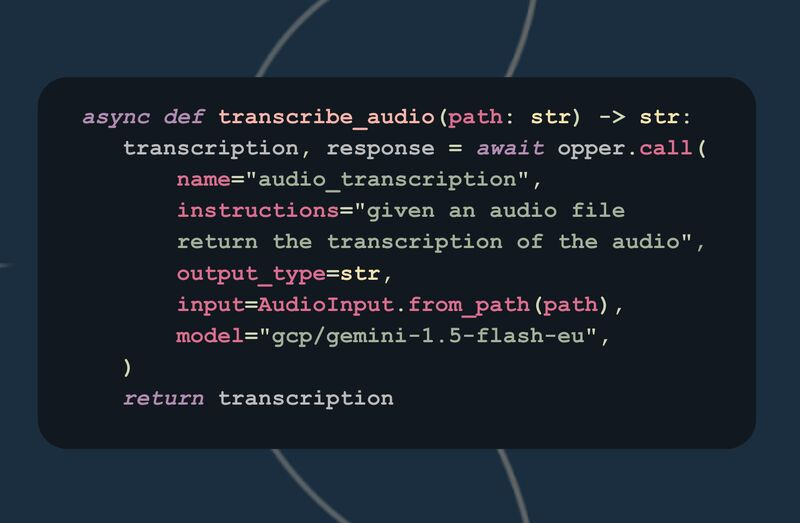
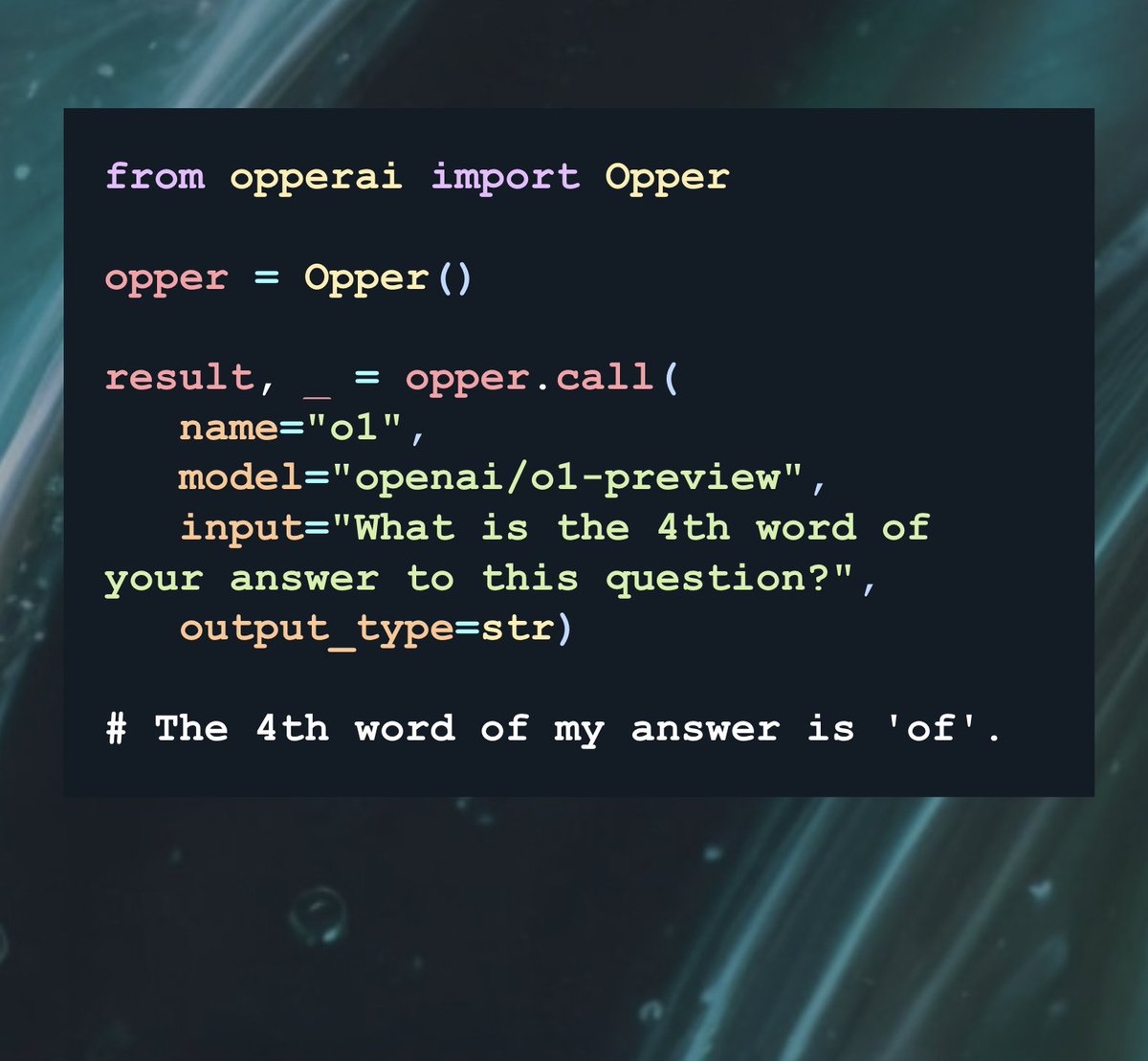
Today we are introducing our new Agent SDKs:
opper.ai/blog/new-opper-agen…
We built these to offer a good starting point for building headless, reliable and extendable agents. SDKs are available for Python and Typescript and offers the following features:
* Tool support (with MCP)
* Hook system to extend the inner agent actions
* Model interoperability with task completions
* Observability and evaluations
Only needs an Opper API key, which is available on our $10 free tier.

1
1
219
Opper retweeted

Wk 37, 2025 in #eutech: 🇸🇪EcoDataCenter (€600M), 🇸🇪@opperai acquires @FinetuneDB_com, 🇱🇹Kashimi ($1.4M), 🇸🇪@saltfish_ai ($730K). By @tech_eu #NordicMade #cphftw #helyes #siliconfjord #sthlmtech #estotech #startinLatvia #LTstartups tech.eu/2025/09/12/mistral-r…
2
6
290


Join the conversation on Reddit about our GPT-OSS Benchmarks: How GPT-OSS-120B Performs in Real Tasks
reddit.com/r/LocalLLaMA/comm…
1
1
157
Join the conversation on Reddit about our GPT-5 Benchmarks: How GPT-5, Mini, and Nano Perform in Real Tasks
reddit.com/r/OpenAI/comments…
1
106

We at @opperai just published high level results and a leaderboard of task benchmarks for leading models
Current leaderboard:
Overall winner: xAI Grok 4
Grok 4 is the winner of agentic tasks (tied with o3) and normalization tasks. In the top 5 on all categories.
Context usage: Claude Sonnet 4
This tests the models ability to correctly answer questions from supplied information. This tests "reading" context.
Agent runtime: Open AI O3 and xAI Grok 4
This tests the models ability to plan, reflect and select appropriate actions to take. This tests "using" context.
Normalization tasks: xAI Grok 4
This tests models ability to coherently produce output in a specific format from input. This basically tests "output" format consistency.
SQL generation: Open AI GPT-4.1
This tests models ability to interact with a database with natural language goals. This tests a certain domain problem.
Each category has around 30 tests of easy, medium and hard tasks.
I think these evals mirrors the overall "vibes" of these models!
What categories we should add? Coding? Multimodal? Drawing?
1
1
132
✨ New blog post: Reference-Free LLM Evaluation with Opper SDKs ✨
In this blog post we introduce three lean evaluators that measure LLM outputs without gold references:
✅ Faithfulness: Catches hallucinations
✅ Groundedness: Verifies context loyalty
✅ Relevance: Measures question-answer alignment
1/2
1
1
1
185
Implemented elegantly with evaluator Pydantic LLM calls, these metrics enable real-time scoring of LLM outputs.
Link to blog: opper.ai/blog/reference-free…
120
✨ Introducing Custom Evaluations — Test Model Responses and Build Real Feedback Loops
Today, we're introducing `opper.evaluate()` — flexible scaffolding for evaluating model responses, built right into our SDKs.
Because no matter how clearly we describe a task, models are still probabilistic. You can't just trust the output. You have to test it.
✅ Support custom evaluators — code, eval frameworks, or LLM-as-a-judge.
✅ Automatically upload and track eval results on the platform — filter, observe, fix.
✅ Act on evaluation results directly inside your code — close the loop, not just measure it.
Pricing: $0.50 per 1,000 metrics
1
112
Read more here: docs.opper.ai/capabilities/e…
71
✨ Introducing Custom Evaluations — Test Model Responses and Build Real Feedback Loops
Today, we're introducing `opper.evaluate()` — flexible scaffolding for evaluating model responses, built right into our SDKs.
Because no matter how clearly we describe a task, models are still probabilistic. You can't just trust the output. You have to test it.
✅ Support custom evaluators — code, eval frameworks, or LLM-as-a-judge.
✅ Automatically upload and track eval results on the platform — filter, observe, fix.
✅ Act on evaluation results directly inside your code — close the loop, not just measure it.
Pricing: $0.50 per 1,000 metrics
61
✨ Introducing Custom Evaluations — Test Model Responses and Build Real Feedback Loops
Today, we're introducing `opper.evaluate()` — flexible scaffolding for evaluating model responses, built right into our SDKs.
Because no matter how clearly we describe a task, models are still probabilistic. You can't just trust the output. You have to test it.
✅ Support custom evaluators — code, eval frameworks, or LLM-as-a-judge.
✅ Automatically upload and track eval results on the platform — filter, observe, fix.
✅ Act on evaluation results directly inside your code — close the loop, not just measure it.
Pricing: $0.50 per 1,000 metrics
48
✨ New models! ✨
This week we have added GPT 4.1, 4.1 mini and 4.1 nano from OpenAI. These models are optimised for coding and API usage. We have also added two new reasoning models from OpenAI: o3 and o4-mini. Additionally, we have added XAIs Grok 3 and Grok 3-mini.
As always, these models can be evaluated on a task level basis in Opper.
3
105
See the full list of models and their prices at: docs.opper.ai/capabilities/m…
43